Detection:目标检测常用评价指标的学习总结(IoUTPFPTNFNPrecisionRecallF1-scoreP-R曲线APmAP ROC曲线TPRFPR和AUC)
Posted 玉堃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Detection:目标检测常用评价指标的学习总结(IoUTPFPTNFNPrecisionRecallF1-scoreP-R曲线APmAP ROC曲线TPRFPR和AUC)相关的知识,希望对你有一定的参考价值。
目录
- 前言
- 1. IoU
- 2. TP、FP、TN、FN
- 3. Accuracy、Precision、Recall和 F 1 F_1 F1-score指标
- 4. P-R曲线、AP和mAP
- 5. ROC曲线和AUC
- 总结
- 附录1 基于yolov5的计算指标代码,举例计算P-R曲线和ap值,mAP值。
前言
刚开始学习目标检测的时候常常弄不清楚TP,FP,TN,FN对应的目标框是什么、P-R曲线是什么、AUC又是什么等等问题。因此,本人借此机会对这些内容进行了深入学习,并进行整理总结。现在分享给各位读者朋友。
由于本文目前是我写的最多的一篇文章,难免存在一些错误。如果读者朋友发现了,麻烦在评论区告知我,我及时改正。 ⌣ ¨ \\ddot\\smile ⌣¨
对于前置内容有一定了解且只想查看指定指标的,可以从目录直接跳转。如果前置内容不熟悉的读者,建议从头开始看。
本篇文章主要分为5个部分:
- 第一部分介绍IoU这个指标的含义和计算方法。
- 第二部分介绍TP、FP、TN、FN这四个指标的含义,以及在目标检测中的使用方法。
- 第三部分介绍Accuracy、Precision、Recall、F1-score这四个指标的含义,以及在单类别和多类别下的计算方法。
- 第四部分介绍P-R曲线、AP和mAP这个三个指标的含义和计算方法。
- 第五部分介绍ROC曲线和AUC这个两指标的含义和计算方法。
- 最后还附上了yolov5计算指标代码的部分解释,并举例说明。详情参见附录。
本篇博客的参考资料如下:
- 作者:TODAY’S,目标检测指标TP、FP、TN、FN和Precision、Recall。
- 作者:虎大猫猫一,文讲清楚目标检测中mAP、AP、precison、recall、accuracy、TP、FP、FN、TN
- 作者:小小詹同学, FP、FN、TP、TN、精确率(Precision)、召回率(Recall)、准确率(Accuracy)评价指标详述
- 作者:NaNNN,多分类模型Accuracy, Precision, Recall和F1-score的超级无敌深入探讨
- 作者:daige123, 学习笔记3——目标检测的评价指标(AC、TP、FP、FN、TN、AP、ROC、AUC、mAP、mAP@.5、mAP@.5:.95
- 作者:Matrix_11, 机器学习 F1-Score, recall, precision
- 作者: 山竹小果, 评价指标整理:Precision, Recall, F-score, TPR, FPR, TNR, FNR, AUC, Accuracy
- 作者:流星落, mAP@0.5与mAP@0.5:0.95的含义,YOLO
- 作者:吴良超的学习笔记,ROC 曲线与 PR 曲线
- 作者:希葛格的韩少君, 目标检测中的AP,mAP
- 维基百科:ROC曲线
- An introduction to ROC analysis
- 作者:满船清梦压星河HK【python numpy】a.cumsum()、np.interp()、np.maximum.accumulate()、np.trapz()
1. IoU
定义:IoU(Intersection Over Union)交占比,该指标常用来表示预测框和真实框的相近程度。其计算方法为两个框交集的面积除以两个框并集的面积。公式如下:
I
o
U
=
A
∩
B
A
∪
B
,
A
,
B
分别表示预测框和真实框。
IoU = \\fracA\\cap BA\\cup B, A,B分别表示预测框和真实框。
IoU=A∪BA∩B,A,B分别表示预测框和真实框。
图片表示如下,蓝色部分为A和B计算得到的面积。
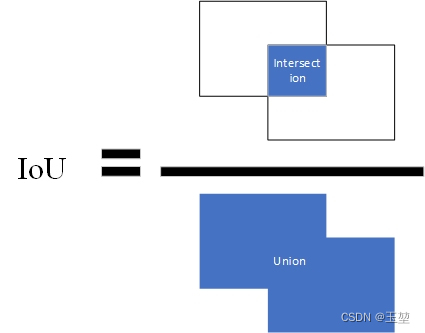
IoU还有其他的变种,如CIoU,DIoU,GIoU等,本文不做过多介绍。我会单独列出一篇文章总结。如果读者朋友现在感兴趣可以参考其他博客的介绍。
2. TP、FP、TN、FN
2.1 混淆矩阵
提到TP、FP、TN、FN,首先我们得了解一下混淆矩阵。
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
举例说明如下:(图片来自百度百科)
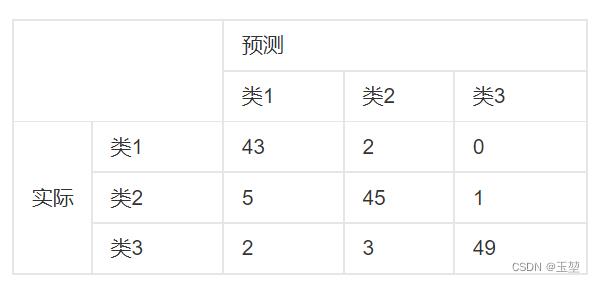
其中,第一行第一列的43表示原本属于类1,且预测为类1的数量为43。
第二行第一列的5表示原本属于类2,且预测为类1的数量为5。
其余数目同理。
第一列总数43+5+2=50,表示全部预测为类1的数目为50。
第一行总数43+2=45,表示全部原本属于类1的数目是45。
其余数目同理。
2.2 TP、FP、TN、FN的定义
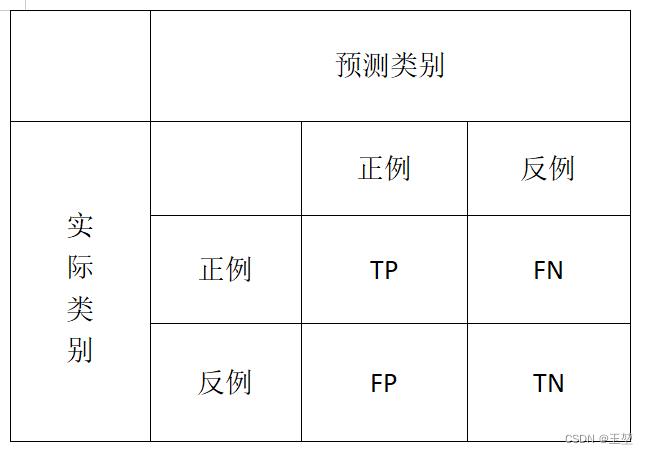
经过混淆矩阵的理解,此处就可以引出TP、FP、TN、FN的定义:
TP(True Positive): 真正例,表示预测为正例(positive),且预测正确(true),即原本为正例。
FN(False Negative): 假反例,表示预测结果为反例(negative),且预测错误(false),即原本为正例。
FP(False Positive): 假正例,表示预测结果为正例(positive),且预测错误(false),即原本为反例。
TN(true Negative): 真反例,表示预测结果为反例(negative),且预测正确(true),即原本为反例。
个人记忆的方法是,后面的字母表示预测的结果,前面的字母表示预测的正确与否。
在混淆矩阵中表示如下:
2.3 TP、FP、TN、FN在目标检测中的对应内容
在目标检测中,我们经过网络会获取许多的预测框和其对应的置信度打分(confidence score)。首先,通过对比预先设定的置信度阈值(confidence threshold)来过滤预测框。其中高于置信度阈值的预测框将其看作正例(positive),低于置信度阈值的预测框在目标检测中一般舍弃不用。
2.3.1 TP,FP在目标检测中的理解
这两个指标可以成对讲,在所有保留的预测框中(即所有的positive中),通过IoU阈值来判断预测结果。大于IoU阈值的为预测正确(true),小于IoU阈值的为预测错误(false)。但是要注意一点,对于每个目标而言,TP只有一个,因此在大于IoU阈值的预测框中,选取IoU值最大的一个预测框为TP,其他所有的预测框都为FP。小于IoU阈值预测框也是FP。
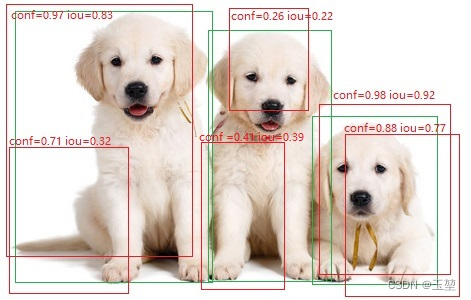
以二分类为例,举例如下:
如图所示,绿框是真实框,记为GT(ground true)。红色为预测框。在下述图中有三只可爱的狗,即三个目标,GT=3。且假设,置信度阈值和IoU阈值都为0.5。
此时,从下图可以看出,大于置信度阈值的预测框有4个,即这4个框都为正例(positive),小于置信度阈值的框有两个(conf=0.26和conf=0.41的两个框),则这两个框为负例(negative)。在预测为正例的预测框中,小于IoU阈值的预测框只有一个,即IoU=0.32的预测框,那么该预测框为FP。再看剩下的3个预测框,基于上面的原则,对于左边的目标而言,IoU=0.83的预测框满足TP的定义。对于右边的预测框而言,虽然,IoU=0.92和IoU=0.77的预测框都预测正确,且大于IoU阈值,但是我们只选择其中IoU最高的作为TP。余下IoU=0.77的预测框则作为FP。 最后,我们就会得到FP=2(IoU=0.32的框和IoU=0.77的框),TP=2(IoU=0.83的框和IoU=0.92的框)。
(图片来自百度百科,里面的框,conf和iou值都是p上去的,且数据是编的。仅供理解TP和FP的概念使用)
2.3.2 TN,FN在目标检测中的理解
这两个指标也可以一起讲。在目标检测中,负例本身就不存在。因此,对于FN而言,我们取没有预测出来的目标数量作为FN。对于TN而言,目标检测不使用这个概念。
注意:无论小于置信度的预测框有多少个,我们都不做考虑。只取没有预测出来的目标的数量作为FN。
以二分类为例,举例如下:
如图所示,绿框是真实框,记为GT(ground true)。红色为预测框。在下述图中有三只可爱的狗,即三个目标,GT=3。且假设,置信度阈值和IoU阈值都为0.5。
根据2.3.1节中的例子,下图中左右两个目标被预测出来,中间的小狗没有预测出来。因此,FN=1。
此时,我们并不关心小于置信度阈值的两个框(conf=0.26的预测框和conf=0.41的预测框)。
2.3.3 总结
(1)大于置信度阈值的预测框全部都表示预测为正例(positive)
(2)TP:IoU>IoU阈值的预测框数量,同一个目标只取最大IoU值的预测框,即一个目标只有一个TP。
(3)FP:IoU<IoU阈值的预测框和检测到同一个目标的多余预测框的数量。
(4)TN:用不到这个概念。
(5)FN:没有检测到的目标的数量。
(6)FN和TP之和表示所有的目标数量,即FN+TP=GT。
3. Accuracy、Precision、Recall和 F 1 F_1 F1-score指标
3.1 Accuracy
Accuracy,中文又称准确率。该指标表示在模型预测的所有测试框(TP+FP+TN+FN)中,预测正确的测试框(TP+TN)的占比。公式如下:
A
c
c
=
T
P
+
T
N
T
P
+
F
P
+
T
N
+
F
N
Acc = \\fracTP+TNTP+FP+TN+FN
Acc=TP+FP+TN+FNTP+TN
准确率表示模型预测目标的能力。区别于后续的Precision和Recall只针对正例,准确率针对的是所有样本,既包含正例也包含反例。
准确率常用于分类模型,在目标检测中很少提及。这是因为Accuracy无法解决类别不平衡的问题。假设,有100张图片,其中90张是狗,6张是猫,4张是鸟。如果模型无论输入什么图片都预测为狗的话,此时Accuracy就可以达到90%,这种情况下,模型显然是没有任何学习能力的,但是Accuracy却很高。在目标检测中,由于场景的复杂性,经常会出现目标类别不平衡的情况。此时使用Accuracy效果并不理想,因此才引入了精确率(Precision)和召回率(Recall)。
Accuracy针对的是全部样本,而Precision和Recall针对的是每个类别。这样Precision和Recall就可以方便的处理多类别下类别不平衡的情况,以下章节分别介绍了单类别目标检测的Precision,Recall、 F 1 F_1 F1-score的计算方法,和多类别下Precision,Recall、 F 1 F_1 F1-score的计算方法。
3.2 单类别下的Precision、recall和 F 1 F_1 F1-score的计算方法
3.2.1 Precision
Precision,中文又称精确率,或查准率。该指标表示在所有预测为正例的测试框(TP+FP)中,预测为正例且正确的测试框(TP)的占比。公式如下:
P
=
T
P
T
P
+
F
P
P = \\fracTPTP+FP
P=TP+FPTP
查准率表示模型预测正确物体的能力。当查准率为0时,模型预测出来的所有正例都是错误的。当查准率为1时,模型预测出来的所有正例都是正确的。查准率越高表示模型预测出来的所有正例中大部分都是正确的目标,只有少量不是目标的物体被识别为目标。
3.2.2 Recall
Recall,中文又称召回率,或查全率(有时也被成为灵敏度)。该指标表示在所有的正例(TP+FN)中,模型预测为正例且正确的目标(TP)的占比。公式如下:
R
=
T
P
T
P
+
F
N
=
T
P
G
T
R =\\fracTPTP+FN = \\fracTPGT
R=TP+FNTP=GTTP
查全率表示模型能够找全正确物体的能力。当查全率为0时,模型一个正确的正例都没有找到,当查全率为1时,所有的正确的正例都被找到。查全率越高,表示模型能够找到更多的正确的正例。
总结:
Precision着重评估:在预测为Positive的所有数据中,真实Positve的数据到底占多少?
Recall着重评估:在所有的Positive数据中,到底有多少数据被成功预测为Positive?
3.2.3 Precision和Recall的侧重
Recall和Precision之间是个矛盾的指标,当Precision高的时候,往往Recall就低。同理,当Recall高的时候,往往Precision就低。那么对于Recall和Precision之间的侧重就取决于当前应用的环境。举例如下:
(1)注重Recall指标的情况。
当面前站了10个人,里面有8个平民(negative),2个罪犯(positive)。此时我们就更加注重recall,我们宁愿把平民错认为罪犯(FP),也要把减少把罪犯认成平民(FN),避免让罪犯成为漏网之鱼。因此,我们更加注重预测的查全率,减少漏检,有一种宁杀错不放过的感觉。回顾Recall的公式,可以得出,这种情况我们更注重Recall,而不是Precision。
(2)注重Precision指标的情况。
目前有10份邮件,其中8个正常邮件(negative),2个垃圾邮件(positive)。此时我们更加注重Precision,我们宁愿把垃圾邮件检测为正常邮件(FN),也不能把正常邮件检测为垃圾邮件(TP),避免错过重要信息。因此,我们更加预测的准确性,减少误检。回顾Precision的公式,可以得出,这种情况我们更注重Precision,而不是Recall。
3.2.4 F 1 F_1 F1-score
F 1 F_1 F1-score其实是 F β F_\\beta Fβ-score的一个特例( β = 1 \\beta=1 β=1), 是Precision指标和Recall指标的调和平均值。用来平衡Precision指标和Recall指标,使得模型更加稳定,不会偏向于Precision指标和Recall指标的任意一个。
在介绍F1-score 之前,我们先学习下更通用的形式 F β F_\\beta Fβ-score,这个指标是也是用来衡量Precision指标和Recall指标的,不过可以通过 β \\beta β来设置模型对于Precision指标和Recall指标的偏好。
F
β
F_\\beta
Fβ-score个公式如下:
F
β
−
s
c
o
r
e
=
(
1
+
β
2
)
∗
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
β
2
∗
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F_\\beta-score = \\frac(1+\\beta^2)*Precision*Recall\\beta^2*Precision + Recall
Fβ−score=β2∗Precision+Recall(1+β2)∗Precision∗Recall
从上述的公式中可以看出,如果 β \\beta β>1分母中Precision的权重很大,为了使 F β − s c o r e F_\\beta-score Fβ−score指标更高,我们希望Precision很小,此时相对的Recall就越大(从P-R曲线上看,Precision和Recall是相矛盾的数据。P-R曲线后续章节会介绍)。则 β \\beta β>1的情况下,说明模型更偏好于提升Recall,此时模型更偏向于查全的能力。相反, β \\beta β<1分母中Recall的权重很大,为了使 F β − s c o r e F_\\beta-score Fβ−score指标更高,我们希望Recall很小,此时相对的Precision就越大。则 β \\beta β<1的情况下,说明模型更偏好于提升Precision,此时模型更偏向于查准的能力。为使模型即不具有偏向性,又可以同时评估Precision指标和Recall指标,我们选用 β \\beta β=1,即F1-score来作为模型的调和平均值,从而描述模型的稳定性
F
1
F_1
F1-score个公式如下:
F
1
−
s
c
o
r
e
=
2
∗
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F_1-score = \\frac2*Precision*RecallPrecision + Recall
F1−score=Precision+Recall2以上是关于Detection:目标检测常用评价指标的学习总结(IoUTPFPTNFNPrecisionRecallF1-scoreP-R曲线APmAP ROC曲线TPRFPR和AUC)的主要内容,如果未能解决你的问题,请参考以下文章