python数据分析与挖掘学习笔记_小说文本数据挖掘part1
Posted 小胖子小胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据分析与挖掘学习笔记_小说文本数据挖掘part1相关的知识,希望对你有一定的参考价值。
这一节主要是对小说文本数据的挖掘项目。文本挖掘的一个重要的应用是进行站点的个性化推荐。将用户感兴趣的信息推送给对应的用户,可以更好地发挥该信息的价值。比如,我们常常会在浏览网页的时候看到相关的广告是我们感兴趣的,新闻推送的是我们感兴趣的文章,阅读小说推荐的是我们想看的小说,逛淘宝的时候也会发现有一部分猜你喜欢,推荐的是你多半感兴趣的商品;网易云音乐的每日推荐曲目也是根据用户的听歌记录进行类似推荐的,等等。
这都是文本挖掘以及相关信息挖掘的技术实现。文本挖掘是数据挖掘技术的其中一种。文本挖掘是对现有的一些文本信息进行分析,处理,从而提取出一些有价值的信息供我们使用的一种技术。
进行个性化推荐的本质其实就是计算文本之间的相似度,推荐与用户浏览数据最相似的内容作为推荐,能够在最大程度上给用户推荐起感兴趣的内容。
实现的核心步骤为:
1、读取文档
2、对要计算的多篇文档进行分词
3、对文档进行整理成指定格式,方便后续进行计算
4、计算出词语的频率
5【可选】、对频率低的词语进行过滤
6、通过语料库建立词典
7、加载要对比的文档
8、将要对比的文档通过doc2bow转化为稀疏向量
9、对稀疏向量进行进一步处理,得到新语料库
10、将新语料库通过tfidfmodel进行处理,得到tfidf
11、通过token2id得到特征数
12、稀疏矩阵相似度,从而建立索引
13、得到最终相似度结果
要实现以上思路,我们需要用到python的中文分词工具包jieba,它的处理思路简单,主要思路如下:
1. 加载词典dict.txt, 我们是可以在该词典中添加词语的;
2. 从内存的词典中构建该句子的DAG(有向无环图);
3. 对于词典未收录词,使用HMM模型的viterbi算法尝试分词处理;
4. 已收录词和未收录词全部分词完毕后,使用dp寻找DAG的最大概率路径;
5. 输出分词结果。
当时记得有人问到,有没有英文分词工具,这个貌似是没有的,因为英文分词就是靠空格分割,不需要专门分词工具。
首先描述一下jieba的一些基本用法:
1. 全模式
sentence="我喜欢上海东方明珠"
w1=jieba.cut(sentence,cut_all=True)
for item in w1:
print(item)
print("")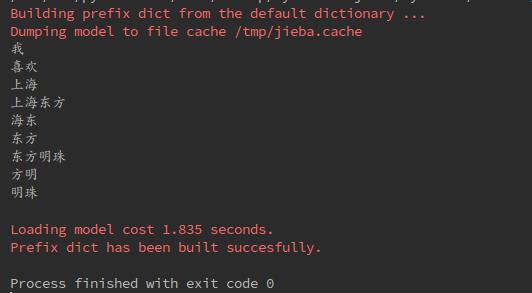
2. 精准模式
#精准模式
w2=jieba.cut(sentence,cut_all=False)
for item in w2:
print(item)
print("")
3. 搜索引擎模式
w3=jieba.cut_for_search(sentence)
for item in w3:
print(item)
print("")
4. 默认模式
w4=jieba.cut(sentence)
for item in w4:
print(item)
print("")默认的不加参数的模式为精准模式。

jieba还可以标注词语的词性:
#词性标注
import jieba.posseg
w5=jieba.posseg.cut(sentence)
#.flag词性
#.word词语
for item in w5:
print(item.word+"----"+item.flag)
print("")
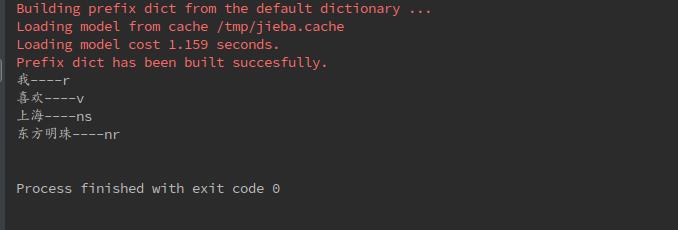
常用的一些符号及词性的对应关系为:
a:形容词
c:连词
d:副词
e:叹词
f:方位词
i:成语
m:数词
n:名词
nr:人名
ns:地名
nt:机构团体
nz:其他专有名词
p:介词
r:代词
t:时间
u:助词
v:动词
vn:名动词
w:标点符号
un:未知词语
5. 词典加载
需要导入jieba.posseg的包
import jieba.posseg
#词典加载
jieba.load_userdict("/home/hadoop/jieba/jieba/dict.txt")
sentence2 = "上海交通大学是一个很好的学校"
w6 = jieba.posseg.cut(sentence2)
for item in w6:
print(item.word+"----"+item.flag)
print("")
7. 提取关键字
需要导入jieba.analyse的包
import jieba.analyse
sentence3="我喜欢上海东方明珠"
print("")
#提取关键词
tag=jieba.analyse.extract_tags(sentence3, 3)
print(tag)
print("")
其中jieba.analyse.extract_tags(xx, num)中的num是指定提取的关键字的个数。
8. 返回词语的位置
可以通过tokenize中设置mode来制定模式
#返回词语的位置
w9=jieba.tokenize(sentence)
for item in w9:
print(item)
print("")
w10 = jieba.tokenize(sentence, mode="search")
for item in w10:
print(item)
print("")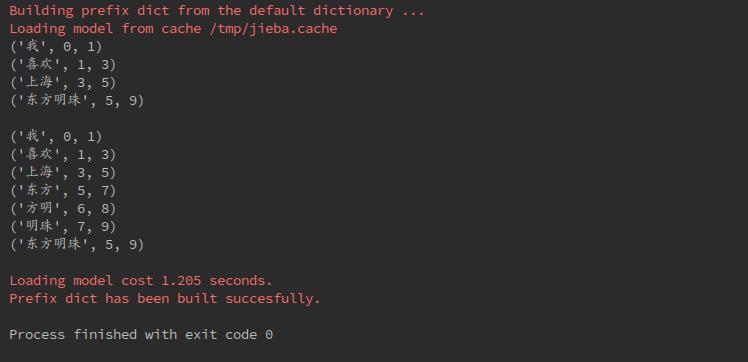
在导入一些中文的文档时,使用open(path).read()可能会出现编码问题,因此有老师建议将文档转为html,上传到本地服务器,使用urllib.request包来解决这个问题。
#编码问题解决方案
#data=open("./fiction.txt","r",encoding='utf-8').read()
import urllib.request
data = urllib.request.urlopen("http://127.0.0.1/fiction.html").read().decode("utf-8", "ignore")
tag = jieba.analyse.extract_tags(data, 30) #jieba.analyse.extract_tags(sentence, topK), topK的默认值为20
print(tag)
"""好了。基础部分差不多介绍到这里,下面就是开始进行文本挖掘和相似度的计算。
部分内容引用自:https://segmentfault.com/a/1190000004061791
以上是关于python数据分析与挖掘学习笔记_小说文本数据挖掘part1的主要内容,如果未能解决你的问题,请参考以下文章