「深度学习一遍过」必修24:基于UNet的Semantic Segmentation
Posted 闭关修炼——暂退
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「深度学习一遍过」必修24:基于UNet的Semantic Segmentation相关的知识,希望对你有一定的参考价值。
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
项目 GitHub 地址
 https://github.com/zhao302014/Classic_model_examples/tree/main/2015_UNet_SemanticSegmentation/MyUNet_SemanticSegmentation
https://github.com/zhao302014/Classic_model_examples/tree/main/2015_UNet_SemanticSegmentation/MyUNet_SemanticSegmentation项目心得
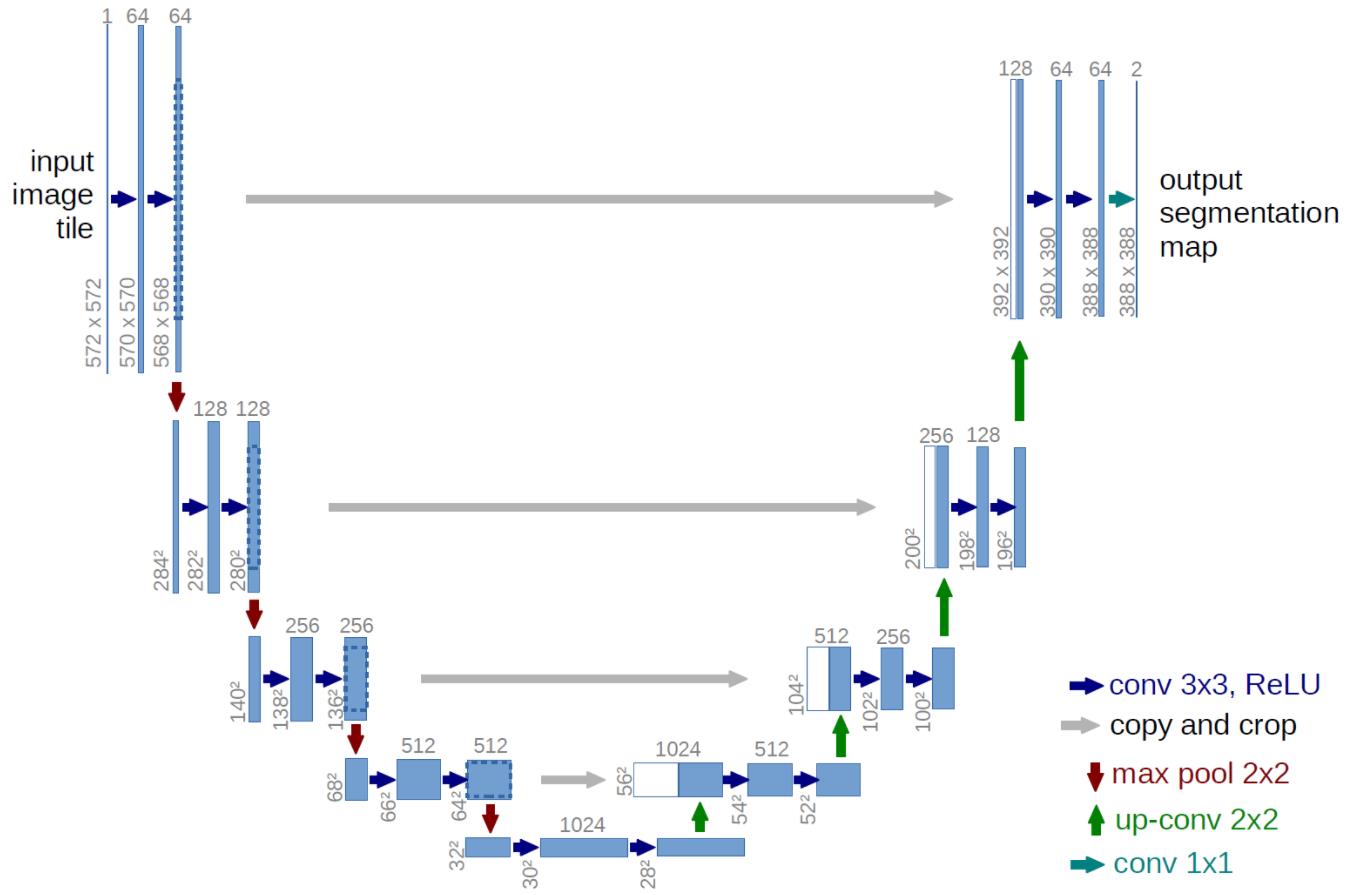
- 2015 年——U-Net:像这 U-net 论文中画出的结构,有两个最大的特点:U 型结构(全局观)和 skip-connection(灰线)。该项目实现的代码 net.py 中没有根据输入图大小重新设计卷积值等大小,而是完全拟合了下图中从论文中截取的 U-Net 架构:输入
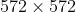 ,输出
,输出  ,很容易发现输入图片大小和输出图片大小不一致,而我们熟知的 FCN 思路主要是下采样提取特征然后上采样到输入图大小进行最终训练、预测;论文中设置的输入图大小与输出特征图大小不一致,这样做是因为受限于当年的硬件条件,不能将原图
,很容易发现输入图片大小和输出图片大小不一致,而我们熟知的 FCN 思路主要是下采样提取特征然后上采样到输入图大小进行最终训练、预测;论文中设置的输入图大小与输出特征图大小不一致,这样做是因为受限于当年的硬件条件,不能将原图 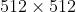 输入,而 resize 会损失图像的分辨率,所以采用的是将 的图片进行镜像 padding,得到
输入,而 resize 会损失图像的分辨率,所以采用的是将 的图片进行镜像 padding,得到 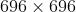 ,切割出
,切割出 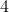 张 的图片(左上,右上,左下,右下),输出 的图片,最后拼接在一起(重复的部分会取平均)。在该项目中我将输入图大小设置为 ,标签图大小等比例缩放到 ,测试图设置为 。这样就会避免在训练过程中因为训练图经过模型后的特征图大小与标签图大小不匹配而引起的报错。最后提一点就是 skip-connection 时是使用 concat 进行操作的。
张 的图片(左上,右上,左下,右下),输出 的图片,最后拼接在一起(重复的部分会取平均)。在该项目中我将输入图大小设置为 ,标签图大小等比例缩放到 ,测试图设置为 。这样就会避免在训练过程中因为训练图经过模型后的特征图大小与标签图大小不匹配而引起的报错。最后提一点就是 skip-connection 时是使用 concat 进行操作的。
项目代码
net.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月11日(农历八月初五)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
import torch.nn as nn
# --------------------------------------------------------------------------------- #
# 自己搭建一个 U-Net 模型结构
# · 提出时间:2015 年
# · U-Net 主要是针对生物医学图片的分割;在今后的许多对医学图像的分割网络中,很大一部分会采取 U-Net 作为网络的主干
# · 整体结构就是先编码(下采样),再解码(上采样),回归到跟原始图像一样大小的像素点的分类
# · U-Net 基于 FCN,对 FCN 的基本结构进行了更精细的设计,更为高效,是可以替代 FCN 的方案
# · 模型结构图中灰色线用 cancat 操作,下采样用 Conv2d 操作,上采样用 ConvTranspose2d 操作
# --------------------------------------------------------------------------------- #
# 定义一个裁剪特征图大小的函数
def Crop_FeatureMap(FeatureMap1, FeatureMap2):
FeatureMap1_size = FeatureMap1.shape[2] # 获取特征图一大小:(FeatureMap1_size, FeatureMap1_size)
FeatureMap2_size = FeatureMap2.shape[2] # 获取特征图二大小:(FeatureMap2_size, FeatureMap2_size)
crop = (FeatureMap1_size - FeatureMap2_size) // 2 # 将特征图一大小变为特征图二大小上下、左右各需裁剪,故整除 2
FeatureMap1 = FeatureMap1[:, :, crop:FeatureMap1_size-crop, crop:FeatureMap1_size-crop] # 改写特征图一shape:[banch_size, channel_num, FeatureMap_size, FeatureMap_size]
return FeatureMap1
class MyUNet(nn.Module):
def __init__(self):
super(MyUNet, self).__init__()
# ReLU 激活函数用在每一个卷积操作之后
self.ReLU = nn.ReLU()
# Max Pooling 用在下采样中,使特征图 size 减半
self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
# ------------ #
# 下采样
# ------------ #
# 下采样第一部分卷积(从上向下看)
self.down_c1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3)
self.down_c1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3)
# 下采样第二部分卷积(从上向下看)
self.down_c2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3)
self.down_c2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3)
# 下采样第三部分卷积(从上向下看)
self.down_c3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3)
self.down_c3_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3)
# 下采样第四部分卷积(从上向下看)
self.down_c4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3)
self.down_c4_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3)
# 下采样第五部分卷积(从上向下看)
self.down_c5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3)
self.down_c5_2 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3)
# ------------ #
# 上采样
# ------------ #
# 上采样第四部分卷积(从下向上看)
self.up_conv5_4 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2)
self.up_c4_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3)
self.up_c4_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3)
# 上采样第三部分卷积(从下向上看)
self.up_conv4_3 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2)
self.up_c3_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3)
self.up_c3_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3)
# 上采样第二部分卷积(从下向上看)
self.up_conv3_2 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2)
self.up_c2_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3)
self.up_c2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3)
# 上采样第一部分卷积(从下向上看)
self.up_conv2_1 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2)
self.up_c1_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3)
self.up_c1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3)
# 上采样输出部分卷积(64 --> 2)
self.up_conv1_1 = nn.ConvTranspose2d(in_channels=64, out_channels=2, kernel_size=1)
# 为满足实例另加 ↓
self.up_conv1_0 = nn.ConvTranspose2d(in_channels=2, out_channels=1, kernel_size=1)
def forward(self, x): # 输入shape:torch.Size([1, 1, 572, 572])
down_x1_1 = self.ReLU(self.down_c1_1(x)) # shape:torch.Size([1, 64, 570, 570])
down_x1_2 = self.ReLU(self.down_c1_2(down_x1_1)) # shape:torch.Size([1, 64, 568, 568])
down_x = self.max_pool(down_x1_2) # shape:torch.Size([1, 64, 284, 284])
down_x2_1 = self.ReLU(self.down_c2_1(down_x)) # shape:torch.Size([1, 128, 282, 282])
down_x2_2 = self.ReLU(self.down_c2_2(down_x2_1)) # shape:torch.Size([1, 128, 280, 280])
down_x = self.max_pool(down_x2_2) # shape:torch.Size([1, 128, 140, 140])
down_x3_1 = self.ReLU(self.down_c3_1(down_x)) # shape:torch.Size([1, 256, 138, 138])
down_x3_2 = self.ReLU(self.down_c3_2(down_x3_1)) # shape:torch.Size([1, 256, 136, 136])
down_x = self.max_pool(down_x3_2) # shape:torch.Size([1, 256, 68, 68])
down_x4_1 = self.ReLU(self.down_c4_1(down_x)) # shape:torch.Size([1, 512, 66, 66])
down_x4_2 = self.ReLU(self.down_c4_2(down_x4_1)) # shape:torch.Size([1, 512, 64, 64])
down_x = self.max_pool(down_x4_2) # shape:torch.Size([1, 512, 32, 32])
down_x5_1 = self.ReLU(self.down_c5_1(down_x)) # shape:torch.Size([1, 1024, 30, 30])
down_x5_2 = self.ReLU(self.down_c5_2(down_x5_1)) # shape:torch.Size([1, 1024, 28, 28])
up_conv5_4 = self.ReLU(self.up_conv5_4(down_x5_2)) # shape:torch.Size([1, 512, 56, 56])
down_x4_2 = Crop_FeatureMap(down_x4_2, up_conv5_4) # shape: torch.Size([1, 512, 56, 56])
up_concat5_4 = torch.cat([down_x4_2, up_conv5_4], dim=1) # shape:torch.Size([1, 1024, 56, 56])
up_x4_1 = self.up_c4_1(up_concat5_4) # shape:torch.Size([1, 512, 54, 54])
up_x4_2 = self.up_c4_2(up_x4_1) # shape:torch.Size([1, 512, 52, 52])
up_conv4_3 = self.ReLU(self.up_conv4_3(up_x4_2)) # shape:torch.Size([1, 256, 104, 104])
down_x3_2 = Crop_FeatureMap(down_x3_2, up_conv4_3) # shape: torch.Size([1, 256, 104, 104])
up_concat4_3 = torch.cat([down_x3_2, up_conv4_3], dim=1) # shape:torch.Size([1, 512, 104, 104])
up_x3_1 = self.up_c3_1(up_concat4_3) # shape:torch.Size([1, 256, 102, 102])
up_x3_2 = self.up_c3_2(up_x3_1) # shape:torch.Size([1, 256, 100, 100])
up_conv3_2 = self.ReLU(self.up_conv3_2(up_x3_2)) # shape:torch.Size([1, 128, 200, 200])
down_x2_2 = Crop_FeatureMap(down_x2_2, up_conv3_2) # shape: torch.Size([1, 128, 200, 200])
up_concat3_2 = torch.cat([down_x2_2, up_conv3_2], dim=1) # shape:torch.Size([1, 256, 200, 200])
up_x2_1 = self.up_c2_1(up_concat3_2) # shape:torch.Size([1, 128, 198, 198])
up_x2_2 = self.up_c2_2(up_x2_1) # shape:torch.Size([1, 128, 196, 196])
up_conv2_1 = self.ReLU(self.up_conv2_1(up_x2_2)) # shape:torch.Size([1, 64, 392, 392])
down_x1_2 = Crop_FeatureMap(down_x1_2, up_conv2_1) # shape: torch.Size([1, 64, 392, 392])
up_concat2_1 = torch.cat([down_x1_2, up_conv2_1], dim=1) # shape:torch.Size([1, 128, 392, 392])
up_x1_1 = self.up_c1_1(up_concat2_1) # shape:torch.Size([1, 64, 390, 390])
up_x1_2 = self.up_c1_2(up_x1_1) # shape:torch.Size([1, 64, 388, 388])
x = self.up_conv1_1(up_x1_2) # shape:torch.Size([1, 2, 388, 388])
# 为满足实例另加 ↓
x = self.up_conv1_0(x) # shape: torch.Size([1, 1, 388, 388])
return x
if __name__ == "__main__":
x = torch.rand((1, 1, 572, 572))
model = MyUNet()
y = model(x)train.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月11日(农历八月初五)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
import torch.nn as nn
from torch.optim import lr_scheduler
from net import MyUNet
from CreateDataset import DataLoader
# 加载训练数据集
train_data_path = "data/train/"
train_dataset = DataLoader(train_data_path)
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=1, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用 net 里定义的模型,如果 GPU 可用则将模型转到 GPU
model = MyUNet().to(device)
# 定义损失函数
loss_fn = nn.BCEWithLogitsLoss()
# 定义优化器
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.00001, weight_decay=1e-8, momentum=0.9)
# 学习率每隔 10 个 epoch 变为原来的 0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
loss, current, n = 0.0, 0.0, 0
for batch, (X, y) in enumerate(dataloader):
# 前向传播
x, y = X.to(device), y.to(device)
x = x.float() # 输入的类型是字节型的 tensor,而加载的权重的类型是 float 类型的 tensor,需要将字节型的 tensor 转化为 float 型的 tensor
y = y.float()
output = model(x)
cur_loss = loss_fn(output, y)
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
n = n + 1
print('train_loss:' + str(loss / n))
# 开始训练
epoch = 100
for t in range(epoch):
lr_scheduler.step()
print(f"Epoch t + 1\\n----------------------")
train(train_dataloader, model, loss_fn, optimizer)
torch.save(model.state_dict(), "save_model/model.pth".format(t)) # 模型保存
print("Done!")test.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月11日(农历八月初五)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
import glob
import cv2
import numpy as np
from net import MyUNet
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用 net 里定义的模型,如果 GPU 可用则将模型转到 GPU
model = MyUNet().to(device)
# 加载 train.py 里训练好的模型
model.load_state_dict(torch.load("./save_model/20model.pth"))
# 进入验证阶段
model.eval()
# 读取所有图片路径
tests_path = glob.glob('./data/test/*.png')
# 遍历素有图片
for test_path in tests_path:
# 读取图片
img = cv2.imread(test_path)
# 转为灰度图
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 转为 batch 为 1,通道为 1,大小为 img_shape*img_shape 的数组
img = img.reshape(1, 1, img.shape[0], img.shape[1])
# 转为tensor
img_tensor = torch.from_numpy(img)
# 将tensor拷贝到device中
img_tensor = img_tensor.to(device=device, dtype=torch.float32)
# 预测
pred = model(img_tensor)
# 提取结果
pred = np.array(pred.data.cpu()[0])[0]
print(pred)
# 处理结果
pred[pred >= 0.99] = 255
pred[pred < 0.99] = 0
# 结果显示
cv2.imshow('image', pred)
cv2.waitKey(0)欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于「深度学习一遍过」必修24:基于UNet的Semantic Segmentation的主要内容,如果未能解决你的问题,请参考以下文章