安装Hadoop,启动hadoop(每次都用),设置免密码登陆
Posted sherri_du
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安装Hadoop,启动hadoop(每次都用),设置免密码登陆相关的知识,希望对你有一定的参考价值。
安装hadoop2.2.01、上传一个Hadoop包
mkdir /itcast根目录下创建一个文件,以后Hadoop统一放入其中
tar -zxvf hadoop-2.2.0-64bit.tar.gz -C /itcast/ (解压到指定目录)
3、配置hadoop伪分布式
cd /itcast/用ls查看是否有hadoop-2.2.0,然后查看其中的目录结构
cd hadoop-2.2.0/ 用ls查看:
*bin中存放可执行脚本,sbin存放启动停止相关的,etc存放配置文件
cd /itcast/hadoop-2.2.0/etc/hadoop/
指定pwd复制目录 /itcast/hadoop-2.2.0/etc/hadoop
修改配置文件(5个)
第一个、vim hadoop-env.sh
#第27行
export JAVA_HOME=/usr/java/jdk1.7.0_79
第二个: vim core-site.xml
文件中插入一行
<configuration>
<!--用来指定HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name> (filesystem默认地址)
<value>hdfs://itcast01:9000</value> (hdfs://主机名+端口 )
(如果没有配置主机名可以写localhost 127.0.0.1或者192.168.8.88)
</property>
<!-- 用来指定Hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/itcast/hadoop-2.2.0/tmp</value>
</property>
</configuration>
第三个:hdfs-site.xml
<configuration>
<!-- 指定HDFS保存数据副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四个、vim mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
(重命名,原来之前只有mapred-site.xml.template,没有配置文件mapred-site.xml)
<configuration>
<!-- 告诉Hadoop以后mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
第五个、yarn-site.xml
<configuration>
<!-- nodemanager获取数据的方式是shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的老大(reducemanager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>itcast01</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
4、 将hadoop添加到环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
export HADOOP_HOME=/itcast/hadoop-2.2.0
source /etc/profile #刷新配置
5、 初始化文件系统HDFS(格式化文件系统)
#hadoop namenode -format(这个命令已经过时了,但是依然可用)
which hadoop #找到这个命令在什么地方 /itcast/hadoop-2.2.0/bin/hadoop
which hdfs #现在Hadoop归在hdfs下,找到他在什么地方 /itcast/hadoop-2.2.0/bin/hdfs
(可以用 cd /itcast/hadoop-2.2.0/bin/hdfs 加 ls 打开查看一下)
hdfs namenode -format # 开始格式化在cd /itcast/hadoop-2.2.0目录下(不记得用哪个进行格式化可以输入hdfs回车看)#
一定要看到:Storage directory /itcast/hadoop-2.2.0/tmp/dfs/name has been successfully formatted.
可以在/itcast/hadoop-2.2.0下查看是否有tmp目录了
6、启动Hadoop(cd /itcast/hadoop-2.2.0/sbin)(以后每次打开都需要用)
./start-all.sh #(过时了 This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh )
#有个小问题,需要多次输入密码
还可以通过浏览器的方式验证 (只有Hadoop启动时才可以打开)
http://192.168.8.88:50070 (hdfs管理界面)显示active活跃状态
http://192.168.8.88:8088 (yarn管理界面)
http://192.168.8.88:50070 (hdfs管理界面)
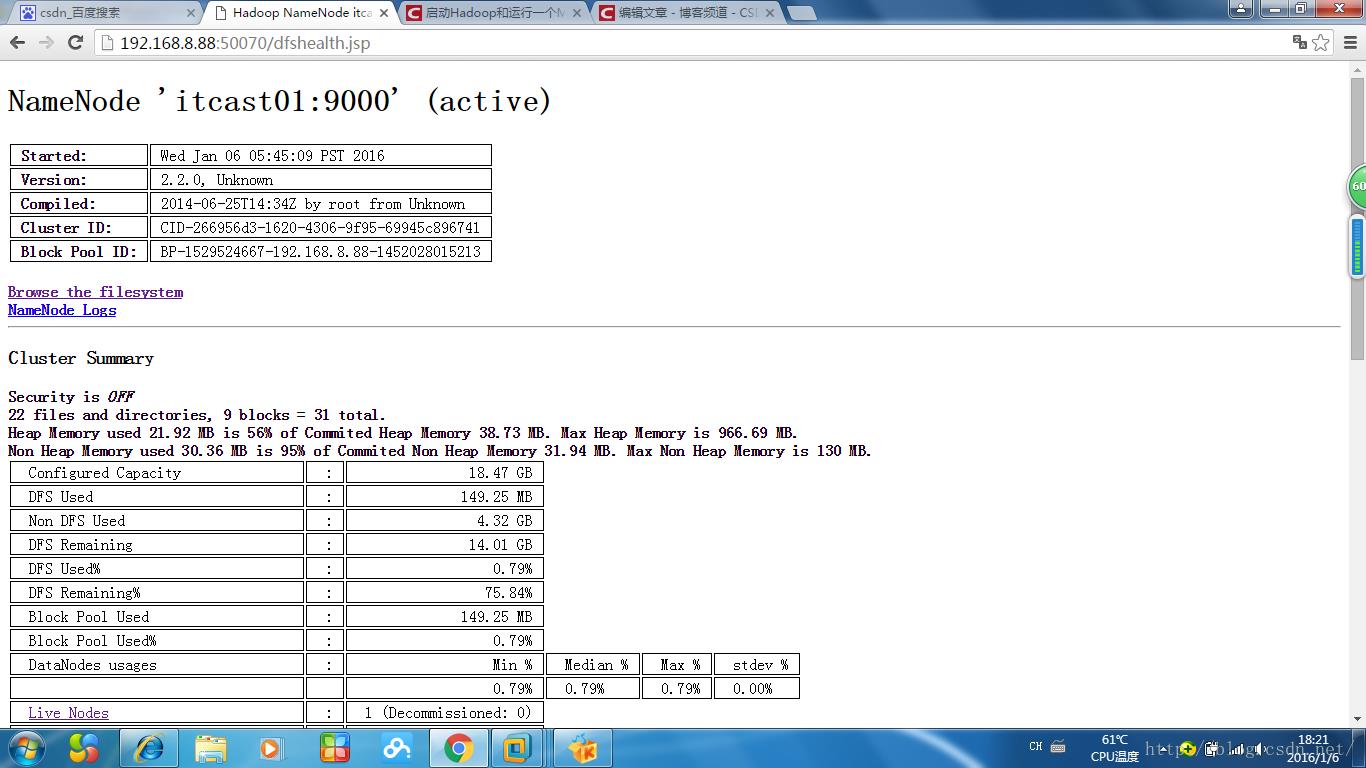
这里的Live Node指的是 Datenode
点击Browse the filesystem ,出错了,所以
在这个文件中添加linux主机名和IP的映射关系
C:\\Windows\\System32\\drivers\\etc中的hosts,保存刷新网页出现下面情况
http://192.168.8.88:8088 (yarn管理界面)
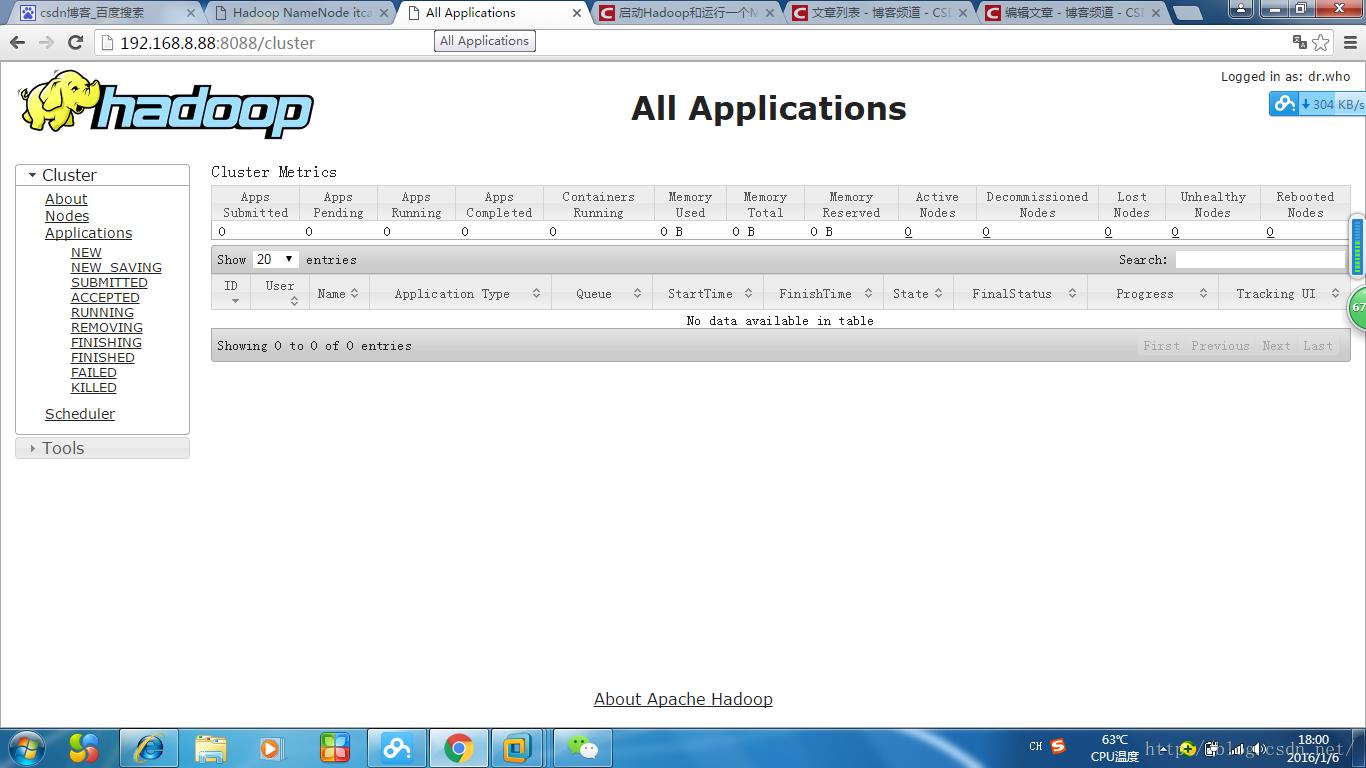
hdfs的老大是namenode,小弟是datanode,secondarynode是namenoded 的助理,帮助进行一些文件的合并
yarn的老大是resourcemanager,小弟是nodemanager(可以有多个)
7、 测试HDFS
#上传文件到HDFS
hadoop fs -put /home/djl/jdk-7u79-linux-i586.tar.gz hdfs://itcast01:9000/jdk(使用Hadoop将本地文件上传到Hdfs)
#从HDFS下载文件到本地
还可以下载点击文件,点击Download this file
还可以通过命令行下载hadoop fs -get hdfs://itcast01:9000/jdk /home/jdk1.7 并且重新命名为jdk1.7
tar -zxvf jdk1.7 解压成功,说明下载成功
8、验证集群是否启动成功
输入jps查看配置是否成功(配置部分最好直接复制粘贴,不容易出错)
3081 DataNode
3710 Jps
3340 ResourceManager
3610 NodeManager
2977 NameNode
3212 SecondaryNameNode
which jps查看位置/usr/java/jdk1.6.0_45/bin/jps
9、测试MR和YARN
cd /itcast/hadoop-2.2.0/share/hadoop/mapreduce
vim words #打开写入字符
hello tomQ
hello jerry
hello kitty
hello world
hello tom
wc words #统计单词 eg:5 10 56 words指 5行10个单词56个字符
more words #统计单词(统计相同单词一共出现的次数)
hadoop fs -put words hdfs://itcast01:9000/words #把words上传到HDFS
hadoop fs -ls hdfs://itcast01:9000/ #查看words文件是否上传成功,还可以通过浏览器查看
hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcount hdfs://itcast01:9000/words hdfs://itcast01:9000/wcout
#wordcount 后面两个分别跟的是前后两个地址,一个是我们要count的文件要查的地址,后面那个是我们保存的地方的地址
hadoop -ls / #查看计算完的文件或用浏览器
#当运行出错时,可以这样查看
cd /itcast/hadoop-2.2.0/ 中有一个log是用来存储Hadoop运行的日志,打开
more hadoop-root-namenode-itcast01.log如果出现问题里面应该有erro
8、配置ssh免密码登陆(secure shell)
ssh itcast01(不管进自己还是别的都需要输密码)exit 退出
启动Hadoop需要输密码就是因为用的是ssh
新建一台虚拟机,设置IP为192.168.8.99
两个虚拟机和本地直接都相互ping通
一台机器给另一台机器发送命令,需要输入密码,即使是给自己发送
ssh 192.168.8.99 mkdir /itcast0106
#在192.168.8.88上通过ssh向192.168.8.99发送指令新建一个文件夹,需要输入192.168.8.99的密码
cd /root/进入root目录
cd .ssh/
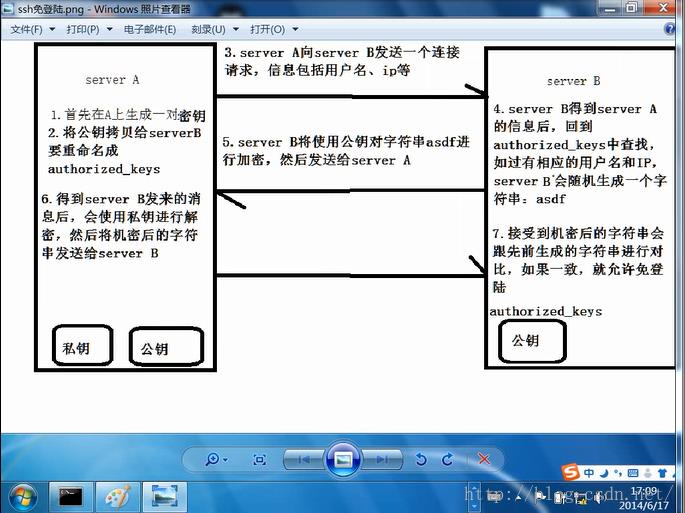
#生成ssh免登陆密钥
ssh-keygen -t rsa
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)-----密码是非对称的
可以用more id_rsa.pub 和 more id_rsa 查看
设置自己到自己免登陆密码,将公钥拷贝到要免登陆的机器上
cp id_rsa.pub authorized_keys
此时就设置好了免密码登陆,以后ssh itcast01 和启动Hadoop 都不用再输入密码
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
或
ssh-copy-id -i localhost(这两个语句可以实现同样功能)
ssh 192.168.8.99 从8.88进入到8.99,但是需要输入密码。 按exit退出
本地想登陆到8.99,需要将8.88的公钥拷贝给8.99 (cd /root/.ssh/)
ssh-copy-id 192.168.8.99
此时8.99中出现了authorized——keys是8.88的公钥(这种免密码是单向的)
以上是关于安装Hadoop,启动hadoop(每次都用),设置免密码登陆的主要内容,如果未能解决你的问题,请参考以下文章