完全解析!Bert & Transformer 阅读理解源码详解
Posted 红色石头Will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了完全解析!Bert & Transformer 阅读理解源码详解相关的知识,希望对你有一定的参考价值。

接上一篇:
参考论文:
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/1810.04805
在本文中,我将以run_squad.py以及SQuAD数据集为例介绍阅读理解的源码,官方代码基于tensorflow-gpu 1.x,若为tensorflow 2.x版本,会有各种错误,建议切换版本至1.14。
当然,注释好的源代码在这里:
https://github.com/sherlcok314159/ML/tree/main/nlp/code
章节
Demo传参
数据篇
番外句子分类
创造实例
实例转换
模型构造
写入预测
Demo传参
python bert/run_squad.py \\
--vocab_file=uncased_L-12_H-768_A-12/vocab.txt \\
--bert_config_file=uncased_L-12_H-768_A-12/bert_config.json \\
--init_checkpoint=uncased_L-12_H-768_A-12/bert_model.ckpt \\
--do_train=True \\
--train_file=SQUAD_DIR/train-v2.0.json \\
--train_batch_size=8 \\
--learning_rate=3e-5 \\
--num_train_epochs=1.0 \\
--max_seq_length=384 \\
--doc_stride=128 \\
--output_dir=/tmp/squad2.0_base/ \\
--version_2_with_negative=True
阅读源码最重要的一点不是拿到就读,而是跑通源码里面的小demo,因为你跑通demo就意味着你对代码的一些基础逻辑和参数有了一定的了解。
前面的参数都十分常规,如果不懂,建议看我的文本分类的讲解。这里讲一下比较特殊的最后一个参数,我们做的任务是阅读理解,如果有答案缺失,在SQuAD1.0是不可以的,但是在SQuAD允许,这也就是True的意思。
需要注意,不同人的文件路径都是不一样的,你不能照搬我的,要改成自己的路径。
数据篇
其实阅读理解任务模型是跟文本分类几乎是一样的,大的差异在于两者对于数据的处理,所以本篇文章重点在于如何将原生的数据转换为阅读理解任务所能接受的数据,至于模型构造篇,请看文本分类:
https://github.com/sherlcok314159/ML/blob/main/nlp/tasks/text.md
番外句子分类
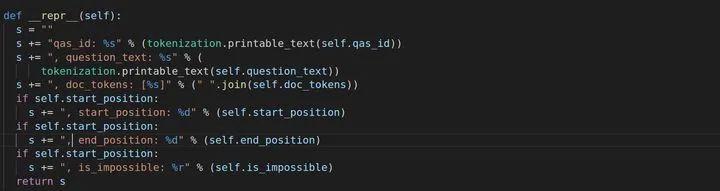
想必很多人看到SquadExample类的_repr_方法都很疑惑,这里处理好一个example,为什么后面还要进行处理?看英文注释会发现这个类其实跟阅读理解没关系,它只是处理之后对于句子分类任务的,自然在run_squad.py里面没被调用。_repr_方法只是在有start_position的时候进行字符串的拼接。
创造实例
用于训练的数据集是json文件,需要用json库读入。
训练集的样式如下,可见data是最外层的
"data": [
"title": "University_of_Notre_Dame",
"paragraphs": [
"context": "Architecturally, the school has a Catholic character.",
"qas": [
"answers": [
"answer_start": 515,
"text": "Saint Bernadette Soubirous"
],
"question": "To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?",
"id": "5733be284776f41900661182"
]
]
,
"title":"...",
"paragraphs":[
"context":"...",
"qas":[
"answers":[
"answer_start":..,
"text":"...",
],
"question":"...",
"id":"..."
,
]
]
]

input_data是一个大列表,然后每一个元素样式如下
'paragraphs': [..., ..., ..., ..., ..., ..., ..., ..., ..., ...], 'title': 'University_of_Notre_Dame'
is_whitespace方法是用来判断是否是一个空格,在切分字符然后加入doc_tokens会用到。

然后我们层层剥开,然后遍历context的内容,它是一个字符串,所以遍历的时候会遍历每一个字母,字符会被进行判断,如果是空格,则加入doc_tokens,char_to_word_offset表示切分后的索引列表,每一个元素表示一个词有几个字符组成。
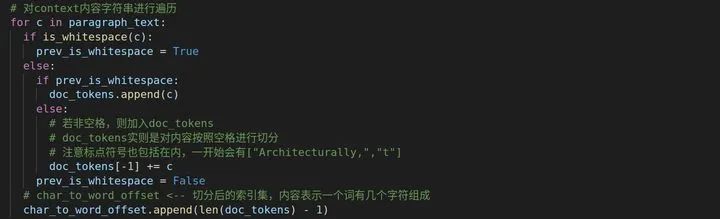
切分后的doc_tokens会去掉空白部分,同时会包括英文逗号。一个单词会有很多字符,每个字符对应的索引会存在char_to_word_offset,例如,前面都是0,代表这些字符都是第一个单词的,所以都是0,换句话说就是第一个单词很长。
doc_tokens = ['Architecturally,', 'the', 'school', 'has', 'a', 'Catholic', 'character.', 'Atop', 'the',"..."]
char_to_word_offset = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
接下来进行qas内容的遍历,每个元素称为qa,进行id和question内容的分配,后面都是初始化一些参数

qa里面还有一个is_impossible,用于判断是否有答案

确保有答案之后,刚刚读入了问题,现在读入与答案相关的部分,读入的时候注意start_position和end_position是相对于doc_tokens的

接下来对答案部分进行双重检验,actual_text是根据doc_tokens和始末位置拼接好的内容,然后对orig_answer_text进行空格切分,最后用find方法判断orig_answer_text是否被包含在actual_text里面。

这个是针对is_impossible来说的,如果没有答案,则把始末位置全部变成-1。

然后将example变成SquadExample的实例化对象,将example加入大列表——examples并返回,至此实例创建完成。

实例转换
把json文件变成实例之后,我们还差一步便可以把数据塞进模型进行训练了,那就是将实例转化为变量。
先对question_text进行简单的空格切分变为query_tokens

如果问题过长,就进行截断操作

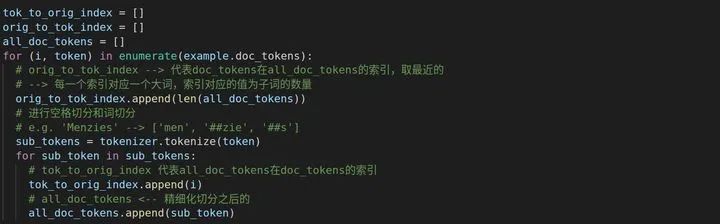
接下来对doc_tokens进行空格切分以及词切分,变成all_doc_tokens,需要注意的是orig_to_tok_index代表的是doc_tokens在all_doc_tokens的索引,取最近的一个,而tok_to_orig_index代表的是all_doc_tokens在doc_tokens索引
对tok_start_position和tok_end_position进行初始化,记住,这两个是相对于all_doc_tokens来说的,一定要与start_position和end_position区分开来,它们是相对于doc_tokens来说的

接下来先介绍_improve_answer_span方法,这个方法是用来处理特殊的情况的,举个例子,假如说你的文本是"The Japanese electronics industry is the lagest in the world.",你的问题是"What country is the top exporter of electornics?" 那答案其实应该是Japan,可是呢,你用空格和词切分的时候会发现Japanese已经在词表中可查,这意味着不会对它进行再切分,会直接将它返回,这种情况下可能需要这个方法救场。

因为是监督学习,答案已经给出,所以呢,这个方法干的事情就是词切分后的tokens进行再一次切分,如果发现切分之后会有更好的答案,就返回新的始末点,否则就返回原来的。
对tok_start_position和tok_end_position进行进一步赋值
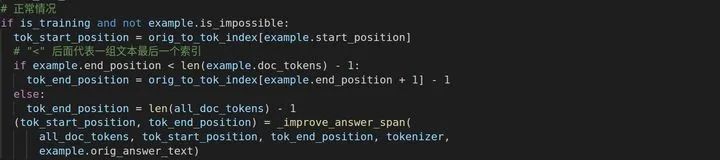
计算max_tokens_for_doc,与文本分类类似,需要减去[CLS]和两个[SEP]的位置,这里不同的是还要减去问题的长度,因为这里算的是文本的长度。
tokens = [CLS] query tokens [SEP] context [SEP]

很多时候文章长度大于maximum_sequence_length的时候,这个时候我们要对文章进行切片处理,把它按照一定长度进行切分,每一个切片称为一个doc_span,start代表从哪开始,length代表一个的长度。

doc_spans储存很多个doc_span。这里对窗口的长度有所限制,规定了start_offset不能比doc_stride大,这是第二个窗口的起点,从这个角度或许可以理解doc_stride代表平滑的长度。
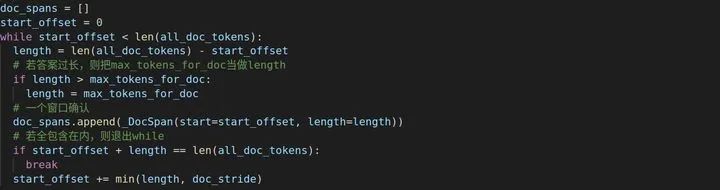
接下来的操作跟文本分类有些类似,添加[CLS],然后添加问题和[SEP],这些在segment_ids里面都为0。
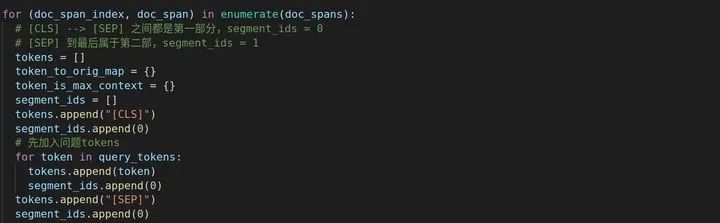
下面讲_check_is_max_context方法,这个方法是用来判断某个词是否具有完备的上下文关系,源代码给了一个例子:
Span A: the man went to the
Span B: to the store and bought
Span C: and bought a gallon of ...
那么对于bought来说,它在Span B和Span C中都有出现,那么,哪一个上下文关系最全呢?其实我们凭直觉应该可以猜到应该是Span C,因为Span B中bought出现在句末,没有下文。当然了,我们还是得用公式计算一下
score = min(num_left_context, num_right_context) + 0.01 * doc_span.length
score_B = min(4, 0) + 0.05 = 0.05
score_C = min(1,3) + 0.05 = 1.05
所以,在Span C中,bought的上下文语义最全,最终该方法会返回True or False,在滑动窗口这个方法中,一个词很可能出现在多个span里面,所以用这个方法判断当前这个词在当前span里面是否具有最完整的上下文
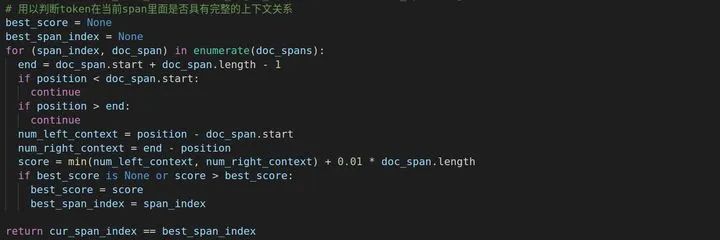
回到上面,token_to_orig_map是用来记录文章部分在all_doc_tokens的索引,而token_is_max_context是记录文章每一个词在当前span里面是否具有最完整的上下文关系,因为一开始只有一个span,那么一开始每个词肯定都是True。split_token_index用于切分成每一个token,这样可以进行上下文关系判断,至于后面添[SEP]和segment_ids添1这种操作文本分类也有。

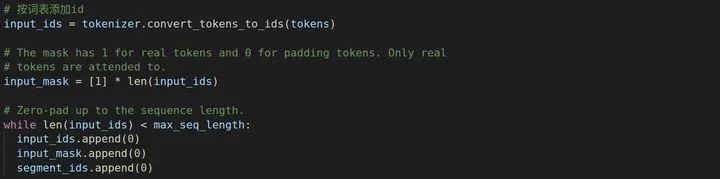
接下来将tokens(精细化切分后的)按照词表转化为id,另外若不足,则把0填充进去这种操作也是很常见的。
前面是进行判断,如果切了之后答案并不在span里面就直接舍弃,若在里面,因为一开始all_doc_tokens里面没有问题和[CLS],[SEP]时正文的索引是tok_start_position,然后转换为input_ids又有问题以及[CLS],[SEP],所以要得到正文索引需要跳过它们。

接下来大量的tf.logging只是写入日志信息,同时也是你终端或输出那里看到的。
最终用这些参数实例化InputFeatures对象,然后不断重复,每一个feature对应着一个特殊的id,即为unique_id。
模型构建
这里大致与文本分类差不多,只是文本分类在模型里面直接进行了softmax处理,然后进行最小交叉熵损失,而这次我们没有直接这样做,得到了开头和结尾处的未归一化的概率logits,之后我们直接返回。
然后这次我们是在model_fn_builder方法里面的子方法model_fn里定义compute_loss,其实这里也是经过softmax进行归一化,然后再计算交叉熵损失,最终返回均方误差。

然后我们计算开头和结尾处的损失,总损失为二者和的平均。
最终我们进行优化。

写入预测
start_logit & end_logit 代表着未经过softmax的概率,start_logit表示tokens里面以每一个token作为开头的概率,后者类似的。还有一对null_start_logit & null_end_logit,它们两个代表的是SQuAD2.0没有答案的那些,默认全为0。
首先,简单介绍一下_get_best_indexes,这个方法是用来输出由高到低前n_best_size个的概率的索引。

遍历start_indexes,end_indexes(都是分别经过_get_best_indexes得到),对于答案未缺失的,以具体的logit填入,另外,feature_index代表第几个feature。

如果答案缺失,则全都为0

接下来我们进一步转换为具体的文本

然后进一步清洗数据

这样还有个问题,词切分会自动小写,与答案还存在一定的偏移,这里介绍get_final_text方法来解决这一问题,比如:
pred_text = steve smith
orig_text = Steve Smith's
这个方法通俗来讲就是获得orig_text(未经过词切分)上正确的截取片段。
然后将其添加到nbest中

同样会存在没有答案的情况

接下来会有一个total_scores,它的元素是start_logit和end_logit相加,注意,它们不是数值,是数组,之后就计算total_scores的交叉熵损失作为概率。

剩下的部分跟文本分类差不多,这里就此略过。
推荐阅读
(点击标题可跳转阅读)
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 
以上是关于完全解析!Bert & Transformer 阅读理解源码详解的主要内容,如果未能解决你的问题,请参考以下文章