优化C++软件
Posted wuhui_gdnt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化C++软件相关的知识,希望对你有一定的参考价值。
3. 出最大的时间消耗者
3.1. 一个时钟周期是多少?
在本手册中,我使用CPU时钟周期,而不是秒或毫秒,作为时间测度。这是因为计算机的速度有非常大的差异。如果我写某个东西今天需要10 μs,在下一代计算机它可能仅需要5 μs,我的手册很快就过时了。但如果我写某个东西需要10时钟周期,那么即使CPU时钟周期加倍,它仍将需要10时钟周期。
一个时钟周期的长度是时钟频率的倒数。例如,如果时钟频率是2GHz,那么一个时钟周期的长度是12GHz=0.5 ns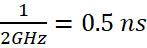 。
。
一台计算机上的时钟周期不总是与另一台计算机上的时钟周期可比较。Pentium 4(NetBurst)CPU设计了比其他CPU更高的时钟频率,但一般而言,执行相同的代码片段,它比其他CPU使用更多的时钟周期。
假定在程序中一个循环重复1000次,并且循环里有100个浮点操作(加法、乘法等)。如果每个浮点操作需要5时钟周期,我们可以粗略地估计,在一个2GHz CPU上,该循环将需要1000 * 100 * 5 * 0.5 ns = 250 μs。我们应该尝试优化这个循环吗?当然不!250 μs不到刷新屏幕时间的1/50。用户无法看到这个延迟。但如果该循环在另一个也是重复1000次的循环里,那么估计计算时间是250 ms。这个时延刚好能被注意到,但尚不令人讨厌。我们可能决定做某些测量看一下我们的估计算法是否正确,或者计算时间是否实际上超出250 ms。如果响应时间很长,用户实际上必须等待结果,那么我们将考虑是否有什么可以改进的。
3.2. 使用性能分析器查找热点
在开始优化前,必须确定程序的关键部分,在某些程序里,超过99%的时间花在执行数学计算的最里层循环中。在其他程序里,99%的时间花在读、写数据文件,而花在实际处理数据的时间不超过1%。优化代码事关重要的部分,而不是使用少量时间的其他部分,非常重要。优化不那么关键的代码部分,不仅浪费了时间,还使得代码不那么清晰,更难以调试与维护。
大多数编译器包包含一个可以告诉你每个函数调用了几次,以及使用了多少时间的性能分析器。还有第三方性能分析器,诸如Aqtime、Intel VTune与AMD CodeAnalyst。
有几个不同的性能分析方法:
- 插桩(instrumentation):编译器在每个函数调用处插入额外的代码,统计函数调用的次数与其使用的时间。
- 调试。分析器在每个函数或每行代码插入临时调试断点。
- 基于时间的抽样:分析器告诉操作系统产生一个中断,比如每毫秒。分析器统计在程序的每部分里,中断发生了多少次。这不要求修改测试的程序,但不那么可靠。
- 基于事件的抽样:分析器告诉CPU在特定事件产生中断,例如每1000次缓存不命中发生时。这使得查看程序哪个部分有最多的缓存不命中、分支误预测、浮点异常等成为可能。基于事件抽样要求一个CPU特定的分析器。对Intel CPU,使用Intel VTune;对AMD CPU,使用AMD CodeAnalyst。
不幸的是,分析器通常不可靠。它们有时给出误导的结果或因为技术问题完全失败。
分析器某些常见的问题有:
- 粗糙的时间测量。如果以毫秒粒度测量时间,而关键函数执行需要几微妙,那么测量会变得不精确,或只是零。
- 执行时间太小或太长。如果被测试程序在短时间里完成,抽样产生太少的分析数据。如果程序执行时间太长,分析器抽样的数据超过处理的能力。
- 等待用户输入。许多程序花费大多数时间在等待用户输入或网络资源上。这个时间包括在剖面数据里。修改程序使其使用一组测试数据,而不是用户输入,以便使分析可行,可能是必要的。
- 其他进程的干扰。分析器不仅测量花在被测试程序里的时间,还有运行在同一台计算机上所有其他进程的时间,包括分析器本身。
- 在被优化的程序中,函数地址被湮没。分析器通过地址识别程序里的热点,并尝试将这些地址转换到函数名。但一个高度优化的程序通常以这样一个方式重新组织,函数名与代码地址间没有清晰的对应关系。内联的函数名对分析器完全不可见。结果将错误报告花费最多时间的函数。
- 使用代码的调试版本。某些分析器要求测试的代码包含调试信息,以识别个别函数或代码行。代码的调试版本没有优化。
- CPU核间跳转。在多核CPU上,进程或线程不一定待在同一个处理器核,但事件计数器会。这导致对在多个CPU核间跳转的线程无意义的事件计数。你可能需要通过设置线程亲和性掩码,将一个线程锁定在特定的CPU核。
- 可重现性差。程序执行的延迟可能由不可重新的随机事件导致,这样的事件,如任务切换与垃圾收集,会在随机出现,使程序部分看起来比正常需要更多时间。
有各种替代方案。一个简单的方案是在调试器里运行程序,在程序运行上按下break。如果存在一个使用90% CPU时间的热点,那么有90%的机会break出现在这个热点中。重复break几次可能足以识别一个热点。使用调试器里的调用栈来识别热点周围的环境。
有时,识别性能瓶颈最好的方式是直接将测量手段放入代码,而不是使用一个现成的分析器。这不能解决所有与性能分析相关的问题,但它通常能给出更可靠的结果。如果你对分析器工作的方式不满意,那么你可以把期望的测量手段放入程序中。你可以添加计数器变量,统计程序每部分执行的次数。另外,可以在程序最重要或最关键部分前后读取时间,测量每部分花的时间,这个方法的进一步讨论,参考第157页。
你的测量代码应该包括在#if指示里,使在代码的最终版本中可以禁止它。在代码中插入你自己的测量手段是,在程序开发期间,追踪性能的一个非常有用的手段。
时间测量可能要求一个非常高的精度,如果时间间隔很短。在Windows里,微秒精度,你可以使用GetTickCount或QueryPerformanceCounter函数。使用CPU里的时间戳计数器可以得到高得多的精度,它以CPU的时钟频率进行统计(在Windows:__rdtsc())。
如果线程在不同的CPU核间跳转,时间戳计数器变得无效。你可能不得不将线程在测量期间固定在特定的CPU核上。(Windows中SetThreadAffinityMask,Linux中sched_setaffinity)。
应该使用一个真实的测试数据集测试程序。测试数据应该包含典型程度的随机性,以得到真实次数的缓存不命中与分支误预测。
在找到程序最耗时部分时,将优化努力集中在这些耗时部分上是重要的。代码的关键部分可以第157页描述的方法进一步测试与调查。
分析器对查找与CPU密集代码相关的问题是最有用的。但许多程序使用,比进行算术操作,更多时间来载入文件或访问数据块、网络及其他资源。在下面部分里讨论最常见的时间消耗者。
3.3. 程序安装
花在安全程序包的时间传统上不视为软件优化问题。但它确实会偷走用户时间。如果软件优化的目的是为用户节省时间,安装软件包以及使其工作的时间就不能忽略。使用高度复杂的现代软件,安装工程需要超过一小时并不罕见。重装软件包几次以找出及解决兼容性问题也不罕见。
在决定软件包是否基于一个要求安全许多文件的复杂框架上时,软件开发者应该将安装时间与兼容性问题考虑进来。
安装过程应该总是使用标准化的安装工具。在一开始选择所有的安装选项,使得余下的安装过程无需照管应该是可能的。卸载也应该以一个标准化的方式进行。
3.4. 自动更新
许多软件程序定期自动通过网络下载更新。某些程序在计算机每次启动时查找更新,即使程序从来没有被使用。安装有许多这样程序的计算机会需要几分钟来启动,这完全是浪费用户的时间。其他程序每次启动时查找更新。用户可能不需要更新,如果当前版本满足用户的需要。更新的查找应该是可选的,缺省关闭,除非更新有迫切的安全原因。更新过程应该运行在一个低优先级线程中,且仅程序确实需要时。程序在不使用时,不应该在后台留下一个进程。下载程序更新的安装应该被推迟,直到关闭以及重启程序。
操作系统的更新会特别耗时。有时需要几个小时来安装操作系统的自动更新。这非常成问题,因为这些耗时的更新可能在不方便的时候,突如其来。如果用户在离开工作场所前,出于安全原因必须关闭或退出计算机,而系统在更新过程中禁止用户关机,这会是一个非常大的问题。
3.5. 程序载入
通常,载入一个程序的时间比执行它更多。对基于大运行时框架、中间码、解释器、即时编译器等的程序,载入时间可以高得令人发指,就像以Java、C#、Visual Basic等编写的程序的常态。
但即使对以编译的C++实现的程序,程序载入也会是耗时者。这通常出现在程序使用大量运行时DLL(动态链接库或共享对象)、资源文件、配置文件、帮助文档以及数据块时。在一个大程序启动时,操作系统可能不会载入它所有的模块。某些模块仅在需要时才载入,或者在RAM不足时,它们被交换到硬盘。
用户期望对简单的活动,像击键或移动鼠标,有立刻响应。对用户来说,如果因为需要从硬盘载入鼠标模块或资源文件,这样的响应延迟几秒是不可接受的。耗内存的应用强迫操作系统将内存交换到硬盘。内存交换是简单事件,如移动鼠标或击键,有不可接受长响应时间的一个常见原因。
避免过多的DLL、配置文件、资源文件、帮助文档等分散在硬盘上。几个文件,最好在与.exe文件在同一个目录里,是可接受的。
3.6. 动态链接与位置无关代码
函数库可以实现为静态库(*.lib,*.a)或动态库,也称为共享对象(*.dll,*.so)。有几个因素会使动态库比静态库慢,这些因素在下面第149页详细解释。
位置无关代码用在类Unix系统的共享对象里。Mac系统通常缺省使用位置无关代码。位置无关代码是低效的,特别在32位模式里,原因在下面的第149页解释。
3.7. 文件访问
在硬盘上读写一个文件通常需要比处理该文件中的数据多得多的时间,特别如果用户有一个扫描所有文件访问的病毒扫描器。
顺序前向访问一个文件比随机访问要更快。读写大内存块比一次读写少量比特要快。一次不要读写少于几K字节。
你可以在一个内存缓冲里镜像整个文件,在一个操作里读写它,而不是以一个非连续方式读写少量比特。
访问一个最近访问过的文件通常比第一次访问该文件要快得多。这是因为该文件已经被拷贝到硬盘缓存。
远程或可删除媒体上的文件,比如软盘与U盘,可能不能被缓存。这会有相当戏剧性的后果。我曾经制作了一个Windows程序,通过调用每写一行就会打开与关闭文件的WritePrivateProfileString创建一个文件。因为硬盘缓存,这在硬盘上工作得足够快,但向软盘写入文件时,它需要几分钟。
包含数值数据的大文件以二进制保存这些数据,比以ASCII形式更紧凑与高效。二进制保存数据的一个缺点是,它不是人类可读的,不容易移植到使用big-endian储存的系统。
在具有许多文件输入/输出操作的程序中,优化文件访问比优化CPU使用更重要。如果在等待硬盘操作完成时,处理器有其他工作可做,将文件访问放入一个单独的线程是有好处的。
3.8. 系统数据块
在Windows中,访问系统数据块需要几秒。在Windows系统中,将应用特定的信息保存在一个独立的文件里,比保存在大的注册表数据块要更高效。注意,如果你使用诸如GetPrivateProfileString及WritePrivateProfileString的函数读写配置文件(*.ini文件),系统可能将信息保存在数据库里。
3.9. 其他数据库
许多软件应用使用数据库保存用户数据。数据库会消耗大量的CPU时间、RAM与硬盘空间。在简单的情形下,以一个普通数据文件替代数据库是可能的。数据库查询通常可以通过使用索引、操作组而不是循环等来优化。优化数据库查询超出了本手册范畴,但你应该知道,优化数据库访问通常大有可为。
3.10. 图形化
图形化用户接口会使用大量的计算资源。典型地,使用一个特定的图形化框架。操作系统可能在其API中提供这样一个框架。在某些情形里,在操作系统API与应用软件间,有额外一层第三方图形化框架。这样一个额外的框架会消耗大量的额外资源。
在应用软件中,每个图形化操作被实现为对图形化库或API函数的函数调用,它们再调用一个设备驱动。图形化函数的调用是耗时的,因为它可能穿过几层,需要切换到保护模式再切回来。显然,调用画整个多边形或位图的图形化函数比,通过多次函数调用分别画每个像素或行要更高效。
计算机游戏与动画片中图形化对象的计算当然也是耗时的,特别在没有图形处理单元时。
各种图形函数库与驱动性能上差异很大。哪个最好,我没有特别的建议。
3.11. 其他系统资源
写到打印机或其他设备最好以大数据块完成,而不是一次一小块,因为对驱动的每次调用都涉及切换到保护模式,再切回来的开销。
访问系统驱动以及使用操作系统先进的设施会耗时,因为它可能涉及载入多个驱动、配置文件以及系统模块。
3.12. 网络访问
某些应用程序将因特网或内部网用于自动更新、远程帮助文档、数据库访问等。这里的问题是访问时间不能控制。在简单测试设置里,网络访问可能是快的,但在网络过载或用户远离服务器的一个使用情形里,很慢或完全不可用。
在决定在本地还是远程保存帮助文档及其他资源时,应该考虑这些问题。如果频繁的更新是必须的,那么最好在本地建立远程的数据镜像。
访问远程数据库通常要求密码登录。对许多勤奋工作的软件用户,登录过程已知是一个烦人的时间消耗者。在某些情形里,如果网络或数据库严重过载,登录过程可能超过1分钟。
3.13. 内存访问
与对数据执行计算所需时间相比,从RAM内存访问数据需要相当长的时间。这是为什么现代计算机有内存缓存的原因。典型地,有8 ~ 64K字节的1级缓存,256K到2M字节2级缓存。还可能有3级缓存。
如果程序中所有数据的总体大小超过2级缓存,且数据分散在内存里,或者以非连续的方式访问,那么内存访问很可能是程序中最大的时间消耗者。如果被缓存了,读写内存中一个变量仅需要2 ~ 3时钟周期,但如果没有缓存,则几百时钟周期。数据存储参考第26页,内存缓存参考第88页。
3.14. 上下文切换
上下文切换是在一个多任务环境中不同任务间、一个多线程程序中不同线程间,或者一个大程序里不同部分间的切换。频繁的上下文切换会降低性能,因为数据缓存、代码缓存、分支目标缓冲、分支模式历史等的内容必须被更新。
如果分配给每个任务或线程的时间片越小,上下文切换越频繁。时间片的长度由操作系统确定,不是应用程序。
在具有多个CPU或多核CPU的计算机中,上下文切换次数更少。
3.15. 依赖链
现代微处理器可以进行乱序执行。这意味着如果一段代码声明计算A、然后B,且A的计算慢,那么微处理器可以在A的计算完成前开始B的计算。当然,仅在B的计算不需要A的值时,才有可能。
为了利用乱序执行,必须避免长依赖链。依赖链是一系列计算,其中每个计算依赖前一个计算的结果。这阻止CPU同时或乱序执行多个计算。如何打破依赖链的例子,参考第105页。
3.16. 执行单元吞吐率
在执行单元的时延与吞吐率间有一个重要的区别。例如,在现代CPU上进行一次浮点加法可能需要3 ~ 5时钟周期。但每时钟周期开始一个新的浮点加法是可能的。这意味着,如果每个加法依赖前面加法的结果,那么每3时钟周期将只有一次加法。但如果加法都无关,那么每时钟周期有一次加法。
在一个计算密集程序中,在上面章节提到的时间消耗者不占支配地位,也没有长依赖链时, 可以实现最高可能的性能。在这个情形里,性能受执行单元的吞吐率限制,而不是时延或内存访问。
现代微处理器的执行核被分为几个执行单元。典型地,有两个或更多整数单元,一或两个浮点加法单元,以及一个或两个浮点乘法单元。这意味着同时进行一次整数加法、一次浮点加法及一次浮点乘法是可能的。
因此,执行浮点计算的代码最好平衡好加法与乘法。减法使用与加法相同的单元。除法需要更长的时间。不降低性能,在浮点操作间进行整数操作是可能的,因为整数操作使用不同的执行单元。例如,一个进行浮点计算的循环通常使用整数操作来递增循环计数器、比较循环计数器与上下限等。在大多数情形里,可以假定这些整数操作不会增加整体的计算时间。
以上是关于优化C++软件的主要内容,如果未能解决你的问题,请参考以下文章