Hadoop3 - MapReduce SequenceFile MapFile 格式存储
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop3 - MapReduce SequenceFile MapFile 格式存储相关的知识,希望对你有一定的参考价值。
一、MapReduce 小文件问题
上篇文章说 MapReduce 并行机制时,讲到如果是针对小于 block 的小文件的话,会每个拆分成一个 MapTask 导致对大量小文件的处理,另外 HDFS 对大量小文件的存储效率其实也是不高,MapReduce在读取小文件进行处理时,也存在资源浪费导致计算效率不高的问题。
因此针对于小文件可以进行合并为一个大文件从而提高提高访问效率。文件的合并压缩有 SequenceFile 或者 MapFile 两种不错的方案。
二、SequenceFile
SequenceFile 是 hadoop 里用来存储序列化的键值对即二进制的一种文件格式。也可以作为 MapReduce 作业的输入和输出,其中 Hive 和Spark 也支持这种格式 。
它有如下优点:
-
二进制的KV形式存储数据:底层交互更加友好,性能更快,所以可以在
HDFS里存储图像或者更加复杂的结构作为KV对。 -
支持压缩和分片:当你压缩为一个
SequenceFile时,并不是将整个文件压缩成一个单独的单元,而是压缩文件里的record或者block of records(块)。即使使用的压缩方式如Snappy, Lz4 or Gzip不支持分片,也可以利用SequenceFIle来实现分片。 -
可以用于存储多个小文件:由于
Hadoop本身就是用来处理大型文件的,小文件是不适合的,所以用一个SequenceFile来存储很多小文件就可以提高处理效率,也能节省Namenode内存,因为Namenode只需一个SequenceFile的metadata,而不是为每个小文件创建单独的metadata。 -
IO性能更好:由于数据是以
SequenceFile形式存储,所以中间输出文件即map输出也会用SequenceFile来存储,可以提高整体的IO开销性能。
MapReduce 中使用,可以通过 job.setInputFormatClass、job.setOutputFormatClass 指定输入输出类型,还可以使用SequenceFileOutputFormat.setOutputCompressionType 指定压缩格式:
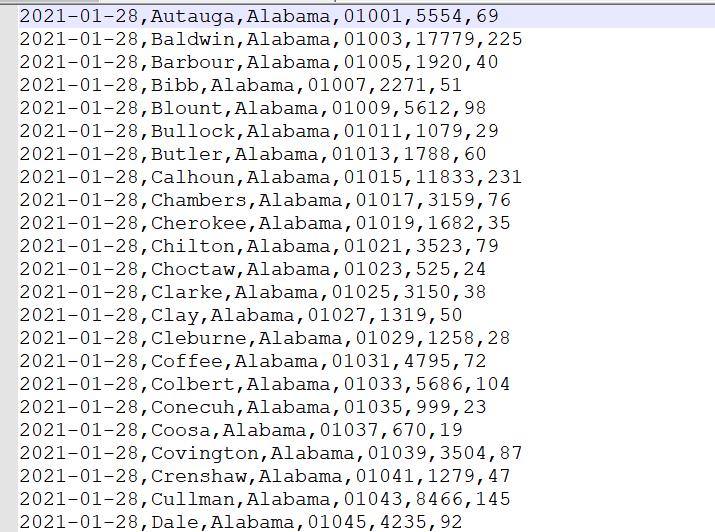
例如将如下文本格式转化为 SequenceFile 格式:
public class SequenceFileDriver extends Configured implements Tool
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new SequenceFileDriver(), args);
System.exit(status);
@Override
public int run(String[] args) throws Exception
Job job = Job.getInstance(getConf(), SequenceFileDriver.class.getSimpleName());
job.setJarByClass(SequenceFileDriver.class);
job.setMapperClass(FileMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
FileInputFormat.addInputPath(job, new Path("D:/test/input"));
Path output = new Path("D:/test/output");
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(output))
fs.delete(output, true);
FileOutputFormat.setOutputPath(job, output);
return job.waitForCompletion(true) ? 0 : 1;
class FileMapper extends Mapper<LongWritable, Text, LongWritable, Text>
NullWritable outValue = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
context.write(key, value);
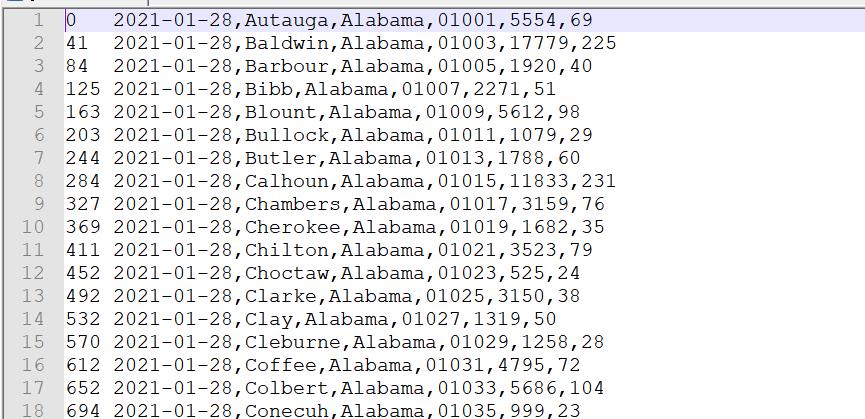
转化后,查看文件应该会乱码,因为已经是二进制压缩格式,

读取 SequenceFile 格式文件到文本
public class SequenceFileDriver extends Configured implements Tool
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new SequenceFileDriver(), args);
System.exit(status);
@Override
public int run(String[] args) throws Exception
Job job = Job.getInstance(getConf(), SequenceFileDriver.class.getSimpleName());
job.setJarByClass(SequenceFileDriver.class);
job.setMapperClass(FileMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(SequenceFileInputFormat.class);
// job.setOutputFormatClass(SequenceFileOutputFormat.class);
// SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
FileInputFormat.addInputPath(job, new Path("D:/test/output"));
Path output = new Path("D:/test/output1");
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(output))
fs.delete(output, true);
FileOutputFormat.setOutputPath(job, output);
return job.waitForCompletion(true) ? 0 : 1;
class FileMapper extends Mapper<LongWritable, Text, LongWritable, Text>
NullWritable outValue = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
context.write(key, value);
二、MapFile
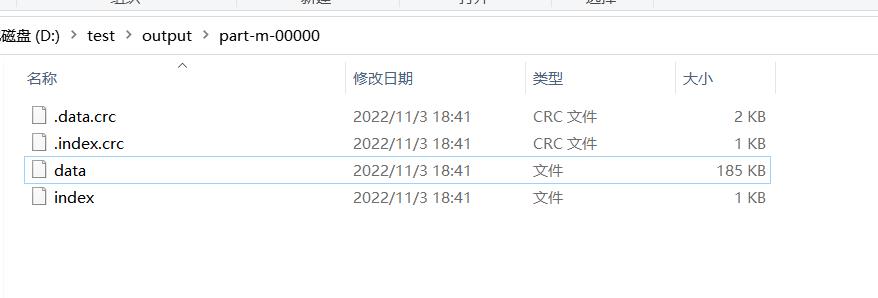
可以将 MapFile 理解是排序后的 SequenceFile,其结构由两部分组成分别是data和 index。data 存储数据的文件内容,index 存储文件的数据索引,记录了每个Record的Key值,以及该Record在文件中的偏移位置。当文件被访问的时候,索引文件会被加载到内存,通过索引映射关系可以迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是最高的,缺点是会消耗一部分内存来存储index数据。
public class MapFileDriver extends Configured implements Tool
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new MapFileDriver(), args);
System.exit(status);
@Override
public int run(String[] args) throws Exception
Job job = Job.getInstance(getConf(), MapFileDriver.class.getSimpleName());
job.setJarByClass(MapFileDriver.class);
job.setMapperClass(FileMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.setOutputFormatClass(MapFileOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("D:/test/input"));
Path output = new Path("D:/test/output");
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(output))
fs.delete(output, true);
FileOutputFormat.setOutputPath(job, output);
return job.waitForCompletion(true) ? 0 : 1;
class FileMapper extends Mapper<LongWritable, Text, LongWritable, Text>
NullWritable outValue = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
context.write(key, value);
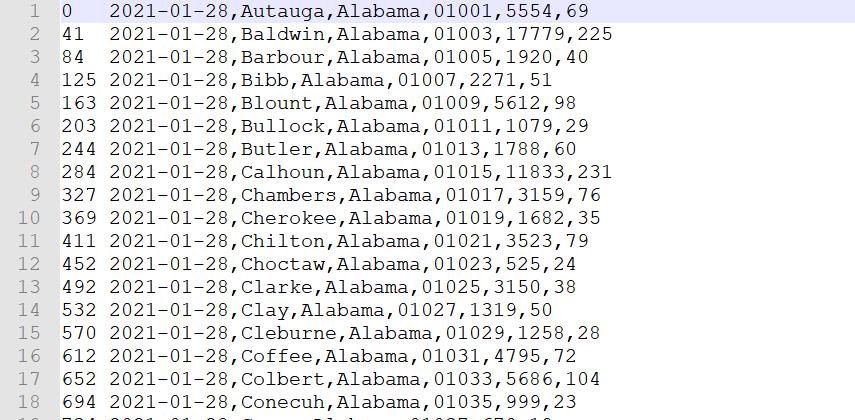
读取 MapFile
MapReduce 中没有封装 MapFile 的读取输入类,我们可以自定义InputFormat,使用MapFileOutputFormat中的getReader方法获取读取对象,或者直接使用SequenceFileInputFormat对MapFile的数据进行解析
public class MapFileDriver extends Configured implements Tool
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new MapFileDriver(), args);
System.exit(status);
@Override
public int run(String[] args) throws Exception
Job job = Job.getInstance(getConf(), MapFileDriver.class.getSimpleName());
job.setJarByClass(MapFileDriver.class);
job.setMapperClass(FileMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(SequenceFileInputFormat.class);
// job.setOutputFormatClass(MapFileOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("D:/test/output"));
Path output = new Path("D:/test/output1");
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(output))
fs.delete(output, true);
FileOutputFormat.setOutputPath(job, output);
return job.waitForCompletion(true) ? 0 : 1;
class FileMapper extends Mapper<LongWritable, Text, LongWritable, Text>
NullWritable outValue = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
context.write(key, value);
以上是关于Hadoop3 - MapReduce SequenceFile MapFile 格式存储的主要内容,如果未能解决你的问题,请参考以下文章