分类器组合方法Bootstrap, Boosting, Bagging, 随机森林
Posted Maggie张张
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分类器组合方法Bootstrap, Boosting, Bagging, 随机森林相关的知识,希望对你有一定的参考价值。
接《分类器组合方法Bootstrap, Boosting, Bagging, 随机森林(一) 》
Adaboost
Adaboost给每个基分类器设置了一个重要性参数α,基分类器的重要性参数α是训练误差的的函数,错误率越接近于1,则α有一个很大的负值,如果错误率接近于0,则有一个很大的正值。接下来,用α更新训练样本的权值。
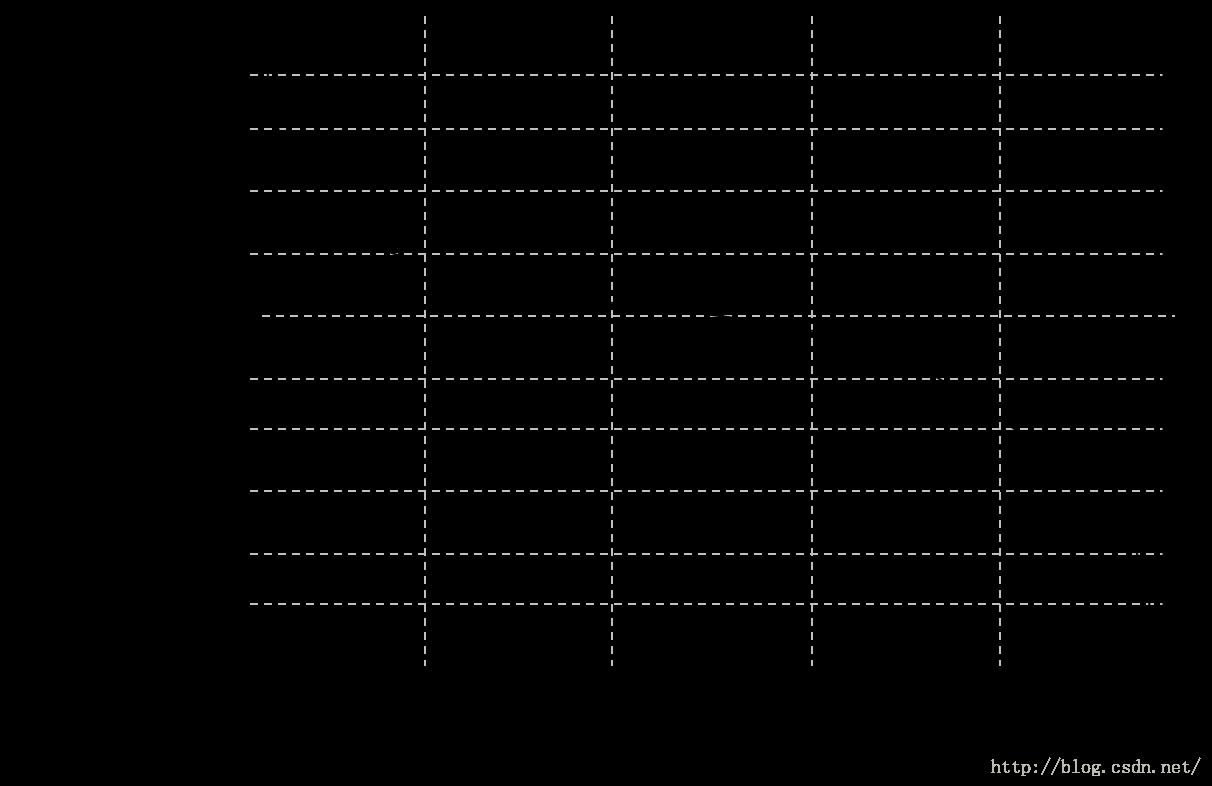
权值更新公式用来增加那些被错误分类地样本的权值,并减少那些已经被正确分类的样本的权值。
之前Bagging算法中,样本最终的预测结果是根据基分类器的预测结果投票表决产生的,但是Adaboost不是这样,它是根据基分类器的重要性参数α得到的,这样有助于Adaboost惩罚那些准确率很差的模型。
另外,如果任何中间轮产生高于50%的误差,则权值被统一设置为原始值1/N,并重新进行抽样。

算法步骤如下:

举个例子,依然是之前的例子,有10个样本,每个样本有1个属性值。




随机森林
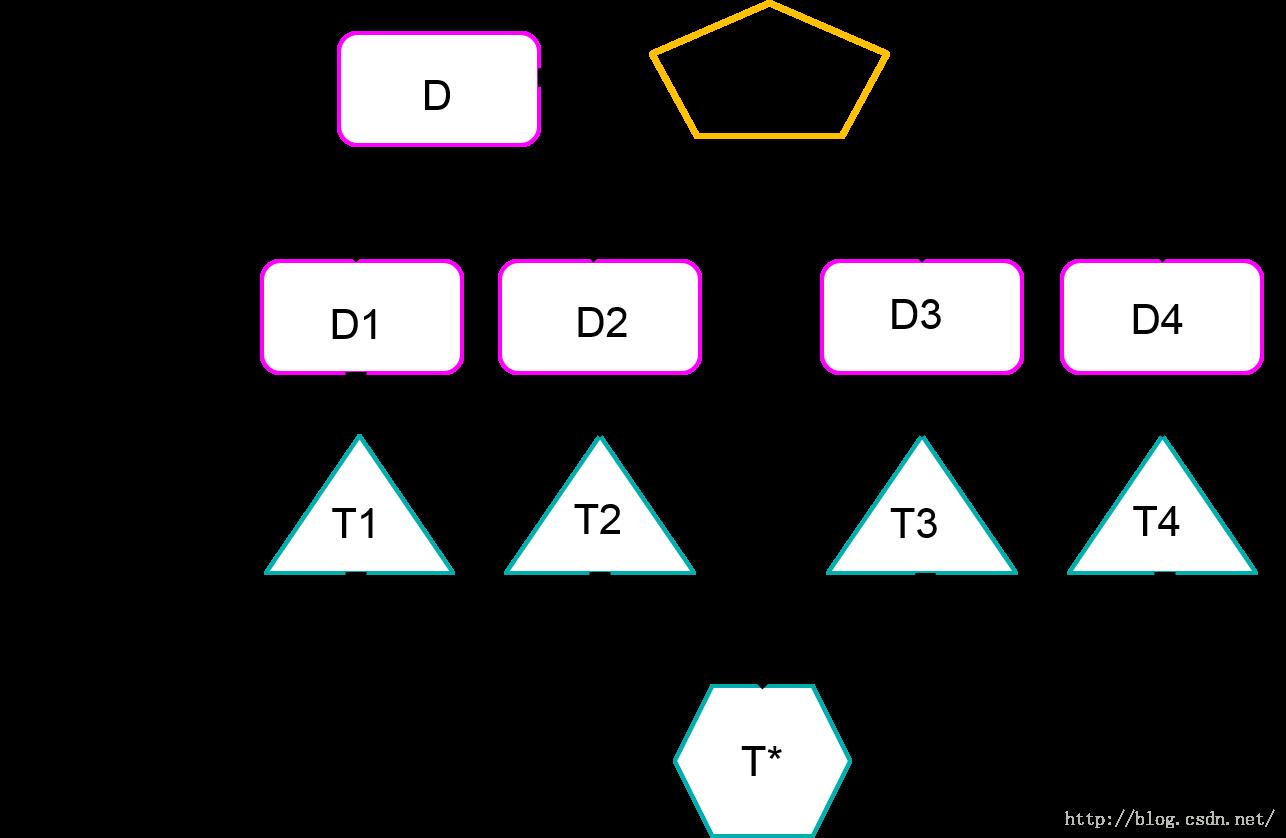
RF 是一类专门用决策树分类器设计的组合方法。 也就是说,随机森林这种组合方法中,基分类器选定了就是决策树。每一棵树建立的过程中所选用的属性都是原始样本所有属性的随机子集。 决策树之前讲过,以 ID3 为例的话,结点的分裂是要选择信息增益最大的那个属性进行分裂的,而计算信息增益的时候,考虑的是全部的属性的信息增益,所以树的增长依靠的是全部属性共同的贡献; 但是RF不一样,每棵树在增长的时候,依靠的只是所有属性中的一部分。
这个图表现的就是随机森林的模式。。。然后每个测试样本的标签是通过基分类器得到的结果举手投票得到的。

以上是关于分类器组合方法Bootstrap, Boosting, Bagging, 随机森林的主要内容,如果未能解决你的问题,请参考以下文章