lucene一---基本原理和结构
Posted forrestxingyunfei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene一---基本原理和结构相关的知识,希望对你有一定的参考价值。
数据的分类
结构化数据:有固定类型或者有固定长度的数据
例如:数据库中的数据(mysql,oracle等), 元数据(就是windows中的数据)
结构化数据搜索方法:
数据库中数据通过sql语句可以搜索
元数据(windows中的)通过windows提供的搜索栏进行搜索
非结构化数据:没有固定类型和固定长度的数据
例如: world文档中的数据, 邮件中的数据
非结构化数据搜索方法:
Word文档使用ctrl+F来搜索
顺序扫描法:
Ctrl+F中是使用的顺序扫描法,拿到搜索的关键字,去文档中,逐字匹配,直到找到和关键字一致的内容为止.
优点: 如果文档中存在要找的关键字就一定能找到想要的内容
缺点: 慢, 效率低
全文检索算法(倒排索引算法):
将文件中的内容提取出来, 将文字拆封成一个一个的词(分词), 将这些词组成索引(字典中的目录), 搜索的时候先搜索索引,通过索引找文档,这个过程就叫做全文检索.
分词: 去掉停用词(a, an, the ,的, 地, 得, 啊, 嗯 ,呵呵),因为搜索的时候搜索这些词没有意义,将句子拆分成词,去掉标点符号和空格
优点: 搜索速度快
缺点: 因为创建的索引需要占用磁盘空间,所以这个算法会使用掉更多的磁盘空间,这是用空间换时间
原理:
相当于字典,分为目录和正文两部分,查询的时候通过先查目录,然后通过目录上标注的页数去正文页查找需要的内容
Lucene
什么是lucene
Lucene是apache旗下的顶级项目,是一个全文检索工具包
Lucene就是一个可以创建全文检索引擎系统的一堆jar包.可以使用它来构建全文检索引擎系统,但是它不能独立运
全文检索引擎系统
放在tomcat下可以独立运行,对外提供全文检索服务.
Lucene应用领域
1. 互联网全文检索引擎(比如百度, 谷歌, 必应)
2. 站内全文检索引擎(淘宝, 京东搜索功能)
3. 优化数据库查询(因为数据库中使用like关键字是全表扫描也就是顺序扫描算法,查询慢)
Lucene下载
官方网站:http://lucene.apache.org/
版本:lucene4.10.3
Jdk要求:1.7以上
IDE:Eclipse
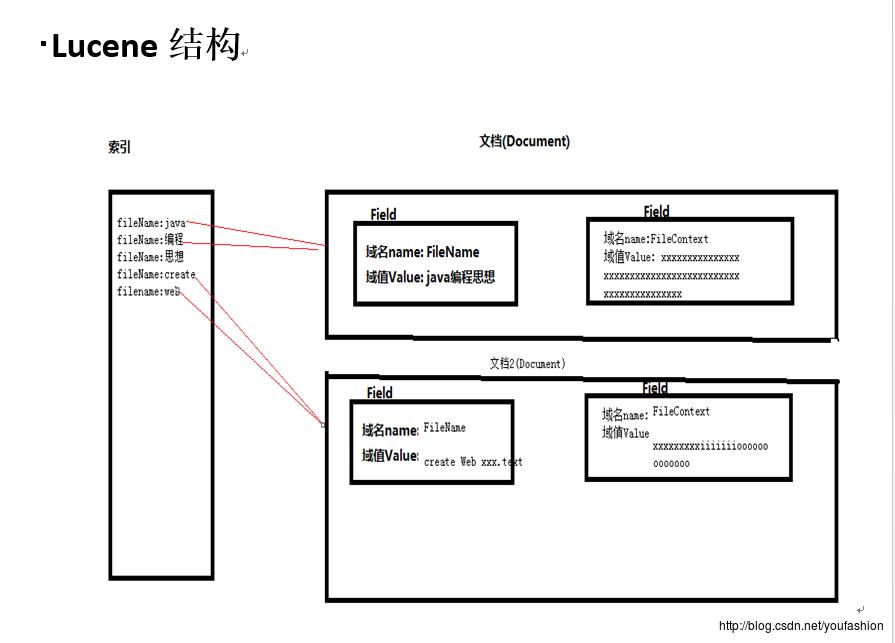
索引:
域名:词 这样的形式,
它里面有指针执行这个词来源的文档
索引库: 放索引的文件夹(这个文件夹可以自己随意创建,在里面放索引就是索引库)
Term词元: 就是一个词, 是lucene中词的最小单位
文档:
Document对象,一个Document中可以有多个Field域对象,Field域对象中是key value键值对的形式:有域名和域值,
一个document就是数据库表中的一条记录, 一个Filed域对象就是数据库表中的一行一列
这是一个通用的存储结构.
创建索引和所有时所用的分词器必须一致
域的详细介绍
是否分词:
分词的作用是为了索引
需要分词: 文件名称, 文件内容
不需要分词: 不需要索引的域不需要分词,还有就是分词后无意义的域不需要分词
比如: id, 身份证号
是否索引:
索引的的目的是为了搜索.
需要搜索的域就一定要创建索引,只有创建了索引才能被搜索出来
不需要搜索的域可以不创建索引
需要索引: 文件名称, 文件内容, id, 身份证号等
不需要索引: 比如图片地址不需要创建索引,e:\\\\xxx.jpg
因为根据图片地址搜索无意义
是否存储:
存储的目的是为了显示.
是否存储看个人需要,存储就是将内容放入Document文档对象中保存出来,会额外占用磁盘空间, 如果搜索的时候需要马上显示出来可以放入document中也就是要存储,这样查询显示速度快, 如果不是马上立刻需要显示出来,则不需要存储,因为额外占用磁盘空间不划算.
域的各种类型
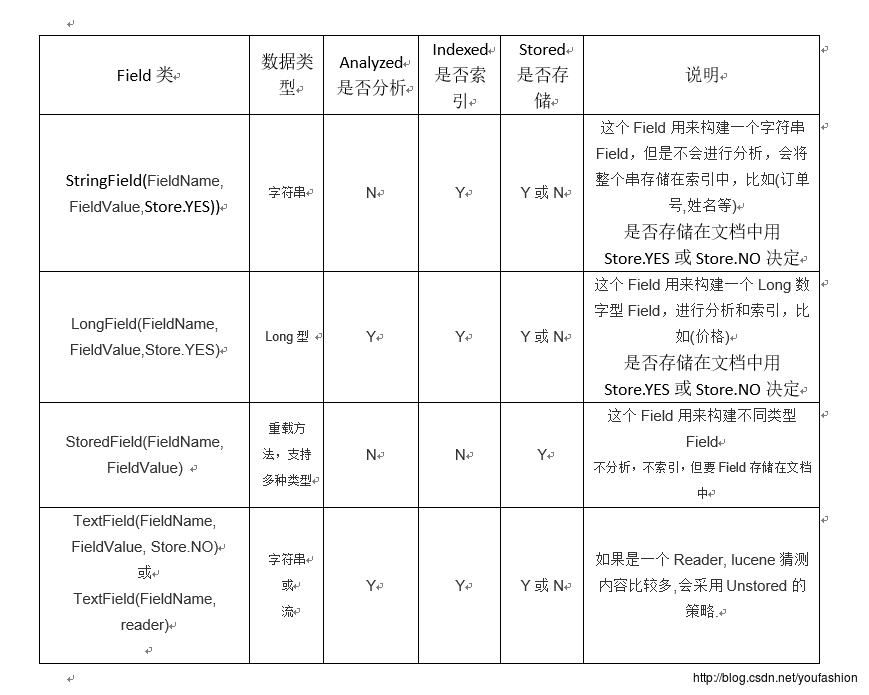
注意:lucene底层的算法,钱数是要分词的,因为要根据价钱进行对比
例如: 大于12.5元的小于100元的商品搜索出来

以上是关于lucene一---基本原理和结构的主要内容,如果未能解决你的问题,请参考以下文章