机器学习集成学习进阶Xgboost算法案例分析
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习集成学习进阶Xgboost算法案例分析相关的知识,希望对你有一定的参考价值。
目录
1 xgboost算法api介绍
1.1 xgboost的安装
官网链接:https://xgboost.readthedocs.io/en/latest/
pip3 install xgboost
2 xgboost参数介绍
xgboost虽然被称为kaggle比赛神奇,但是,我们要想训练出不错的模型,必须要给参数传递合适的值。
xgboost中封装了很多参数,主要由三种类型构成:通用参数(general parameters),Booster 参数(booster parameters)和学习目标参数(task parameters)
- 通用参数:主要是宏观函数控制;
- Booster参数:取决于选择的Booster类型,用于控制每一步的booster(tree, regressiong);
- 学习目标参数:控制训练目标的表现。
2.1 通用参数(general parameters)
- booster [缺省值=gbtree]
- 决定使用哪个booster,可以是gbtree,gblinear或者dart。
- gbtree和dart使用基于树的模型(dart 主要多了 Dropout),而gblinear 使用线性函数.
- silent [缺省值=0]
- 设置为0打印运行信息;设置为1静默模式,不打印
- nthread [缺省值=设置为最大可能的线程数]
- 并行运行xgboost的线程数,输入的参数应该<=系统的CPU核心数,若是没有设置算法会检测将其设置为CPU的全部核心数
下面的两个参数不需要设置,使用默认的就好了
- num_pbuffer [xgboost自动设置,不需要用户设置]
- 预测结果缓存大小,通常设置为训练实例的个数。该缓存用于保存最后boosting操作的预测结果。
- num_feature [xgboost自动设置,不需要用户设置]
- 在boosting中使用特征的维度,设置为特征的最大维度
2.2 Booster 参数(booster parameters)
2.2.1 Parameters for Tree Booster
- eta [缺省值=0.3,别名:learning_rate]
- 更新中减少的步长来防止过拟合。
- 在每次boosting之后,可以直接获得新的特征权值,这样可以使得boosting更加鲁棒。
- 范围: [0,1]
- gamma [缺省值=0,别名: min_split_loss](分裂最小loss)
- 在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。
- Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。
- 范围: [0,∞]
- max_depth [缺省值=6]
- 这个值为树的最大深度。 这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。设置为0代表没有限制
- 范围: [0,∞]
- min_child_weight [缺省值=1]
- 决定最小叶子节点样本权重和。XGBoost的这个参数是最小样本权重的和.
- 当它的值较大时,可以避免模型学习到局部的特殊样本。 但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。.
- 范围: [0,∞]
- subsample [缺省值=1]
- 这个参数控制对于每棵树,随机采样的比例。
- 减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。
- 典型值:0.5-1,0.5代表平均采样,防止过拟合.
- 范围: (0,1]
- colsample_bytree [缺省值=1]
- 用来控制每棵随机采样的列数的占比(每一列是一个特征)。
- 典型值:0.5-1
- 范围: (0,1]
- colsample_bylevel [缺省值=1]
- 用来控制树的每一级的每一次分裂,对列数的采样的占比。
- 我个人一般不太用这个参数,因为subsample参数和colsample_bytree参数可以起到相同的作用。但是如果感兴趣,可以挖掘这个参数更多的用处。
- 范围: (0,1]
- lambda [缺省值=1,别名: reg_lambda]
- 权重的L2正则化项(和Ridge regression类似)。
- 这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数
- 在减少过拟合上还是可以挖掘出更多用处的。.
- alpha [缺省值=0,别名: reg_alpha]
- 权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。
- scale_pos_weight[缺省值=1]
- 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负
- 样本的数目与正样本数目的比值。
2.2.2 Parameters for Linear Booster
linear booster一般很少用到。
- lambda [缺省值=0,别称: reg_lambda]
- L2正则化惩罚系数,增加该值会使得模型更加保守。
- alpha [缺省值=0,别称: reg_alpha]
- L1正则化惩罚系数,增加该值会使得模型更加保守。
- lambda_bias [缺省值=0,别称: reg_lambda_bias]
- 偏置上的L2正则化(没有在L1上加偏置,因为并不重要)
2.3 学习目标参数(task parameters)
-
objective [缺省值=reg:linear]
- “reg:linear” – 线性回归
- “reg:logistic” – 逻辑回归
- “binary:logistic” – 二分类逻辑回归,输出为概率
- “multi:softmax” – 使用softmax的多分类器,返回预测的类别(不是概率)。在这种情况下,你还需要多设一个参数:num_class(类别数目)
- “multi:softprob” – 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
-
eval_metric [缺省值=通过目标函数选择]
可供选择的如下所示:
-
“rmse”: 均方根误差
-
“mae”: 平均绝对值误差
-
“logloss”: 负对数似然函数值
-
“
-
error”
- 二分类错误率。
- 其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。
-
“error@t”: 不同的划分阈值可以通过 ‘t’进行设置
-
“merror”: 多分类错误率,计算公式为(wrong cases)/(all cases)
-
“mlogloss”: 多分类log损失
-
“auc”: 曲线下的面积
-
-
seed [缺省值=0]
- 随机数的种子
- 设置它可以复现随机数据的结果,也可以用于调整参数
3 xgboost案例介绍
3.1 案例背景
该案例和前面决策树中所用案例一样。
泰坦尼克号沉没是历史上最臭名昭着的沉船事件之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。 在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
案例:https://www.kaggle.com/c/titanic/overview
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt

经过观察数据得到:
- 1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
- 2 其中age数据存在缺失。
3.2 步骤分析
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程(字典特征抽取)
- 4.机器学习(xgboost)
- 5.模型评估
3.3 代码实现
- 导入需要的模块
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
- 1.获取数据
# 1、获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
- 2.数据基本处理
- 2.1 确定特征值,目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
- 2.2 缺失值处理
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取
x['age'].fillna(x['age'].mean(), inplace=True)
- 2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
- 3.特征工程(字典特征抽取)
特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
x.to_dict(orient=“records”) 需要将数组特征转换成字典数据
# 对于x转换成字典数据x.to_dict(orient="records")
# ["pclass": "1st", "age": 29.00, "sex": "female", ]
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
- 4.xgboost模型训练和模型评估
# 模型初步训练
from xgboost import XGBClassifier
xg = XGBClassifier()
xg.fit(x_train, y_train)
xg.score(x_test, y_test)
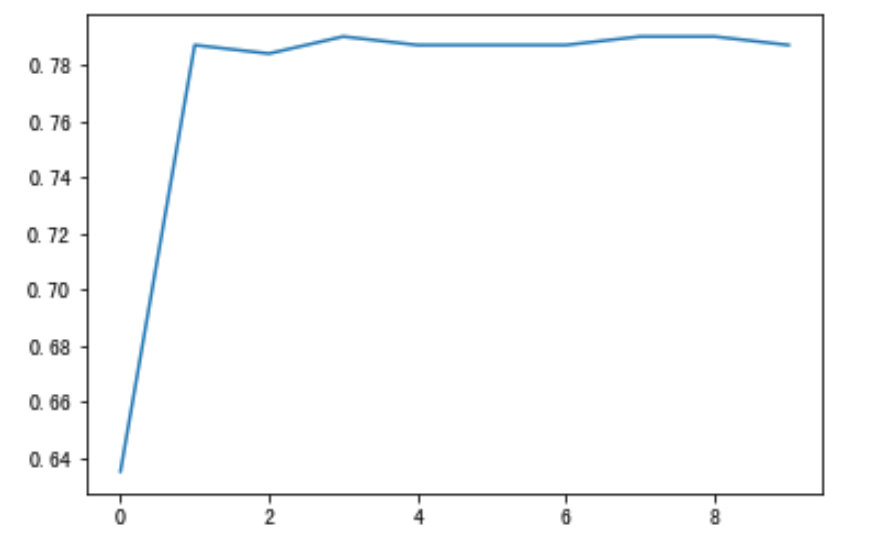
# 针对max_depth进行模型调优
depth_range = range(10)
score = []
for i in depth_range:
xg = XGBClassifier(eta=1, gamma=0, max_depth=i)
xg.fit(x_train, y_train)
s = xg.score(x_test, y_test)
print(s)
score.append(s)
# 结果可视化
import matplotlib.pyplot as plt
plt.plot(depth_range, score)
plt.show()
4 otto案例介绍
– Otto Group Product Classification Challenge【xgboost实现】
4.1 背景介绍
奥托集团是世界上最大的电子商务公司之一,在20多个国家设有子公司。该公司每天都在世界各地销售数百万种产品,所以对其产品根据性能合理的分类非常重要。
不过,在实际工作中,工作人员发现,许多相同的产品得到了不同的分类。本案例要求,你对奥拓集团的产品进行正确的分分类。尽可能的提供分类的准确性。
链接:https://www.kaggle.com/c/otto-group-product-classification-challenge/overview
4.22 思路分析
- 1.数据获取
- 2.数据基本处理
- 2.1 截取部分数据
- 2.2 把标签纸转换为数字
- 2.3 分割数据(使用StratifiedShuffleSplit)
- 2.4 数据标准化
- 2.5 数据pca降维
- 3.模型训练
- 3.1 基本模型训练
- 3.2 模型调优
- 3.2.1 调优参数:
- n_estimator,
- max_depth,
- min_child_weights,
- subsamples,
- consample_bytrees,
- etas
- 3.2.2 确定最后最优参数
- 3.2.1 调优参数:
4.3 部分代码实现
- 2.数据基本处理
- 2.1 截取部分数据
- 2.2 把标签值转换为数字
- 2.3 分割数据(使用StratifiedShuffleSplit)
# 使用StratifiedShuffleSplit对数据集进行分割
from sklearn.model_selection import StratifiedShuffleSplit
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
for train_index, test_index in sss.split(X_resampled.values, y_resampled):
print(len(train_index))
print(len(test_index))
x_train = X_resampled.values[train_index]
x_val = X_resampled.values[test_index]
y_train = y_resampled[train_index]
y_val = y_resampled[test_index]
# 分割数据图形可视化
import seaborn as sns
sns.countplot(y_val)
plt.show()
- 2.4 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_val_scaled = scaler.transform(x_val)
- 2.5 数据pca降维
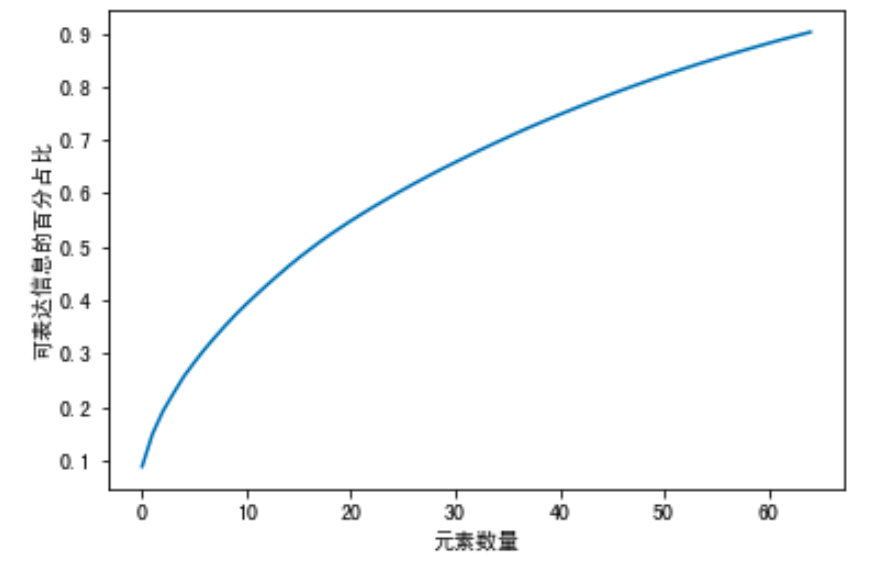
print(x_train_scaled.shape)
# (13888, 93)
from sklearn.decomposition import PCA
pca = PCA(n_components=0.9)
x_train_pca = pca.fit_transform(x_train_scaled)
x_val_pca = pca.transform(x_val_scaled)
print(x_train_pca.shape, x_val_pca.shape)
(13888, 65) (3473, 65)
从上面输出的数据可以看出,只选择65个元素,就可以表达出特征中90%的信息
# 降维数据可视化
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel("元素数量")
plt.ylabel("可表达信息的百分占比")
plt.show()
- 3.模型训练
- 3.1 基本模型训练
from xgboost import XGBClassifier
xgb = XGBClassifier()
xgb.fit(x_train_pca, y_train)
# 改变预测值的输出模式,让输出结果为百分占比,降低logloss值
y_pre_proba = xgb.predict_proba(x_val_pca)
# logloss进行模型评估
from sklearn.metrics import log_loss
log_loss(y_val, y_pre_proba, eps=1e-15, normalize=True)
xgb.get_params
-
3.2 模型调优
-
3.2.1 调优参数:
-
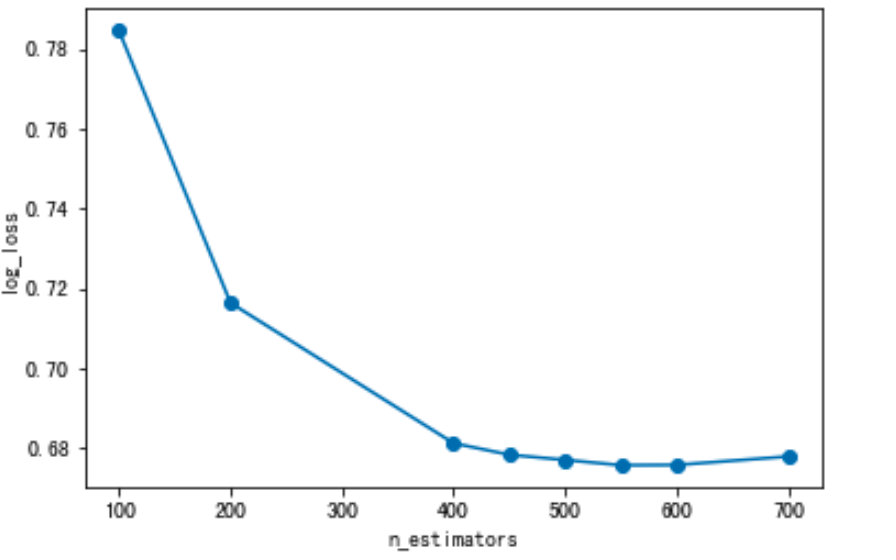
1) n_estimator
scores_ne = []
n_estimators = [100,200,400,450,500,550,600,700]
for nes in n_estimators:
print("n_estimators:", nes)
xgb = XGBClassifier(max_depth=3,
learning_rate=0.1,
n_estimators=nes,
objective="multi:softprob",
n_jobs=-1,
nthread=4,
min_child_weight=1,
subsample=1,
colsample_bytree=1,
seed=42)
xgb.fit(x_train_pca, y_train)
y_pre = xgb.predict_proba(x_val_pca)
score = log_loss(y_val, y_pre)
scores_ne.append(score)
print("测试数据的logloss值为:".format(score))
# 数据变化可视化
plt.plot(n_estimators, scores_ne, "o-")
plt.ylabel("log_loss")
plt.xlabel("n_estimators")
print("n_estimators的最优值为:".format(n_estimators[np.argmin(scores_ne)]))
- 2)max_depth
scores_md = []
max_depths = [1,3,5,6,7]
for md in max_depths: # 修改
xgb = XGBClassifier(max_depth=md, # 修改
learning_rate=0.1,
n_estimators=n_estimators[np.argmin(scores_ne)], # 修改
objective="multi:softprob",
n_jobs=-1,
nthread=4,
min_child_weight=1,
subsample=1,
colsample_bytree=1,
seed=42)
xgb.fit(x_train_pca, y_train)
y_pre = xgb.predict_proba(x_val_pca)
score = log_loss(y_val, y_pre)
scores_md.append(score) # 修改
print("测试数据的logloss值为:".format(log_loss(y_val, y_pre)))
# 数据变化可视化
plt.plot(max_depths, scores_md, "o-") # 修改
plt.ylabel("log_loss")
plt.xlabel("max_depths") # 修改
print("max_depths的最优值为:".format(max_depths[np.argmin(scores_md)])) # 修改
- 3) min_child_weights,
- 依据上面模式进行调整
- 4) subsamples,
- 5) consample_bytrees,
- 6) etas
- 3.2.2 确定最后最优参数
xgb = XGBClassifier(learning_rate =0.1,
n_estimators=550,
max_depth=3,
min_child_weight=3,
subsample=0.7,
colsample_bytree=0.7,
nthread=4,
seed=42,
objective='multi:softprob')
xgb.fit(x_train_scaled, y_train)
y_pre = xgb.predict_proba(x_val_scaled)
print("测试数据的logloss值为 : ".format(log_loss(y_val, y_pre, eps=1e-15, normalize=True)))
以上是关于机器学习集成学习进阶Xgboost算法案例分析的主要内容,如果未能解决你的问题,请参考以下文章
史诗级干货长文集成学习进阶(XGBoost & lightGBM)