使用Spark读写Parquet文件验证Parquet自带表头的性质及NULL值来源Java
Posted 虎鲸不是鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Spark读写Parquet文件验证Parquet自带表头的性质及NULL值来源Java相关的知识,希望对你有一定的参考价值。
使用Spark读写Parquet文件验证Parquet自带表头的性质及NULL值来源【Java】
前言
地主家的集群从CDH5.16升级到CDP7.1.5时,遇到了一个很头疼的NULL值问题。老一套集群是IBM DataStage运算后写入Hive的HDFS路径,我等短工们作为大数据学徒工,自然是不晓得DataStage有神马黑科技,可以做到很多本该是NULL的字段居然自动变成了""这种空String。到了CDP7我们使用阿里云DataPhin,硬翻HQL任务后,理所当然并没有做类似:
select
nvl(col1,'') as col1
from
db1.tb1
;
的这种骚操作,也就出现了一大坨的NULL值。这种情况下给业务的报表也很难看。由于CDP7我们统一采用Parquet格式,故笔者使用Spark读写Parquet文件,向SQL Boy们科普Parquet自带表头【schema】的性质,且要通过演示,证明NULL值是存储在Parquet文件块中的,而非存储在Hive中。当然也就不需要对Hive多动脑筋。
Java代码
POM依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<scala.version>2.12.12</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.3.0</spark.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>$scala.version</version>
</dependency>
<!-- 添加spark依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_$scala.binary.version</artifactId>
<version>$spark.version</version>
</dependency>
<!-- 可以使用Lombok的@注解-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.20</version>
</dependency>
<!-- mysql驱动包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<encoding>$project.build.sourceEncoding</encoding>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<!--
zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF -->
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 可以设置jar包的入口类(可选) -->
<!--<mainClass>com.aa.flink.StreamWordCount</mainClass>-->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Spark写Parquet文件块
package com.zhiyong.parquet;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StringType;
/**
* @program: zhiyong_study
* @description: 测试Parquet
* @author: zhiyong
* @create: 2022-11-04 20:13
**/
public class test1
public static void main(String[] args)
SparkSession spark = SparkSession.builder().appName("测试写Parquet")
.master("local[2]")
.getOrCreate();
Dataset<Long> ds1 = spark.range(10);
Dataset<Row> df1 = ds1.toDF("id");
//df1.show();//输出id,内容0->9
Dataset<Row> df2 = df1.withColumn("name", functions.lit("战斗暴龙兽").cast(DataTypes.StringType));
//df2.show();//输出id和name,内容 0|战斗暴龙兽->9|战斗暴龙兽
Dataset<Row> df3 = df2
.withColumn("name_id", functions.concat_ws("^", df2.col("name"), df2.col("id")));
//df3.show();//输出name和id拼接,内容 0|战斗暴龙兽|战斗暴龙兽^0->9|战斗暴龙兽|战斗暴龙兽^9
Dataset<Row> df4 = df3.filter("id%3=1");//获取一些数据
//df4.show();//过滤出只有id=1,4,7的数据
Dataset<Row> df5 = df4.selectExpr("id", "name", "null as name_id");
//df5.show();
//df5.filter("name_id is NULL").show();//null生效
Dataset<Row> df6 = df3.filter("id%3!=1").unionAll(df5);
df6=df6.sort(df6.col("id").asc());
//df6.show();排序
//df6.write().mode(SaveMode.Append).parquet("file:///E:/tempdata/20221104/parquet");
String[] str = "name_id";
Dataset<Row> df7 = df6.na().fill("Na1",str);
df7.show();
为了方便,笔者连Hive都没有连接,直接造了10条数据,然后取了3条将name_id这个拼接的字段值置为NULL,最后直接写入到Win10宿主机的本地路径:

可以看到已经将Parquet文件写到了Win10的本地E:\\tempdata\\20221104\\parquet路径。接下来就可以读取这个Parquet文件查看内容。
Spark读Parquet文件块
package com.zhiyong.parquet;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.StructField;
/**
* @program: zhiyong_study
* @description: 测试读Parquet
* @author: zhiyong
* @create: 2022-11-04 20:54
**/
public class test2
public static void main(String[] args)
SparkSession spark = SparkSession.builder().appName("测试读Parquet")
.master("local[2]")
.getOrCreate();
Dataset<Row> df1 = spark.read().parquet("file:///E:/tempdata/20221104/parquet");
df1.show();
String[] schema_name = df1.schema().names();
StringBuilder strb = new StringBuilder();
System.out.print("表头:");
for (String s : schema_name)
System.out.print(s + "\\t");
StructField[] schema = df1.schema().fields();
for (StructField structField : schema)
DataType dataType = structField.dataType();
String name = structField.name();
System.out.println("dataType = " + dataType + "\\tname=" + name);
if (dataType.toString().equalsIgnoreCase("StringType"))
if (strb.length()>0)
strb.append(",");
strb.append(name);
String[] split = strb.toString().split(",");
Dataset<Row> fillDf = df1.na().fill("***", split);
fillDf.show();
为了方便,直接从本地读这个路径的Parquet文件块即可:
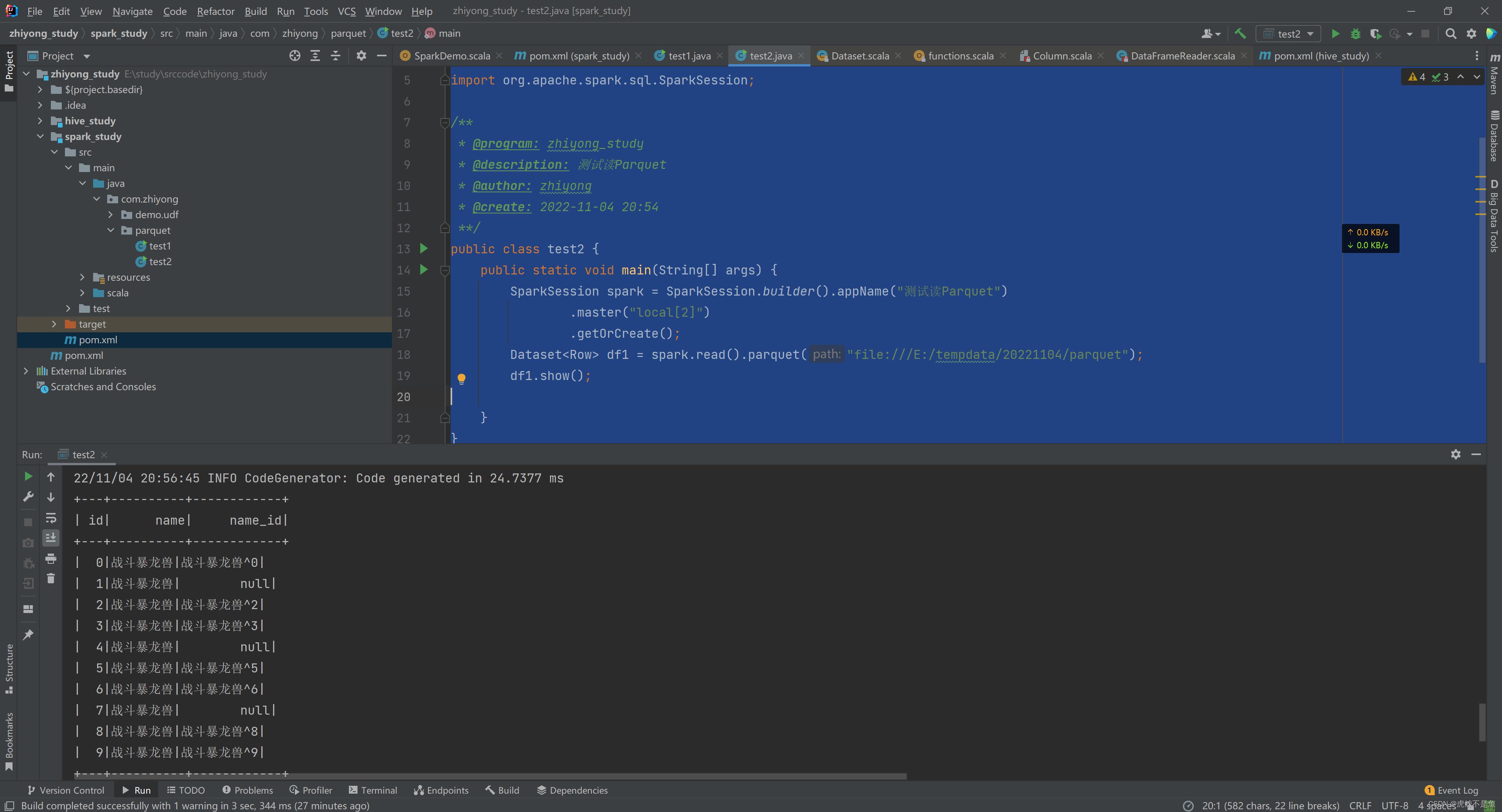
结论
此时可以看到,事实胜于雄辩。Parquet文件块本身就存储了表头信息【Schema】,且在数据文件中本身就存储了null,不只是Hive读Parquet会出现NULL,Spark会,Impala也会。。。
Hive参数总共几千个:https://lizhiyong.blog.csdn.net/article/details/126634922
在Hiveconf.java源码文件中也搜索了一波,没找到和Parquet、NULL等非常相关的参数。
所以,想要解决NULL的情况,一定要对Parquet文件块做修正,确保Parquet文件块中本身就不存在NULL值,而不是妄想设置Hive的参数实现读数据时自动将NULL转为""空String。
当然也没啥好办法。。。要不在每个HQL任务最后一步:
insert overwrite table db1.tb1
select
nvl(col1,'') as col1
from
db2.tb2
;
做nvl空值处理,要不就使用Spark或者Flink对Parquet文件做空值填充的修复。
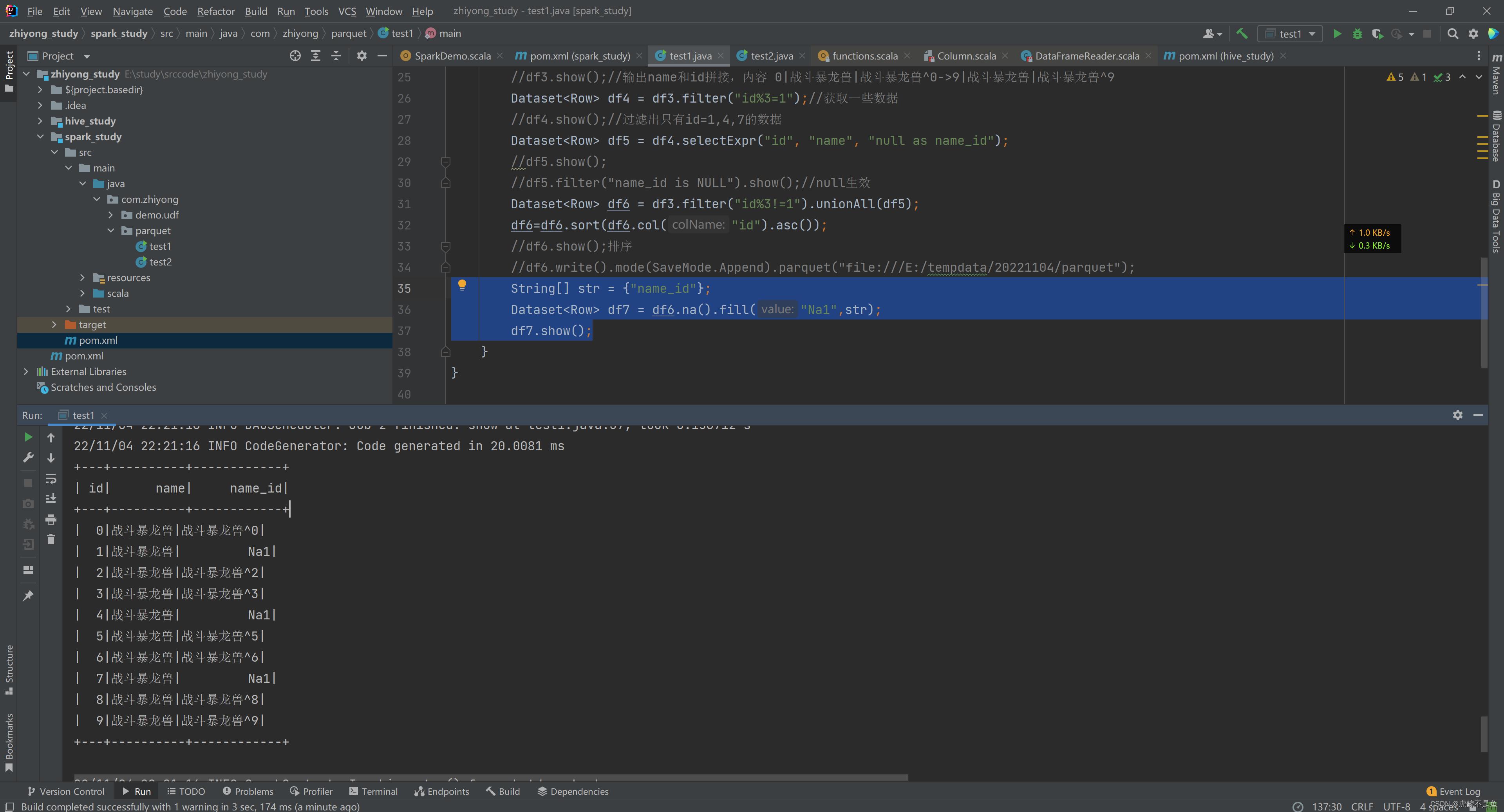
这样可以填充NULL值。
甚至可以自动对String类型的所有字段做空值填充:

Java实现起来比SQL还是要方便很多。
总归是没想到啥太好的解决方法。。。
转载请注明出处:https://lizhiyong.blog.csdn.net/article/details/127697083

以上是关于使用Spark读写Parquet文件验证Parquet自带表头的性质及NULL值来源Java的主要内容,如果未能解决你的问题,请参考以下文章