看图说话——CNN和LSTM的联合应用
Posted 张雨石
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了看图说话——CNN和LSTM的联合应用相关的知识,希望对你有一定的参考价值。
看图说话是深度学习波及的领域之一。其基本思想是利用卷积神经网络来做图像的特征提取,利用LSTM来生成描述。但这算是深度学习中热门的两大模型为数不多的联合应用了。
本文是参考文献[1]的笔记,论文是比较早的论文,15年就已经发表了,不新。但还是想写下来它的细节以备后用。
关于CNN(卷积神经网络)和LSTM(长短期记忆网络)的细节,本文不再赘述其细节。读者们需要了解的是:
- 卷积神经网络是一种特别有效的提取图像特征的手段。一个在大数据集如ImageNet上预训练好的模型能够非常有效的提取图像的特征。
- 长短期记忆网络能够处理长短不一的序列式数据,比如语言句子。给定一个输入,网络能够给出一个序列输出。
背景
在参考论文提出的模型之前,对于看图说话这个问题,解决方法主要有两个大类:
- 利用一些预定义好的属性来进行生成,比如对于路况图像,可以判断路上多少车,然后判断路况堵不堵之后就可以生成描述。但这样不具有可扩展性,对于每种场景都需要定制。
- 使用搜索排序的方法定义该问题,即对于每张图像,在已有的描述中选择最好的一个。这种方法的限制在于不能生成新的语句。
网络模型
图像到文字的问题可以看做是一种机器翻译,在现在的机器翻译模型中,以LSTM为基础的seq2seq模型成为主流,该模型的基本思想是,对于一个数据pair (A, B)。因为A和B表达的是同一个意思,所以存在某种隐含状态h,使得A和B都对应到h。于是seq2seq模型就先对A进行编码,得到一个数据表示,再基于这个数据表示去解码,生成目标语言的文字。
图像到文字也类似,假设存在某种隐含状态h,图像可以编码到h,而基于h可以生成目标语句。
用公式表示则是:
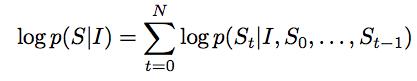
模型则如图示:
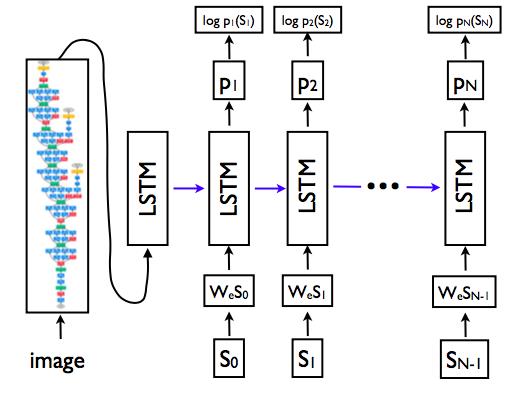
值得注意的是,在LSTM模型方面,训练和预测的时候是不一样的。
- 在训练时,假设数据是<某张图像A, " 我 是 谁 ">,那么LSTM的输入S0到SN-1分别是、我、是、谁;而输出分别是 我、是、谁、。
- 在预测时,对于数据是<某张图像A1, ???>,那么LSTM的输入S0为,S1到SN-1分别为上一步的输出。
实验
效果评价
使用三种评价指标:
- 人工评价: 在Amazon Mechanical Turk平台上进行评测,每条数据可以由多个人打分。
- BLEU:衡量预测结果和实际结果在N-gram上的精度。
- Perplexity: 语言模型的常用指标,语句出现的概率,等于其句子中每个词出现的概率之积。METEOR和Cider是其变种。
训练细节
为了避免过拟合,采用了如下手段:
- 使用在大数据集上预训练好的CNN模型。这样不止防止了过拟合,还会提升效果。
- 预训练好的word embedding并不能提升效果,所以没用。
- Dropout和Ensembling可以显著提升效果
- 图像的文本描述数据部分都经过了预处理
- 统计词语频度,只保留出现过5个以上的词语。
实验结果
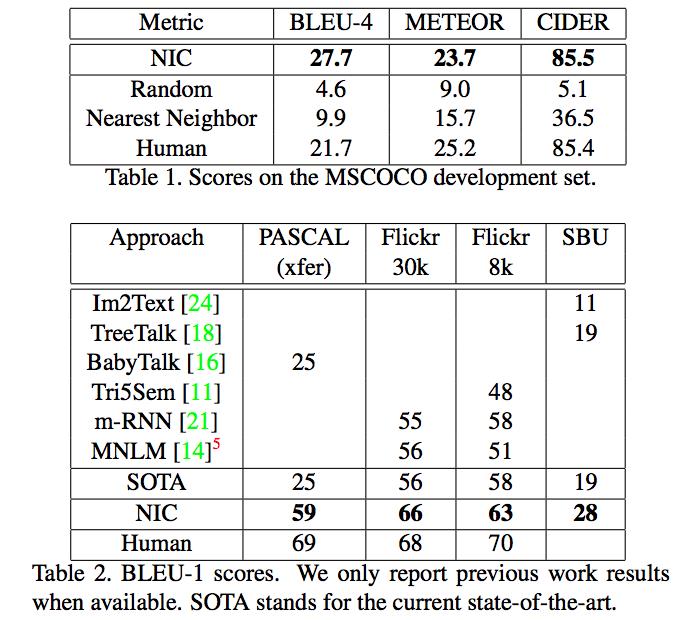
- 各个指标均显著变好。
- 在Flickr30k和Flickr8k的类似数据上进行对比,发现大数据集可以显著提升效果
- 在top-1的预测结果上,模型的输出有80%在训练集上出现过。而Top-15则只有50%的语句在训练集上出现过。
参考文献
[1]. Show and Tell: A Neural Image Caption Generator
公众号
更多关于Transformer、Bert、AutoML、架构等方面的知识欢迎关注公众号【雨石记】。

以上是关于看图说话——CNN和LSTM的联合应用的主要内容,如果未能解决你的问题,请参考以下文章