图学习?Transformer:我也行
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图学习?Transformer:我也行相关的知识,希望对你有一定的参考价值。
微信公众号“圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~
Transformer诞生于NLP领域,目前已经成为NLP中的主力模型。同时,Transformer在CV领域也逐渐显示出其超强的能力,诸如ViT、Swin Transformer、BEiT等Vision Transformer模型验证了Transformer同样适用于图像领域。然而,Transformer在图表示学习领域的发展速度明显不如NLP和CV领域。在图表示学习中,基于图卷积(GCN)的方法仍然是主力模型。
为什么Transformer难以应用到图学习场景中呢?其中一个很重要的原因在于,Transformer中的position encoding在图中很难表达。在NLP或者CV中,数据都是一维和二维的顺序结构,因此可以很自然的使用position encoding刻画元素的相对位置。然而在图中,不存在空间上的顺序,如何才能设计出图中合理的position encoding,是Transformer在图学习领域应用的一个难点。这篇文章给大家介绍一下Transformer模型在图学习领域的应用,梳理Transformer在图学习上的发展历程,看看Transformer是如何逐渐杀入图学习领域的。
1. Graph Attention Networks
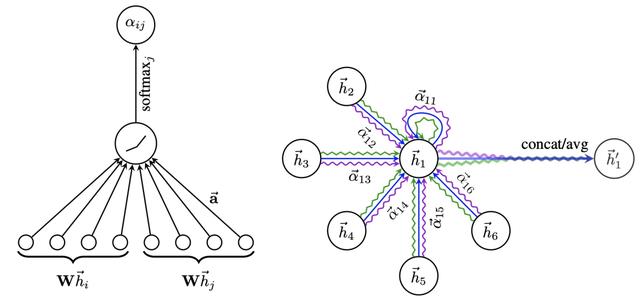
最开始使用Transformer中Attention思想进行图表示学习的工作是在GRAPH ATTENTION NETWORKS(ICLR 2018)中提出的GAT,提出使用多头注意力机制学习图中节点之间的关系,来进行信息融合。和图卷积神经网络GCN相比,GAT相当于使用attention score来代替拉普拉斯矩阵计算的融合方法。
GAT的核心思路比较直观,计算节点之间的attention score,利用attention score作为节点表示融合的权重。具体实现为,计算每个节点和其邻居节点的attention score,再用attention score融合邻居节点的表示得到该节点新的表示,计算过程中使用了multi-head的思路,公式表示如下:
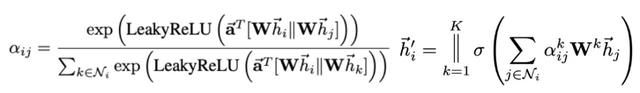
2. Graph Transformer Networks
Graph Transformer Networks(NIPS 2019)提出使用Transformer实现异构图上的图表示学习。普通的GCN只能用于同构图,解决异构图的编码一般采用人工设计meta-path提取子图,再使用GCN在子图上编码实现。这种两阶段的方法的效果依赖人工设计的meta-path,并且需要针对特定问题进行meta-path的设计。本文提出使用Transformer自动生成meta-path。首先,一个异构图可以根据边类型拆分成多个同构图,每个同构图有一个对应的邻接矩阵表示。而每个metapath组成的图的邻接矩阵,根据其序列的边类型,可以表示成多种类型边的邻接矩阵的乘积,如下(Ap代表某个metapath生成的子图邻接矩阵,At表示某个类型边同构图对应的子图邻接矩阵):
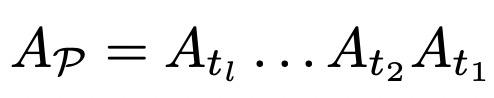
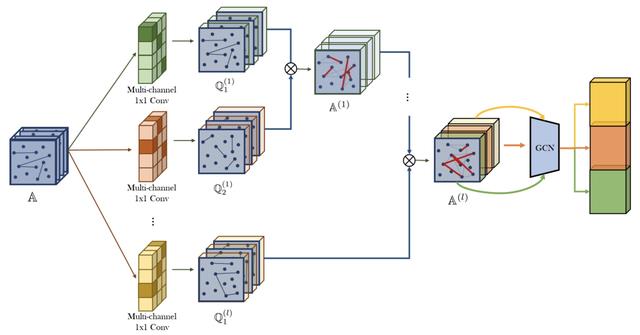
为了实现meta-path的自动生成,利用一维卷积+softmax生成每个邻接矩阵的权重,利用权重选择两个同构图邻接矩阵,这两个邻接矩阵做乘法即可得到一个2阶的meta-path。通过多层的叠加,理论上可以生成任意长度的meta-path。然而N层的叠加会得到N阶的meta-path而忽略了低阶的meta-path。因此文中在候选临街矩阵中增加了单位矩阵,以此实现灵活的meta-path长度空值。最后利用GCN提取各个基于meta-path生成子图上的图表示。
Self-Supervised Graph Transformer on Large-Scale Molecular Data(NIPS 2020)利用Transfomer进行分子结构的图无监督预训练。这篇文章的基础结构为,首先利用图神经网生成每个节点的初始表示,这一步骤借助了GNN的图节点表示学习能力提取每个节点的初步图信息。然后将每个节点经过GNN得到的表示作为Transformer中的Q、K、V,将所有节点看成全联通的图进行attention(例如GAT中的方法),以此来实现分子结构图整体的进一步信息提取。为了能够在分子结构图上进行无监督预训练,文中提出了针对分子图的contextual property prediction和graph-level motif prediction两种无监督预训练任务。
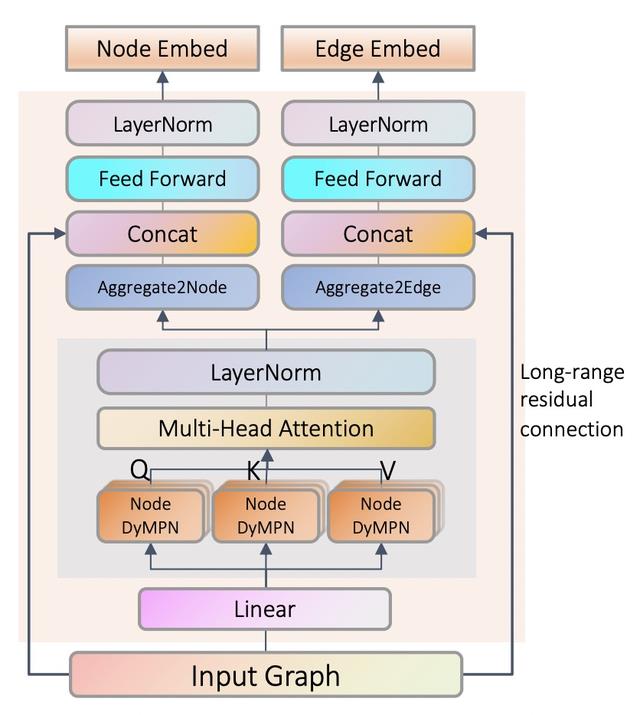
3. Graphformer
Do Transformers Really Perform Bad for Graph Representation?(NIPS 2021)是微软亚研院的一篇工作,提出了Graphformer,用于graph embedding的学习。文中讨论的一个核心问题为,如何将图的结构信息编码到Transformer中,类似NLP中的position embedding。为了将图结构信息融入到模型中,文中提出了Centrality Encoding、Edge Encoding、Spatial Encoding三种和图结构信息相关的编码,引入到Transformer中,弥补注意力机制无法编码的图结构信息。下面分别介绍这三种类型的Encoding。
Centrality Encoding用于描述图中每个节点的重要性。不同节点在图中的重要性不同,而普通的注意力机制无法考虑到这种信息。因此,文中会给每个节点的出入度学习一个embedding,类似于position embedding,只不过把position位置换成节点的出入度,将这个embedding加到节点的特征上,作为Transformer的输入,有效将节点自身的重要性特点引入到了模型中。
Spatial Encoding用于描述两个节点的距离。对于每一对节点,文中使用这两个节点在图上的最短距离作为这两个节点之间的Spatial Encoding。Edge Encoding用于描述两个节点之间边类型的信息。Edge Encoding将两个节点最短路径的边表示信息进行融合,作为一部分参考信息。Spatial Encoding和Edge Encoding都用于对attention score进行校准,让模型在计算节点之间的attention score时将节点之间的距离、边类型考虑在内。因此最终的attention score计算方式如下,包括正常的mullti-head attention部分、spatial encoding部分以及edge encoding部分:
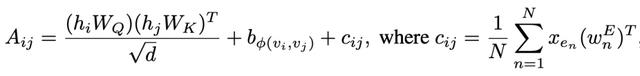
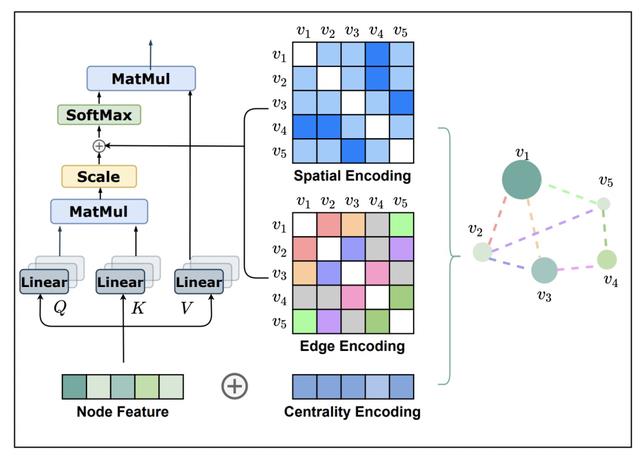
Graphormer的模型结构如下,左侧为正常的Transformer,右侧是为了将图结构信息引入Transformer而增加的三个Encoding部分。
4. 总结
本文给大家介绍了Transformer在图学习中典型的4篇工作,从GAN,到Graph Transformer,再到去年NIPS上的Graphformer。Transformer在图领域的应用逐渐成熟,也有更多的工作研究如何适配Transformer和图数据结构。从GAN中直接在图中使用注意力机制,逐渐到Graphformer中设计适合图结构的Transformer。
微信公众号“圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~
【历史干货算法笔记】
最新NLP Prompt代表工作梳理!ACL 2022 Prompt方向论文解析
一网打尽:14种预训练语言模型大汇总
Vision-Language多模态建模方法脉络梳理
Spatial-Temporal时间序列预测建模方法汇总
12篇顶会论文,深度学习时间序列预测经典方案汇总
花式Finetune方法大汇总
NLP中的绿色Finetune方法
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
缺少训练样本怎么做实体识别?小样本下的NER解决方法汇总
以上是关于图学习?Transformer:我也行的主要内容,如果未能解决你的问题,请参考以下文章