IO进化史:BIONIO多路复用selectpollepoll
Posted java叶新东老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IO进化史:BIONIO多路复用selectpollepoll相关的知识,希望对你有一定的参考价值。
什么是IO
input 和 output的简写,意思是输入和输出;也可以是读取(read)或者写入(write);当应用程序需要读或者写数据时都是往内存中进行读写操作的;在由CPU将内存中的数据通过IO传输到外围设备,比如网卡、磁盘、键盘、鼠标、显卡等等;而操作系统给出了相应的读写接口,供应用程序调用;表面上是进行了IO操作,本质上其实是应用程序和内核的交互。
为什么要学习IO
我们在敲代码的时候,往往都是开发上层应用,像CPU、内存、网卡以及其他的外围设备的通讯操作系统已经帮我们实现了;并且Java的JDK又封装了一层,到开发者这边用起来就显得非常简便;这样的话,开发者就不知道操作系统内部是如何运作的;只是现在开始互联网的从业人员越来越多,导致的一个现象就是企业对开发者的要求越来越高了,虽然这些技术用不到,但是在面试的时候也会问到这些知识点;并且,如果你是从事网络相关的开发,或者是高级工程师的话,就必须对IO有所了解,知己知彼,方能百战百胜嘛!
在计算机中,无论上层技术多么复杂,底层的io模型其实就一套;所以越早学习底层,上层的学习就越轻松;
用户态与内核态
Kernel 运行在超级权限模式(Supervisor Mode)下,所以拥有很高的权限。按照权限管理的原则,多数应用程序应该运行在最小权限下。因此,很多操作系统,将内存分成了两个区域:
- 内核空间(Kernal Space),这个空间只有内核程序可以访问;内核空间中的代码可以访问所有内存,我们称这些程序在内核态(Kernal Mode) 执行;
- 用户空间(User Space),这部分内存专门给应用程序使用。用户空间中的代码被限制了只能使用一个局部的内存空间,我们说这些程序在用户态(User Mode) 执行;
所有用户程序都是运行在用户态的, 但是有时候程序确实需要做一些内核态的事情, 例如从硬盘读取数据, 或者从键盘获取输入等. 而唯一可以做这些事情的就是操作系统, 所以此时程序就需要先操作系统请求以程序的名义来执行这些操作,这时需要一个这样的机制: 用户态程序切换到内核态, 但是不能控制在内核态中执行的指令,这种机制叫系统调用。
IO的分类
IO分为两类,它们之间是有区别的,而且有很大的区别;
1. 文件系统的IO
也叫本地io,就是和磁盘或者外围存储设备进行读写操作,外围设备有USB、移动硬盘等等;
2. 网络的IO
将数据发送给对方 和 读取对方的数据就称为网络IO;
网络IO是如何连接的?
网络IO就是本机的应用程序对着内核的缓冲区读写的过程,发送数据时应用程序会将数据复制到内核态的写队列中,再由内核将数据复制到网卡,然后进行发送;读取数据则反过来,网卡接受到数据后将数据复制到内核态的读队列中,在通知应用程序来获取数据;

读队列(Receive queue) 和 写队列(Send queue)
Q是Queue的缩写,在linux控制台输入命令netstat -anp | head会展示以下信息
[root@zayhu01-mb ~]# netstat -anp | head
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2742/sshd
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 29931/ruby
Recv-Q:网络接收队列,表示收到的数据已经在本地接收缓冲,但是还有多少没有被进程取走Send-Q:发送队列,对方没有收到的数据或者说没有Ack的,数据还是存在本地缓冲区
当我们调用java IO的write()方法后,都是将数据先写到send-Q里面的,
Recv-Q和Send-Q都是内核级别的队列,这两个值通常应该为0,如果不为0可能是有问题的。packets在两个队列里都不应该有堆积状态。可接受短暂的非0情况。
如果接收队列Recv-Q一直处于阻塞状态,可能是遭受了拒绝服务 denial-of-service ***。如果发送队列Send-Q不能很快的清零,可能是有应用向外发送数据包过快,或者是对方接收数据包不够快。
网络IO的分类
- 同步: 由app自己进行读和写
- 异步:由内核完成读写,app没有访问io,只访问了缓冲区(buffer),异步都是用回调的方式进行读写的,类似支付的回调方式,目前只有windows实现了异步io
- 阻塞: blocking
- 非阻塞: non-blocking
他们可以组合成以下几种方式
- 同步阻塞:就是拿一个个不能响的水壶烧水,你要一直等着 ( BIO)
- 同步非阻塞:就是你定时来看这个水烧开了没有( NIO)
- 异步非阻塞:就是你买了能响的水壶,水开了它自己会响(异步非阻塞 AIO)
注意:没有异步非阻塞的模型,你都异步了还要阻塞干嘛呢!是吧?没必要!
BIO
BIO为同步阻塞IO,blocking queue的简写,也就是说多线程情况下只有一个线程操作内核的queue,当前线程操作完queue后,才能给下一个线程操作;
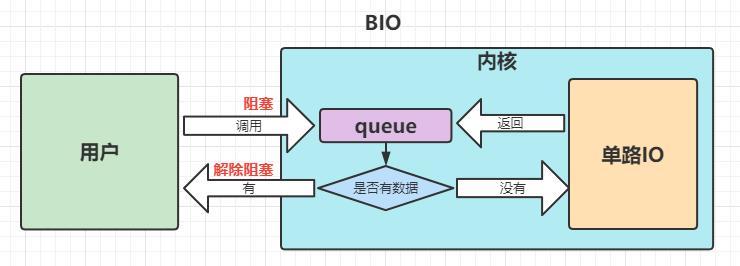
举个例子:
- 一个人去 商店买一把菜刀,他到商店问老板有没有菜刀(发起系统调用)
- 如果有(表示在内核缓冲区有需要的数据)老板直接把菜刀给买家(从内核缓冲区拷贝到用户缓冲区)这个过程买家一直在等待
- 如果没有,商店老板会向工厂下订单(IO操作,等待数据准备好)
- 工厂把菜刀运给老板(进入到内核缓冲区)
- 老板把菜刀给买家(从内核缓冲区拷贝到用户缓冲区)
这个过程买家一直在等待,所以称为同步io
在BIO下,一个连接就对应一个线程,如果连接特别多的情况下,就会有特别多的线程,很费线程;在早期的时候,世界上的计算机还很少,网站也少,会上网的人更是寥寥无几,并发最高的时候也就几十上百个,所以当并发量不高的情况下,BIO也够用了;
NIO (流程图)
Non-blocking IO的简写,同步非阻塞IO,内核发生了变化,app访问内核的缓冲区时不会阻塞,但是返回值需要用户自己判断;如果连接数特别多的i情况下,就需要应用程序不停遍历,一个个进行状态的判断,询问是否有数据到达;
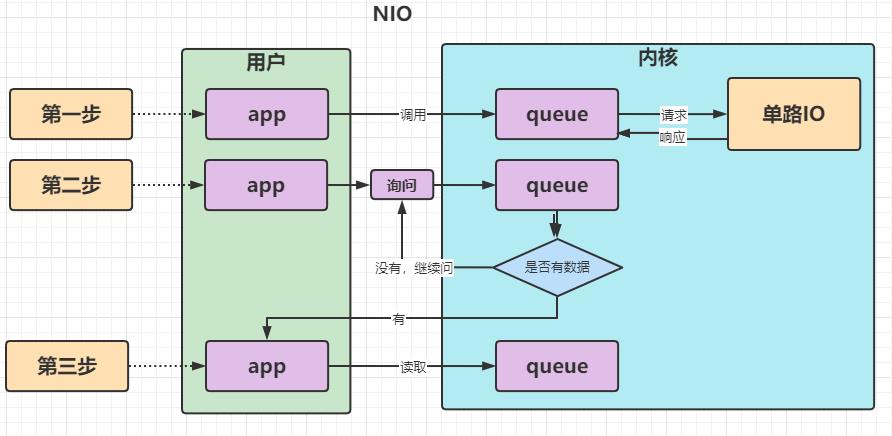
举个例子:
- 一个人去 商店买一把菜刀,他到商店问老板有没有菜刀(发起系统调用)
- 老板说没有,在向工厂进货(返回状态)
- 买家去别地方玩了会,又回来问,菜刀到了么(发起系统调用)老板说还没有(返回状态)
- 买家又去玩了会(不断轮询)
- 最后一次再问,菜刀有了(数据准备好了)
- 老板把菜刀递给买家(从内核缓冲区拷贝到用户缓冲区)
整个过程轮询+等待:轮询时没有等待,可以做其他事,从内核缓冲区拷贝到用户缓冲区需要等待是同步io
2.1.2 NIO的分类
NIO有2个种类
- Non-blocking IO 指的是非阻塞IO
- new IO ,是指java.nio包,这两者不是同一类的东西,千万不要混淆;
NIO出现的问题
NIO 每次都需要应用程序自己去调用每一条管道来判断是否有数据返回,这样无形中就多了很多次系统调用,而里面有一些系统调用不是必须要的,所以,为了解决这个问题,就衍生出了一种新的技术:多路复用
多路复用
NIO同一时间只能访问一个文件描述符,而这些操作都是在用户态进行操作的,这样一来,就需要应用程序不停的循环遍历,占用了资源,效率也非常低下,所以衍生出了一个新技术,多路复用,多路复用可以同时监听多个文件描述符,并且监听的工作都是由内核态完成的,如果有某一个连接有数据到达了,会将有数据的连接告诉应用程序,应用程序这边只需要区连接里拿数据就可以了;
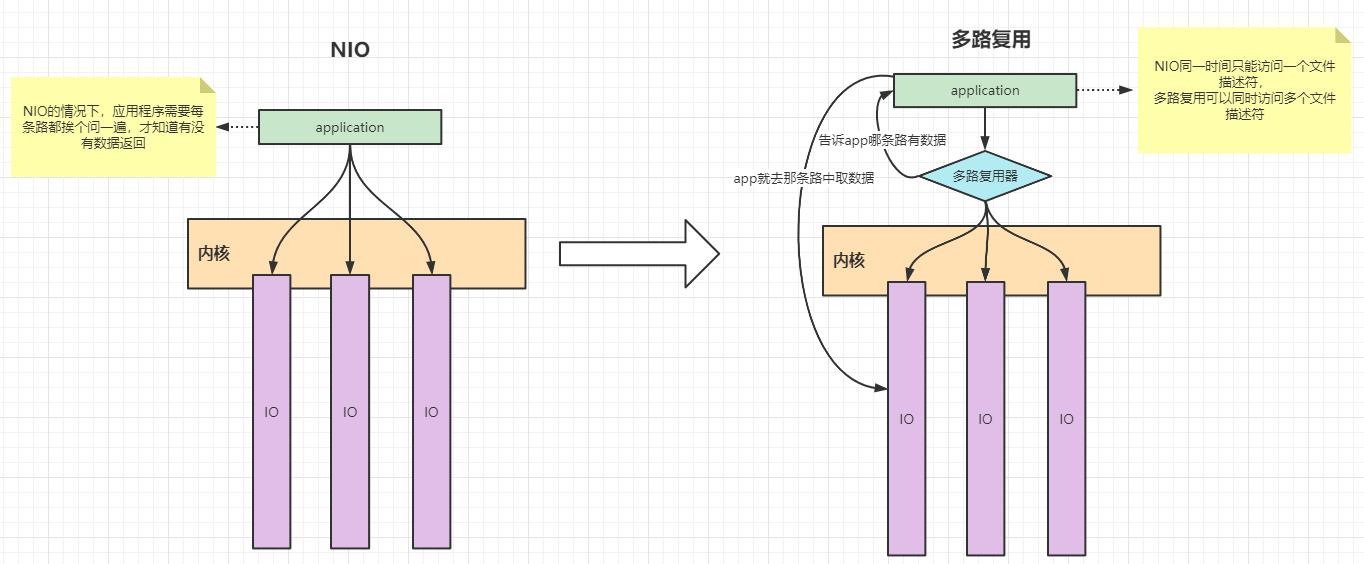
常见的多路复用有三个模型,分别是 select 、poll、epoll;接下来我们一个个介绍;
select
select可以同时监听多个连接,但是一个select监听的路数量有限制(一般是1024个),如果有2048个请求,就得用2个select,每次调用select时都会在内核态中遍历这些文件描述符,来判断连接状态,看看是否有数据返回;

poll
poll和selelct的机制是一样的,poll是selelct的升级版。最主要的区别就是poll监听的路数量没有限制;其他的基本都一样;
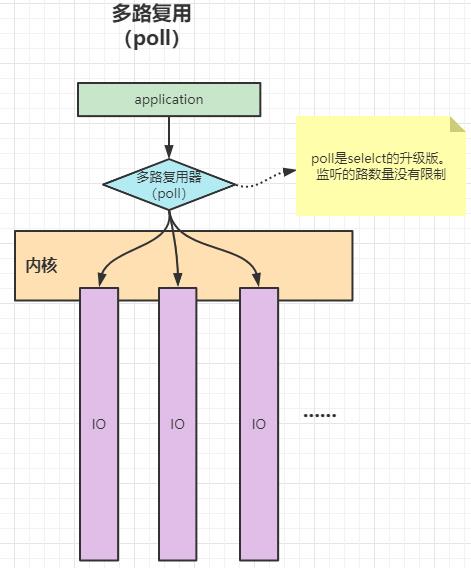
**其实无论是NIO、select、还是poll,都是要遍历所有的IO,来询问状态,通过状态来判断是否有数据返回; **
- NIO:只是NIO的遍历过程中它成本更高,因为它需要在用户态和内核态之间不停地切换;先在用户态进行请求,然后在内核态进行遍历,将遍历的结果在返回给用户态, 就这样来回不断地切换;
- select、poll: 遍历过程中触发了一次系统调用,将文件描述符传递给内核,由内核进行遍历和修改状态;
select 和poll的弊端
- 每次都要重新传递fds(文件描述符)
- 每次内核被调用之后,都会触发一个遍历fds的全量复杂度;
epoll
epoll可以有效规避遍历,它和select/poll最大的区别是 epoll不需要去遍历文件描述符,它在内核态使用中断机制就已经将就绪的连接给筛选出来了;所以,程序只要调用epoll_wait()方法,就能及时取走已就绪的连接;

注意:epoll只在liunx里有,windows不支持epoll
redis的底层就是用epoll多路复用器,所以它的速度非常快;epoll主要有三个方法,分别是
epoll_create: 创建小本本,调用后会返回一个文件描述符;这个文件描述符在内部是一个红黑树epoll_ctl:在刚刚创建的小本本上添加socket的连接信息,可以添加多个;添加的连接会加到红黑树里面;epoll_wait:有消息了吗? 调用此方法后会进入阻塞,等待返回数据,会返回一个就绪链表,这个链表里面的连接都是已经有结果的了,epoll_wait返回的就是这个就绪链表;
epoll没有去遍历红黑树,那它怎么知道哪些连接已经就绪了呢?
在内部使用了内核的中断机制,当树中某个一个连接发送请求给网卡之后,网卡就会去请求了,当对方发送数据过来之后,网卡会触发中断机制,发送一个中断信号给内核,内核收到这个信号之后会先去更新文件描述符的buffer缓冲区,把网卡的数据复制到buffer缓冲区,然后在将数据复制到就绪队列;
mmap
mmap是用来实现用户态和内核态的内存共享的;
epoll早期版本是没有epoll_create、epoll_ctl、epoll_wait这三个方法的,所以传递参数就用到了mmap,但是后来有了这三个方法之后,就不需要mmap了,用户和内核直接传递参数的
ET和LT
- ET:(边缘触发),基于事件回调的方式,将就绪的socket连接以回调的方式通知app,这种方式更加高效,nginx用的就是ET
- LT: (条件触发),基于传统的阻塞方法,只通知就绪的socket链接,redis使用的就是LT;
以上是关于IO进化史:BIONIO多路复用selectpollepoll的主要内容,如果未能解决你的问题,请参考以下文章