机器学习HMM模型算法实例
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习HMM模型算法实例相关的知识,希望对你有一定的参考价值。
目录
1 前向算法求HMM观测序列的概率
前向后向算法是前向算法和后向算法的统称,这两个算法都可以用来求HMM观测序列的概率。我们先来看看前向算法是如何求解这个问题的。
1.1 流程梳理
前向算法本质上属于动态规划的算法,也就是我们要通过找到局部状态递推的公式,这样一步步的从子问题的最优解拓展到整个问题的最优解。
-
在前向算法中,通过定义“前向概率”来定义动态规划的这个局部状态。
-
什么是前向概率呢, 其实定义很简单:**定义时刻t时隐藏状态为qi, 观测状态的序列为
 的概率为前向概率。**记为:
的概率为前向概率。**记为: -
既然是动态规划,我们就要递推了,现在假设我们已经找到了在时刻t时各个隐藏状态的前向概率,现在我们需要递推出时刻t+1时各个隐藏状态的前向概率。
-
我们可以基于时刻t时各个隐藏状态的前向概率,再乘以对应的状态转移概率,即
 就是在时刻t观测到
就是在时刻t观测到 ,并且时刻t隐藏状态qj 时刻t+1隐藏状态qi的概率。
,并且时刻t隐藏状态qj 时刻t+1隐藏状态qi的概率。 -
如果将下面所有的线对应的概率求和,即
 就是在时刻t观测到,并且时刻t+1隐藏状态qi的概率。
就是在时刻t观测到,并且时刻t+1隐藏状态qi的概率。 -
继续一步,由于观测状态ot+1只依赖于t+1时刻隐藏状态qi, 这样
 就是在时刻t+1观测到
就是在时刻t+1观测到 ,并且时刻t+1隐藏状态的qi概率。
,并且时刻t+1隐藏状态的qi概率。 -
而这个概率,恰恰就是时刻t+1对应的隐藏状态i的前向概率,这样我们得到了前向概率的递推关系式如下:
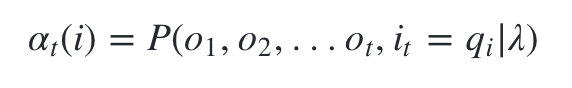
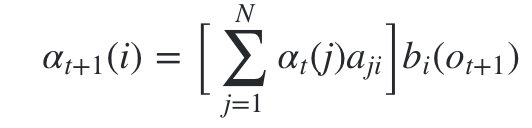
我们的动态规划从时刻1开始,到时刻T结束,由于αT(i)表示在时刻T观测序列为,并且时刻T隐藏状态qi的概率,我们只要将所有隐藏状态对应的概率相加,即 就得到了在时刻T观测序列为的概率。
就得到了在时刻T观测序列为的概率。
1.2 算法总结
- 输入:HMM模型 λ=(A,B,Π),观测序列
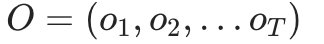
- 输出:观测序列概率P(O|λ)
-
- 计算时刻1的各个隐藏状态前向概率:
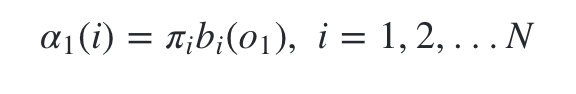
- 计算时刻1的各个隐藏状态前向概率:
-
- 递推时刻2,3,… …T时刻的前向概率:

- 递推时刻2,3,… …T时刻的前向概率:
-
- 计算最终结果:

- 计算最终结果:
-
从递推公式可以看出,我们的算法时间复杂度是O(TN2),比暴力解法的时间复杂度O(TNT)少了几个数量级。
1.3 HMM前向算法求解实例
这里我们用前面盒子与球的例子来显示前向概率的计算。 我们的观察集合是:

我们的状态集合是:

而观察序列和状态序列的长度为3.
初始状态分布为:

状态转移概率分布矩阵为:

观测状态概率矩阵为:

球的颜色的观测序列:

按照我们上一节的前向算法。首先计算时刻1三个状态的前向概率:
时刻1是红色球,
- 隐藏状态是盒子1的概率为:

- 隐藏状态是盒子2的概率为:

- 隐藏状态是盒子3的概率为:
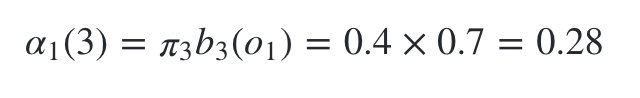
现在我们可以开始递推了,首先递推时刻2三个状态的前向概率:
时刻2是白色球,
- 隐藏状态是盒子1的概率为:

- 隐藏状态是盒子2的概率为:

- 隐藏状态是盒子3的概率为:
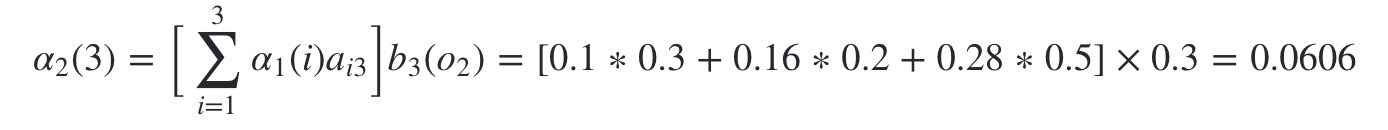
继续递推,现在我们递推时刻3三个状态的前向概率:
时刻3是红色球,
- 隐藏状态是盒子1的概率为:
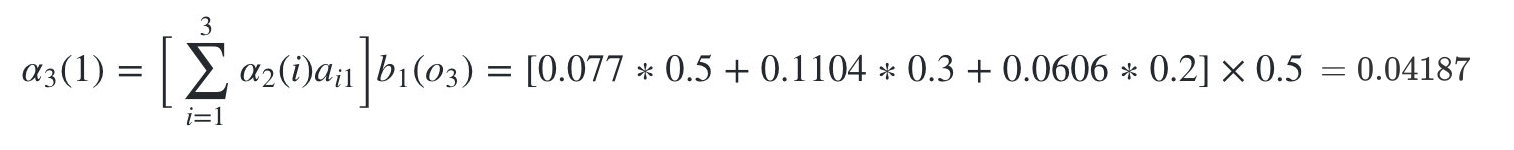
- 隐藏状态是盒子2的概率为:
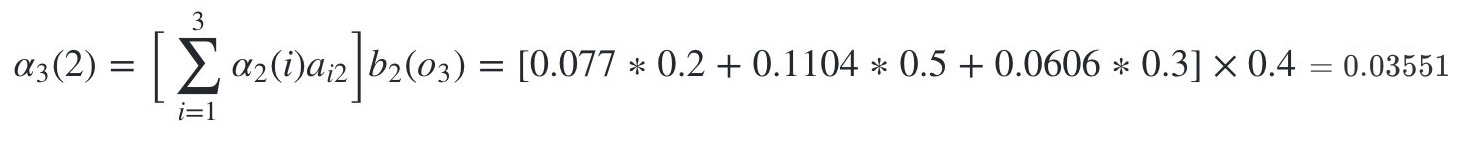
- 隐藏状态是盒子3的概率为:
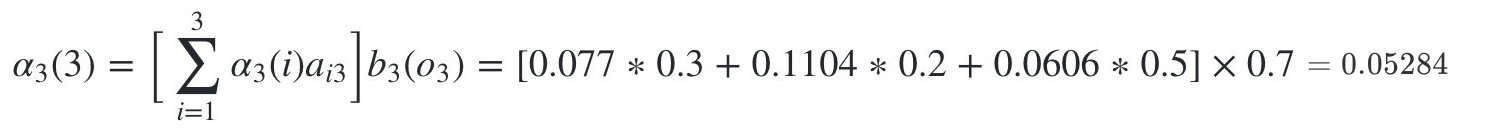
最终我们求出观测序列:O=红,白,红的概率为:
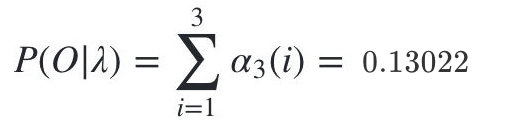
1.4 用后向算法求HMM观测序列的概率
1.4.1 流程梳理
熟悉了用前向算法求HMM观测序列的概率,现在我们再来看看怎么用后向算法求HMM观测序列的概率。
后向算法和前向算法非常类似,都是用的动态规划,唯一的区别是选择的局部状态不同,后向算法用的是“后向概率”。
1.4.2 后向算法流程
以下是后向算法的流程,注意下和前向算法的相同点和不同点:
- 输入:HMM模型 λ=(A,B,Π),观测序列
- 输出:观测序列概率P(O|λ)
- 初始化时刻T的各个隐藏状态后向概率:

- 递推时刻T−1,T−2,…1时刻的后向概率:
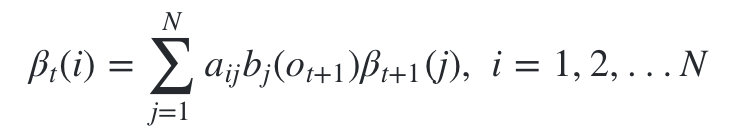
- 计算最终结果:
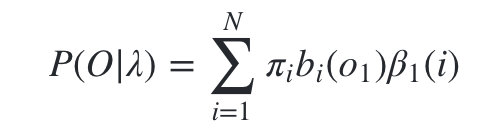
- 初始化时刻T的各个隐藏状态后向概率:
此时我们的算法时间复杂度仍然是O(TN2)
1.5 小结
- 前向算法求HMM观测序列
- 输入:HMM模型 λ=(A,B,Π),观测序列
- 输出:观测序列概率P(O|λ)
-
- 计算时刻1的各个隐藏状态前向概率:
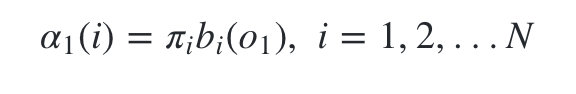
- 计算时刻1的各个隐藏状态前向概率:
-
- 递推时刻2,3,… …T时刻的前向概率:
- 递推时刻2,3,… …T时刻的前向概率:
-
- 计算最终结果:
- 计算最终结果:
-
- 输入:HMM模型 λ=(A,B,Π),观测序列
- 后向算法求HMM观测序列
- 输入:HMM模型 λ=(A,B,Π),观测序列
- 输出:观测序列概率P(O|λ)
- 初始化时刻T的各个隐藏状态后向概率:
- 递推时刻T−1,T−2,…1时刻的后向概率:
- 计算最终结果:
- 初始化时刻T的各个隐藏状态后向概率:
- 输入:HMM模型 λ=(A,B,Π),观测序列
2 维特比算法解码隐藏状态序列
2.1 HMM最可能隐藏状态序列求解概述
在本篇我们会讨论维特比算法解码隐藏状态序列,即给定模型和观测序列,求给定观测序列条件下,最可能出现的对应的隐藏状态序列。
HMM模型的解码问题最常用的算法是维特比算法,当然也有其他的算法可以求解这个问题。
同时维特比算法是一个通用的求序列最短路径的动态规划算法,也可以用于很多其他问题。
HMM模型的解码问题即:
- 给定模型 λ=(A,B,Π) 和观测序列
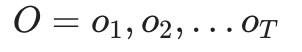 ,求给定观测序列O条件下,最可能出现的对应的状态序列
,求给定观测序列O条件下,最可能出现的对应的状态序列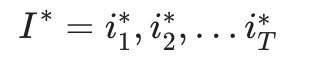 ,即
,即 的最大化。
的最大化。
一个可能的近似解法是求出观测序列O在每个时刻t最可能的隐藏状态 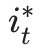 然后得到一个近似的隐藏状态序列
然后得到一个近似的隐藏状态序列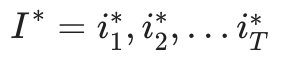 。要这样近似求解不难,利用前向后向算法评估观察序列概率的定义:
。要这样近似求解不难,利用前向后向算法评估观察序列概率的定义:
-
在给定模型λ和观测序列O时,在时刻t处于状态q
i
的概率是
,这个概率可以通过HMM的前向算法与后向算法计算。这样我们有:

近似算法很简单,但是却不能保证预测的状态序列整体是最可能的状态序列,因为预测的状态序列中某些相邻的隐藏状态可能存在转移概率为0的情况。
而维特比算法可以将HMM的状态序列作为一个整体来考虑,避免近似算法的问题,下面我们来看看维特比算法进行HMM解码的方法。
2.2 维特比算法概述
维特比算法是一个通用的解码算法,是基于动态规划的求序列最短路径的方法。
既然是动态规划算法,那么就需要找到合适的局部状态,以及局部状态的递推公式。在HMM中,维特比算法定义了两个局部状态用于递推。
- 第一个局部状态是在时刻t隐藏状态为 i 所有可能的状态转移路径
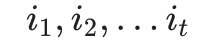 中的概率最大值。
中的概率最大值。
- 记为
 :
:
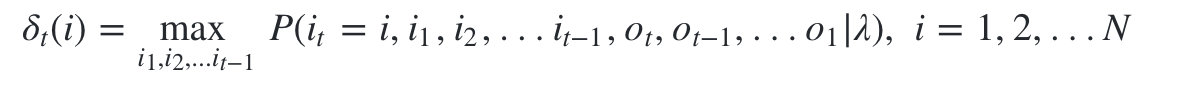
由 的定义可以得到
的定义可以得到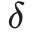 的递推表达式:
的递推表达式:

- 第二个局部状态由第一个局部状态递推得到。
- 我们定义在时刻t隐藏状态为i的所有单个状态转移路径
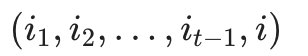 中概率最大的转移路径中第t-1个节点的隐藏状态为:
中概率最大的转移路径中第t-1个节点的隐藏状态为:
- 其递推表达式可以表示为:
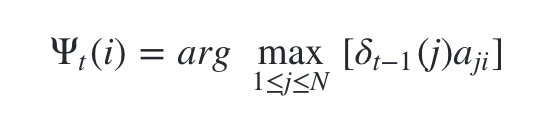
有了这两个局部状态,我们就可以从时刻0一直递推到时刻T,然后利用 记录的前一个最可能的状态节点回溯,直到找到最优的隐藏状态序列。
记录的前一个最可能的状态节点回溯,直到找到最优的隐藏状态序列。
2.3 维特比算法流程总结
现在我们来总结下维特比算法的流程:
- 输入:HMM模型 λ=(A,B,Π),观测序列

- 输出:最有可能的隐藏状态序列

流程如下:
- 1)初始化局部状态:
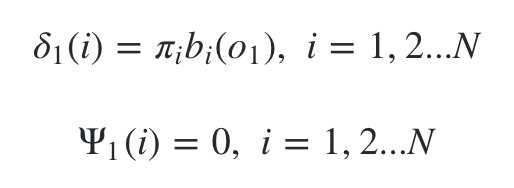
-
- 进行动态规划递推时刻 t=2,3,…T 时刻的局部状态:
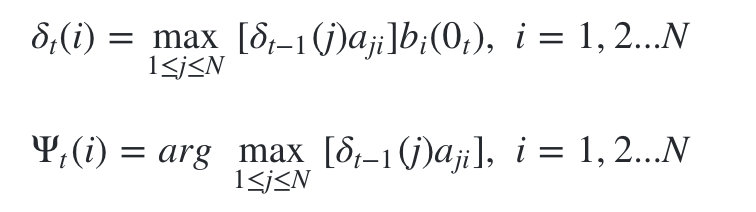
-
- 计算时刻T最大的
 ,即为最可能隐藏状态序列出现的概率。计算时刻T最大的
,即为最可能隐藏状态序列出现的概率。计算时刻T最大的 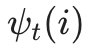 ,即为时刻T最可能的隐藏状态。
,即为时刻T最可能的隐藏状态。
- 计算时刻T最大的

-
- 利用局部状态
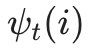 开始回溯。对于 t=T-1,T-2,…,1
开始回溯。对于 t=T-1,T-2,…,1
- 利用局部状态
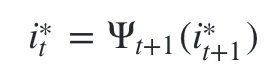
最终得到最有可能的隐藏状态序列: 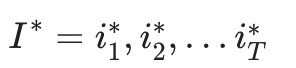
2.4 HMM维特比算法求解实例
下面我们仍然用盒子与球的例子来看看HMM维特比算法求解。 我们的观察集合是:

我们的状态集合是:

而观察序列和状态序列的长度为3.
初始状态分布为:
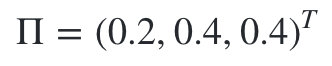
状态转移概率分布矩阵为:

观测状态概率矩阵为:
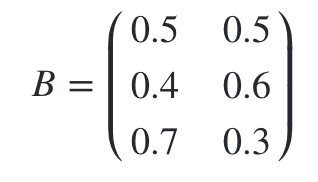
球的颜色的观测序列:

按照我们前面的维特比算法,首先需要得到三个隐藏状态在时刻1时对应的各自两个局部状态,此时观测状态为1:

现在开始递推三个隐藏状态在时刻2时对应的各自两个局部状态,此时观测状态为2:
- \\delta_2(1) = \\max_1\\leq j \\leq 3[\\delta_1(j)a_j1]b_1(o_2) = \\max_1\\leq j \\leq 3[0.1 \\times 0.5, 0.16 \\times 0.3, 0.28\\times 0.2] \\times 0.5 = 0.028δ2(1)=max1≤j≤3[δ1(j)a**j1]b1(o2)=max1≤j≤3[0.1×0.5,0.16×0.3,0.28×0.2]×0.5=0.028
- \\Psi_2(1)=3Ψ2(1)=3
- \\delta_2(2) = \\max_1\\leq j \\leq 3[\\delta_1(j)a_j2]b_2(o_2) = \\max_1\\leq j \\leq 3[0.1 \\times 0.2, 0.16 \\times 0.5, 0.28\\times 0.3] \\times 0.6 = 0.0504δ2(2)=max1≤j≤3[δ1(j)a**j2]b2(o2)=max1≤j≤3[0.1×0.2,0.16×0.5,0.28×0.3]×0.6=0.0504
- \\Psi_2(2)=3Ψ2(2)=3
- \\delta_2(3) = \\max_1\\leq j \\leq 3[\\delta_1(j)a_j3]b_3(o_2) = \\max_1\\leq j \\leq 3[0.1 \\times 0.3, 0.16 \\times 0.2, 0.28\\times 0.5] \\times 0.3 = 0.042δ2(3)=max1≤j≤3[δ1(j)a**j3]b3(o2)=max1≤j≤3[0.1×0.3,0.16×0.2,0.28×0.5]×0.3=0.042
- \\Psi_2(3)=3Ψ2(3)=3
继续递推三个隐藏状态在时刻3时对应的各自两个局部状态,此时观测状态为1:
- \\delta_3(1) = \\max_1\\leq j \\leq 3[\\delta_2(j)a_j1]b_1(o_3) = \\max_1\\leq j \\leq 3[0.028 \\times 0.5, 0.0504 \\times 0.3, 0.042\\times 0.2] \\times 0.5 = 0.00756δ3(1)=max1≤j≤3[δ2(j)a**j1]b1(o3)=max1≤j≤3[0.028×0.5,0.0504×0.3,0.042×0.2]×0.5=0.00756
- \\Psi_3(1)=2Ψ3(1)=2
- \\delta_3(2) = \\max_1\\leq j \\leq 3[\\delta_2(j)a_j2]b_2(o_3) = \\max_1\\leq j \\leq 3[0.028 \\times 0.2, 0.0504\\times 0.5, 0.042\\times 0.3] \\times 0.4 = 0.01008δ3(2)=max1≤j≤3[δ2(j)a**j2]b2(o3)=max1≤j≤3[0.028×0.2,0.0504×0.5,0.042×0.3]×0.4=0.01008
- \\Psi_3(2)=2Ψ3(2)=2
- \\delta_3(3) = \\max_1\\leq j \\leq 3[\\delta_2(j)a_j3]b_3(o_3) = \\max_1\\leq j \\leq 3[0.028 \\times 0.3, 0.0504 \\times 0.2, 0.042\\times 0.5] \\times 0.7 = 0.0147δ3(3)=max1≤j≤3[δ2(j)a**j3]b3(o3)=max1≤j≤3[0.028×0.3,0.0504×0.2,0.042×0.5]×0.7=0.0147
- \\Psi_3(3)=3Ψ3(3)=3

2.5 小结
- 维特比算法流程总结:
- 输入:HMM模型 λ=(A,B,Π),观测序列

- 输出:最有可能的隐藏状态序列
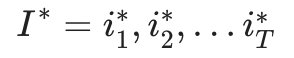
- 输入:HMM模型 λ=(A,B,Π),观测序列
流程如下:
- 1)初始化局部状态:
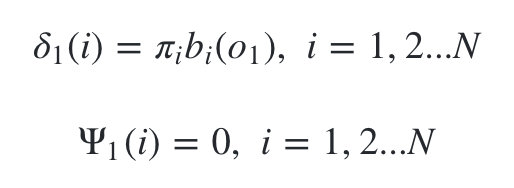
-
- 进行动态规划递推时刻 t=2,3,…T 时刻的局部状态:
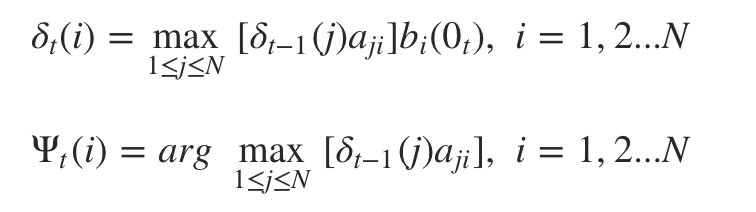
-
- 计算时刻T最大的
 ,即为最可能隐藏状态序列出现的概率。计算时刻T最大的
,即为最可能隐藏状态序列出现的概率。计算时刻T最大的 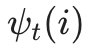 ,即为时刻T最可能的隐藏状态。
,即为时刻T最可能的隐藏状态。
- 计算时刻T最大的
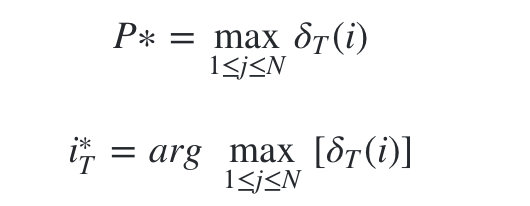
-
- 利用局部状态
 开始回溯。对于 t=T-1,T-2,…,1
开始回溯。对于 t=T-1,T-2,…,1
- 利用局部状态
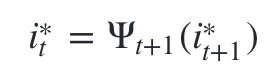
最终得到最有可能的隐藏状态序列: 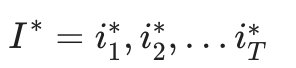
3 鲍姆-韦尔奇算法简介
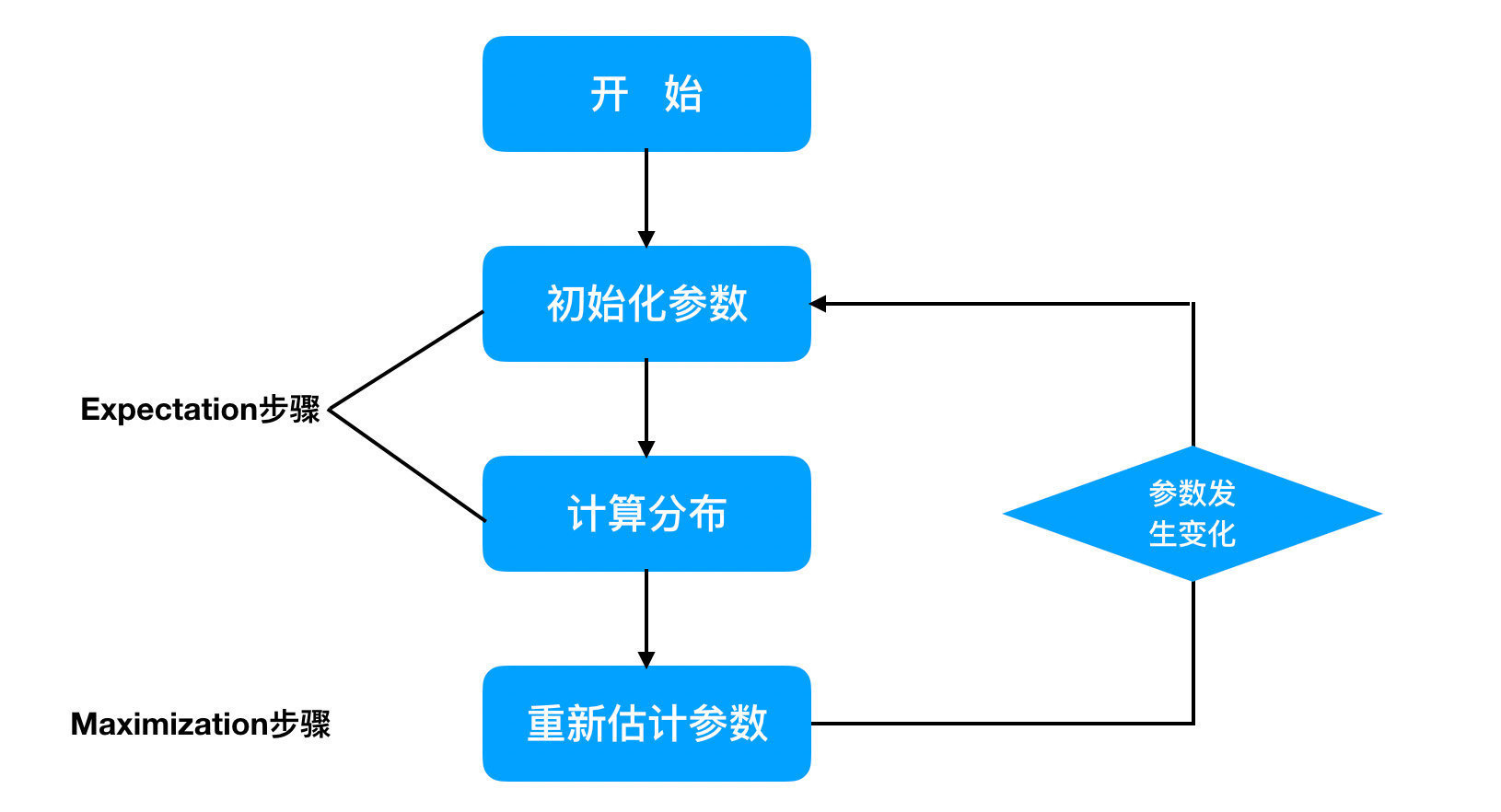
3.1 鲍姆-韦尔奇算法简介
模型参数学习问题 —— 鲍姆-韦尔奇(Baum-Welch)算法(状态未知) ,
- 即给定观测序列
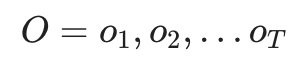 ,估计模型的λ=(A,B,Π)参数,使该模型下观测序列的条件概率最P(O|λ)大。
,估计模型的λ=(A,B,Π)参数,使该模型下观测序列的条件概率最P(O|λ)大。 - 它的解法最常用的是鲍姆-韦尔奇算法,其实就是基于EM算法的求解,只不过鲍姆-韦尔奇算法出现的时代,EM算法还没有被抽象出来,所以被叫为鲍姆-韦尔奇算法。
3.2 鲍姆-韦尔奇算法原理
鲍姆-韦尔奇算法原理既然使用的就是EM算法的原理,
- 那么我们需要在E步求出联合分布P(O,I|λ)基于条件概率
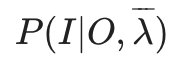 的期望,其中
的期望,其中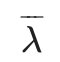 为当前的模型参数,
为当前的模型参数, - 然后在M步最大化这个期望,得到更新的模型参数λ。
接着不停的进行EM迭代,直到模型参数的值收敛为止。
首先来看看E步,当前模型参数为 , 联合分布P(O,I|λ)基于条件概率的期望表达式为:
, 联合分布P(O,I|λ)基于条件概率的期望表达式为:
- L(\\lambda, \\overline\\lambda) = \\sum\\limits_IP(I|O,\\overline\\lambda)logP(O,I|\\lambda)L(λ,λ)=I∑P(I∣O,λ)log**P(O,I∣λ)
在M步,我们极大化上式,然后得到更新后的模型参数如下:
- \\overline\\lambda = arg;\\max_\\lambda\\sum\\limits_IP(I|O,\\overline\\lambda)logP(O,I|\\lambda)λ=argmaxλ**I∑P(I∣O,λ)log**P(O,I∣λ)
通过不断的E步和M步的迭代,直到收敛。
4 HMM模型API介绍
4.1 API的安装:
官网链接:https://hmmlearn.readthedocs.io/en/latest/
pip3 install hmmlearn
4.2 hmmlearn介绍
hmmlearn实现了三种HMM模型类,按照观测状态是连续状态还是离散状态,可以分为两类。
GaussianHMM和GMMHMM是连续观测状态的HMM模型,而MultinomialHMM是离散观测状态的模型,也是我们在HMM原理系列篇里面使用的模型。
在这里主要介绍我们前面一直讲的关于离散状态的MultinomialHMM模型。
对于MultinomialHMM的模型,使用比较简单,里面有几个常用的参数:
- "startprob_"参数对应我们的隐藏状态初始分布Π,
- "transmat_"对应我们的状态转移矩阵A,
- "emissionprob_"对应我们的观测状态概率矩阵B。
4.3 MultinomialHMM实例
下面我们用我们在前面讲的关于球的那个例子使用MultinomialHMM跑一遍。
import numpy as np
from hmmlearn import hmm
# 设定隐藏状态的集合
states = ["box 1", "box 2", "box3"]
n_states = len(states)
# 设定观察状态的集合
observations = ["red", "white"]
n_observations = len(observations)
# 设定初始状态分布
start_probability = np.array([0.2, 0.4, 0.4])
# 设定状态转移概率分布矩阵
transition_probability = np.array([
[0.5, 0.2, 0.3],
[0.3, 0.5, 0.2],
[0.2, 0.3, 0.5]
])
# 设定观测状态概率矩阵
emission_probability = np.array([
[0.5, 0.5],
[0.4, 0.6],
[0.7, 0.3]
])
# 设定模型参数
model = hmm.MultinomialHMM(n_components=n_states)
model.startprob_=start_probability # 初始状态分布
model.transmat_=transition_probability # 状态转移概率分布矩阵
model.emissionprob_=emission_probability # 观测状态概率矩阵
现在我们来跑一跑HMM问题三维特比算法的解码过程,使用和之前一样的观测序列来解码,代码如下:
seen = np.array([[0,1,0]]).T # 设定观测序列
box = model.predict(seen)
print("球的观测顺序为:\\n", ", ".join(map(lambda x: observations[x], seen.flatten())))
# 注意:需要使用flatten方法,把seen从二维变成一维
print("最可能的隐藏状态序列为:\\n", ", ".join(map(lambda x: states[x], box)))
我们再来看看求HMM问题一的观测序列的概率的问题,代码如下:
print(model.score(seen))
# 输出结果是:-2.03854530992
要注意的是score函数返回的是以自然对数为底的对数概率值,我们在HMM问题一中手动计算的结果是未取对数的原始概率是0.13022。对比一下:
import math
math.exp(-2.038545309915233)
# ln0.13022≈−2.0385
# 输出结果是:0.13021800000000003
以上是关于机器学习HMM模型算法实例的主要内容,如果未能解决你的问题,请参考以下文章