spark.mllib源码阅读-分类算法1-LogisticRegression
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-分类算法1-LogisticRegression相关的知识,希望对你有一定的参考价值。
LogisticRegression解释:
传统的线性回归模型z(x)=wx+b,其输出为负无穷至正无穷的区间,如果输出值为一个事件发生的概率,那么就要求输出区间为[0,1],传统的一些线性回归模型就不能work了,一个很简单的想法就是在z(x)线性输出的基础上增加一个从0到1光滑的单调递增的函数。同时对于很多事件来说,在事件确定发生的概率区间内 条件的微弱变化几乎不影响事件的发生,而在事件发生与不发生的交界区间 条件的微弱变化对事件发生的概率产生了极大的影响。因此,我们就需要一个函数g(z),其在z的两个相当大的区间内其输出几乎不随z的变化而变化,而在一个小区间内变化又很大,同时整体的变化的平滑的。sigmod函数即很好的符合上述的要求:

sigmoid函数
这样,输入到概率输出的映射用函数表示为
称之为Logistic函数。
事件发生和不发生的概率表示为:
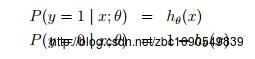
上式可简化为:
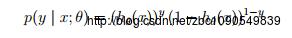
通常使用极大似然来进行Logistic回归的参数估计,在m个样本的训练集上,其似然函数为:
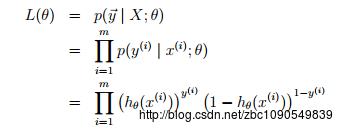
对数似然函数为:
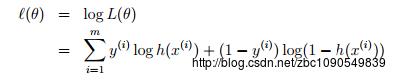
要最大化对数似然函数,可以参照梯度下降法的方法,对对数似然函数求各个参数的偏导数:
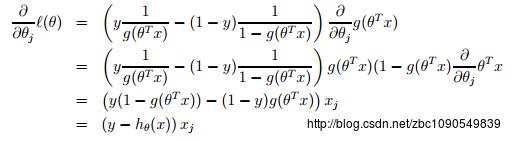
由于是求极大值的最优化问题,参数更新的方向是沿着梯度的正方向: ,参数更新的规则为:
,参数更新的规则为:

以上LogisticRegression函数由来是个人从形象上推测的。LogisticRegression函数严格的数学推导和后面的参数求解过程,可以参阅斯坦福大学的课件。
LogisticRegression回归实现:
讲完了理论,下面来看看Spark具体的LogisticRegression的实现。LogisticRegression的Spark实现包括LogisticRegression模型的定义和参数的求解两部分。
LogisticRegressionModel
Logistic回归分类模型实现的分类器,包括2分类和多分类问题.Logistic回归分类模型仍然是一个广义的线性回归问题,因此使用了LogisticRegressionModel作为它的基类。
在二分类问题上,Logistic回归输出值是一个0-1区间的实数值,通过与阀值threshold比较来判断其类别。在多分类问题上,Logistic回归输出值是一个0-1区间的实数值序列,通过选取最大的输出值,来选取最优的分类类别。
override protected def predictPoint(
dataMatrix: Vector,
weightMatrix: Vector,
intercept: Double) =
require(dataMatrix.size == numFeatures)
// If dataMatrix and weightMatrix have the same dimension, it's binary logistic regression.
if (numClasses == 2)
val margin = dot(weightMatrix, dataMatrix) + intercept
val score = 1.0 / (1.0 + math.exp(-margin))
threshold match
case Some(t) => if (score > t) 1.0 else 0.0
case None => score
else
//多分类问题,weightsArray存储的是每个分类器的权重和偏置
//最后取输出概率P最大的类别,这里并没有显式求出P值,而是计算并比较的g(x)值
var bestClass = 0
var maxMargin = 0.0
val withBias = dataMatrix.size + 1 == dataWithBiasSize
(0 until numClasses - 1).foreach i =>
var margin = 0.0
dataMatrix.foreachActive (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataWithBiasSize) + index)
if (withBias)
margin += weightsArray((i * dataWithBiasSize) + dataMatrix.size)
if (margin > maxMargin)
maxMargin = margin
bestClass = i + 1
bestClass.toDouble
LogisticRegression参数求解
Spark对LogisticRegression实现了两类优化求解算法,LogisticRegressionWithSGD和LogisticRegressionWithLBFGS。两类算法都使用的Logistic损失函数LogisticGradient 和L2正则化SquaredL2Updater。LogisticRegressionWithSGD和spark.mllib源码阅读-回归算法1-LinearRegression中介绍的回归方法训练模型思路一直,均是调用父类GeneralizedLinearAlgorithm的run方法来实现模型训练。
LogisticRegressionWithLBFGS类优化求解器采用的LBFGS(在spark.mllib源码阅读-优化算法3-Optimizer进行了相关的介绍),同时覆写了父类GeneralizedLinearAlgorithm的run方法。
if (numOfLinearPredictor == 1)
def runWithMlLogisticRegression(elasticNetParam: Double) =
// Prepare the ml LogisticRegression based on our settings
//调用了另外一个ML包的LogisticRegression实现,该实现只能处理二分类问题
val lr = new org.apache.spark.ml.classification.LogisticRegression()
lr.setRegParam(optimizer.getRegParam())
lr.setElasticNetParam(elasticNetParam)
lr.setStandardization(useFeatureScaling)
if (userSuppliedWeights)
val uid = Identifiable.randomUID("logreg-static")
lr.setInitialModel(new org.apache.spark.ml.classification.LogisticRegressionModel(uid,
new DenseMatrix(1, initialWeights.size, initialWeights.toArray),
Vectors.dense(1.0).asML, 2, false))
lr.setFitIntercept(addIntercept)
lr.setMaxIter(optimizer.getNumIterations())
lr.setTol(optimizer.getConvergenceTol())
// Convert our input into a DataFrame
val spark = SparkSession.builder().sparkContext(input.context).getOrCreate()
val df = spark.createDataFrame(input.map(_.asML))
// Determine if we should cache the DF
val handlePersistence = input.getStorageLevel == StorageLevel.NONE
// Train our model
val mlLogisticRegressionModel = lr.train(df, handlePersistence)
// convert the model
val weights = Vectors.dense(mlLogisticRegressionModel.coefficients.toArray)
createModel(weights, mlLogisticRegressionModel.intercept)
optimizer.getUpdater() match
case x: SquaredL2Updater => runWithMlLogisticRegression(0.0)
case x: L1Updater => runWithMlLogisticRegression(1.0)
case _ => super.run(input, initialWeights)
else
//这里调用了父类GeneralizedLinearAlgorithm的run进行模型训练
super.run(input, initialWeights)
二分类问题调用的是org.apache.spark.ml.classification.LogisticRegression(),这个是在Spark1.2后期版本加入的Logistic回归模型。
这里就有个疑问了,ml包下的Logistic回归模型和mllib下的Logistic回归模型有什么不同。
粗略看了二者的源码,在二分类问题上,不同点主要是ml.LogisticRegression加入了elastic net这样一个L1正则化和L2正则化这样一个调制因子。在多分类问题上,ml.LogisticRegression主要采用的是softmax函数来进行预测分类,K个类别的概率总和等于1。mllib.LogisticRegression使用的是OneVsAll就是把当前某一类看成一类,其他所有类别看作一类,这样有成了二分类的问题了,假如有k个类别,选取lable=0作为“pivot”类,则构建k-1个分类器:
classifier1:lable=0 VS lable=1
classifier2:lable=0 VS lable=2
classifierk-1:lable=0 VS lable=k-1
最后输出K-1个分类器中输出概率最大的那个类。并且这个概率是与Lable0事件相比的发生概率。OneVsAll假设了classifieri中lable=0与lable=i之间存在了关联性。
这就需要选取一个合适的“pivot”类了。
由于Logistic回归用于预测事件发生与否,如预测一个点击行为:不点击、点击A、点击B、点击C等,用户可能发生点击A,也可能发生点击A和B,重点是要找到最有可能发生的点击行为。那么可以使用lable="不点击"作为“pivot”类。
而如果选取lable="点击A"作为“pivot”类,就会出现问题了。
回过头来看ml.LogisticRegression,其是找到K个类别中输出概率最大的类,并且各类别的输出概率之和为1,同时,各类别发生与否是相互独立的。
以上是关于spark.mllib源码阅读-分类算法1-LogisticRegression的主要内容,如果未能解决你的问题,请参考以下文章