kubernetes 源码分析之节点异常时 pod 驱逐过程
Posted 回归心灵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kubernetes 源码分析之节点异常时 pod 驱逐过程相关的知识,希望对你有一定的参考价值。
概述
在 Kubernetes 集群中,当节点由于某些原因(网络、宕机等)不能正常工作时会被认定为不可用状态(Unknown 或者 False 状态),当时间超过了 pod-eviction-timeout 值时,那么节点上的所有 Pod 都会被节点控制器计划删除。
详细分析
Kubernetes 集群中有一个节点生命周期控制器:node_lifecycle_controller.go。它会与每一个节点上的 kubelet 进行通信,以收集各个节点已经节点上容器的相关状态信息。当超出一定时间后不能与 kubelet 通信,那么就会标记该节点为 Unknown 状态。并且节点生命周期控制器会自动创建代表状况的污点,用于防止调度器调度 pod 到该节点。
那么 Unknown 状态的节点上已经运行的 pod 会怎么处理呢?节点上的所有 Pod 都会被污点管理器(taint_manager.go)计划删除。而在节点被认定为不可用状态到删除节点上的 Pod 之间是有一段时间的,这段时间被称为容忍度。你可以通过下面的方式来配置容忍度的时间长短:
tolerations:
- key: node.kubernetes.io/not-ready
operator: Exists
effect: NoExecute
tolerationSeconds: 180
- key: node.kubernetes.io/unreachable
operator: Exists
effect: NoExecute
tolerationSeconds: 180
如果在不配置的情况下,Kubernetes 会自动给 Pod 添加一个 key 为 node.kubernetes.io/not-ready 的容忍度 并配置 tolerationSeconds=300,同样,Kubernetes 会给 Pod 添加一个 key 为 node.kubernetes.io/unreachable 的容忍度 并配置 tolerationSeconds=300。从 Kubernetes 源码中也可找到相应的配置:
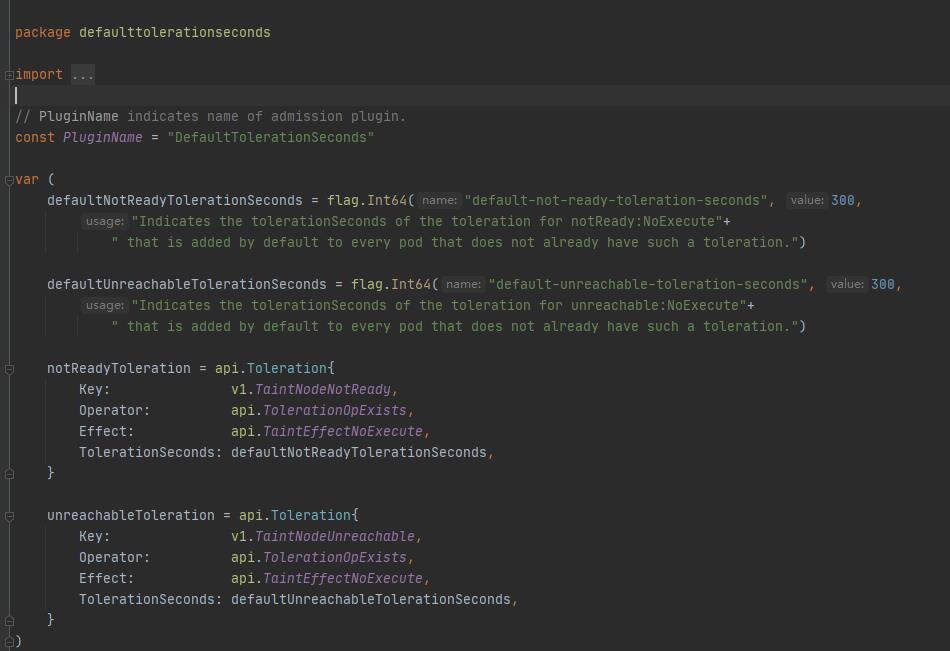
当到了删除 Pod 时,污点管理器会创建污点标记事件,然后驱逐 pod 。这里需要注意的是由于已经不能与 kubelet 通信,所以该节点上的 Pod 在管理后台看到的是处于灰色标记,但是此时如果去获取 pod 的状态其实还是处于 Running 状态。每种类型的资源都有相应的资源控制器(Controller),例如:deployment_controller.go、stateful_set_control.go。每种控制器都在监听资源变化,从而做出相应的动作执行。deployment 控制器在监听到 Pod 被驱逐后会创建一个新的 Pod 出来,但是 Statefulset 控制器并不会创建出新的 Pod,原因是因为它可能会违反 StatefulSet 固有的至多一个的语义,可能出现具有相同身份的多个成员,这将可能是灾难性的,并且可能导致数据丢失。具体的原因请看官方文档: 强制删除 StatefulSet 类型的 Pods
源码分析
下面将从代码的角度去分析 Pod 驱逐过程中的一些关键步骤。
节点容忍度时间的选择
在污点管理器 taint_manager.go 文件中有一个 processPodOnNode 方法,该方法就是当节点状态变化时处理节点上 Pod 的过程。代码如下:
func (tc *NoExecuteTaintManager) processPodOnNode(
podNamespacedName types.NamespacedName,
nodeName string,
tolerations []v1.Toleration,
taints []v1.Taint,
now time.Time,
)
if len(taints) == 0
tc.cancelWorkWithEvent(podNamespacedName)
allTolerated, usedTolerations := v1helper.GetMatchingTolerations(taints, tolerations)
if !allTolerated
klog.V(2).Infof("Not all taints are tolerated after update for Pod %v on %v", podNamespacedName.String(), nodeName)
// We're canceling scheduled work (if any), as we're going to delete the Pod right away.
tc.cancelWorkWithEvent(podNamespacedName)
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), time.Now(), time.Now())
return
minTolerationTime := getMinTolerationTime(usedTolerations)
// getMinTolerationTime returns negative value to denote infinite toleration.
if minTolerationTime < 0
klog.V(4).Infof("New tolerations for %v tolerate forever. Scheduled deletion won't be cancelled if already scheduled.", podNamespacedName.String())
return
startTime := now
triggerTime := startTime.Add(minTolerationTime)
scheduledEviction := tc.taintEvictionQueue.GetWorkerUnsafe(podNamespacedName.String())
if scheduledEviction != nil
startTime = scheduledEviction.CreatedAt
if startTime.Add(minTolerationTime).Before(triggerTime)
return
tc.cancelWorkWithEvent(podNamespacedName)
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), startTime, triggerTime)
其中 minTolerationTime := getMinTolerationTime(usedTolerations) 语句是用于获取驱逐时间的,方法的内容主要是获取之前编排文件中配置的容忍度(tolerations)相关的属性,找出最小值返回。其内容如下:
// getMinTolerationTime returns minimal toleration time from the given slice, or -1 if it's infinite.
func getMinTolerationTime(tolerations []v1.Toleration) time.Duration
minTolerationTime := int64(math.MaxInt64)
if len(tolerations) == 0
return 0
for i := range tolerations
if tolerations[i].TolerationSeconds != nil
tolerationSeconds := *(tolerations[i].TolerationSeconds)
if tolerationSeconds <= 0
return 0
else if tolerationSeconds < minTolerationTime
minTolerationTime = tolerationSeconds
if minTolerationTime == int64(math.MaxInt64)
return -1
return time.Duration(minTolerationTime) * time.Second
Pod 驱逐处理
在 processPodOnNode 方法的最后一行会把要驱逐的 Pod 信息添加到污点驱逐队列(taintEvictionQueue)中,指定创建时间(now)和触发时间(now + minTolerationTime)。
tc.taintEvictionQueue.AddWork(NewWorkArgs(podNamespacedName.Name, podNamespacedName.Namespace), startTime, triggerTime)
污点驱逐队列是一个 TimedWorkerQueue 类型的对象,该类型有一个定时器和处理函数,当到达触发时间时就会执行处理函数。那么 Pod 的驱逐处理也将在 minTolerationTime 秒后被执行。
Pod 的删除逻辑主要在 deletePodHandler 函数中,改函数主要是产生一个 Pod 被污点标记删除事件,然后请求删除 Pod。其代码如下:
func deletePodHandler(c clientset.Interface, emitEventFunc func(types.NamespacedName)) func(args *WorkArgs) error
return func(args *WorkArgs) error
ns := args.NamespacedName.Namespace
name := args.NamespacedName.Name
klog.V(0).Infof("NoExecuteTaintManager is deleting Pod: %v", args.NamespacedName.String())
if emitEventFunc != nil
emitEventFunc(args.NamespacedName)
var err error
for i := 0; i < retries; i++
err = c.CoreV1().Pods(ns).Delete(name, &metav1.DeleteOptions)
if err == nil
break
time.Sleep(10 * time.Millisecond)
return err
污点标记删除事件的语句是 emitEventFunc(args.NamespacedName) ,它会产生一个 Marking for deletion Pod %s 事件,在 Kubernetes 的管理后台也能看到。其代码如下:
func (tc *NoExecuteTaintManager) emitPodDeletionEvent(nsName types.NamespacedName)
if tc.recorder == nil
return
ref := &v1.ObjectReference
Kind: "Pod",
Name: nsName.Name,
Namespace: nsName.Namespace,
tc.recorder.Eventf(ref, v1.EventTypeNormal, "TaintManagerEviction", "Marking for deletion Pod %s", nsName.String())
总结
本文主要介绍了在节点异常时 Pod 被驱逐的过程,先总体介绍了驱逐过程,主要是节点生命周期控制器与节点上 kubelet 通信收集相关状态信息,在一定时间无法通信后认为该节点不可用,然后污点管理器就会执行相关驱逐Pod 的逻辑。后面又结合源码进行的具体详细的分析,希望对你有用。
参考
以上是关于kubernetes 源码分析之节点异常时 pod 驱逐过程的主要内容,如果未能解决你的问题,请参考以下文章