Tensorflow分布式机器学习平台
Posted 帅气的小王子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow分布式机器学习平台相关的知识,希望对你有一定的参考价值。
分布式机器学习的必要性:
TF的实现分为了单机实现和分布式实现,在分布式实现中,需要实现的是对client,master,worker process不在同一台机器上时的支持。
数据量很大的情况下,单机跑深度学习程序,过于耗时,所以需要TensorFlow分布式并行。
分布式机器学习分为单机多卡训练与多机多卡训练。
单机多GPU训练:
单机多GPU的训练过程:
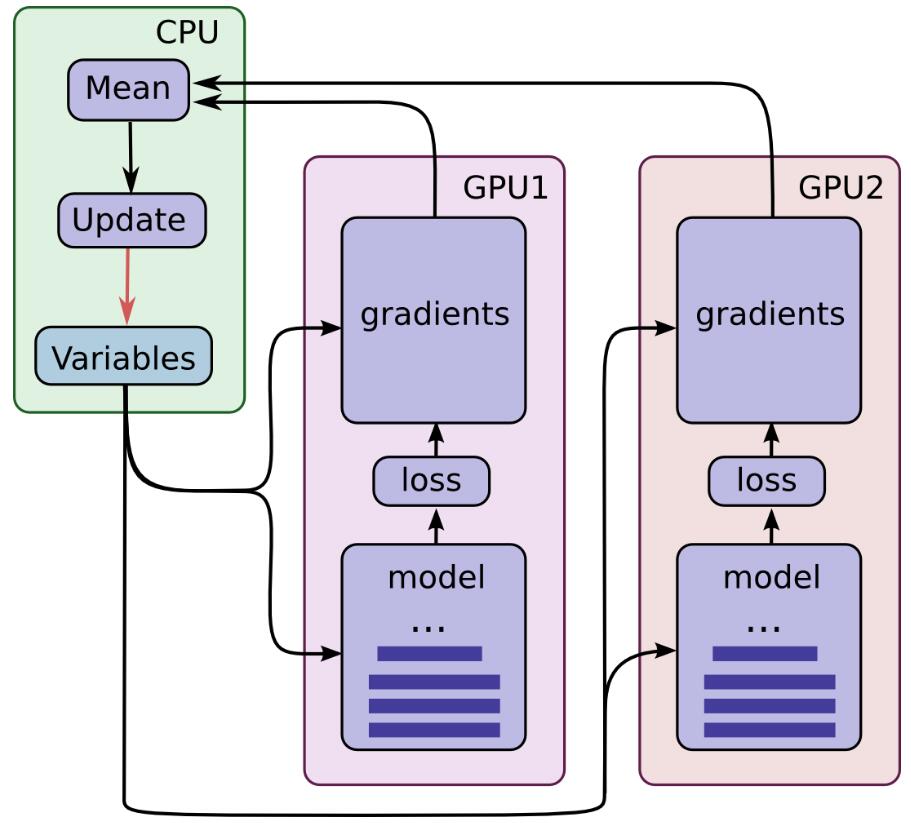
- CPU承担了调度与参数的保存与更新操作,刚开始的时候数据由CPU分发给2个GPU, 在GPU上完成了计算,得到每个batch要更新的梯度,将该梯度返回给CPU。
- 在单机单GPU的训练中,数据是一个batch一个batch的训练。 在单机多GPU中,数据一次处理2个batch(假设是2个GPU训练), 每个GPU处理一个batch的数据计算。
- 然后在CPU上收集完了2个GPU上的要更新的梯度, 计算一下平均梯度,然后更新参数。
- 然后继续循环这个过程。
通过这个过程,处理的速度取决于最慢的那个GPU的速度。如果3个GPU的处理速度差不多的话, 处理速度就相当于单机单GPU的速度的3倍减去数据在CPU和GPU之间传输的开销,实际的效率提升看CPU和GPU之间数据的速度和处理数据的大小。
多机多GPU训练:
基本概念:
Cluster、Job、task概念:三者可以简单的看成是层次关系,task可以看成每台机器上的一个进程,多个task组成job;job又有:ps、worker两种,分别用于参数服务、计算服务,组成cluster。
同步SGD与异步SGD
所谓的同步更新指的是:各个用于并行计算的电脑,计算完各自的batch 后,求取梯度值,把梯度值统一送到ps服务机器中,由ps服务机器求取梯度平均值,更新ps服务器上的参数。
如下图所示,可以看成有四台电脑,第一台电脑用于存储参数、共享参数、共享计算,可以简单的理解成内存、计算共享专用的区域,也就是ps job;另外三台电脑用于并行计算的,也就是worker task。
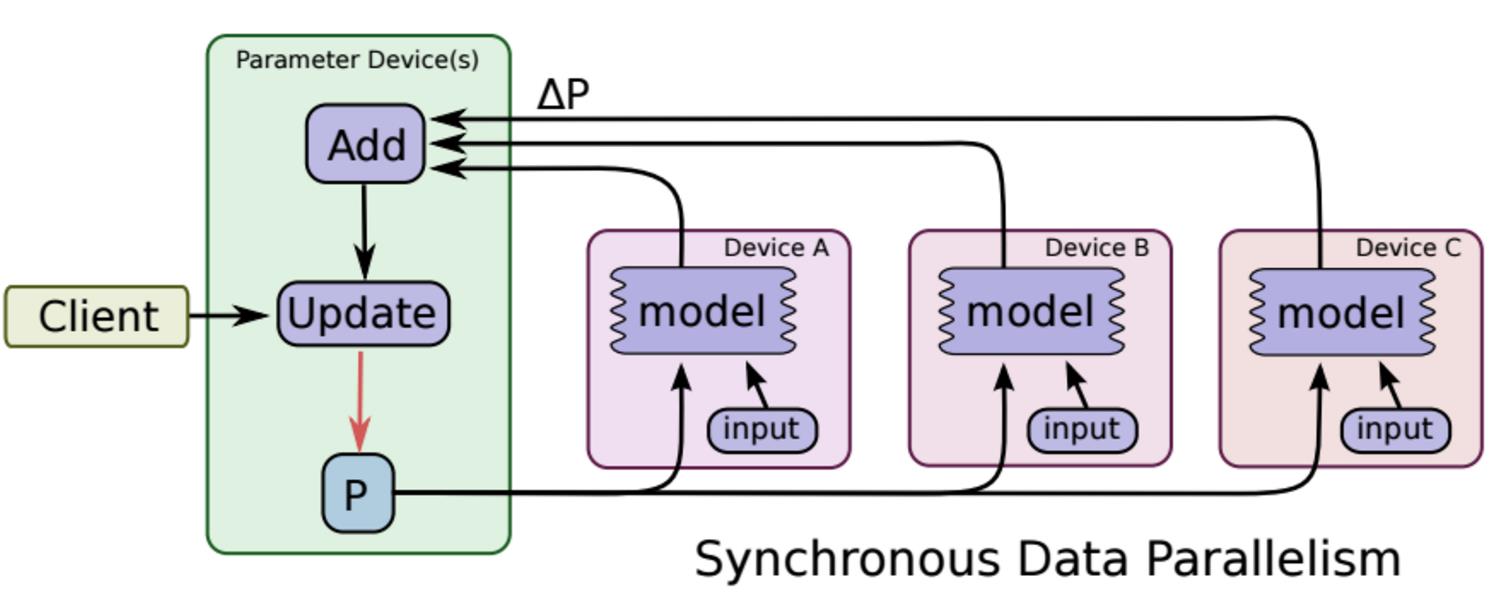
这种计算方法存在的缺陷是:每一轮的梯度更新,都要等到A、B、C三台电脑都计算完毕后,才能更新参数,也就是迭代更新速度取决与A、B、C三台中,最慢的那一台电脑,所以采用同步更新的方法,建议A、B、C三台的计算能力都不想。
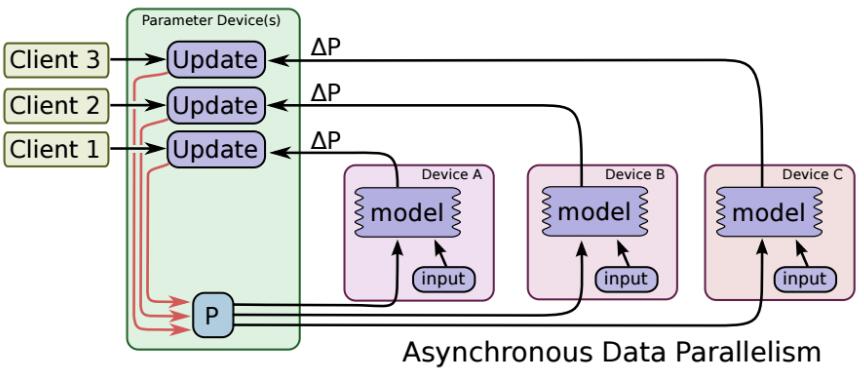
所谓的异步更新指的是:ps服务器收到只要收到一台机器的梯度值,就直接进行参数更新,无需等待其它机器。这种迭代方法比较不稳定,收敛曲线震动比较厉害,因为当A机器计算完更新了ps中的参数,可能B机器还是在用上一次迭代的旧版参数值。
TF分布式模式:
TensorFlow分布式并行基于gRPC通信框架,其中包括一个master创建Session,还有多个worker负责执行计算图中的任务。
gRPC首先是一个RPC,即远程过程调用,通俗的解释是:假设你在本机上执行一段代码num=add(a,b),它调用了一个过程 call,然后返回了一个值num,你感觉这段代码只是在本机上执行的, 但实际情况是,本机上的add方法是将参数打包发送给服务器,然后服务器运行服务器端的add方法,返回的结果再将数据打包返回给客户端.
In-graph 模式
将模型的计算图的不同部分放在不同的机器上执行
In-graph模式, 把计算已经从单机多GPU,已经扩展到了多机多GPU了, 不过数据分发还是在一个节点。 这样的好处是配置简单, 其他多机多GPU的计算节点,只要起个join操作, 暴露一个网络接口,等在那里接受任务就好了。 这些计算节点暴露出来的网络接口,使用起来就跟本机的一个GPU的使用一样, 只要在操作的时候指定tf.device(“/job:worker/task:n”), 就可以向指定GPU一样,把操作指定到一个计算节点上计算,使用起来和多GPU的类似。 但是这样的坏处是训练数据的分发依然在一个节点上, 要把训练数据分发到不同的机器上, 严重影响并发训练速度。在大数据训练的情况下, 不推荐使用这种模式。
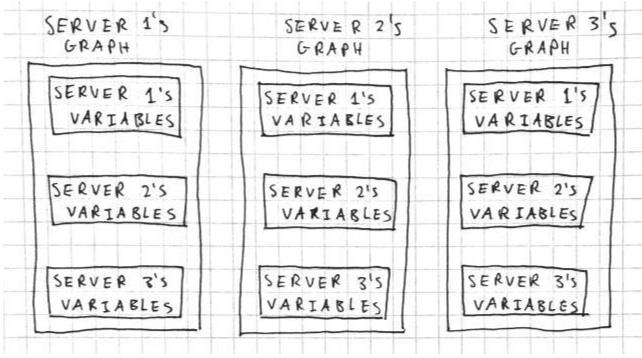
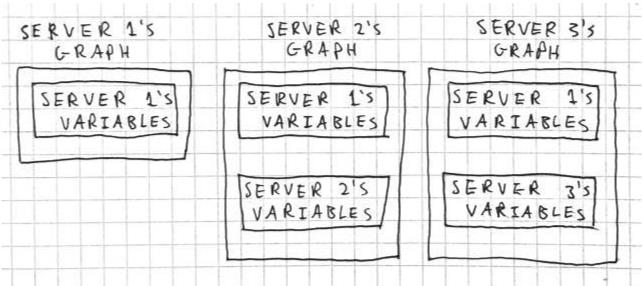
例如,假设我们有一个包含三台服务器的集群。服务器 1 保存共享参数,而服务器 2 和服务器 3 是工作站节点,每个都有本地变量。在图内复制中,每台服务器的图如下所示:
Between-graph 模式
数据并行,每台机器使用完全相同的计算图
Between-graph模式下,训练的参数保存在参数服务器, 数据不用分发, 数据分片的保存在各个计算节点, 各个计算节点自己算自己的, 算完了之后, 把要更新的参数告诉参数服务器,参数服务器更新参数。这种模式的优点是不用训练数据的分发了, 尤其是在数据量在TB级的时候, 节省了大量的时间,所以大数据深度学习还是推荐使用Between-graph模式。
在这里,每个服务器都运行一个只包含共享参数的图,而且任何变量和操作都与单个服务器相关。
Tensorflow on yarn 资管管理调度系统
关于yarn:
加入GPU资源的支持
加入GPU资源的保障
支持GPU、CPU、Memory混合资源管理调度
支持Node Label,可以指定不同的GPU型号,现在有P40和P100
支持GPU亲和性
GPU亲和性:
NodeManager维护GPU卡的拓扑关系
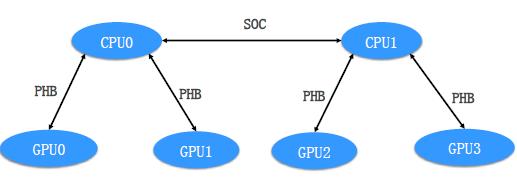
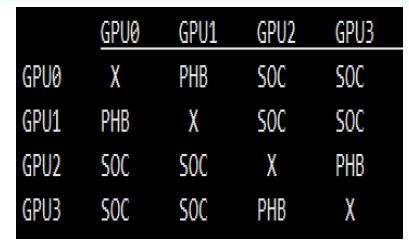
SOC:Between CPU sockets
PHB: As a PCIeHost Bridge
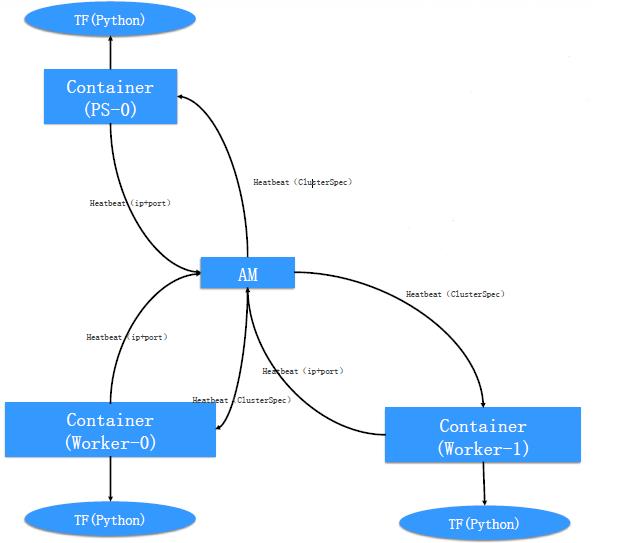
自动构建ClusterSpec:
①Container 随机bing一个端口
②通过Heartbeat告知自己的ip和端口
③AM等收到所有container的端口之后,构造好ClusterSpec通过heartbeat 告知所有container
④Container获得ClusterSpec信息之后,fork出TensorFlow的python进程
⑤说明:ClusterSpec包含ps_hosts、worker_hosts、roles、index
训练数据切分
基于文件的轮询分配(--mode-local=true)
四个文件2个worker的示例:
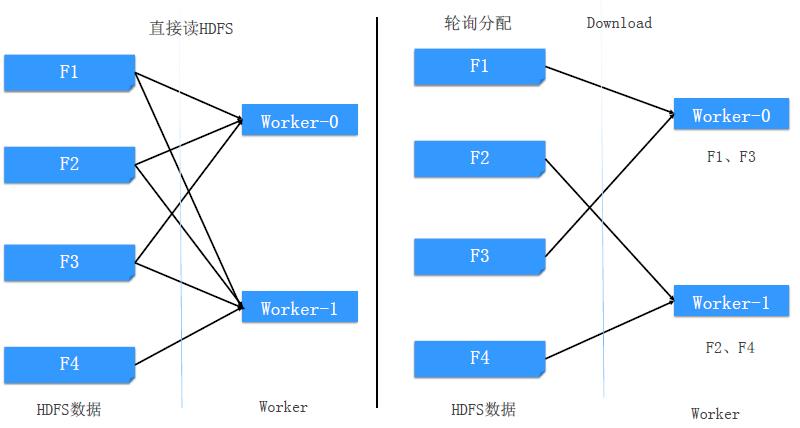
存在的问题
数据分发优化:
目前yarn平台上在做分布式训练时,是针对文件级别的分发,该级别的分发粒度明显不够细,如果文件数量小于worker数量,可能会导致某些worker没有分得文件,还有其他问题等等。
因此希望能做到更细粒度的分发,支持以数据条目为粒度的分发,这样能保证所有worker都能均匀的得到训练数据。
更进一步的,现在的数据分发仅在训练开始时进行分发,每个worker得到的数据是固定的,那么可能会存在“盲人摸象”的问题,如果能够实现在每个loop进行数据的分发,也许可以得到更好的训练效果。
但是这对分发的效率有着极高的要求,因此分发效率的提升也很重要。
最后,在做数据分发时是否进行shuffle,如何shuffle也值得考虑。
内存的智能申请:
目前yarn平台上在提交训练任务时,需要手动指定每个worker所需内存大小,当内存不足够训练时,任务会被终止,需要重新提交训练任务,因此大多数人在提交任务时会尽可能申请更多的内存,
然而这种做法会带来一个问题,就是对资源的浪费,当GPU卡的资源还有剩余时,但因为其他任务对内存资源的过量申请,导致剩余的GPU卡不可用。
如果能够由yarn平台自动分配内存,取代用户手动设置,则可以避免该问题,保证资源的合理分配,使得内存和GPU充分利用。
TF对于RDMA的支持不完善:
Tensorflow分配要传输或接收的tensor内存时候采取了动态分配,这就非常不利于RDMA传输,RDMA传输进行之前需要注册内存,而注册内存的调用性能代价很大,动态分配内存意味着频繁的注册内存,性能开销很大。
为了适应tensorflow gRPC通信的Rendezvous协议,RDMA建立一个中间层cache来存放tensor的一些元信息,比如shape, data-type等,并放在了sender端,而Rendezvous协议要求receiver主动发起传输,则receiver首选需要拿到这些元信息才能通信。并且,过程中元信息还有可能更新。这些都是额外的通信开销。
Tensorflow RDMA通信的通道不可以一次发送多个消息,本次RDMA_WRITE完成前,通道不可以再被使用;因此Tensorflow采用了两个状态变量来控制和约束,增加了额外的处理和负担
TF的水平扩展能力差:
在大部分模型的性能测试中,我们发现随着数据并行度的增加,单个worker的样本处理QPS急剧下降。当worker数量增大到一定规模的时候,系统整体QPS不再有增长甚至有所下降。
缺乏完备的分布式Failover机制:
TF基于静态拓扑配置来构建cluster,不支持动态组网,这就意味着当某个ps或者worker挂掉重启之后,如果ip或者端口发生变化(例如机器crash),训练将无法继续。另外TF的checkpoint只包含server存储的参数信息,不包含worker端的状态,不是全局一致性的checkpoint,无法实现Exactly-Once等基本的Failover语义。
Reference:
https://mp.weixin.qq.com/s/yuHavuGTYMH5JDC_1fnjcg
以上是关于Tensorflow分布式机器学习平台的主要内容,如果未能解决你的问题,请参考以下文章