caffe lstm训练mnist手写数字
Posted 阳光玻璃杯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了caffe lstm训练mnist手写数字相关的知识,希望对你有一定的参考价值。
我们可以把深度学习能做的事情分为两类:时间无关的事情和时间相关的事情。时间无关的话,比如人脸识别,给神经网络一张照片,神经网络就能告诉你这是谁,这是和时间无关的。时间相关的话,比如,我要知道一段视频里的人是在吃饭还是在打哈欠,这个可能通过一张照片是无法判别的,但是通过多张连续的图片,构成一段视频,我们就可以判别这个人是在打哈欠还是在吃饭了。
可是,手写数字明明是一张张无时间关系的静态图片啊?我们怎么用它来训练处理序列数据的lstm这种递归神经网络呢?其实,我们可以这样想:我们把一张手写数字的图片(28*28),看做是28个有序列的数据,每一个数据大小为28个字节,因为这28行我们可以理解为是随着时间的推移,一行一行写出来的。这样,我们就可以用lstm来训练手写数字了。
在 caffe 上配置 LSTM 时,数据的维度比较复杂。比如在 CNN 处理图片时,caffe 的数据维度一般是 NCHW,N 是 batch size,C 是 channel,W 是 width,H 是 height;但是 LSTM 的数据维度是 TN*…,T 是 sequence length,N 是 batch size,但是本人以为这里的N是同时处理的数据流的个数,我们做Mnist手写数字识别的时候,只有一个流,因此这里N为1。T则是序列的长度,毫无疑问,我们这里的序列长度就是28呀。
lstm需要输入两个Blob,一个为(T,N,V)的待处理的数据,另一个为(T,N,1)的标识连续帧的数据。比如我们的例子中,28个长度为28的数据构成一个序列,标识连续帧的cont应该为(0,1,1…共有27个1),而且只需要一行就可以了,因为所有的序列都是一样的,只需要为一个序列做标识就可以了。
cont我们以hdf5的格式给出,对hdf5不了解的先了解下hdf5吧,总之还是蛮简单的,我们只需要生成一行(0,1,1…共有27个1)这样的数据就可以了。
代码如下:
#include "hdf5.h"
#include <stdio.h>
#include <stdlib.h>
#define FILE "h5ex_d_rdwr.h5"
#define DATASET "cont"
#define DIM0 1
#define DIM1 28
int main(void)
hid_t file, space, dset; /* Handles */
herr_t status;
hsize_t dims[2] = DIM0, DIM1 ;
int wdata[DIM0][DIM1], /* Write buffer */
rdata[DIM0][DIM1]; /* Read buffer */
hsize_t i, j,batch;
/*
* Initialize data.
*/
for (i = 0; i < DIM0; i++)
for (j = 0; j < DIM1; j++)
if (j == 0)
wdata[i][j] = 0;
else
wdata[i][j] = 1;
/*
* Create a new file using the default properties.
*/
file = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
/*
* Create dataspace. Setting maximum size to NULL sets the maximum
* size to be the current size.
*/
space = H5Screate_simple(2, dims, NULL);
/*
* Create the dataset. We will use all default properties for this
* example.
*/
dset = H5Dcreate(file, DATASET, H5T_STD_I32LE, space, H5P_DEFAULT,
H5P_DEFAULT, H5P_DEFAULT);
/*
* Write the data to the dataset.
*/
status = H5Dwrite(dset, H5T_NATIVE_INT, H5S_ALL, H5S_ALL, H5P_DEFAULT,
wdata[0]);
/*
* Close and release resources.
*/
status = H5Dclose(dset);
status = H5Sclose(space);
status = H5Fclose(file);
/*
* Now we begin the read section of this example.
*/
/*
* Open file and dataset using the default properties.
*/
file = H5Fopen(FILE, H5F_ACC_RDONLY, H5P_DEFAULT);
dset = H5Dopen(file, DATASET, H5P_DEFAULT);
/*
* Read the data using the default properties.
*/
status = H5Dread(dset, H5T_NATIVE_INT, H5S_ALL, H5S_ALL, H5P_DEFAULT,
rdata[0]);
/*
* Output the data to the screen.
*/
printf("%s:\\n", DATASET);
for (i = 0; i<DIM0; i++)
printf(" [");
for (j = 0; j<DIM1; j++)
printf(" %3d", rdata[i][j]);
printf("]\\n");
/*
* Close and release resources.
*/
status = H5Dclose(dset);
status = H5Fclose(file);
return 0;
我的理解是只需要为一个序列做标注即可,caffe应该会为每个序列都运用次处标注的序列(此处为猜测,如果不对,谢谢指出)。

接下来,用Netscope来搭建神经网络,可以直观的看到神经网络的结构。
使用两个lstm层:
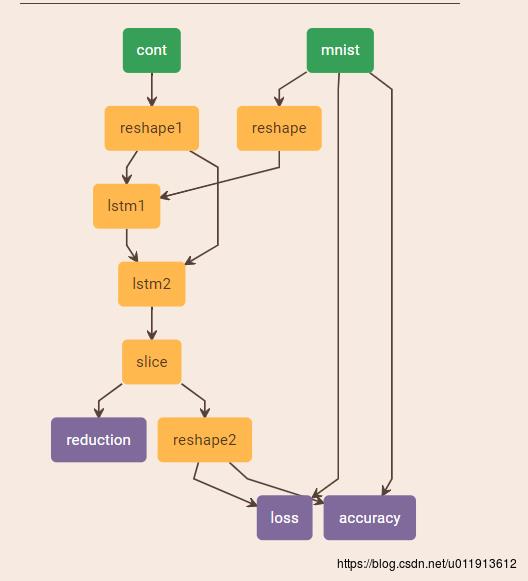
# Enter your network definition here.
# Use Shift+Enter to update the visualization.
name: "LeNet"
layer
name: "mnist"
type: "Data"
top: "data"
top: "label"
include
phase: TRAIN
transform_param
scale: 0.00390625
data_param
source: "examples/mnist/mnist_train_lmdb"
batch_size: 1
backend: LMDB
layer
name: "mnist"
type: "Data"
top: "data"
top: "label"
include
phase: TEST
transform_param
scale: 0.00390625
data_param
source: "examples/mnist/mnist_test_lmdb"
batch_size: 1
backend: LMDB
# 将 data 转换为 [T,Batch, H]
layer
name: "reshape"
type: "Reshape"
bottom: "data"
top: "reshape1"
reshape_param
shape dim:28 dim:1 dim:28
layer
name: "cont"
type: "HDF5Data"
top: "cont"
hdf5_data_param
source: "examples/mnist/lstm_conv_h5.txt" #此处要注意,lstm_conv_h5.txt只有一行:examples/mnist/h5ex_d_rdwr.h5,也就是我们生成hdf5文件的路径。
batch_size: 1
#将 cont 转换为 [T, batch]
layer
name: "reshape1"
type: "Reshape"
bottom: "cont"
top: "cont1"
reshape_param
shape dim:28 dim:1
layer
name: "lstm1"
type: "LSTM"
bottom: "reshape1"
bottom: "cont1"
top: "lstm1"
recurrent_param
num_output: 28
weight_filler
type: "uniform"
min: -0.08
max: 0.08
bias_filler
type: "constant"
value: 0
layer
name: "lstm2"
type: "LSTM"
bottom: "lstm1"
bottom: "cont1"
top: "lstm2"
recurrent_param
num_output: 10
weight_filler
type: "uniform"
min: -0.08
max: 0.08
bias_filler
type: "constant"
value: 0
#输出为28个时间步的 output [t, batch, 10] 只使用第28个时间步的值 output2
layer
name: "slice"
type: "Slice"
bottom: "lstm2"
top: "output1"
top: "output2"
slice_param
axis: 0
slice_point: 27
#output1 一直输出影响观察,这里随便加的一层,没有作用
layer
name: "reduction"
type: "Reduction"
bottom: "output1"
top: "output11"
reduction_param
axis: 0
layer
name: "reshape2"
type: "Reshape"
bottom: "output2"
top: "output22"
reshape_param
shape dim:1 dim:-1
layer
name: "loss"
type: "SoftmaxWithLoss"
bottom: "output22"
bottom: "label"
top: "loss"
layer
name: "accuracy"
type: "Accuracy"
bottom: "output22"
bottom: "label"
top: "accuracy"
# The train/test net protocol buffer definition
net: "examples/mnist/mnist_lstm.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 1000
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: GPU
学习速率很慢,训练个10000次才到43%,训练20000次能到百分之七十多…
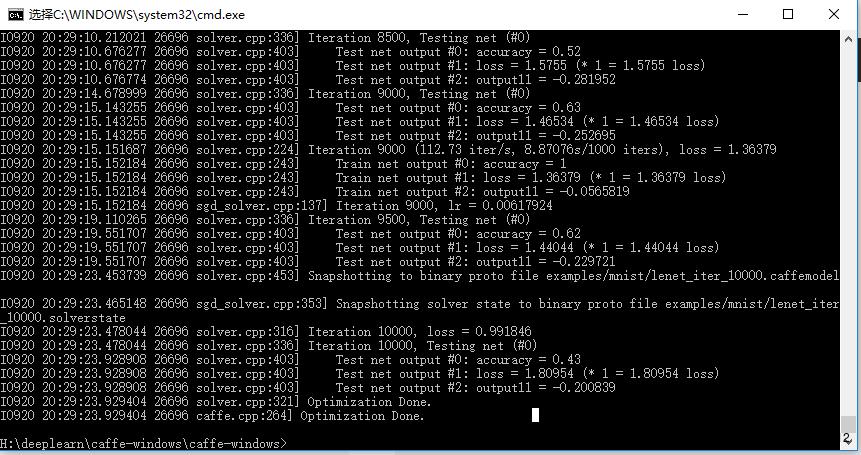
我的困惑是:
第一,为啥准确率这么低?
第二,为啥学习速率这么慢?
是我对lstm的理解有问题吗?大神能不能留言解答下?感谢
以上是关于caffe lstm训练mnist手写数字的主要内容,如果未能解决你的问题,请参考以下文章