C++实战之OpenCL矩阵相乘优化
Posted 哇小明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++实战之OpenCL矩阵相乘优化相关的知识,希望对你有一定的参考价值。
前言
上一篇文章,分析了简单的矩阵相乘在opencl里面的优化kernel代码,每个work-item只负责计算结果矩阵的一个元素。下一步准备每次计算出结果矩阵的块元素,看看计算时间是如何。
这个矩阵系列参考国外一个大神的教程:
https://cnugteren.github.io/tutorial/pages/page4.html
有每个kernel的详解工程,还有github代码工程。
具体分析
这里引入opencl内存的概念:
比较常见的有:
全局内存 __global 修饰符,通常修饰指向一个数据类型的地址,
本地内存 __local 修饰符。local 定义的变量在一个work-group中是共享的,也就是说一个work-group中的所有work-item都可以通过本地内存来进行通信,
私有内存,private 每个work-item里的内部变量
常量内存, constant
下面是opencl的内存模型:
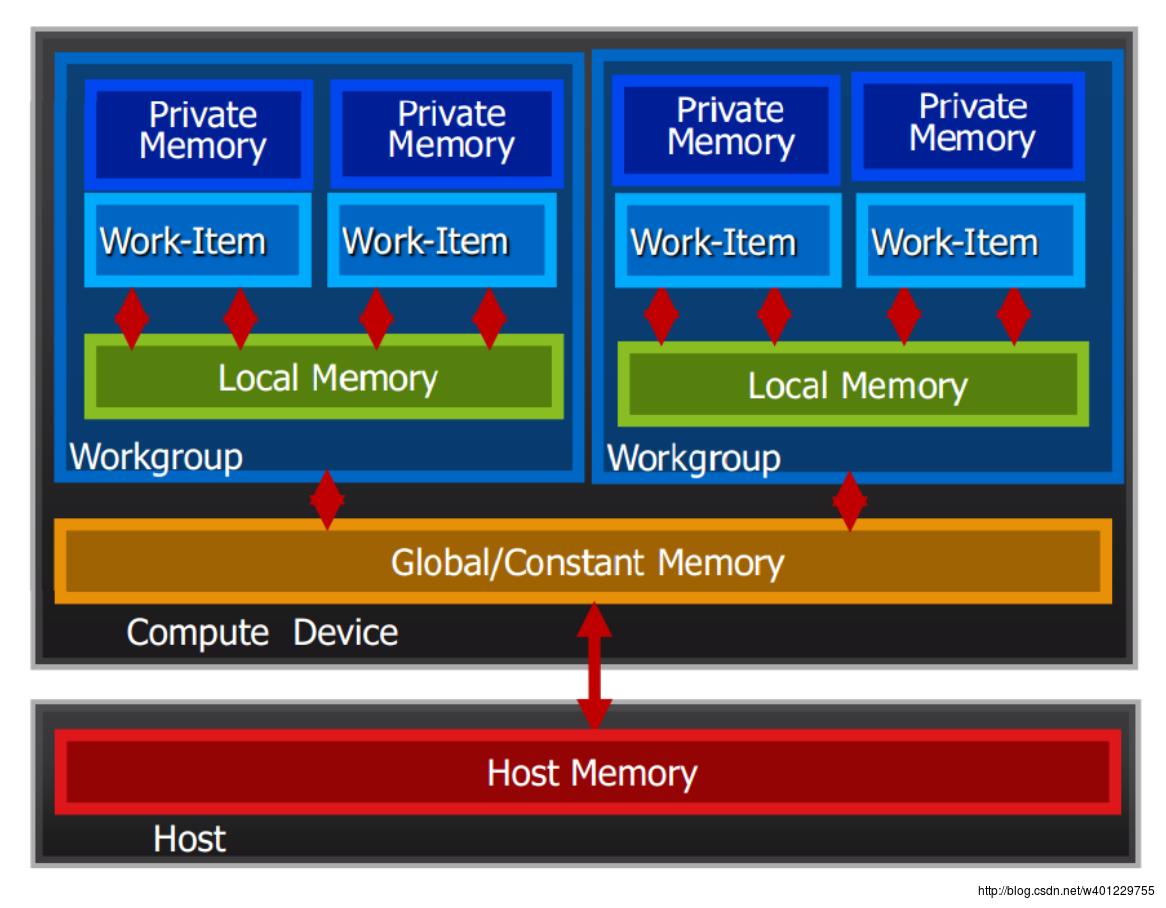
我们分析一下之前的矩阵相乘的一些性能:
__kernel void hello_kernel(__global const int *a,
__global const int *b,
__global int *result_matrix,int result_matrix_row,
int result_matrix_col,int compute_size)
int row = get_global_id(0);
int col = get_global_id(1);
int sum = 0;
for(int i=0;i<compute_size;i++)
sum += a[row*compute_size+i] * b[i*result_matrix_col+col];
result_matrix[row*result_matrix_col+col] = sum;
首先在运行时总共有M*N个work-item同时执行,每个work-item中执行一个size为k(computesize)的for循环,循环里面每次分别load 数组a和b中的一个元素,所以综合起来一个kernel会有 M*N*K*2 个加载global内存的操作,乘以2是因为a,b两个数组。
其次每个work-item计算出结果矩阵的一个元素并保存,所以有M*N个对global内存的 store 的操作。
由上图的内存模型可知这种访问并不是最优的,再同一个work-group中我们可以定义local内存,来减少这种操作。
下面摘自国外博客的配图说明一下这次优化的原理:

其实就是把之前row*col的方式变成了 多个row和col相乘,究其本质还是对应元素相乘再相加。
这边的中心思想是引入work-group分块计算再相加,work-item的大小还是没变为M*N,不同的是在同一个work-group中把global数组A和B的对应值保存在local内存中,之后每个work-item在这个group中访问这个local变量速度会相对访问global较快,后面的大小为k的循环访问的也是local内存,所以在这个点上是被优化了。先看一下代码实现:
__kernel void hello_kernel(const __global int* A,
const __global int* B,
__global int* C, int M, int N, int K)
// Thread identifiers
const int row = get_local_id(0); // Local row ID (max: TS)
const int col = get_local_id(1); // Local col ID (max: TS)
const int globalRow = TS*get_group_id(0) + row; // Row ID of C (0..M)
const int globalCol = TS*get_group_id(1) + col; // Col ID of C (0..N)
// Local memory to fit a tile of TS*TS elements of A and B
__local int Asub[TS][TS];
__local int Bsub[TS][TS];
// Initialise the accumulation register
int acc = 0;
// Loop over all tiles
const int numTiles = K/TS;
for (int t=0; t<numTiles; t++)
// Load one tile of A and B into local memory
const int tiledRow = TS*t + row;
const int tiledCol = TS*t + col;
Asub[col][row] = A[tiledCol*M + globalRow];
Bsub[col][row] = B[globalCol*K + tiledRow];
printf("Asub[%d][%d]=A[%d]=%d\\t",col,row,tiledCol*M + globalRow,A[tiledCol*M + globalRow]);
// Synchronise to make sure the tile is loaded
barrier(CLK_LOCAL_MEM_FENCE);
// Perform the computation for a single tile
for (int k=0; k<TS; k++)
acc += Asub[k][row] * Bsub[col][k];
//printf("acc[%d][%d]=%d\\n",k,row,Asub[k][row]);
printf("acc = %d\\n",acc);
// Synchronise before loading the next tile
barrier(CLK_LOCAL_MEM_FENCE);
// Store the final result in C
C[globalCol*M + globalRow] = acc;
下面具体分析一下这个kernel在运行时的的运行情况:
线看一下cpu端的配置:
#define TS 16
size_t globalWorkSize[2];
globalWorkSize[0]= heightA;
globalWorkSize[1]=widthB;
size_t localWorkSize[2] ;
localWorkSize[0]= TS;
localWorkSize[1]= TS;
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
globalWorkSize, localWorkSize,
0, NULL, NULL);
这边新加了localworksize的参数,并且设置大小为16,这里设置大小是有讲究的:
首先TS 必须为2的幂次方
也就是
localWorkSize[0]*localWorkSize[1] <= CL_DEVICE_MAX_WORK_GROUP_SIZE 要怎么知道自己机器的这个size呢?可以通过
size_t maxWorkItemPerGroup;
clGetDeviceInfo(device, CL_DEVICE_MAX_WORK_GROUP_SIZE,sizeof(maxWorkItemPerGroup), &maxWorkItemPerGroup, NULL);
printf("maxWorkItemPerGroup: %zd\\n", maxWorkItemPerGroup);
我这边打印的结果是256,也就是说我这边group的size最大只能设置到16.(16*16=256)
接下来看kernel的实现细节:
const int row = get_local_id(0); // Local row ID (max: TS)
const int col = get_local_id(1); // Local col ID (max: TS)get_local_id 这一组操作主要是获取work-group中当前work-item所在的2d索引。
const int globalRow = TS*get_group_id(0) + row; // Row ID of C (0..M)
const int globalCol = TS*get_group_id(1) + col; // Col ID of C (0..N)这个是通过当前work-item所在的group-id和自己在此group中的索引计算出,当前work-item在全局的索引。get_group_id是获取当前work-item所在work-group的id。
__local int Asub[TS][TS];
__local int Bsub[TS][TS];定义local 内存,在同一个work-group对所有work-item可见。
const int numTiles = K/TS;这个是一个work-item 需要循环计算的group的数量,这边可以知道,K也要为TS的倍数才行。
for (int t=0; t<numTiles; t++)
// Load one tile of A and B into local memory
const int tiledRow = TS*t + row;
const int tiledCol = TS*t + col;
Asub[col][row] = A[tiledCol*M + globalRow];
Bsub[col][row] = B[globalCol*K + tiledRow];
printf("Asub[%d][%d]=A[%d]=%d\\t",col,row,tiledCol*M + globalRow,A[tiledCol*M + globalRow]);
// Synchronise to make sure the tile is loaded
barrier(CLK_LOCAL_MEM_FENCE);
// Perform the computation for a single tile
for (int k=0; k<TS; k++)
acc += Asub[k][row] * Bsub[col][k];
//printf("acc[%d][%d]=%d\\n",k,row,Asub[k][row]);
printf("acc = %d\\n",acc);
// Synchronise before loading the next tile
barrier(CLK_LOCAL_MEM_FENCE);
主要核心就是这个for循环,循环一进来首先计算此时work-item在当前块的索引位置
然后开始从global内存中把数组A和B 中每块大小为16*16的值储存到本地内存上。用串行的思想去看这段代码,会比较困难。这边有个barrier(CLK_LOCAL_MEM_FENCE); 关键语句,作用就是用来再work-group中同步所有work-item。也就是说只有当前work-group中所有的work-item到达这个点,换个意思就是要保证Asub和Bsub两个大小为16*16大小本地内存被赋值完毕,16*16个work-item必须全部达到这个点,才会继续下去执行。
接下去是一个k循环,前面已经得到了A和B的两个子矩阵并被保存在本地内存中,通过行列相乘相加得到一个子矩阵上的结果,一个work-item一样也只计算出一个元素,一个work-group计算出结果矩阵对应的子矩阵全部元素。
接下去又是一个同步:这个同步是保证这一个分块或者说group全部计算完毕,再去load下一个分块。一个大循环结束后,就计算出结果矩阵对应的一个元素了,把它保存在global内存中:
// Store the final result in C
C[globalCol*M + globalRow] = acc;下面是主代码:
//
// main.cpp
// OpenCL
//
// Created by wmy on 2017/9/19.
// Copyright © 2017年 wmy. All rights reserved.
//
#include <OpenCL/OpenCL.h>
#include <iostream>
#include <fstream>
#include <sstream>
#include <unistd.h>
#include <sys/time.h>
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include <mach/mach_time.h>
#include <boost/algorithm/string.hpp>
using namespace std;
//const int ARRAY_SIZE = 100000;
//4*3---3*5
const int midle = 32;
const int heightA = 32;
const int widthB = 32;
//const int heightB = 3;
//一、 选择OpenCL平台并创建一个上下文
cl_context CreateContext()
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
//选择可用的平台中的第一个
errNum = clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0)
std::cerr << "Failed to find any OpenCL platforms." << std::endl;
return NULL;
//创建一个OpenCL上下文环境
cl_context_properties contextProperties[] =
CL_CONTEXT_PLATFORM,
(cl_context_properties)firstPlatformId,
0
;
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_GPU,
NULL, NULL, &errNum);
return context;
//二、 创建设备并创建命令队列
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id *device)
cl_int errNum;
cl_device_id *devices;
cl_command_queue commandQueue = NULL;
size_t deviceBufferSize = -1;
// 获取设备缓冲区大小
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &deviceBufferSize);
if (deviceBufferSize <= 0)
std::cerr << "No devices available.";
return NULL;
// 为设备分配缓存空间
devices = new cl_device_id[deviceBufferSize / sizeof(cl_device_id)];
printf("deviceBufferSize / sizeof(cl_device_id)=%ld\\n",deviceBufferSize / sizeof(cl_device_id));
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, deviceBufferSize, devices, NULL);
// size_t valueSize;
// clGetDeviceInfo(devices[0], CL_DEVICE_NAME, 0, NULL, &valueSize);
// char* value = (char*) malloc(valueSize);
// clGetDeviceInfo(devices[0], CL_DEVICE_NAME, valueSize, value, NULL);
// printf("Device1 Name: %s\\n", value);
// free(value);
//
// clGetDeviceInfo(devices[1], CL_DEVICE_NAME, 0, NULL, &valueSize);
// value = (char*) malloc(valueSize);
// clGetDeviceInfo(devices[1], CL_DEVICE_NAME, valueSize, value, NULL);
// printf("Device2 Name: %s\\n", value);
// free(value);
//选取可用设备中的第一个
commandQueue = clCreateCommandQueue(context, devices[1], 0, NULL);
*device = devices[0];
delete[] devices;
return commandQueue;
// 三、创建和构建程序对象
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName)
cl_int errNum;
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
if (!kernelFile.is_open())
std::cerr << "Failed to open file for reading: " << fileName << std::endl;
return NULL;
std::ostringstream oss;
oss << kernelFile.rdbuf();
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
program = clCreateProgramWithSource(context, 1,
(const char**)&srcStr,
NULL, NULL);
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
return program;
//创建和构建程序对象
bool CreateMemObjects(cl_context context, cl_mem memObjects[3],
int *a, int *b)
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(int) * midle*heightA, a, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(int) * widthB*midle, b, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE,
sizeof(int) * widthB*heightA, NULL, NULL);
return true;
// 释放OpenCL资源
void Cleanup(cl_context context, cl_command_queue commandQueue,
cl_program program, cl_kernel kernel, cl_mem memObjects[3])
for (int i = 0; i < 3; i++)
if (memObjects[i] != 0)
clReleaseMemObject(memObjects[i]);
if (commandQueue != 0)
clReleaseCommandQueue(commandQueue);
if (kernel != 0)
clReleaseKernel(kernel);
if (program != 0)
clReleaseProgram(program);
if (context != 0)
clReleaseContext(context);
void checkError(cl_int error, int line)
if (error != CL_SUCCESS)
switch (error)
case CL_DEVICE_NOT_FOUND: printf("-- Error at %d: Device not found.\\n", line); break;
case CL_DEVICE_NOT_AVAILABLE: printf("-- Error at %d: Device not available\\n", line); break;
case CL_COMPILER_NOT_AVAILABLE: printf("-- Error at %d: Compiler not available\\n", line); break;
case CL_MEM_OBJECT_ALLOCATION_FAILURE: printf("-- Error at %d: Memory object allocation failure\\n", line); break;
case CL_OUT_OF_RESOURCES: printf("-- Error at %d: Out of resources\\n", line); break;
case CL_OUT_OF_HOST_MEMORY: printf("-- Error at %d: Out of host memory\\n", line); break;
case CL_PROFILING_INFO_NOT_AVAILABLE: printf("-- Error at %d: Profiling information not available\\n", line); break;
case CL_MEM_COPY_OVERLAP: printf("-- Error at %d: Memory copy overlap\\n", line); break;
case CL_IMAGE_FORMAT_MISMATCH: printf("-- Error at %d: Image format mismatch\\n", line); break;
case CL_IMAGE_FORMAT_NOT_SUPPORTED: printf("-- Error at %d: Image format not supported\\n", line); break;
case CL_BUILD_PROGRAM_FAILURE: printf("-- Error at %d: Program build failure\\n", line); break;
case CL_MAP_FAILURE: printf("-- Error at %d: Map failure\\n", line); break;
case CL_INVALID_VALUE: printf("-- Error at %d: Invalid value\\n", line); break;
case CL_INVALID_DEVICE_TYPE: printf("-- Error at %d: Invalid device type\\n", line); break;
case CL_INVALID_PLATFORM: printf("-- Error at %d: Invalid platform\\n", line); break;
case CL_INVALID_DEVICE: printf("-- Error at %d: Invalid device\\n", line); break;
case CL_INVALID_CONTEXT: printf("-- Error at %d: Invalid context\\n", line); break;
case CL_INVALID_QUEUE_PROPERTIES: printf("-- Error at %d: Invalid queue properties\\n", line); break;
case CL_INVALID_COMMAND_QUEUE: printf("-- Error at %d: Invalid command queue\\n", line); break;
case CL_INVALID_HOST_PTR: printf("-- Error at %d: Invalid host pointer\\n", line); break;
case CL_INVALID_MEM_OBJECT: printf("-- Error at %d: Invalid memory object\\n", line); break;
case CL_INVALID_IMAGE_FORMAT_DESCRIPTOR: printf("-- Error at %d: Invalid image format descriptor\\n", line); break;
case CL_INVALID_IMAGE_SIZE: printf("-- Error at %d: Invalid image size\\n", line); break;
case CL_INVALID_SAMPLER: printf("-- Error at %d: Invalid sampler\\n", line); break;
case CL_INVALID_BINARY: printf("-- Error at %d: Invalid binary\\n", line); break;
case CL_INVALID_BUILD_OPTIONS: printf("-- Error at %d: Invalid build options\\n", line); break;
case CL_INVALID_PROGRAM: printf("-- Error at %d: Invalid program\\n", line); break;
case CL_INVALID_PROGRAM_EXECUTABLE: printf("-- Error at %d: Invalid program executable\\n", line); break;
case CL_INVALID_KERNEL_NAME: printf("-- Error at %d: Invalid kernel name\\n", line); break;
case CL_INVALID_KERNEL_DEFINITION: printf("-- Error at %d: Invalid kernel definition\\n", line); break;
case CL_INVALID_KERNEL: printf("-- Error at %d: Invalid kernel\\n", line); break;
case CL_INVALID_ARG_INDEX: printf("-- Error at %d: Invalid argument index\\n", line); break;
case CL_INVALID_ARG_VALUE: printf("-- Error at %d: Invalid argument value\\n", line); break;
case CL_INVALID_ARG_SIZE: printf("-- Error at %d: Invalid argument size\\n", line); break;
case CL_INVALID_KERNEL_ARGS: printf("-- Error at %d: Invalid kernel arguments\\n", line); break;
case CL_INVALID_WORK_DIMENSION: printf("-- Error at %d: Invalid work dimensionsension\\n", line); break;
case CL_INVALID_WORK_GROUP_SIZE: printf("-- Error at %d: Invalid work group size\\n", line); break;
case CL_INVALID_WORK_ITEM_SIZE: printf("-- Error at %d: Invalid work item size\\n", line); break;
case CL_INVALID_GLOBAL_OFFSET: printf("-- Error at %d: Invalid global offset\\n", line); break;
case CL_INVALID_EVENT_WAIT_LIST: printf("-- Error at %d: Invalid event wait list\\n", line); break;
case CL_INVALID_EVENT: printf("-- Error at %d: Invalid event\\n", line); break;
case CL_INVALID_OPERATION: printf("-- Error at %d: Invalid operation\\n", line); break;
case CL_INVALID_GL_OBJECT: printf("-- Error at %d: Invalid OpenGL object\\n", line); break;
case CL_INVALID_BUFFER_SIZE: printf("-- Error at %d: Invalid buffer size\\n", line); break;
case CL_INVALID_MIP_LEVEL: printf("-- Error at %d: Invalid mip-map level\\n", line); break;
case -1024: printf("-- Error at %d: *clBLAS* Functionality is not implemented\\n", line); break;
case -1023: printf("-- Error at %d: *clBLAS* Library is not initialized yet\\n", line); break;
case -1022: printf("-- Error at %d: *clBLAS* Matrix A is not a valid memory object\\n", line); break;
case -1021: printf("-- Error at %d: *clBLAS* Matrix B is not a valid memory object\\n", line); break;
case -1020: printf("-- Error at %d: *clBLAS* Matrix C is not a valid memory object\\n", line); break;
case -1019: printf("-- Error at %d: *clBLAS* Vector X is not a valid memory object\\n", line); break;
case -1018: printf("-- Error at %d: *clBLAS* Vector Y is not a valid memory object\\n", line); break;
case -1017: printf("-- Error at %d: *clBLAS* An input dimension (M,N,K) is invalid\\n", line); break;
case -1016: printf("-- Error at %d: *clBLAS* Leading dimension A must not be less than the size of the first dimension\\n", line); break;
case -1015: printf("-- Error at %d: *clBLAS* Leading dimension B must not be less than the size of the second dimension\\n", line); break;
case -1014: printf("-- Error at %d: *clBLAS* Leading dimension C must not be less than the size of the third dimension\\n", line); break;
case -1013: printf("-- Error at %d: *clBLAS* The increment for a vector X must not be 0\\n", line); break;
case -1012: printf("-- Error at %d: *clBLAS* The increment for a vector Y must not be 0\\n", line); break;
case -1011: printf("-- Error at %d: *clBLAS* The memory object for Matrix A is too small\\n", line); break;
case -1010: printf("-- Error at %d: *clBLAS* The memory object for Matrix B is too small\\n", line); break;
case -1009: printf("-- Error at %d: *clBLAS* The memory object for Matrix C is too small\\n", line); break;
case -1008: printf("-- Error at %d: *clBLAS* The memory object for Vector X is too small\\n", line); break;
case -1007: printf("-- Error at %d: *clBLAS* The memory object for Vector Y is too small\\n", line); break;
case -1001: printf("-- Error at %d: Code -1001: no GPU available?\\n", line); break;
default: printf("-- Error at %d: Unknown with code %d\\n", line, error);
exit(1);
#define TIMES 10
#define TS 16
int main(int argc, char** argv)
cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
cl_mem memObjects[3] = 0, 0, 0 ;
cl_int errNum;
// uint64_t t1,t2,t3;
clock_t t1,t2,t3,t4;
const char* filename = "/Users/wangmingyong/Projects/OpenCL/OpenCL/HelloWorld.cl";
// 一、选择OpenCL平台并创建一个上下文
context = CreateContext();
// 二、 创建设备并创建命令队列
commandQueue = CreateCommandQueue(context, &device);
size_t maxWorkItemPerGroup;
clGetDeviceInfo(device, CL_DEVICE_MAX_WORK_GROUP_SIZE,sizeof(maxWorkItemPerGroup), &maxWorkItemPerGroup, NULL);
printf("maxWorkItemPerGroup: %zd\\n", maxWorkItemPerGroup);
size_t valueSize;
clGetDeviceInfo(device, CL_DEVICE_NAME, 0, NULL, &valueSize);
char* value = (char*) malloc(valueSize);
clGetDeviceInfo(device, CL_DEVICE_NAME, valueSize, value, NULL);
printf("Device Name: %s\\n", value);
free(value);
//创建和构建程序对象
program = CreateProgram(context, device, filename);//"HelloWorld.cl");
// 四、 创建OpenCL内核并分配内存空间
kernel = clCreateKernel(program, "hello_kernel", NULL);
//创建要处理的数据
int result[widthB*heightA]0;
int a[midle*heightA];
int b[widthB*midle];
for (int i = 0; i < heightA; i++)
for(int j = 0;j < midle;j++)
a[i*midle+j]=2;//10.0f * ((int) rand() / (int) RAND_MAX);
for (int k = 0; k < midle; k++)
for(int m = 0;m < widthB;m++)
b[k*widthB+m]=3;//10.0f * ((int) rand() / (int) RAND_MAX);
t1 = clock(); //mach_absolute_time();
//printf("t1 = %.8f\\n",(double)t1);
for(int tt=0;tt<TIMES;tt++)
for(int l=0;l<heightA;l++)
for(int n = 0;n<widthB;n++)
for(int q=0;q<midle;q++)
result[l*widthB+n] +=a [l*midle+q]*b[q*widthB+n];
//std::cout<<"r = "<<result[l*widthB+n]<<std::endl;
t2 = clock(); //mach_absolute_time();
//printf("t2 = %.8f\\n",(double)t2);
//创建内存对象
if (!CreateMemObjects(context, memObjects, a, b))
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
// 五、 设置内核数据并执行内核
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
errNum |= clSetKernelArg(kernel, 3, sizeof(int), &heightA);
errNum |= clSetKernelArg(kernel, 4, sizeof(int), &widthB);
errNum |= clSetKernelArg(kernel, 5, sizeof(int), &midle);
size_t globalWorkSize[2];
globalWorkSize[0]= heightA;
globalWorkSize[1]=widthB;
size_t localWorkSize[2] ;
localWorkSize[0]= TS;
localWorkSize[1]= TS;
t3 = clock();
for(int run=0;run<TIMES;run++)
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
globalWorkSize, localWorkSize,
0, NULL, NULL);
checkError(errNum,__LINE__);
if(errNum == CL_SUCCESS)
cout<<"enqueue success!"<<endl;
else
printf("errNum= %d\\n",errNum);
//mach_absolute_time();
// 六、 读取执行结果并释放OpenCL资源
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE,
0, widthB*heightA * sizeof(int), result,
0, NULL, NULL);
// for(int p=0;p<20;p++)
// cout<<"new ="<<result[p];
//
t4 = clock();
printf("cpu t = %.8f\\n",(float)(t2-t1)/CLOCKS_PER_SEC/TIMES);
printf("gpu t = %.8f \\n",(double)(t4-t3)/CLOCKS_PER_SEC/TIMES);
std::cout << std::endl;
std::cout << "Executed program succesfully." << std::endl;
getchar();
Cleanup(context, commandQueue, program, kernel, memObjects);
return 0;
下面是时间性能分析:
| 维度 | cpu | gpu |
|---|---|---|
| 32*32 | 0.00010410 | 0.00040870 |
| 128*128 | 0.00676160 | 0.00040980 |
| 512*512 | 0.52244419 | 0.00058840 |
这是跟之前的kernel性能相比:
| 维度 | gpu1 | gpu2 |
|---|---|---|
| 32*32 | 0.00029130 | 0.00040870 |
| 128*128 | 0.00036250 | 0.00040980 |
| 512*512 | 0.00056370 | 0.00058840 |
貌似时间都差不多,我这边把readbuffer的操作去掉发现时间少了很多,但是跟前一个kernel的都在同一个数量级差不多的时间,我这边维数改到1024程序就会报错,所以验证不了高维度的性能。后续跟踪下程序为什么限制到了1024,不知是否是机器的原因。
kernel1
512 gpu t = 0.00000460
128 gpu t = 0.00000400
32 0.00000360
kernel2
512 0.00000320
128 gpu t = 0.00000310
32 0.00000370
以上是关于C++实战之OpenCL矩阵相乘优化的主要内容,如果未能解决你的问题,请参考以下文章