spark.mllib源码阅读-回归算法1-LinearRegression
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-回归算法1-LinearRegression相关的知识,希望对你有一定的参考价值。
Spark实现了三类线性回归方法:
1、LinearRegression:普通线性回归模型
2、LassoRegression:加L1正则化的线性回归
3、RidgeRegression:加L2正则化的线性回归
Spark采用了模型和训练分离定义的方式,模型和模型的迭代计算都很清晰:
如LinearRegressionModel和LinearRegressionWithSGD,LassoModel和LassoWithSGD,RidgeRegressionModel和RidgeRegressionWithSGD。其中Model继承自GeneralizedLinearModel和RegressionModel,为了便于模型的保存和输出,还继承了Saveable、Loader和PMMLExportable类,XXXWithSGD继承自GeneralizedLinearAlgorithm,并实现来模型训练的train方法其通过调用父类GeneralizedLinearAlgorithm的run方法来实现模型参数求解的逻辑。

LinearRegression(普通线性回归模型)
三类线性回归模型的实现都大同小异,在此以普通的线性回归LinearRegressionModel和LinearRegressionWithSGD为例来说明。LinearRegressionModel继承了大量的类,但本身实现比较简单,即覆写来父类的predictPoint、save和load方法。代码简单,在此不述。
RidgeRegressionWithSGD继承了GeneralizedLinearAlgorithm类,其主要实现了一个方法train,并定义来自己的Gradient类型和Updater类型为模型训练做准备,另外train实现了重载:
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
regParam: Double,
miniBatchFraction: Double,
initialWeights: Vector): RidgeRegressionModel =
new RidgeRegressionWithSGD(stepSize, numIterations, regParam, miniBatchFraction).run(
input, initialWeights)
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
regParam: Double,
miniBatchFraction: Double): RidgeRegressionModel =
new RidgeRegressionWithSGD(stepSize, numIterations, regParam, miniBatchFraction).run(input)
def train(
input: RDD[LabeledPoint],
numIterations: Int,
stepSize: Double,
regParam: Double): RidgeRegressionModel =
train(input, numIterations, stepSize, regParam, 1.0)
def train(
input: RDD[LabeledPoint],
numIterations: Int): RidgeRegressionModel =
train(input, numIterations, 1.0, 0.01, 1.0)
不同train方法的区别主要是初始化参数值,从这里也可以看到Spark使用来哪些默认的参数值进行模型的初始化。train方法内部调用了父类的run方法。
我们再来看看父类GeneralizedLinearAlgorithm的run方法干来啥?
run方法首先进行了特征值的 Scaling,这里对特征值的方差进行来归一化:
//run方法的特征值Scaling过程
val scaler = if (useFeatureScaling)
new StandardScaler(withStd = true, withMean = false).fit(input.map(_.features))
else
null
// Prepend an extra variable consisting of all 1.0's for the intercept.
// TODO: Apply feature scaling to the weight vector instead of input data.
val data =
if (addIntercept)
if (useFeatureScaling)
input.map(lp => (lp.label, appendBias(scaler.transform(lp.features)))).cache()
else
input.map(lp => (lp.label, appendBias(lp.features))).cache()
else
if (useFeatureScaling)
input.map(lp => (lp.label, scaler.transform(lp.features))).cache()
else
input.map(lp => (lp.label, lp.features))
特征值的 Scaling过程是由用户决定是否需要Scaling,一般来说,用户可以在数据预处理的步骤中进行特征值的Scaling,也可以交给Spark在这里进行。关于
为什么要做特征值的Scaling,在知乎上看到的一个图片能很好的说明问题:
没有进过归一化,寻找最优解的过程
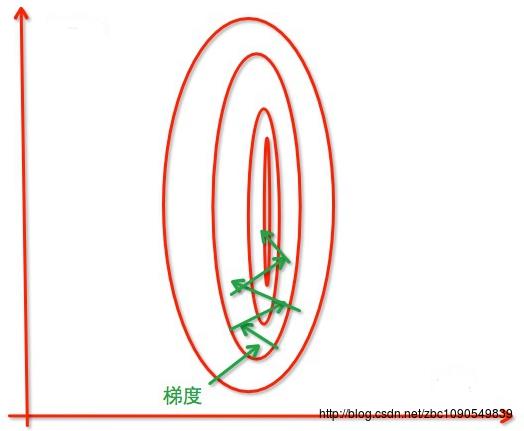
经过归一化,把各个特征的尺度控制在相同的范围内:

另外,本人也有3遍介绍归一化的博文:数据预处理之归一化、机器学习中的归一化方法、时间序列的归一化方法、也可以看看来自知乎的问答,结合具体的机器学习算法,还有很多特定的特征Scaling方法。
说完特征值的Scaling,再回过头来看run方法。run方法除了特征值的Scaling外,还做来一些训练数据的整理、模型参数初始化的过程,之后调用了Optimizer类实例来求解模型参数并在最后调用createModel方法返回一个RegressionModel:
val weightsWithIntercept = optimizer.optimize(data, initialWeightsWithIntercept)
//val intercept = 这里省略了一些代码
//var weights =
createModel(weights, intercept)总结,Spark模型和训练算法模块分离,对模型应用还是训练来说,都是算法思路清晰、模块算法低耦合的特点,同时,对算法开发人员也比较友好,可以单独实现自己的优化算法或者单独实现上层的模型。
以上是关于spark.mllib源码阅读-回归算法1-LinearRegression的主要内容,如果未能解决你的问题,请参考以下文章