❤️解决非线性回归问题的机器学习方法总结:多项式线性模型广义线性(GAM)模型回归树模型支持向量回归(SVR)模型
Posted Super__Tiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️解决非线性回归问题的机器学习方法总结:多项式线性模型广义线性(GAM)模型回归树模型支持向量回归(SVR)模型相关的知识,希望对你有一定的参考价值。
文章目录
前言
本文主要总结了解决非线性回归问题的机器学习方法,其中包括多项式线性模型、广义线性(GAM)模型、回归树模型、支持向量回归(SVR)模型,每个模型的方法都有其特点。
多项式线性模型和GAM模型侧重于经验风险误差最小化,容易过拟合;回归树模型和SVR模型侧重于结构风险最小化,对异常值数据更不敏感,回归树模型可通过剪枝和压缩的方式去降低过拟合的风险,SVR模型具有较好的区间内鲁棒能力。
多项式回归模型
概念解释:
-
为了体现因变量和特征的非线性关系,一个很自然而然的想法就是将标准的线性回归模型:
y i = w 0 + w 1 x i + ϵ i y_i = w_0 + w_1x_i + \\epsilon_i yi=w0+w1xi+ϵi
换成一个多项式函数:
y i = w 0 + w 1 x i + w 2 x i 2 + . . . + w d x i d + ϵ y_i = w_0 + w_1x_i + w_2x_i^2 + ...+w_dx_i^d + \\epsilon yi=w0+w1xi+w2xi2+...+wdxid+ϵ -
对于多项式的阶数d不能取过大,一般不大于3或者4,因为d越大,多项式曲线就会越光滑,在X的边界处有异常的波动。
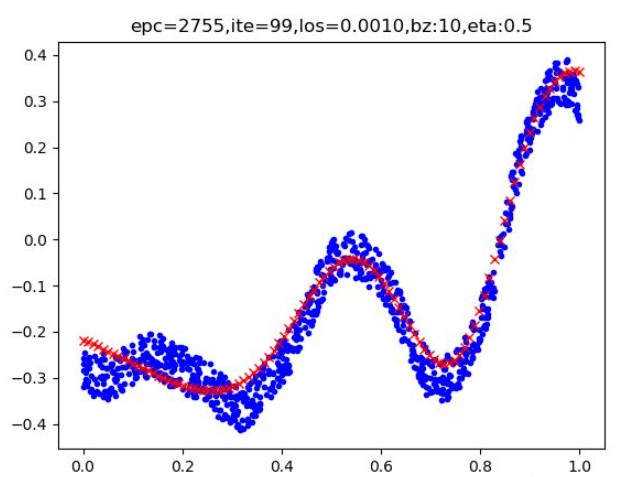
sklearn实现多项式回归模型:
sklearn.preprocessing.PolynomialFeatures(): 创建多项式回归模型。
- 参数:
degree:特征转换的阶数。
interaction_onlyboolean:是否只包含交互项,默认False 。
include_bias:是否包含截距项,默认True。
order:str in ‘C’, ‘F’, default ‘C’,输出数组的顺序。
from sklearn.preprocessing import PolynomialFeatures
X_arr = np.arange(6).reshape(3, 2)
print("原始X为:\\n",X_arr)
poly = PolynomialFeatures(2)
print("2次转化X:\\n",poly.fit_transform(X_arr))
poly = PolynomialFeatures(interaction_only=True)
print("2次转化X:\\n",poly.fit_transform(X_arr))
广义线性可加(GAM)模型
概念解释:
- 广义可加模型GAM实际上是线性模型推广至非线性模型的一个框架,在这个框架中,每一个变量都用一个非线性函数来代替,但是模型本身保持整体可加性。GAM模型不仅仅可以用在线性回归的推广,还可以将线性分类模型进行推广。具体的推广形式是:
标准的线性回归模型:
y i = w 0 + w 1 x i 1 + . . . + w p x i p + ϵ i y_i = w_0 + w_1x_i1 +...+w_px_ip + \\epsilon_i yi=w0+w1xi1+...+wpxip+ϵi
GAM模型框架:
y i = w 0 + ∑ j = 1 p f j ( x i j ) + ϵ i y_i = w_0 + \\sum\\limits_j=1^pf_j(x_ij) + \\epsilon_i yi=w0+j=1∑pfj(xij)+ϵi

pygam实现广义线性可加模型:
pygam.LinearGAM():创建广义线性可加模型。
-
参数:
terms:表达式指定要建模的术语,可选。
max_iter:允许求解器收敛的最大迭代次数。
tol:停止标准的容忍误差。
from pygam import LinearGAM
model = LinearGAM()
gam = model.fit(x, y)
print(model.summary())
print(gam.accuracy(X, y))
GAM模型的优点与不足:
-
优点:简单容易操作,能够很自然地推广线性回归模型至非线性模型,使得模型的预测精度有所上升;由于模型本身是可加的,因此GAM还是能像线性回归模型一样把其他因素控制不变的情况下单独对某个变量进行推断,极大地保留了线性回归的易于推断的性质。
-
缺点:GAM模型会经常忽略一些有意义的交互作用,比如某两个特征共同影响因变量,不过GAM还是能像线性回归一样加入交互项 x ( i ) × x ( j ) x^(i) \\times x^(j) x(i)×x(j)的形式进行建模;但是GAM模型本质上还是一个可加模型,如果我们能摆脱可加性模型形式,可能还会提升模型预测精度,详情请看后面的算法。
回归树模型
概念解释:
-
依据分层和分割的方式将特征空间划分为一系列简单的区域。
-
用所属区域中训练集的平均数或者众数对其进行预测。
-
决策树由结点(node)和有向边(directed edge)组成,结点有两种类型:内部结点(internal node)和叶结点(leaf node),内部结点(红框)表示一个特征或属性,叶结点(蓝框)表示一个类别或者某个值。
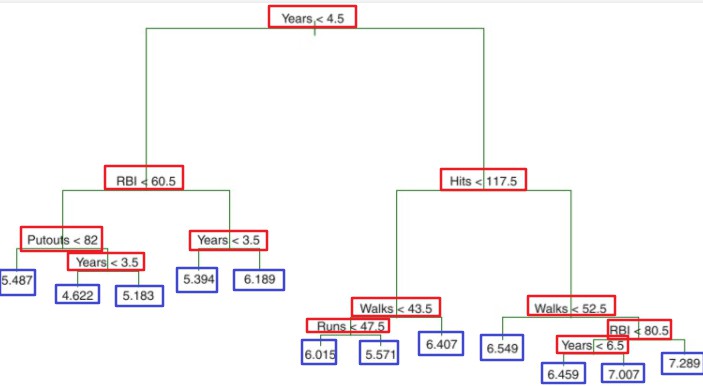
算法流程:
-
1.将自变量的特征空间(即 x ( 1 ) , x ( 2 ) , x ( 3 ) , . . . , x ( p ) x^(1),x^(2),x^(3),...,x^(p) x(1),x(2),x(3),...,x(p))的可能取值构成的集合分割成J个互不重叠的区域 R 1 , R 2 , . . . , R j R_1,R_2,...,R_j R1,R2,...,Rj。
-
2.对落入区域 R j R_j Rj的每个观测值作相同的预测,预测值等于 R j R_j Rj上训练集的因变量的简单算术平均:
a. 选择最优切分特征j以及该特征上的最优点s:
遍历特征j以及固定j后遍历切分点s,选择使得下式最小的(j,s) m i n j , s [ m i n c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] min_j,s[min_c_1\\sum\\limits_x_i\\in R_1(j,s)(y_i-c_1)^2 + min_c_2\\sum\\limits_x_i\\in R_2(j,s)(y_i-c_2)^2 ] minj,s[minc1xi∈R1(j,s)∑(yi−c1)2+minc2xi∈R2(j,s)∑(yi−c2)2]
b. 按照(j,s)分裂特征空间: R 1 ( j , s ) = x ∣ x j ≤ s 和 R 2 ( j , s ) = x ∣ x j > s , c ^ m = 1 N m ∑ x ∈ R m ( j , s ) y i , m = 1 , 2 R_1(j,s) = \\x|x^j \\le s \\和R_2(j,s) = \\x|x^j > s \\,\\hatc_m = \\frac1N_m\\sum\\limits_x \\in R_m(j,s)y_i,\\;m=1,2