MySQL语句详解(最详细)
Posted ღ᭄小艾ヅ࿐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL语句详解(最详细)相关的知识,希望对你有一定的参考价值。
目录:
- 一、SQL语句的分类:
- 二、mysql中如何求帮助?
- 三、SQL语句的基本操作:
- 四、SQL查询语句(重点):
一、SQL语句的分类:
1.DDL(Data Definition Languages)语句:
数据定义语言 ,这些语句定义了不同的数据段,数据库,表,列,索引等数据库对象的定义。常用的语句关键字主要包括:create,drop,alter,rename,truncate
2.DML(Data Manipulation Languages)语句:
数据操纵语句 ,用于添加,删除,更新和查询数据库记录,并检查数据完整性,常用的语句关键字有:insert,delete,update等等
3.DCL(Data Control Languages)语句:
数据控制语句 ,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库,表,字段,用户的访问权限和安全级别。主要的语句的关键字包括:grant,revoke等等
4.DQL(Data Query Languages)语句:
数据查询语句 ,用于从一个或多个表中检索信息。主要的语句关键字包括:select
二、mysql中如何求帮助?
- 查看官方文档(软件作用)
- man手册(工具作用)
- mysql的命令行求帮助(主要针对SQL语句求帮助)
三、SQL语句的基本操作:
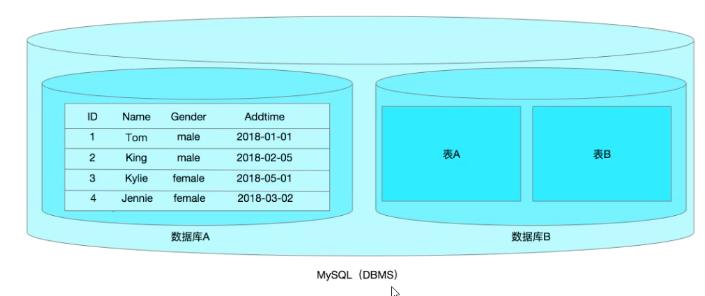
1.mysql的内部结构:
注:我们平常说的MySQL,其实主要指的是MySQL数据库管理系统
- 一个MySQL DBMS可以同时存放多个数据库,理论上一个项目就对应一个数据库
- 一个 数据库中还可以同时包含多个数据表,而数据表才是真正用于存放数据的位置
- 理论上一个功能就对应一个数据表
- 一个数据表又可以拆分成多个字段,每个字段就是一个属性
- 一个数据表除了字段以外,还有很多行,每一行都是一条完整的数据(记录)
2.数据库的基本操作:
①.创建数据库:
- 基本语法:
create database 数据库名称;
特别注意:在mysql中,当一条SQL语句编写完毕后,一定要使用分号;进行结尾,否则系统认为这条语句还没有结束。
- 创建数据库代db1,并同时指定编码格式
create database db1 default charset=utf8;
- 如果存在不报错(if not exists)
create database if not exists db1 default charset=utf8;
说明:不能创建相同名字的数据库!
- 扩展:编码格式:常见的gbk(中国的编码格式)与utf8(国际通用编码格式),后来5.6版本以后又进行了升级utf8mb4
②.查询已创建数据库:
- 基本语法:
- 显示所有数据库:
show databases;- 显示某个数据库的数据结构:
show create database 数据库名称;
③.修改数据库信息:
在MySQL5以后的版本中,MySQL不支持更改数据库的名称。我们所谓的修改数据库主要修改的是数据库的编码格式
- 基本语法:
- alter database数据库名称 default charset=新的编码格式;
④.删除数据库:
- 基本语法:
drop database 数据库名称;
3.数据表的基本操作:
①.数据表的创建:
- 基本语法:
create table 数据表名称(
字段1 字段类型 [字段约束],
字段2 字段类型 [字段约束],
…
);
- 案例:创建一个admin管理员表,拥有三个字段(编号,用户名称,用户密码)
mysql> use 数据库名称; #use在MySQL中的含义代表选择,use数据库名称相当于选择指定的数据库
mysql> create table tb_admin(
id tinyint,
username varchar(20),
password char(32)
) engine=innodb default charset=utf8;;
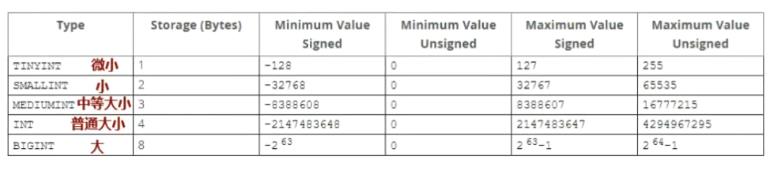
- tinyint:微整型,范围-128 ~ 127,无符号型,则表示0 ~ 255
- 表示字符串类型可以使用char与varchar,char代表固定长度的字段,varchar代表变化长度的字段
- text:文本类型,一般情况下,用varchar存储不了的字符串信息,都建议使用text文本进行处理
②.查询已创建数据表:
mysql> use 数据库名称;
mysql> show tables #显示所有数据表(当前数据库)
#显示数据表的创建过程(编码格式,字段等等信息)
mysql> show create table 数据表名称;
或
mysql> desc 数据表名称;
③.修改数据表信息:
1).数据表字段添加:
- 数据表字段添加:
- 基本语法:
mysql> alter table 数据表名称 add 新字段名称 字段类型 first|after 其他字段名称;
- 选项说明:
first:把新添加的字段放在第一位
after 字段名称:把新添加字段放在指定字段的后面
2).修改字段名称或字段类型:
- 修改字段名称与字段类型(也可以只修改名称)
mysql> alter table 数据表名称 change 旧字段名 新字段名 类型;
- 仅修改字段的类型
mysql> alter table 数据表名称 modify 字段名 类型;
3).删除某个字段:
mysql> alter table 数据表名称 drop 字段名称;
4).修改数据表引擎(MyISAM或InnoDB):
mysql> alter table 数据表名称 engine=myisam;
5).修改数据表的编码格式:
mysql> alter table 数据表名称 default charset=gbk;
6).修改数据表名称:
mysql> rename table 旧数据表名称 to 新数据表名称;
或
mysql> alter table 旧数据表名称 rename 新数据表名称;
扩展:重命名的同时移动数据表到指定的数据库
mysql> rename table 数据库名称.旧数据表名 to 另一个数据库名称.新数据表名;
④.删除数据表:
mysql> drop table 数据表名称;
4.数据的增删改查(重点):
①.数据的增加操作:
- 基本语法:
mysql> insert into 数据表名称([字段1,字段2,字段3...]) values (字段1的值,字段2的值,字段3的值.....);
特别注意:在SQL语句中,除了数字,其他类型的值都需要使用引号引起来,否则插入时会报错
第一步:准备一个数据表
mysql> use db1;
mysql> create table tb_user(
id int,
username varchar(20),
age tinyint unsigned, #unsigned代表无符号型,只有0-255
sex enum('男','女'), #enum代表枚举类型,多选一。只能从给定的值中选择一个
address varchar(255)
) engine=innodb default charset=utf8;
第二步:使用insert语句插入数据
mysql> insert into tb_user values (1,'小凯','18','男','北京朝阳');
mysql> insert into db_user(id,username,age) values (2,'小鹿','21');
②.数据的查询操作:
- 基本语法:
mysql> select * from 数据表名称 [where 查询条件]; #*代表查询所有字段,也可以只查询某些字段
mysql> select id,username from 数据表名称 [where 查询条件];
只查询id=2的小伙伴信息
mysql> select * from db_user where id=2;
查询年龄大于17岁的小伙伴的信息
mysql> select * from db_user where age>17;
③.数据的修改操作:
- 基本语法:
mysql> update 数据表名称 set 字段1=更新后的值,字段2=更新后的值,....where 更新条件;
特别说明:如果在更新数据时,不指定更新条件,则会把这个数据表的所有记录全部更新一遍
- 案例:修改’username=小鹿’这条记录,将其年龄更新为22岁,家庭住址更新为广东省广州市
mysql> update tb_user set age=22,address='广东省广州市' where username='小鹿';
- 案例:过了一年,每个人的年龄都增加了一岁
mysql> update db_user set age=age+1;
④.数据的删除操作:
- 基本语法:
mysql> delete from 数据表名称 [where 删除条件];
- 案例:删除tb_user表中,id=1的用户信息
mysql> delete from tb_user where id=1;
1).delete from 与truncate清空数据表操作:
mysql> delete from 数据表名称;
或者
mysql> truncate 数据表名称;
- delete from 和truncate区别:

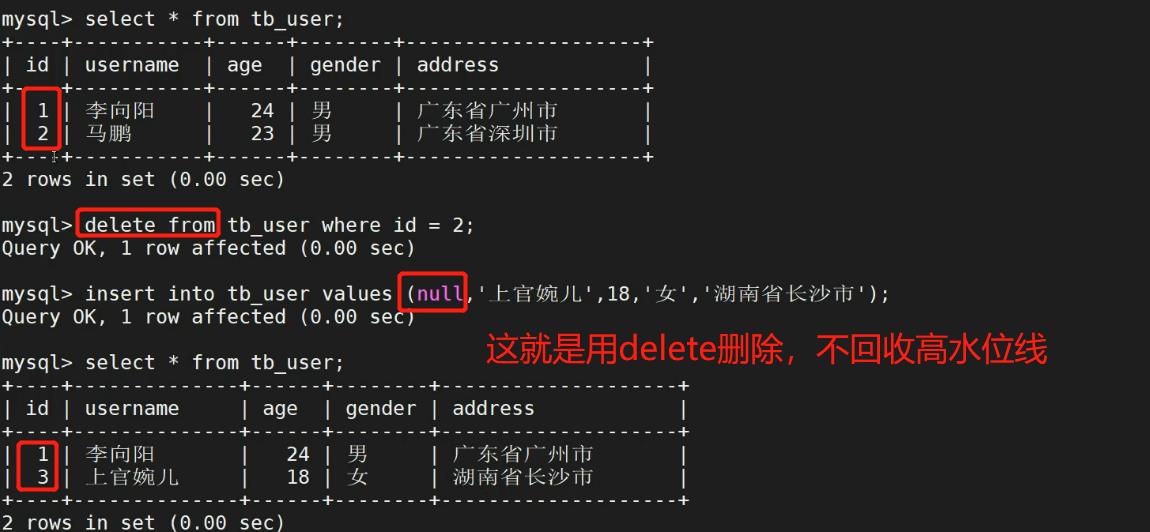
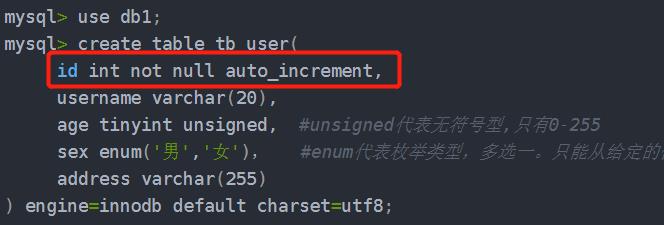
5.自动增长(水位线)与主键约束:
①.自动增长(对某个字段进行自动编号):
- not null:代表非空约束,这个字段只要是插入数据就必须要有值。
- auto_increment:自动增长。
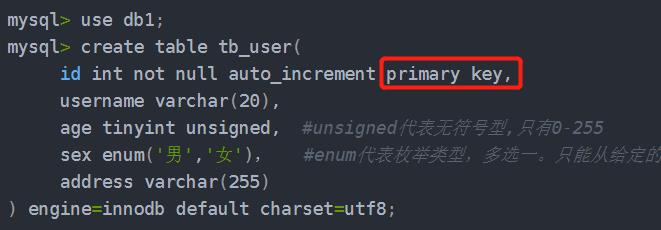
②.主键约束(非空,唯一):
可以有多个主键
或者这样写
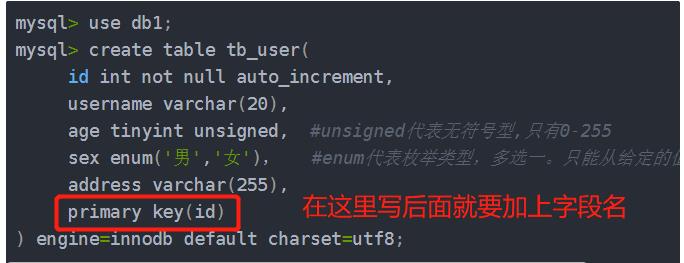
6.扩展常见的数据类型:
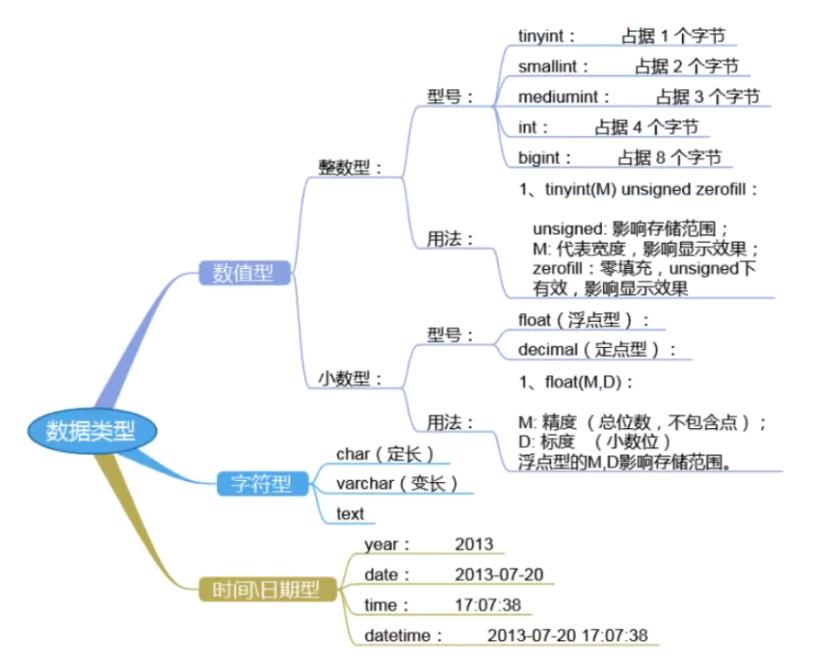
①.数值类型:
1).整数类型(整数、精准):
2).小数类型(浮点类型、定点类型):
* 浮点类型(近似值):
- FLOAT和DOUBLE:
float和double类型代表近似数字数据值。MySQL对于单精度值使用四个字节,对于双精度值使用八个字节。float单精度浮点数精确到约7位小数,double双精度浮点数精确到大约15位小数。float类型会随着数值的增大精度会减小
- 举例说明:
DOUBLE(7,4):DOUBLE类型的使用与FLOAT类型完全一致,唯一的区别就是占用字节不同,且浮点数的精度有所不同

* 定点类型(精确值):
- DECIMAL和NUMERIC:
DECIMAL和NUMERIC类型的存储精确的数值数据。使用这些类型时,重要的是要保留精确的精度,例如使用货币数据。在mysql中,NUMERIC被作为DECIMAL来应用,所以下面的举例DECIMAL同样适用于NUMERIC。
- 举例说明:

3).字符串类型:
* CHAR类型:
- char类型的字符串为定长,长度范围是0-255之间的任何值,占用定长的存储空间,不足的部分用空格填充,读取时删掉后面的空格
- 存储空间:CHAR(M)类型的存储空间和字符集有关系,一个中文在utf8字符集中占用3个bytes,gbk占用2个bytes,数字和字符统一用一个字符表示
- 存储机制:在不够M长度时,MySQL在存储数据时,需要填充特殊的空格
* VARCHAR类型:
- VARCHAR是变长存储,仅使用必要的存储空间
- 存储空间:VARCHAR(M)类型的存储空间和字符集有关,一个中文在utf8字符集中占用3个bytes,gbk统一占用2个bytes,数字和字符一个字节表示
- 存储机制:varchar(M)字段存储实际是从第二个字节开始存储的,然后用1到2个字节表示实际长度,剩下的才是可以存储数据的范围,因此最大可用存储范围是65535-3=65532字节
* 文本类型(text):
- TEXT代表文本类型的数据,当我们使用VARCHAR类型存储数据库,(早期最大只能存储255个字符,MySQL5版本中,其gbk可以存储3万多个字符,utf8格式可以存储2万多个字符),如超过了VARCHAR的最大存储范围,则可以考虑使用TEXT文本类型。
- 使用习惯:255个字符以内(包括255),定长就使用CHAR类型,变长就使用VARCHAR类型,如果超过255个字符,就使用TEXT文本类型。
4).日期时间类型:
- 时间类型的选择比较简单,主要看你需要的时间格式,是年月日,小时分钟秒等等
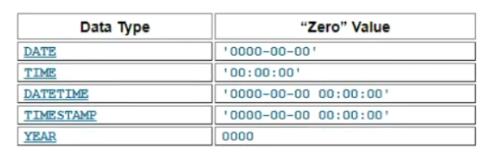
* DATE类型:

* TIME类型:

* DATETIME与TIMESTAMP类型:

* YEAR类型:

5).其他类型:
- BLOB:保存二进制的大型数据(字节串),没有字符集,eg:图片,音频视频等等。(实际运维工作中,很少将文件直接保存在数据库端,一般文件的存储都是基于路径进行操作的)
- ENUM枚举类型:多选一,从给定的多个选项中选择一个。如sex enum(‘男’,‘女’)
- SET集合类型:多选多,从给定的多个选项中选择多个。如hobby set(‘吃饭’,‘睡觉’,‘打豆豆’)
四、SQL查询语句(重点):
1.SQL查询语句:
- 基本语法:
mysql> select */字段列表 from 数据表名称 where 查询条件;
2.SQL查询五子句:
- 基本语法:
mysql> select */字段列表 from 数据表名称 where 子句 group by 子句 having 子句 order by 子句 limit 子句;
①.where 子句
②.group by 子句
③.having 子句
④.order by 子句
⑤.limit子句- 特别注意:五子句的顺序是固定的,不能颠倒
①.where 子句:
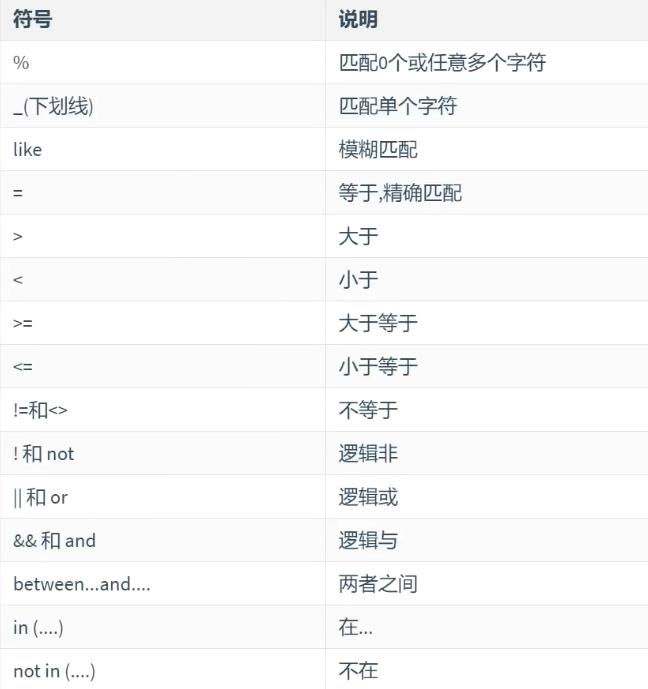
- 案例1:like模糊查询语句,查询姓“张”的同学的信息(name字段对应值应该以“张”开头)
mysql> use db_database;
mysql> create table tb_student(
id mediumint not null auto_increment,
name varchar(20),
sex enum('男','女'),
age tinyint,
address varchar(255),
primary key(id)
)engine=innodb default charset=utf8;
mysql> insert into tb_student values (null,'张三','男',18,'广东省广州市');
mysql> insert into tb_student values (null,'李四','男',19,'北京市朝阳区');
mysql> insert into tb_student values (null,'张琳','女',20,'福建省厦门市');
mysql> insert into tb_student values (null,'张晓露','女','22','湖北省武汉市');
- like模糊查询,有点类似于管道命令中的数据检索。有两个关键字,%百分号与_下划线,%代表任意个字符,_代表任意的某个字符(只能匹配1个)
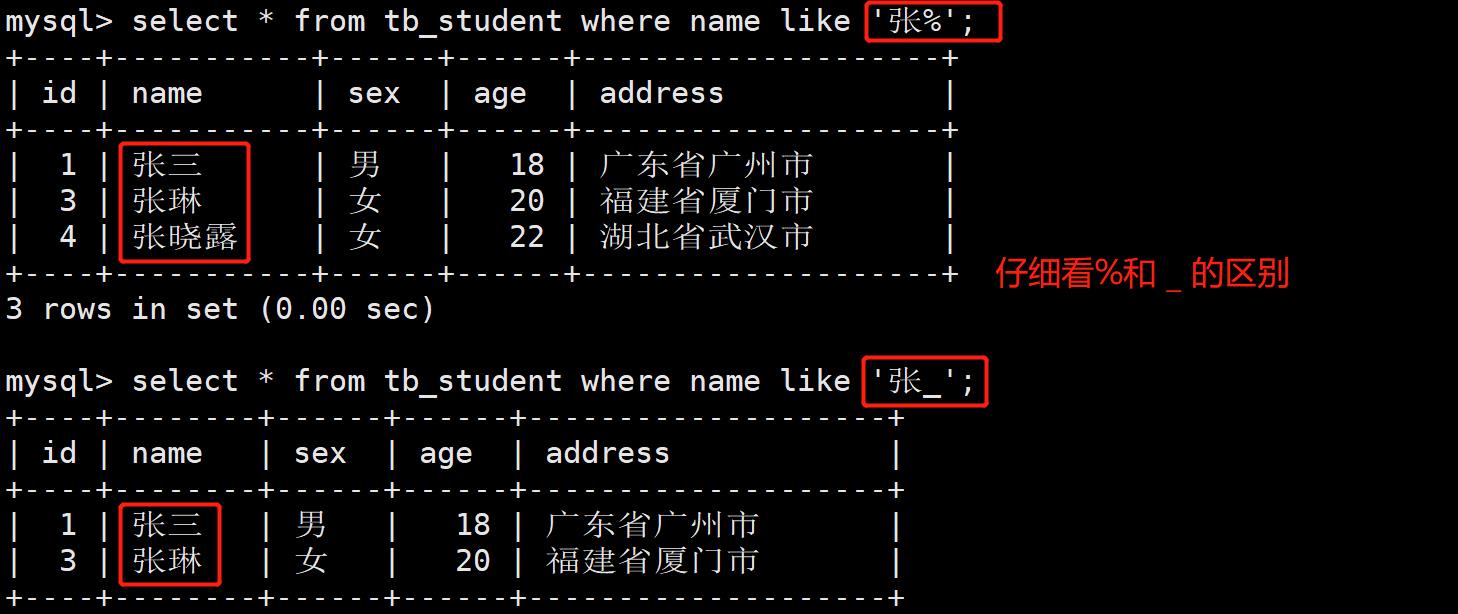
- 案例2:like模糊查询,查询名字中带有“晓”字的同学的信息
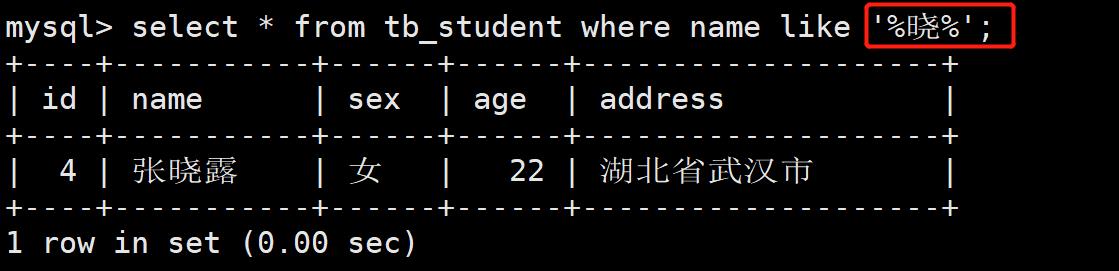
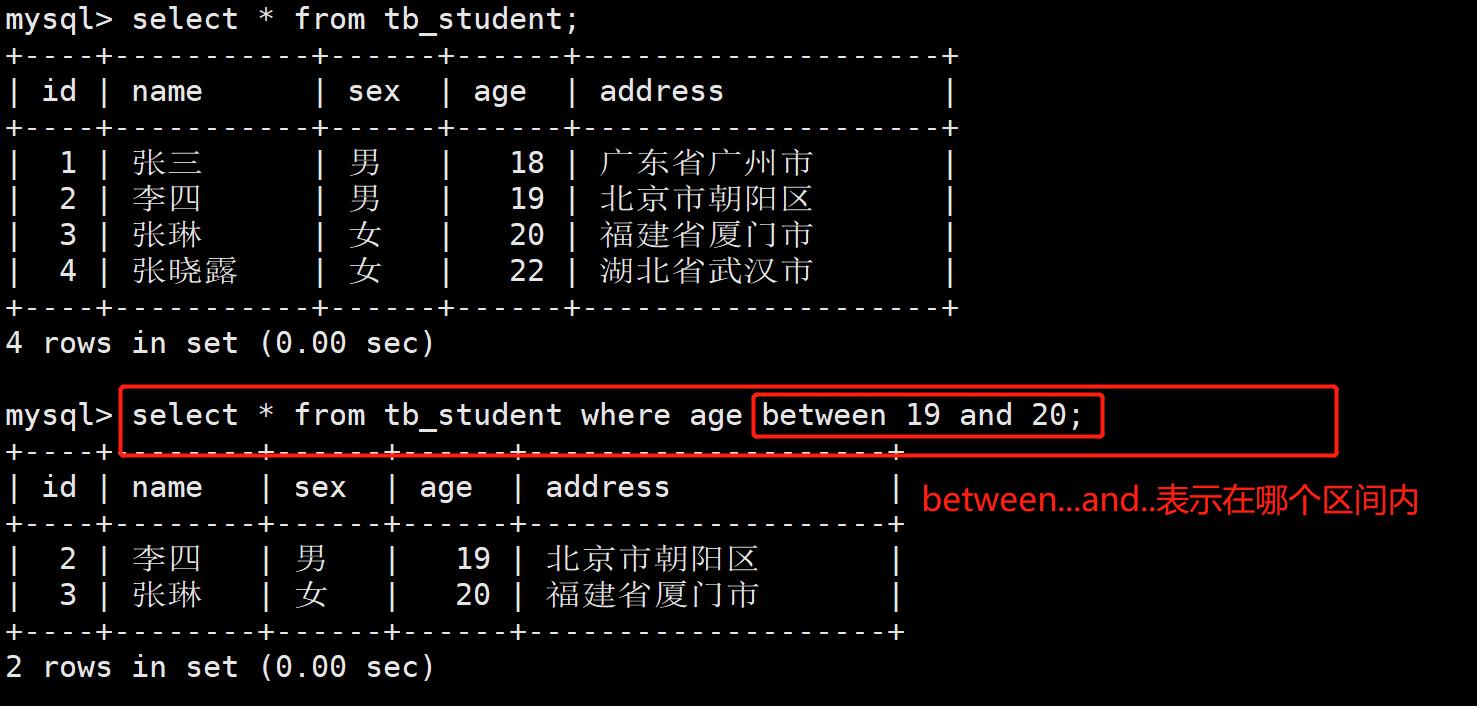
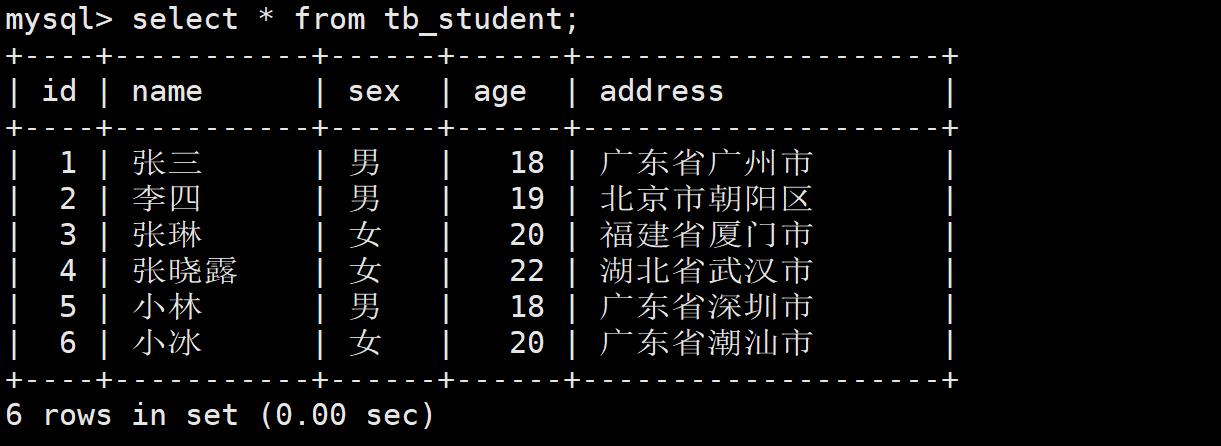
- 案例3:获取年龄在19-20岁之间的同学的信息
- 案例4:获取id为2,4,6同学的信息
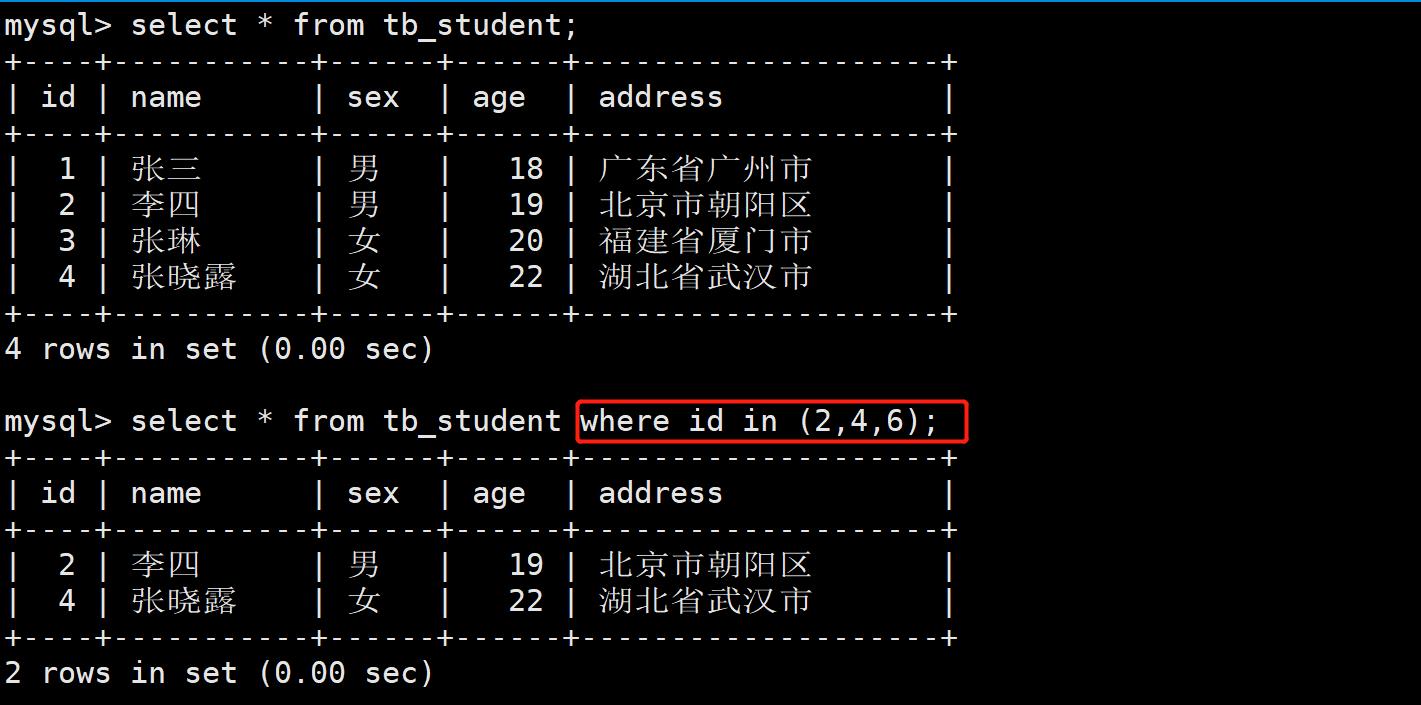
* DISTINCT数据去重操作:
- 获取tb_student表学院年龄的分布情况:
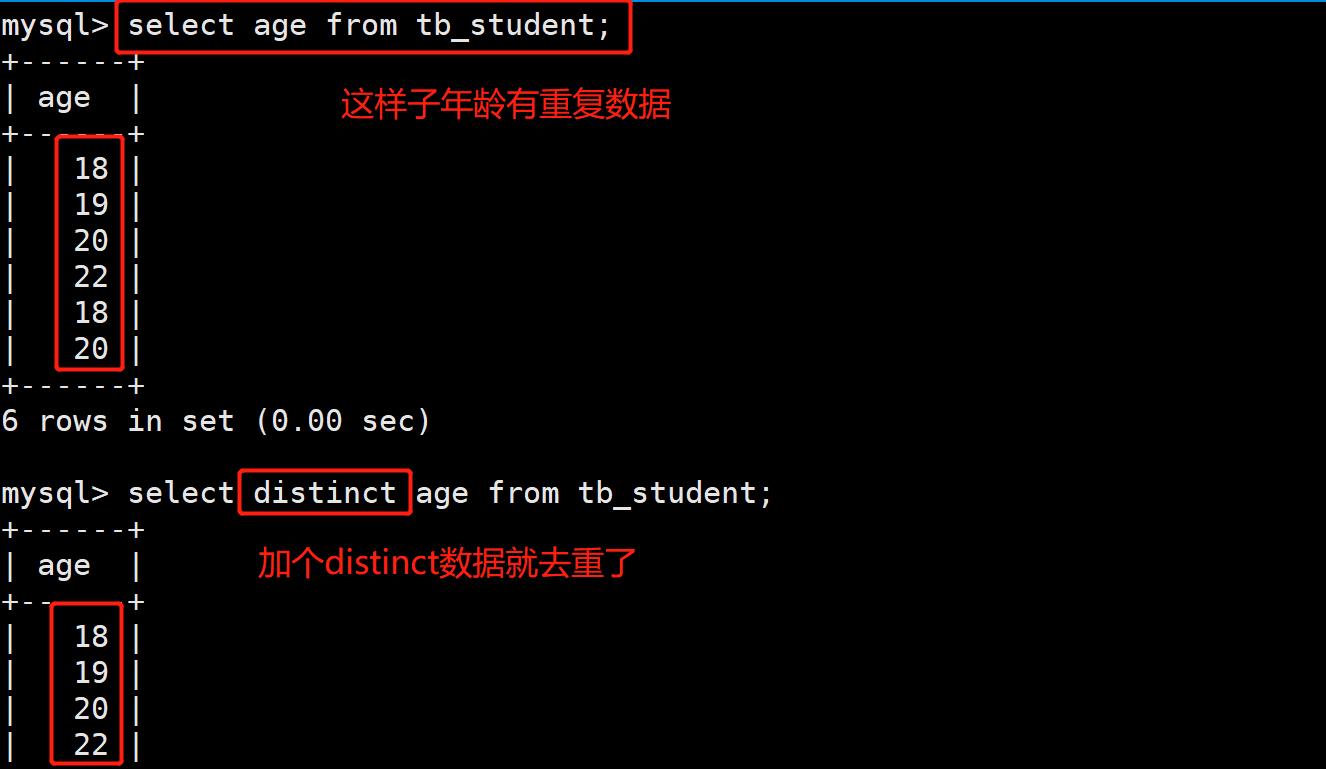
②.group by 子句(难重点):
- group by子句的作用:对数据进行分组操作,为什么要进行分组呢?
分组的目标就是进行分组统计- 在5.7以后的版本中,分组字段必须出现在select后面的查询字段中
- 根据给定 数据列 的查询结果进行分组统计,最终得到一个分组汇总表
注:一般情况下group by需与统计函数一起使用才有意义
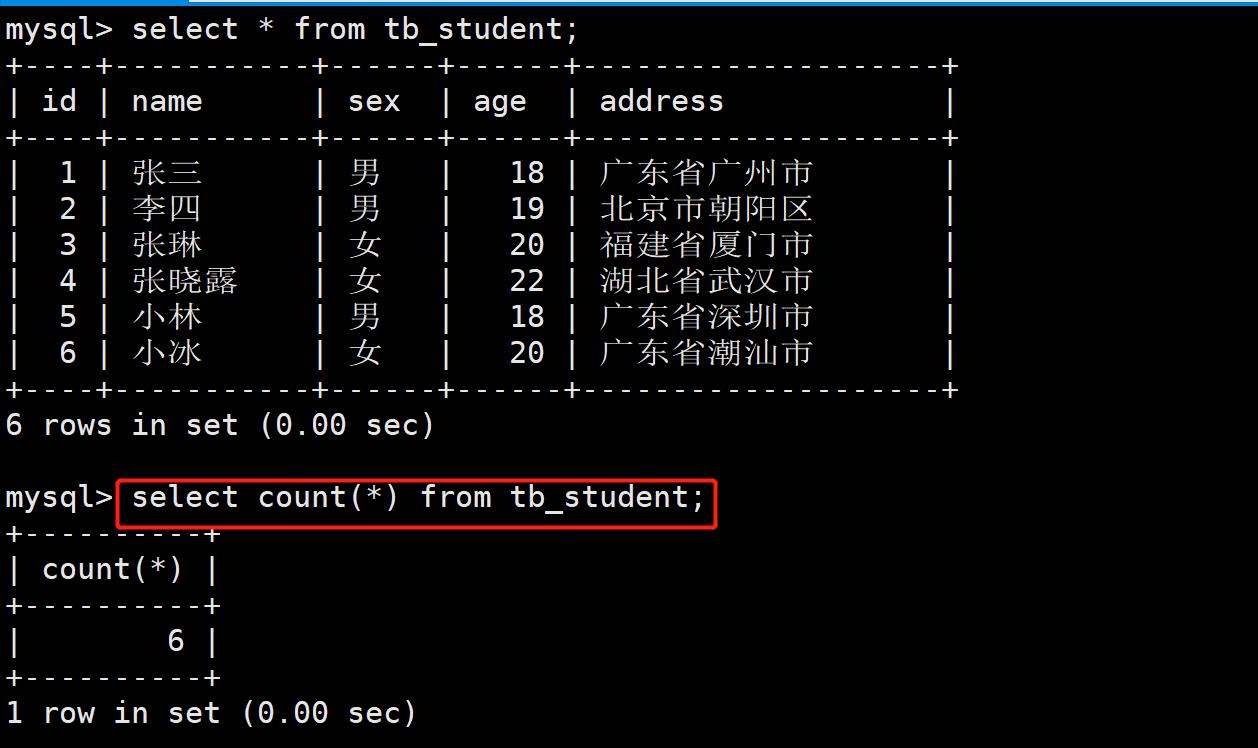
- 案例:求tb_student表中一共有多少个记录
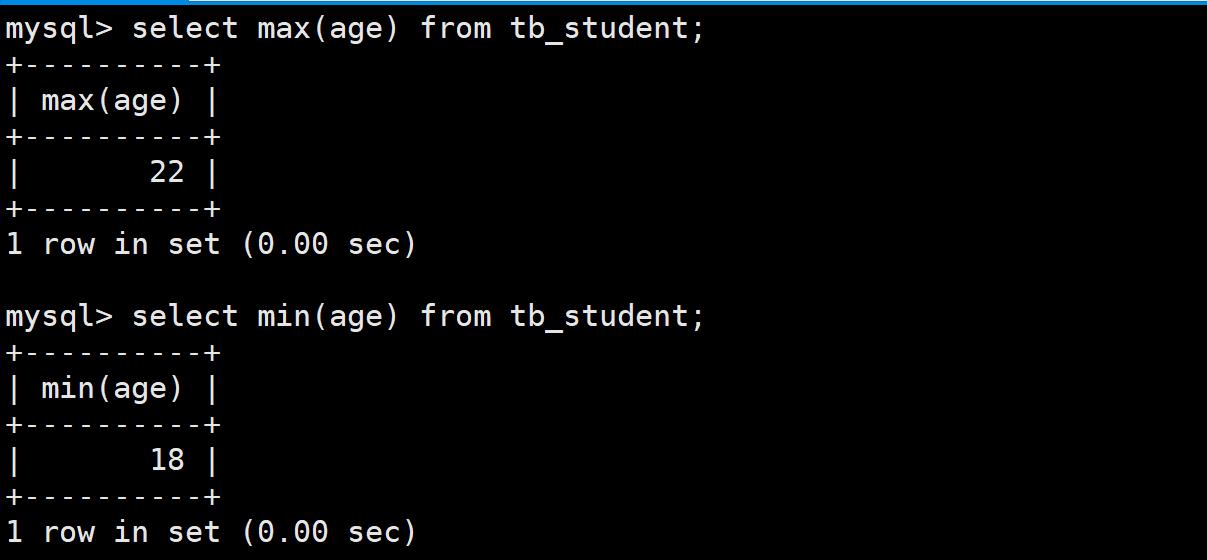
- 案例:求年龄的最大值与最小值:
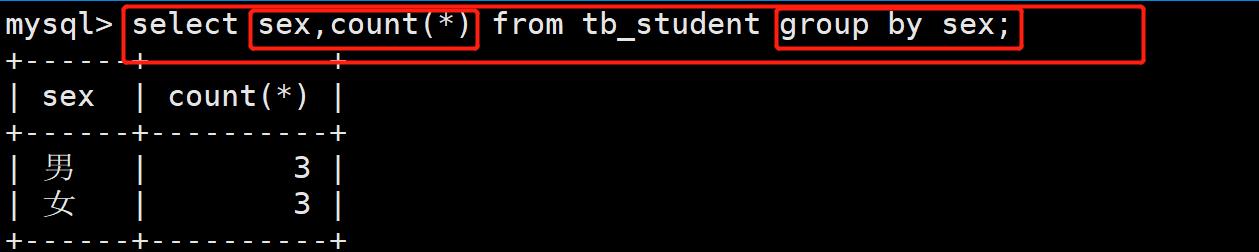
- 案例:求tb_student表中,男同学的总数量和女同学的总数量
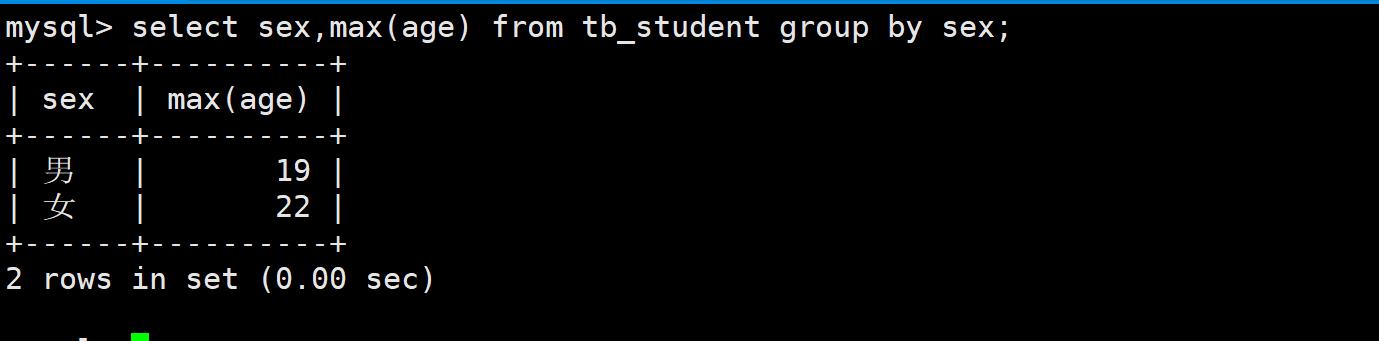
- 案例:求tb_student表中男同学年龄的最大值和女同学年龄的最大值
③.having 子句:
- having与where类似,根据条件对数据进行过滤筛选
- where针对表中的列发挥作用,查询数据
- having针对查询结果集发挥作用,筛选数据
- 案例:having在做简单查询时可以替代where子句
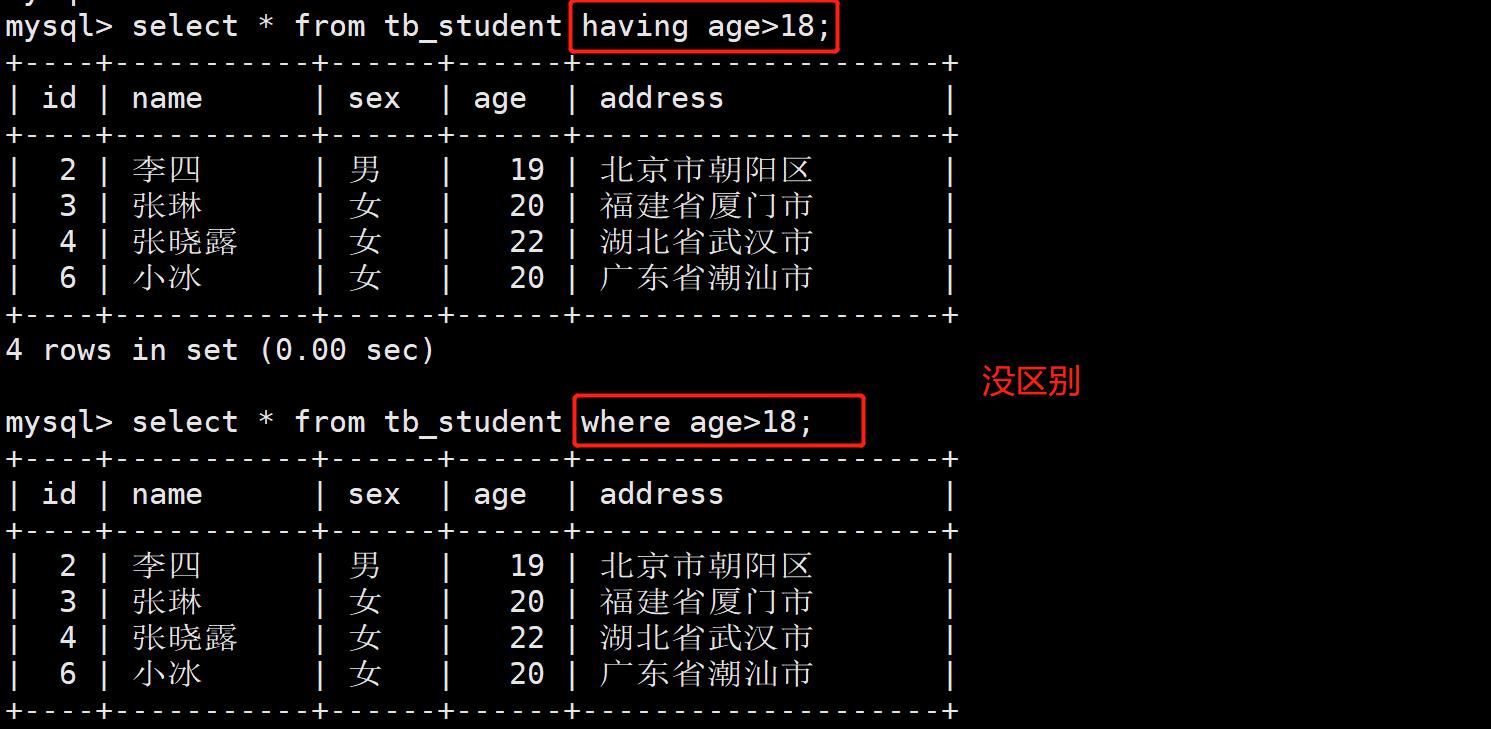
- 案例:按学科进行分组,求每个学科拥有多少人?
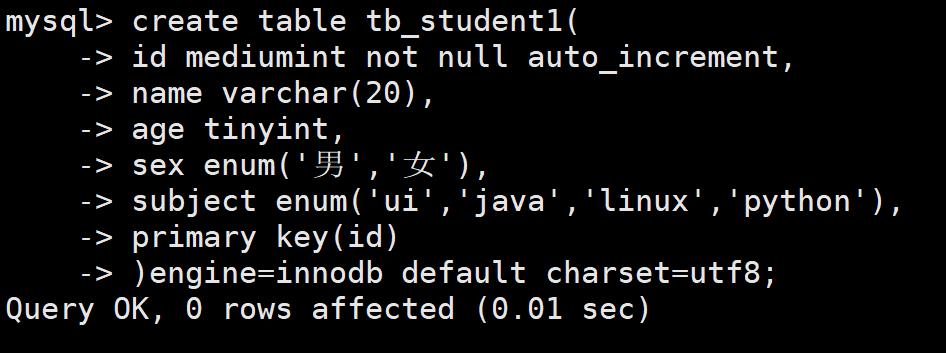
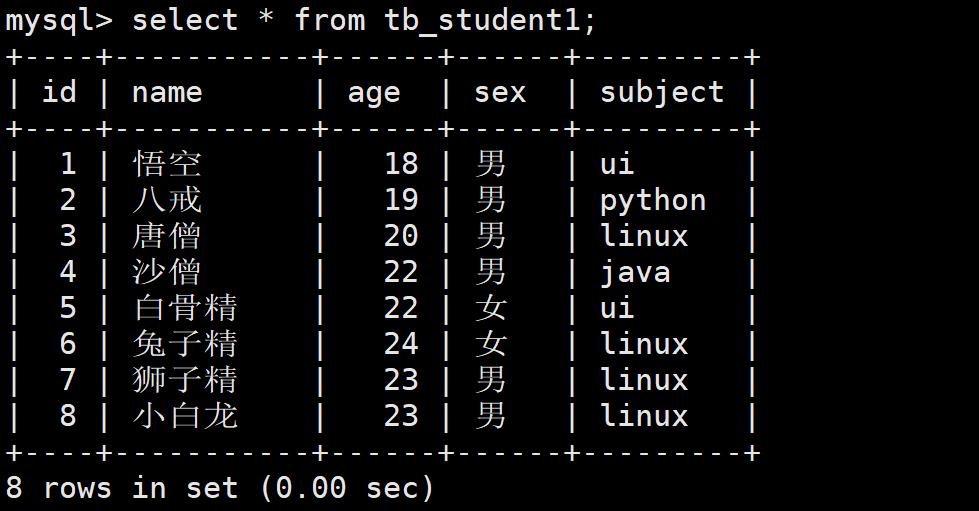
先另外创建一张学生表
插入学生信息
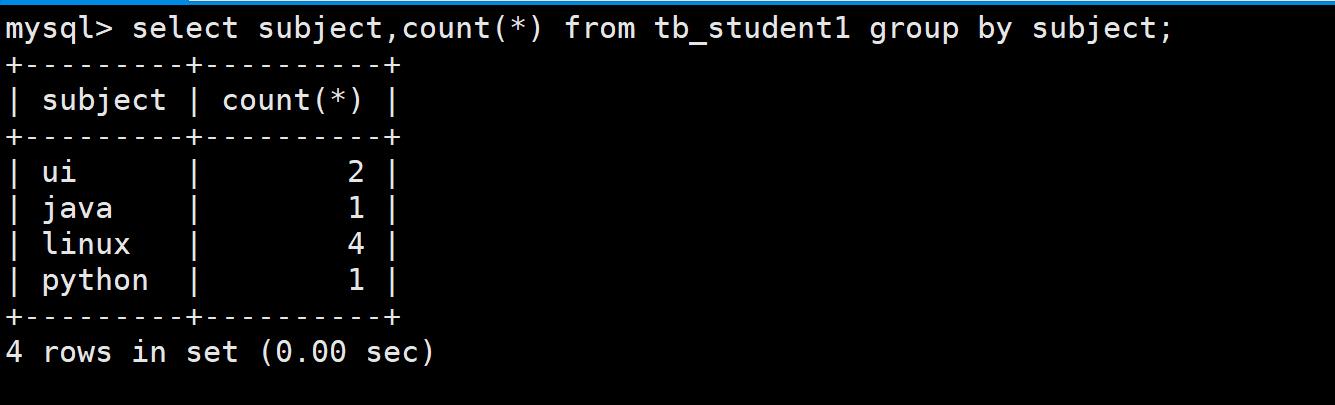
- 案例:求每个学科中,学科人数大于3人的学科信息
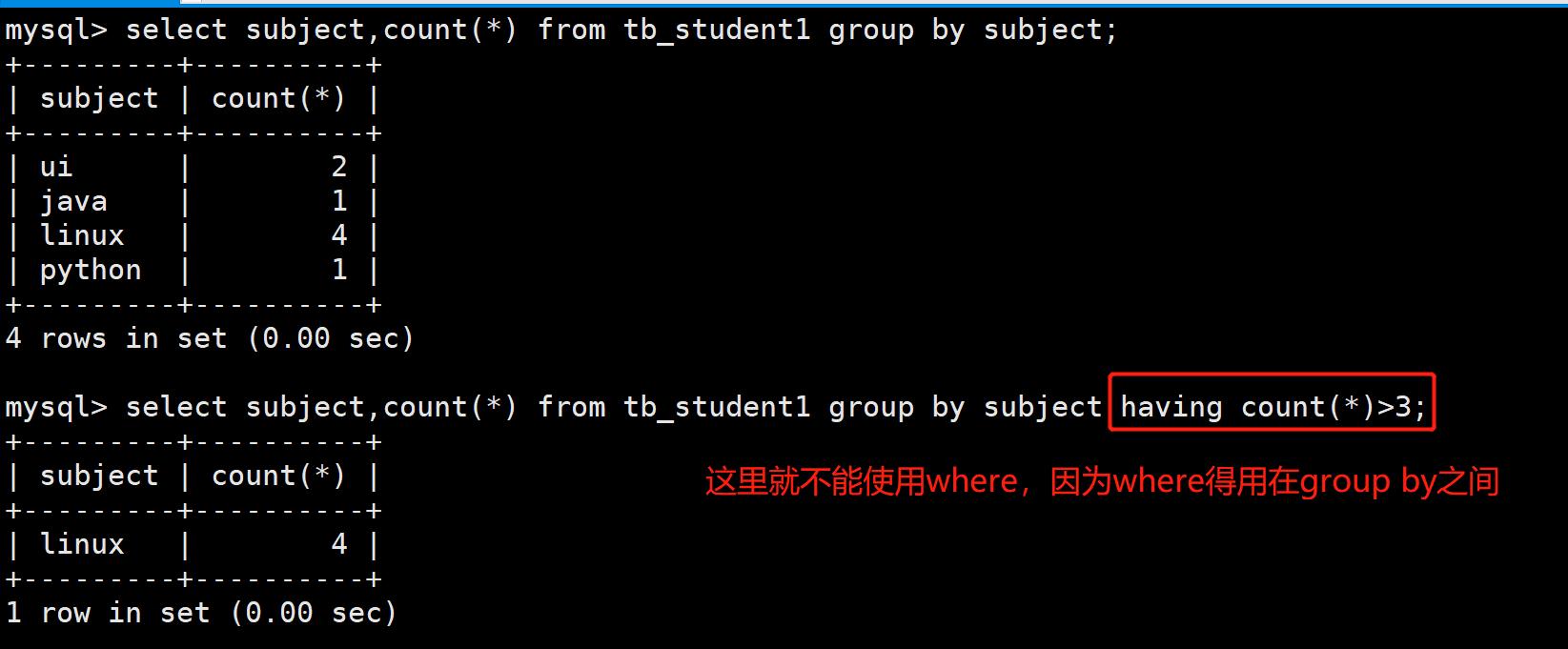
④.order by 子句:
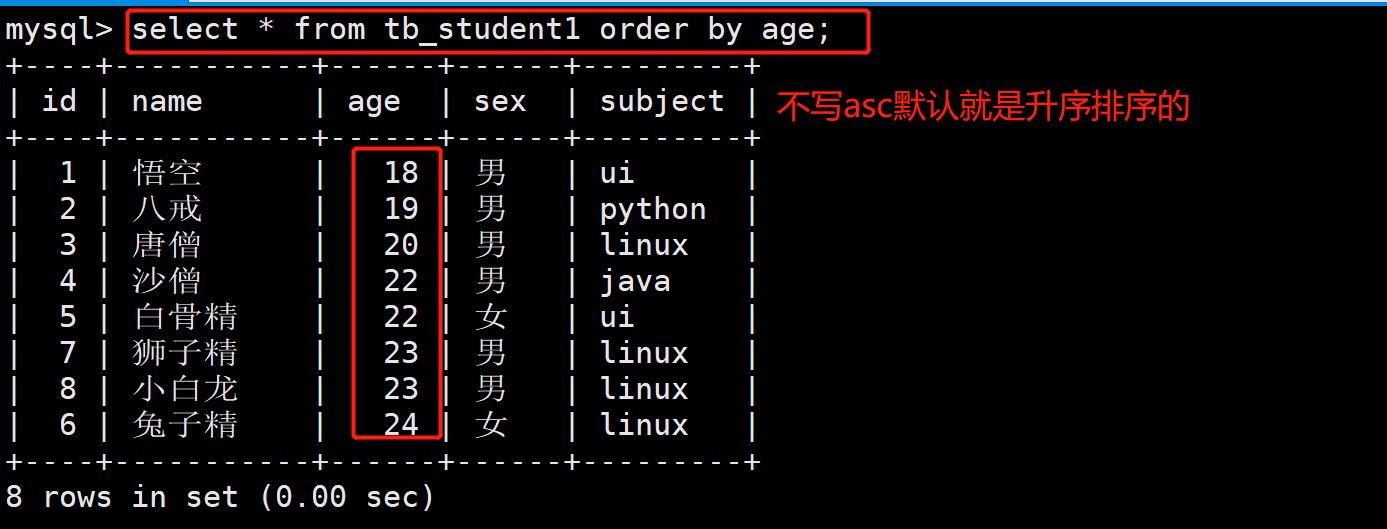
- 主要作用:就是对数据进行排序(升序,降序)
升序:从小到大- mysql> select * from 数据表名 … order by 字段名称 asc;(默认升序)
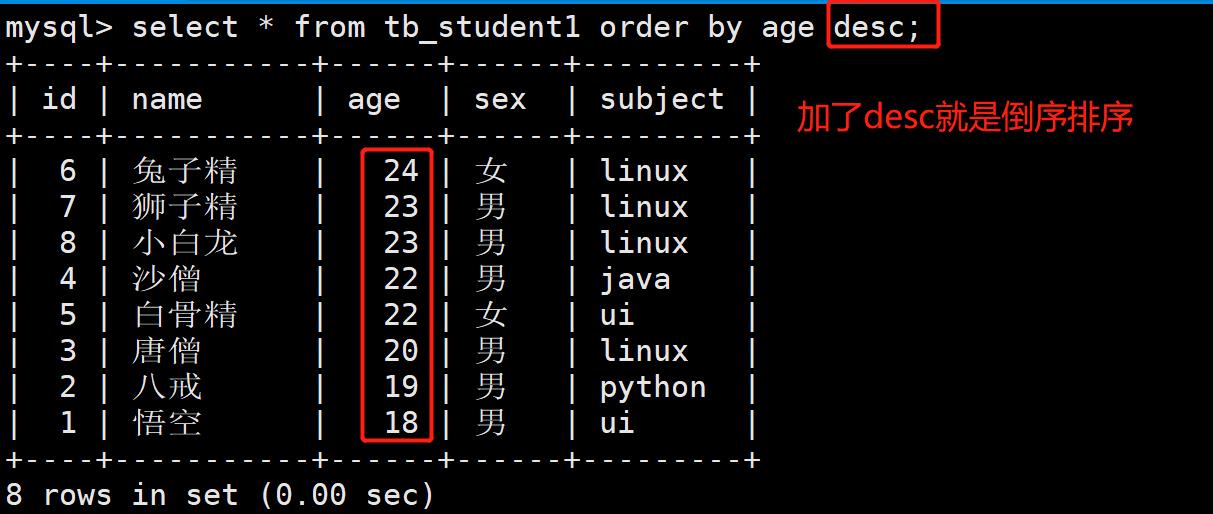
降序:从大到小- mysql> select * from 数据表名 … order by 字段名称 dese;
- 案例:按年龄进行排序
⑤.limit 子句:
- limit 子句在开发项目中,主要应用于数据分页!
- 基本语法:
mysql> select * from 数据表名称 .... limit n; #只查询满足条件的n条数据(限制数量)
或
mysql> select * from 数据表名称 .... limit m,n; #从偏移量为m开始查询,查询n条记录,m的值从0开始
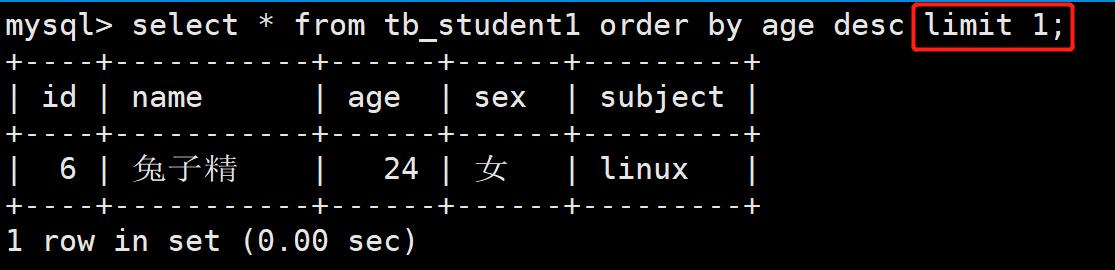
- 案例:获取学生表中,年龄最大的学员信息
- 案例:实现数据分页!
第一页:mysql> select * from tb_student1 limit 0,2;
第二页: mysql> select * from tb_student1 limit 2,2;
3.SQL多表查询(了解):
①.union 联合查询:
- union联合查询作用:把多个表中的数据联合在一起进行显示。
应用场景:分库分表- 第一步:创建两个结构相同的学生表tb_student2,tb_student3
- 第二步:分别往两张表里插入一条测试数据
因为这里我插入数据的时候,没有指定id,所有唐僧的默认id为1,这里将唐僧的id修改为2
- 第三步:使用union进行联合查询


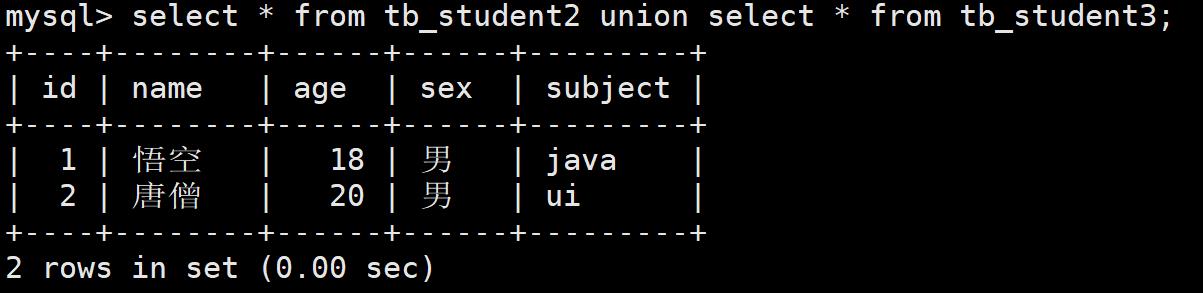
4.内连接查询(重点):
- 内连接查询,把两个表甚至多个表进行连接,然后拿表1中的每一条记录与表2中的每一条记录进行匹配,如果有与之对应的结果,则显示。反之,则忽略这条记录。
- 基本语法:
mysql> select 数据表1.字段列表,数据表2.字段列表 from 数据表1 inner join 数据表2 on 连接条件;
- 案例:获取产品表中每个产品的分类信息

5.外连接查询(重点):
- 内连接查询要求:表1和表2中的每一条记录必须要一一对应,如果无法匹配,则这条记录会被忽略,那如果我需要保留表1和表2中的所有记录该怎么办?
答:可以使用外连接查询
①.左外连接查询:
- 左外连接查询:把左表中的每一条数据都保留,右表匹配到结果就显示,匹配不到就显示为null
- 基本语法:
mysql> select 数据表1.字段列表,数据表2.字段列表 from 数据表1 left join 数据表2 on 连接条件;
②.右外连接查询:
- 右外连接查询:把右表中的每一条数据都保留,左表匹配到结果就显示,匹配不到就显示为null
- 基本语法:
mysql> select 数据表1.字段列表,数据表2.字段列表 from 数据表1 right join 数据表2 on 连接条件;
③.案例:
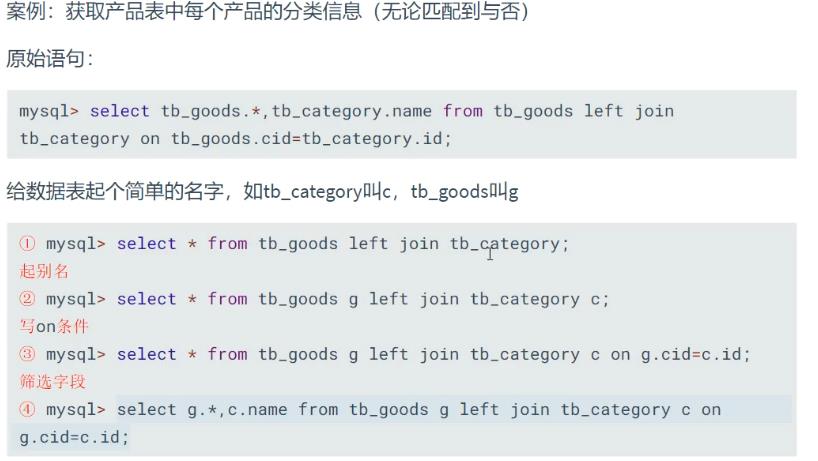
- 获取产品表中每个产品的分类信息(无论匹配到与否)

6.别名机制:
以上是关于MySQL语句详解(最详细)的主要内容,如果未能解决你的问题,请参考以下文章