Apache NiFi 如何从入门到不放弃?
Posted DataFlow范式
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache NiFi 如何从入门到不放弃?相关的知识,希望对你有一定的参考价值。
既然来了,就留下呗。

笔者在之前的文章《物联网遇到流计算》中介绍过 Apache NiFi,虽比不上 StreamSets 华丽的外表,但是功能却很强大,在开源方面,NiFi 的企业级功能是接近完整的。
在本篇文章中,笔者会带大家进入 WiFi,No,是 NiFi 的世界。大家看完后,笔者不相信谁还会有放弃的念头(此处会不会有掌声!)。
本篇文章引用了 Manoj 小哥的部分 Slides,再次说明,表示感谢。
热身
在正式讲解 NiFi 之前,跟着笔者先来做做热身运动。
Data Flow/Data Pipeline/ETL
简单普及几个四是四,十是十的概念,走马观花即可,不必太在意。
1. Data Flow

Data Flow,数据流,有始有终才有意义,始于数据的源,终于可供使用和分析的结果数据。一句话,Data Flow 解决的是数据端到端传输的问题。
数据流中的数据可以来自很多种类型,比如 CSV、JSON、HTTP、IoT 和音视频流等等。
2. Data Pipeline

Data Pipeline,数据管道,又是什么呢?
大家可能对 ETL 非常熟悉了,其实 Data Pipeline 和 ETL 很相似,个人感觉 Data Pipeline 是包含 ETL 的,更加通用的方式,包含全局的系统之间数据的迁移,以及迁移过程中数据的转换处理。
现在国内外有不少公司在研发 Data Pipeline 产品,提供多渠道数据来源实时摄取、数据清洗、任务流管理、元数据管理、流批一体等功能。
3. ETL

ETL(Extract-Transform-Load),大家照着 Extract-Transform-Load 字面意思理解就可以了,即用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
为什么需要实现一个 Data Flow 框架?
是不是 Azkaba、Airflow、DolphinScheduler 等用多了,就忘记当初信誓旦旦的誓言了,好吧,或许不曾有过。
不管那么多了,我们反正就需要实现一个 Data Flow 框架,要解决的问题看似很简单,如下:
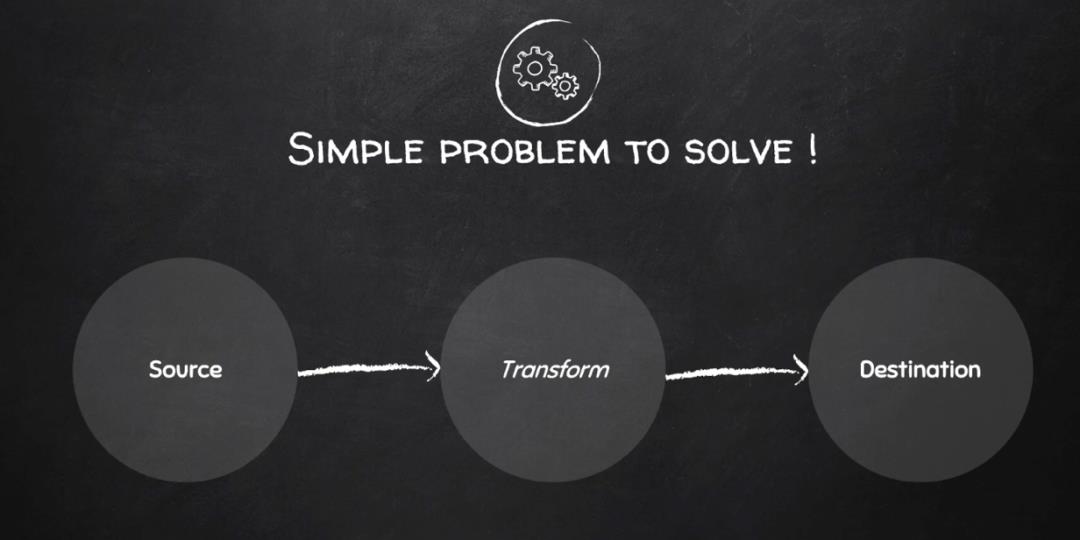
对,就这么简洁。但是要考虑大数据背景下的 N 个 V 问题:

这里笔者列了最初的大数据的 4V 特点,即 Volume(数据海量)、Velocity(高速,产生和分析)、Variety(数据多样性)、Veracity(真实,数据准确性)。
这个框架还要提供如下能力:

笔者的确是没有时间和能力去实现这个框架,幸好社区好多年前就已经实现 Data Flow 的框架,而且具备企业级的功能,接下来的时间就交给今天的主角 Apache NiFi。
何为 Apache NiFi
什么前世今生,笔者就省了,感兴趣的读者去深挖一下,但是不要掉坑里,请记住,我们是研究技术的,不是讲故事的。
官网一句话系列
An easy to use, powerful, and reliable system to process and distribute data.
意思就是,那么好用的数据处理和分发系统,它能(重读)不香嘛.
NiFi 构建的目标就是:

特性

Apache NiFi 的一些高级功能和目标包括:
1. Web-based user interface
Seamless experience between design, control, feedback, and monitoring
2. Highly configurable
2.1 Loss tolerant vs guaranteed delivery
2.2 Low latency vs high throughput
2.3 Dynamic prioritization
2.4 Flow can be modified at runtime
2.5 Back pressure
3. Data Provenance
Track dataflow from beginning to end
4. Designed for extension
4.1 Build your own processors and more
4.2 Enables rapid development and effective testing
5. Secure
5.1 SSL, SSH, HTTPS, encrypted content, etc...
5.2 Multi-tenant authorization and internal authorization/policy management
1. 基于 Web 的用户界面
设计、控制、反馈和监控之间的无缝体验
2. 高度可配置
2.1 容错与可靠投递
2.2 低延迟与高吞吐量
2.3 动态优先级
2.4 流可以在运行时修改
2.5 背压
3. 数据来源
从头到尾跟踪数据流
4. 专为扩展而设计
4.1 构建自己的处理器等
4.2 实现快速开发和有效测试
5. 安全
5.1 SSL、SSH、HTTPS、加密内容等...
5.2 多租户授权和内部授权/策略管理
官网说的很清楚了(笔者提供中英文),也很好理解,不作过多补充,大部分内容在本篇文章都有涉及。
生产环境部署的提示
作为企业级的成熟产品,身份认证和授权是必须的。
NiFi 提供了完善的身份验证(Authentication)和授权验证(Authorization)。由于大部分企业级大数据平台集成了 LDAP,所以 NiFi 需要和 LDAP 集成,方便用户登录和使用,以及管理员的统一管理和操作。
NiFi 要求开启用户验证功能,必须设置 HTTPS 安全连接,因此需要开启 TLS/SSL,官方提供 nifi-toolkit 工具。
nifi-toolkit 工具
为了便于 NiFi 的安全设置,官方提供 nifi-toolkit 工具,可以使用其中的 tls-toolkit.sh 命令行自动生成所需的 keystores、truststore 以及相关配置文件。
tls-toolkit.sh 提供了 Standalone 和 Client/Server 两种方式的操作。如下为 standalone 生成方式:
tls-toolkit.sh standalone -C 'CN=test, OU=NIFI' -n 'nifi-node1,nifi-node2,nifi-node3,nifiregistry-node' --keyPassword xxxxx --keyStorePassword xxxxx --trustStorePassword xxxxx
生成 NiFi 三个节点(nifi-node1、nifi-node2、nifi-node3)和 NiFi Registry 一个节点(nifiregistry-node)的证书信息:
# tree ca
ca
├── CN=test_OU=NIFI.p12
├── CN=test_OU=NIFI.password
├── nifi-cert.pem
├── nifi-key.key
├── nifi-node1
│ ├── keystore.jks
│ ├── nifi.properties
│ └── truststore.jks
├── nifi-node2
│ ├── keystore.jks
│ ├── nifi.properties
│ └── truststore.jks
├── nifi-node3
│ ├── keystore.jks
│ ├── nifi.properties
│ └── truststore.jks
└── nifiregistry-node
├── keystore.jks
├── nifi.properties
└── truststore.jks
另外对于 LDAP 配置来说,如果使用安全的 LDAPS 方式,则 LDAP Authentication Strategy 配置为 LDAPS,如果只是普通的 LDAP,则 Authentication Strategy 配置为 SIMPLE。
用户认证和授权
NiFi 页面的右上角,提供了 Users 和 Policies 功能,用来对用户/组以及权限的管理。

身份验证(Authentication)
在 NiFi 部署配置时,选择 LDAP 中的一个用户作为 Admin 管理员即可。
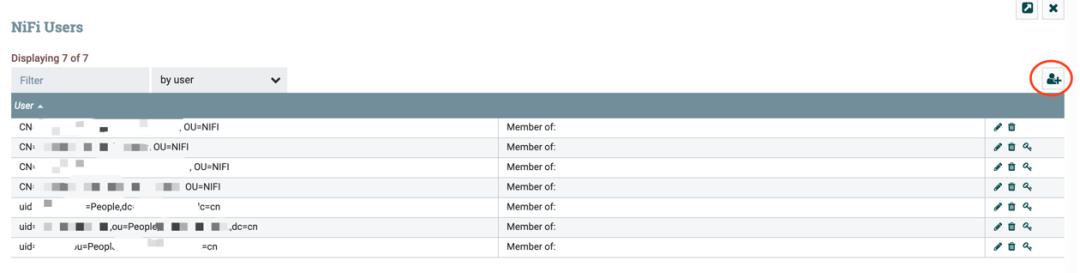
打开 Users 管理台,管理员可以添加用户/组。
授权验证(Authorization)
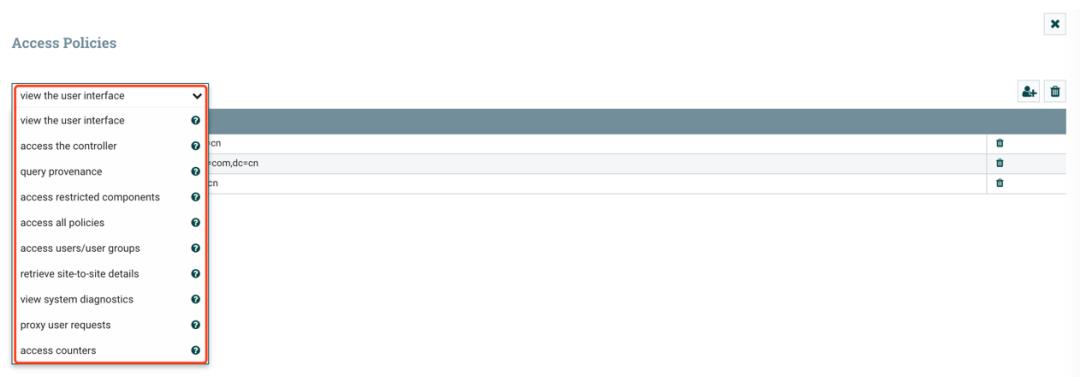
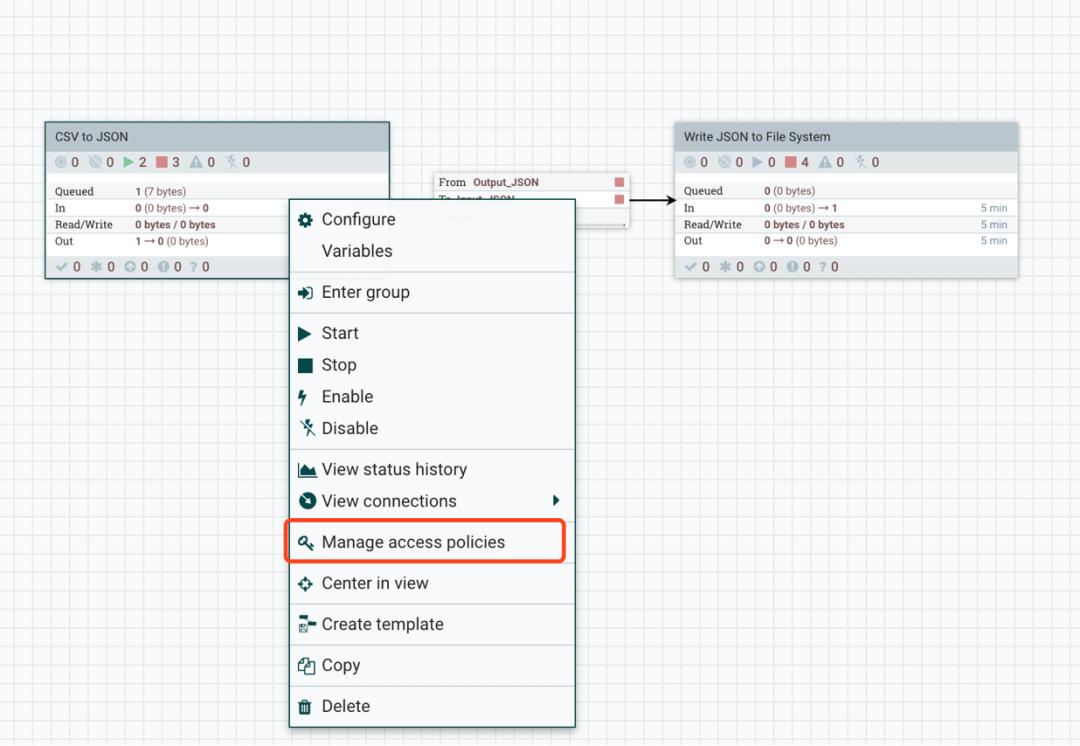
打开 Policies 管理台,可以给上面添加的用户和组授予权限。NiFi 提供的权限控制非常细粒度,其实除了这里设置外,在开发数据流时,针对每个 Processor、Processor Group 和 Controller Service 等都可以设置权限。
NiFi 核心概念
NiFi 提供的概念很多,这里简单罗列几个,不会深入说明。在后面的具体实战环节中,笔者会举例说明,这样大家会更容易理解和应用。
FBP

在计算机编程中,基于流的编程(FBP,flow-based programming)是一种编程范例,将应用程序定义为黑盒子(black box)进程的网络,这些进程通过消息传递在预定义的连接之间交换数据,其中连接是在进程外部指定的。这些黑盒子进程可以无限地重新连接以形成不同的应用程序,而无需在内部进行更改。因此,FBP 是面向组件的。
- 摘自 Wikipedia《Flow-based programming》。
NiFi 的基本设计概念与基于流程的编程(FBP)的主要思想紧密相关。以下是 NiFi 一些主要的概念以及它们是如何映射到 FBP 的:
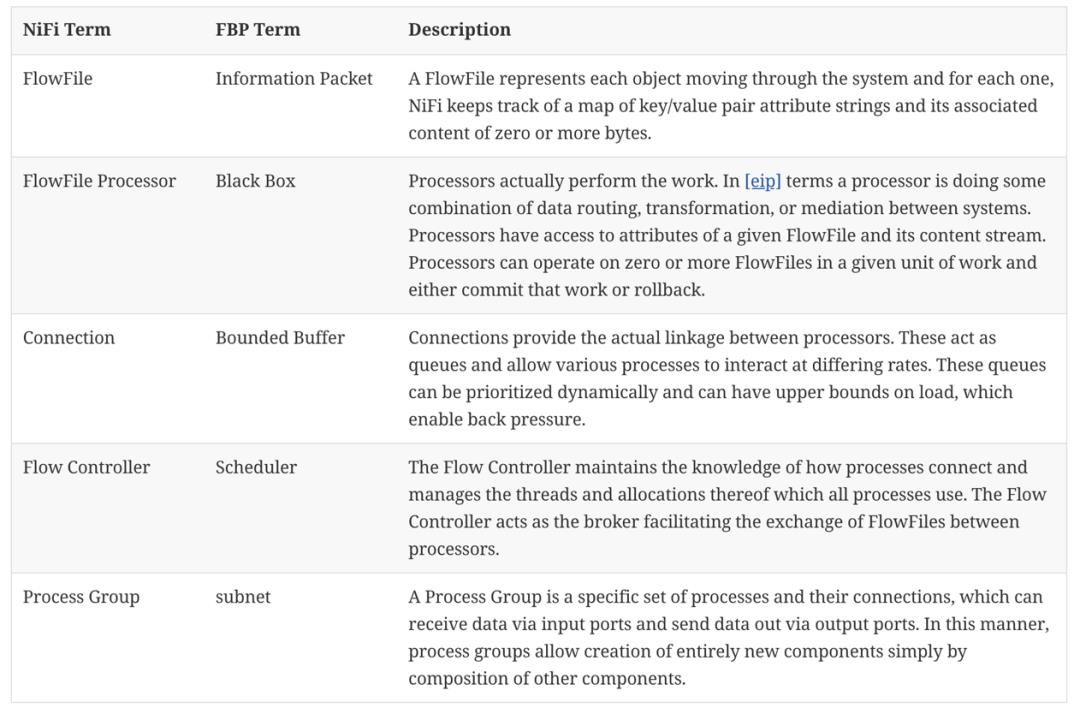
上面图表中的概念后面会详细介绍。
DataFlow Manager
DFM(数据流管理器)是一个 NiFi 用户具有添加、删除和修改 NiFi 数据流组件的权限。
Funnel
Funnel(字面意思为漏斗,功能真的很像漏斗)是一个 NiFi 组件,用于将来自多个连接的数据合并到单个连接中。
Tempalte
通常,一个数据流由许多可重用的子流组成。NiFi 允许 DFMs 选择数据流的一部分或整个数据流并创建模板,为该模板设置一个名称,然后可以像其他组件一样拖放到画布上。因此,可以将多个组件组合在一起,形成一个更大的构建块,从而创建一个数据流。这些模板也可以作为 XML 导出并导入到另一个 NiFi 实例中,从而允许共享这些构建块,当然用户也可以从 NiFi wiki 上下载 Tempalte(https://cwiki.apache.org/confluence/display/NIFI/Example+Dataflow+Templates)。
NiFi 如何工作

接下来,介绍 FBP 图表中提及的术语。
Processor

Processor 是用于监听传入数据的 NiFi 组件、从外部获取数据、对外发布数据,以及从 FlowFiles 中路由、转换或提取信息。
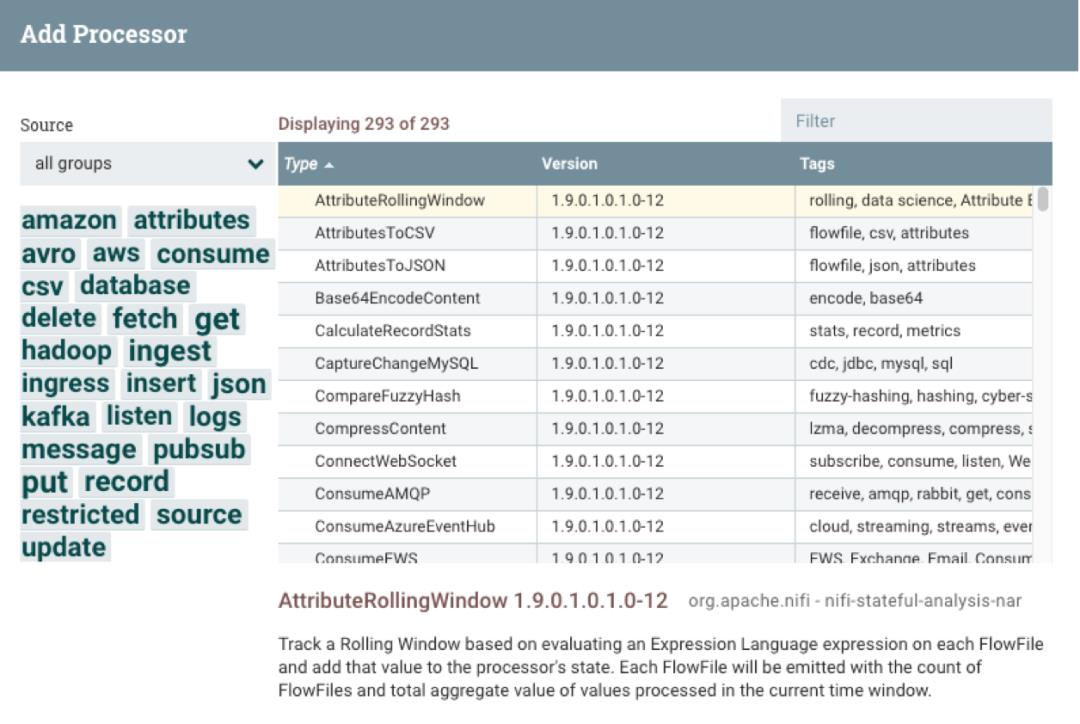
从下图中可以看到 Processor 包含的类型很多,多达 293 个,比如传统数据库、大数据组件、日志文件、消息流、aws 云服务的产品(DynamoDB、Lambda、S3 等)等:
FlowFile
FlowFile 表示 NiFi 中的单个数据块。
1. FlowFile 组成
一个 FlowFile 由两个组件组成:
FlowFile Content
Content 是 FlowFile 真实的数据,比如通过 GetFile、GetHTTP 等方式获取文件的实际内容。FlowFile Attributes
FlowFile 的元数据信息,包含 Content 的信息有:
FlowFile 什么时候创建、FlowFile 名字、FlowFile 来自哪里、FlowFile 表示什么等。
2. 针对 FlowFile 进行的操作
Processor 可以添加、更新或删除 FlowFile attributes
修改 FlowFile content
3. FlowFile 生命周期

Connection

DFM 通过将组件从 NiFi 工具栏(NiFi 左上角)的组件部分拖动到画布上,然后通过 Connection 将组件连接在一起,从而创建一个自动化的数据流。每个 Connection 都包含一个 FlowFile Queue。
简单理解就是:
Connection 是指 Processor 或 Process Group 之间的连接。
每个 Connection 都包含 FlowFile 的一个 Queue,用于缓存传输的流数据,并可设置 Back Pressure。
Process Group

当一个数据流变得复杂时,最好在更高更抽象的层次上对数据流进行设计和管理。NiFi 允许将多个组件(例如 Processors)组合到一个 Process Group 中。NiFi 用户可以轻松地将多个 Process Group 连接在一起形成逻辑数据流,并允许 DFM 进入 Process Group 以查看和操作处理组中的组件。
也就说,针对一个复杂的业务处理数据流,建议最好使用逻辑的 Process Group 来组织这个复杂的 processes,方便维护这些数据流。另外 Process Group 还有 Input/Ouput Port,可以用来在它们之间移动数据。
Controller Service

Controller Service 用来被 processes 使用。比如一个 process 需要写入或读取数据库的数据,需要使用一个 Controller Service 用来建立数据库的连接信息。
笔者在测试环境中创建了一些 Controller Service,包括 HBase 连接、Kerberos 配置:

截止目前,NiFi 提供了 65+ 种 Controller Service。另外在权限控制方面,可以对每个 Controller Service 进行授权操作。
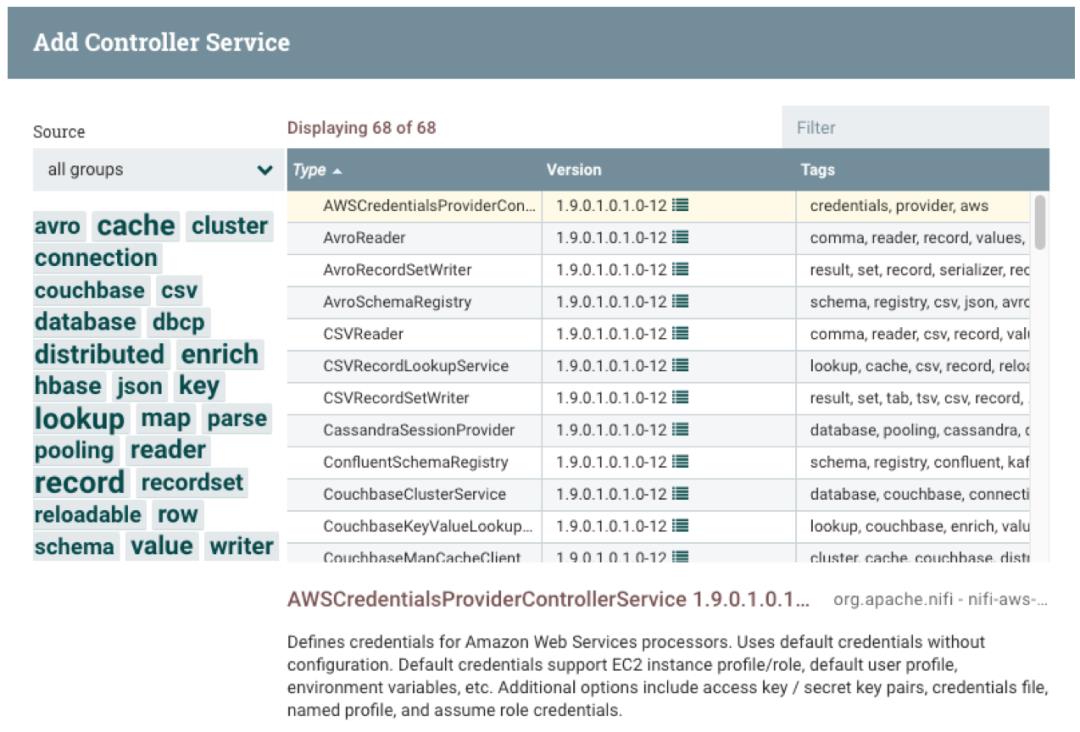
Processors 包罗万象

既然要进行数据流开发,那么用户就要大概了解 NiFi 里面的 Processors 有哪些类型。下面,笔者和大家一起整理归纳一下。
数据摄取 Processors

数据转换 Processors

数据流出/发送数据 Processors

路由和中转 Processors

数据库访问 Processors

Attribute 抽取 Processors

系统交互 Processors

切分和聚合 Processors

HTTP 和 UDP Processors

Amazon Web Services Processors

Connection Queue & Back Pressure 实验

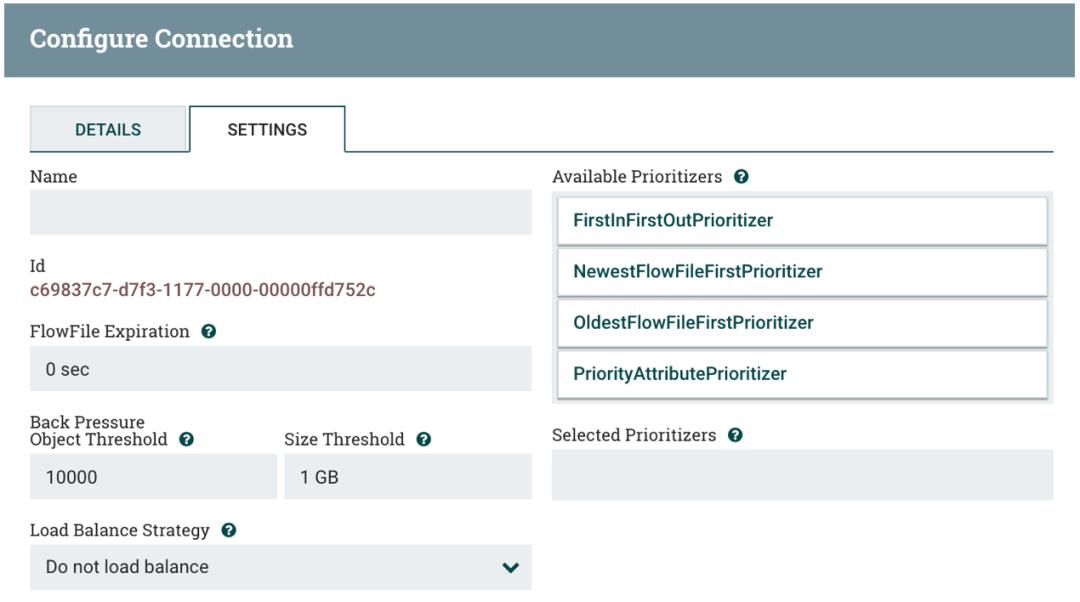
笔者使用 GenerateFlowFile 进行测试,默认 Processors 会在 NiFi 集群所有节点执行,可以对 Processors 执行节点进行设置(这里保持默认值):
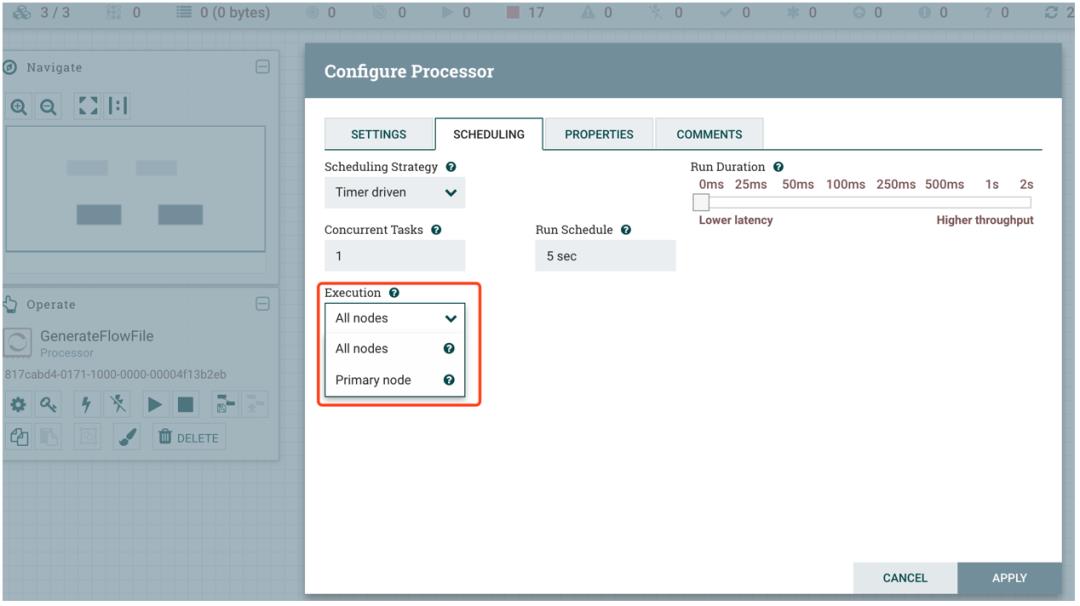
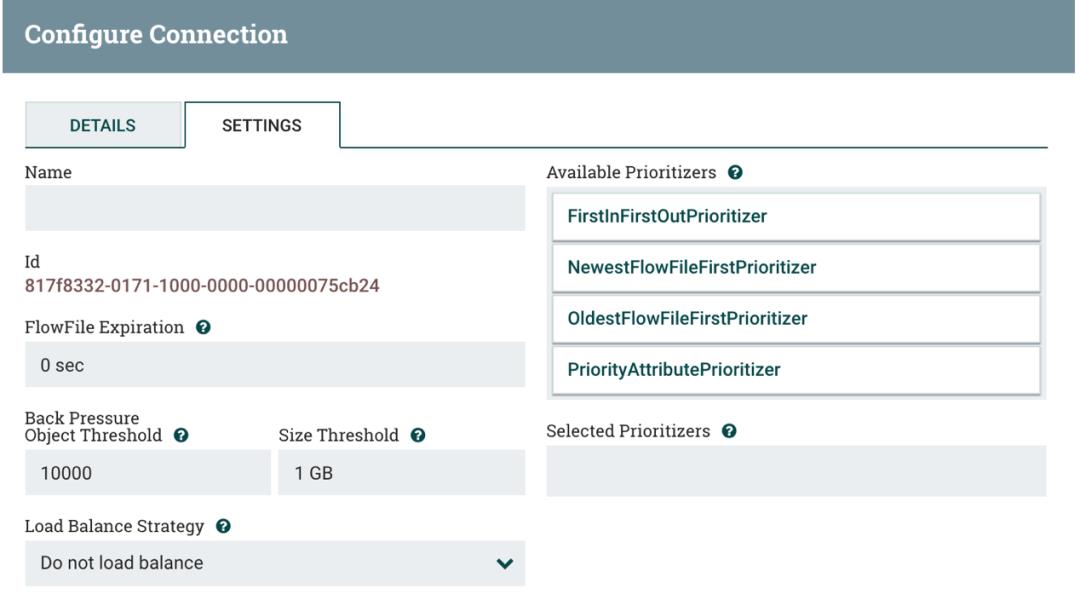
当笔者在 GenerateFlowFile Processor 上点击 Start 后,可以清楚地看到 Queued 达到 30000 时就停止。打开 Connection Details 查看,可以看到 Back Pressure Object Threshold 默认为 10000,Size Threshold 大小为 1 GB,因为笔者的 NiFi 集群有三个节点,就乘以 3 倍即可。
另外 Back Pressure 也可以根据数据量的大小,默认为 1 GB:
Attributes & Content 实验
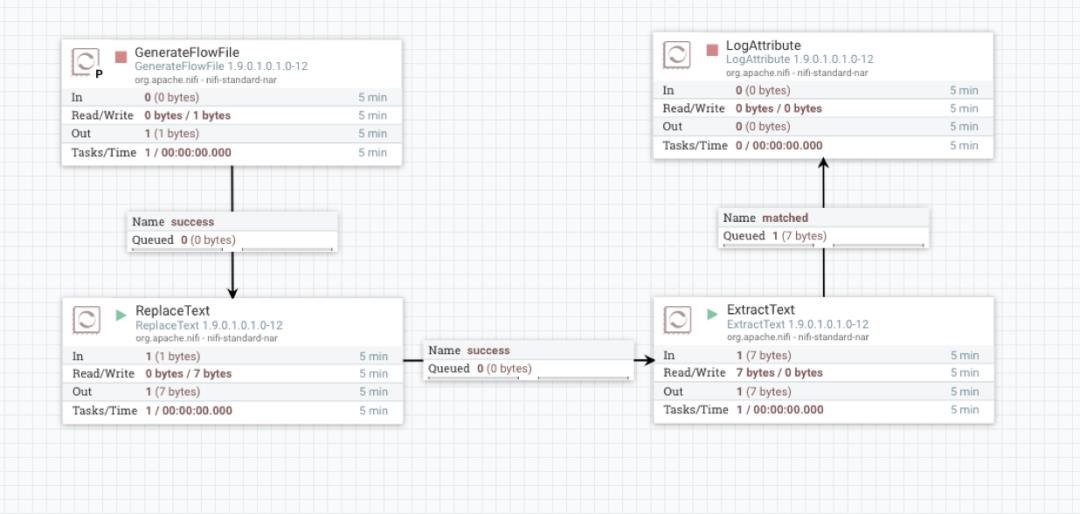
笔者将这个数据流功能描述一下:
GenerateFlowFile 在 NiFi Primary 节点运行,每隔 5s 生成一个文件,大小为 1B
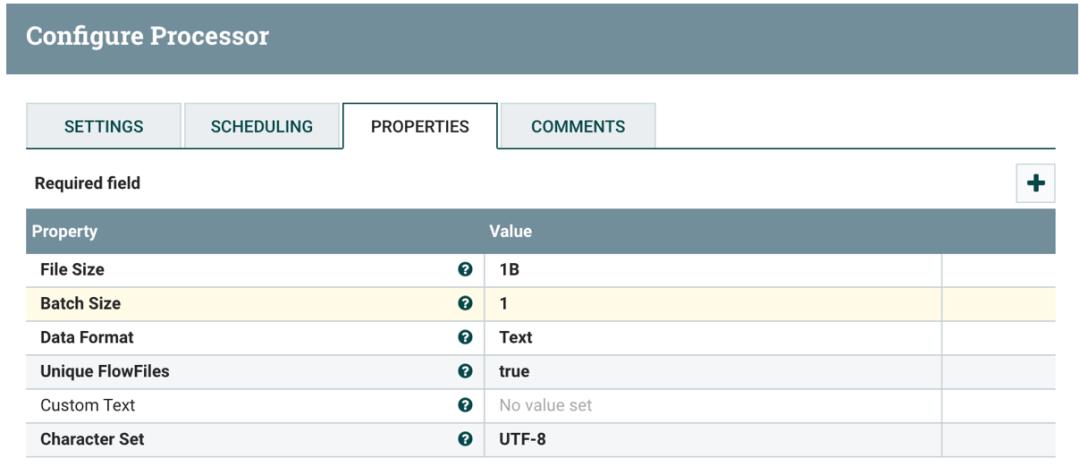
ReplaceText 将 GenerateFlowFile 产生的每个 1B 大小的数据流替换为 A,B,C,D
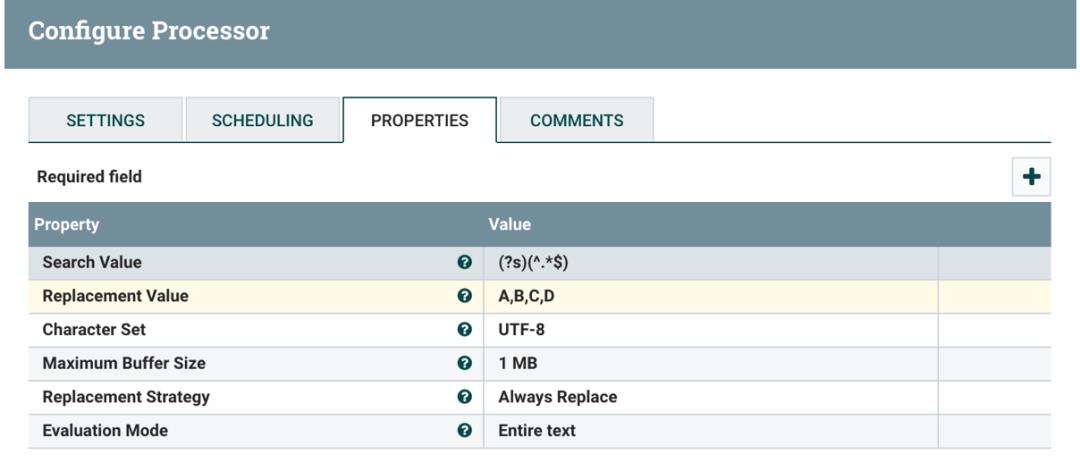
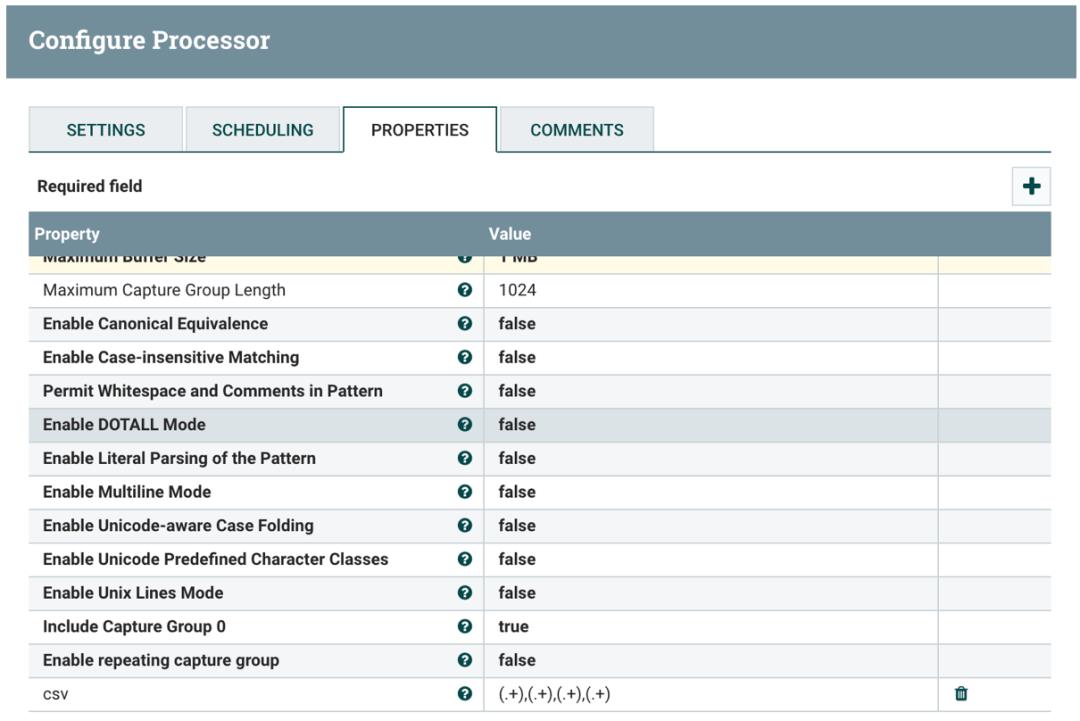
ExtractText 将 ReplaceText 转换的数据流解析为 CSV 格式,以逗号分隔
笔者执行该数据流后,每隔 5s 获取的最后数据流的属性为:
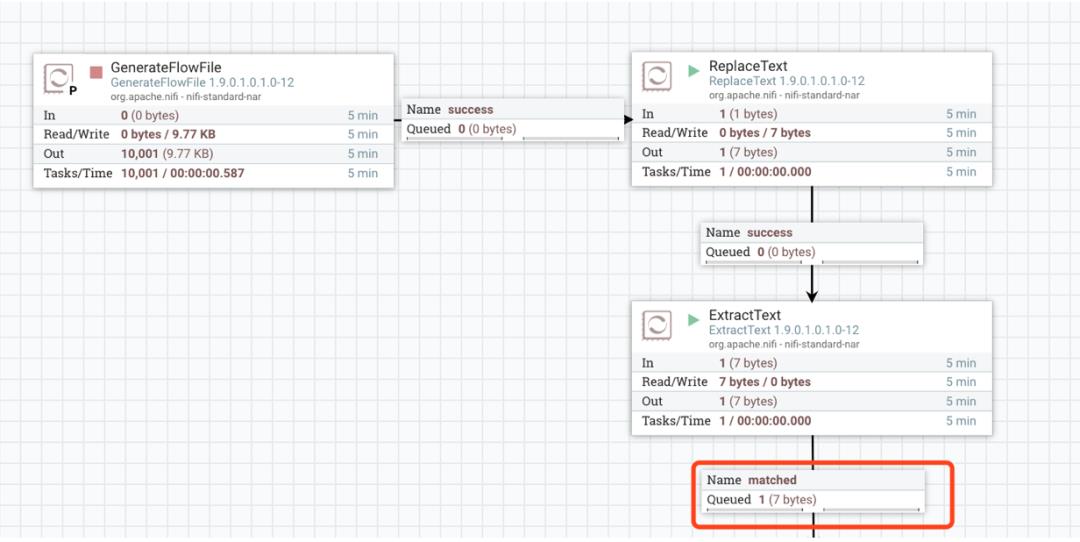

为了便于查看数据流中数据值的变化,可以执行第一个 Processor 生成一条数据后,停止该 Processor 执行,然后依次执行后续的 Processor。
Expression Language 实验

接着上面的数据流,笔者继续添加一个 ReplaceText:
ReplaceText 将 ExtractText 转换的 CSV 格式替换为 JSON 格式
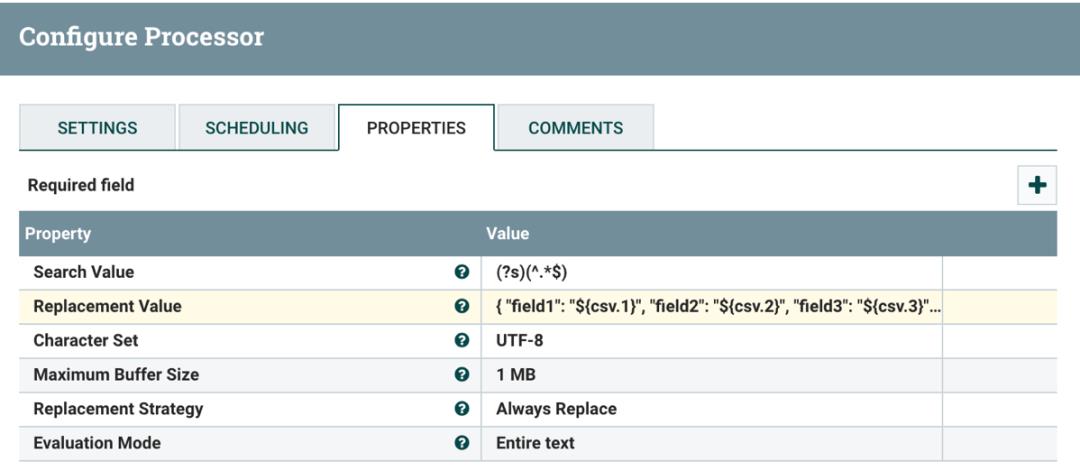
其中配置 ReplaceText Replacement Value 值为: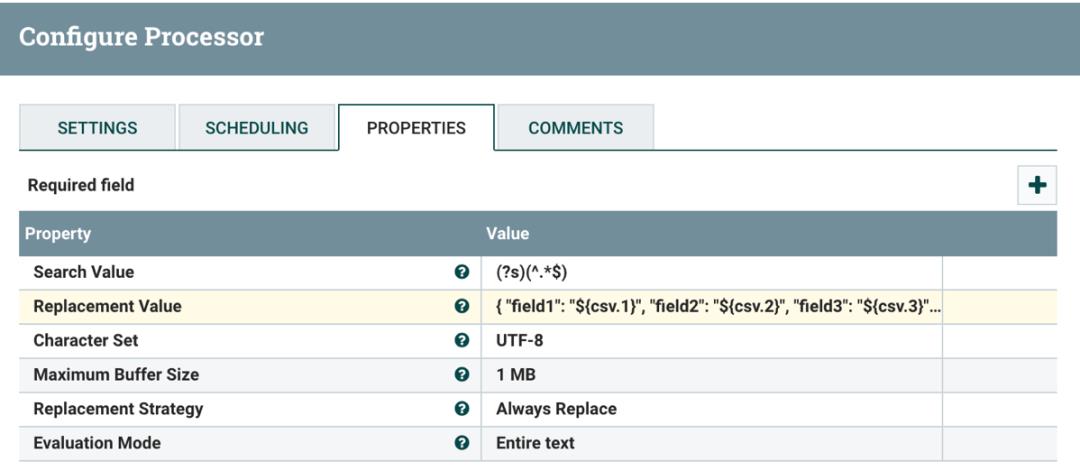
"field1": "$csv.1",
"field2": "$csv.2",
"field3": "$csv.3",
"field4": "$csv.4"
笔者执行该数据流后,每隔 5s 获取的最后数据流值为:
"field1": "A",
"field2": "B",
"field3": "C",
"field4": "D"
补充实验
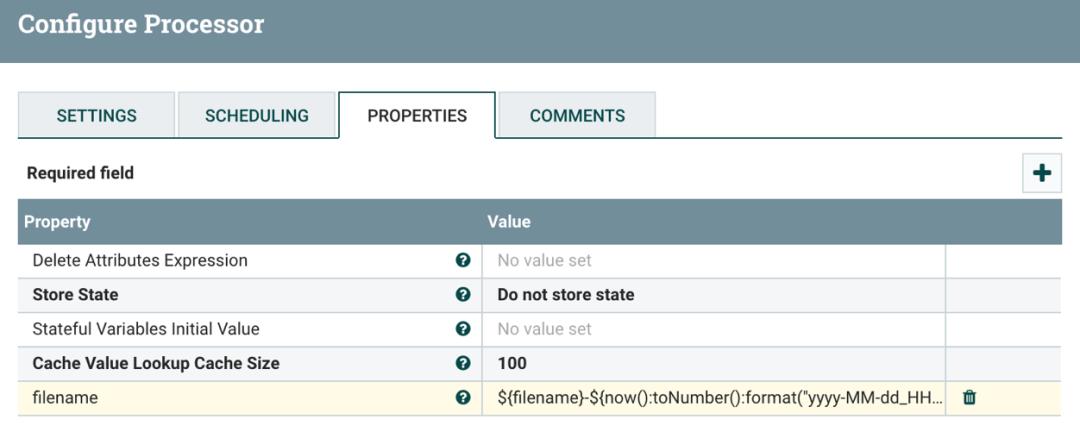
笔者继续添加更多的 Processor 进行数据流转换处理:
UpdateAttribute 修改 filename 的格式,配置 filename 属性值为:
$filename-$now():toNumber():format("yyyy-MM-dd_HHmmss").json
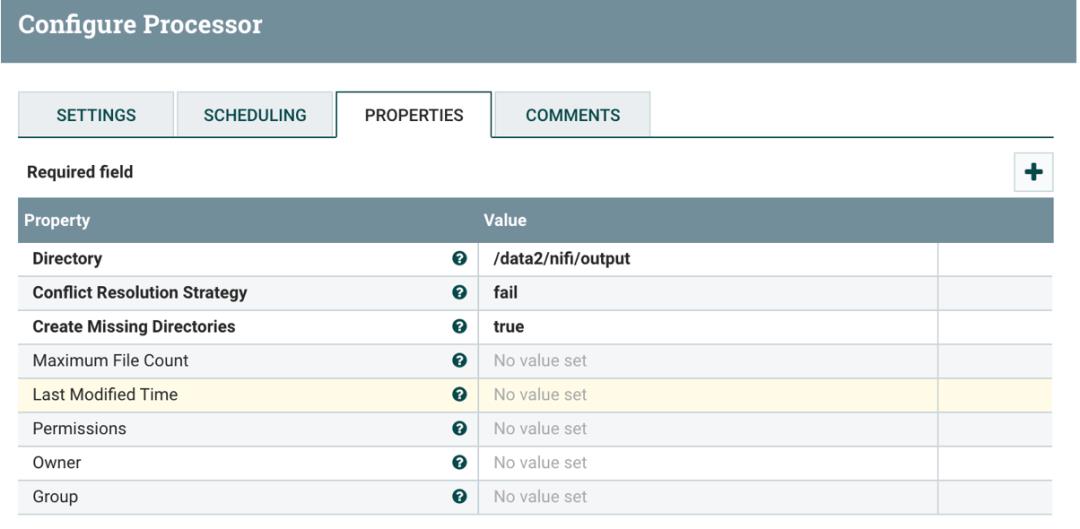
PutFile 将 UpdateAttribute 修改后的文件写入指定的目录
Process Group 实验
在 NiFi 中可以创建 Process Group,比如笔者创建名为 CSV to JSON 的 Process Group:
然后将上面的设计数据流归类到这个 Process Group 中(深深地按住 Shift,然后温柔地使用鼠标框选数据流,并拖到 Process Group 中):
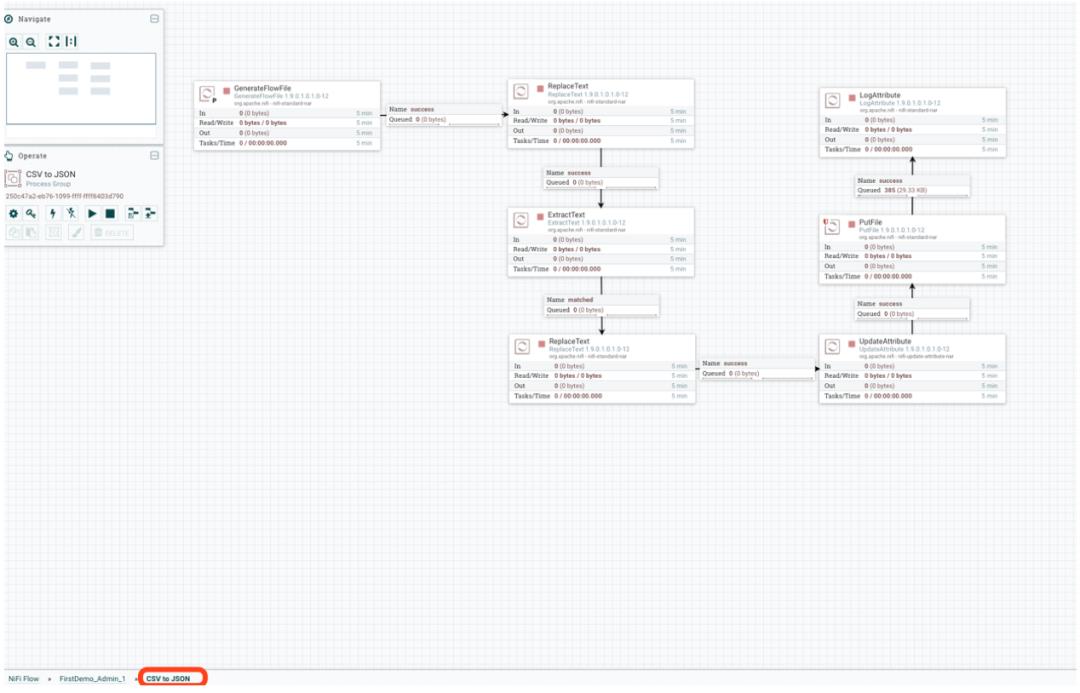
上图中的左下角可以看到对应的 Process Group。
Input Port & Output Port 实验
下面我们来看一下 Input Port & Output Port。
首先在 Process Group 名为 CSV to JSON 中继续创建一个 Process Group,名称为 Write JSON to File System,然后将数据流中的一部分拖入到该 Process Group 中,如下:
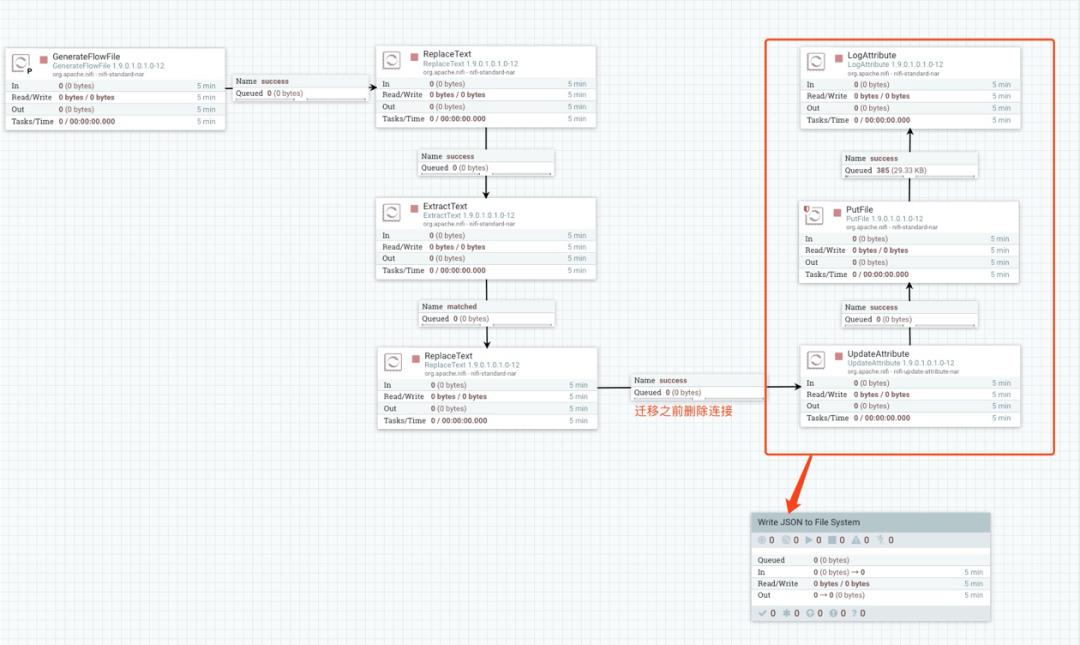
迁移之前,要将拖动的数据流断开与其他 Processor 的连接。
迁移完成后,进入 Write JSON to File System 进程组中:
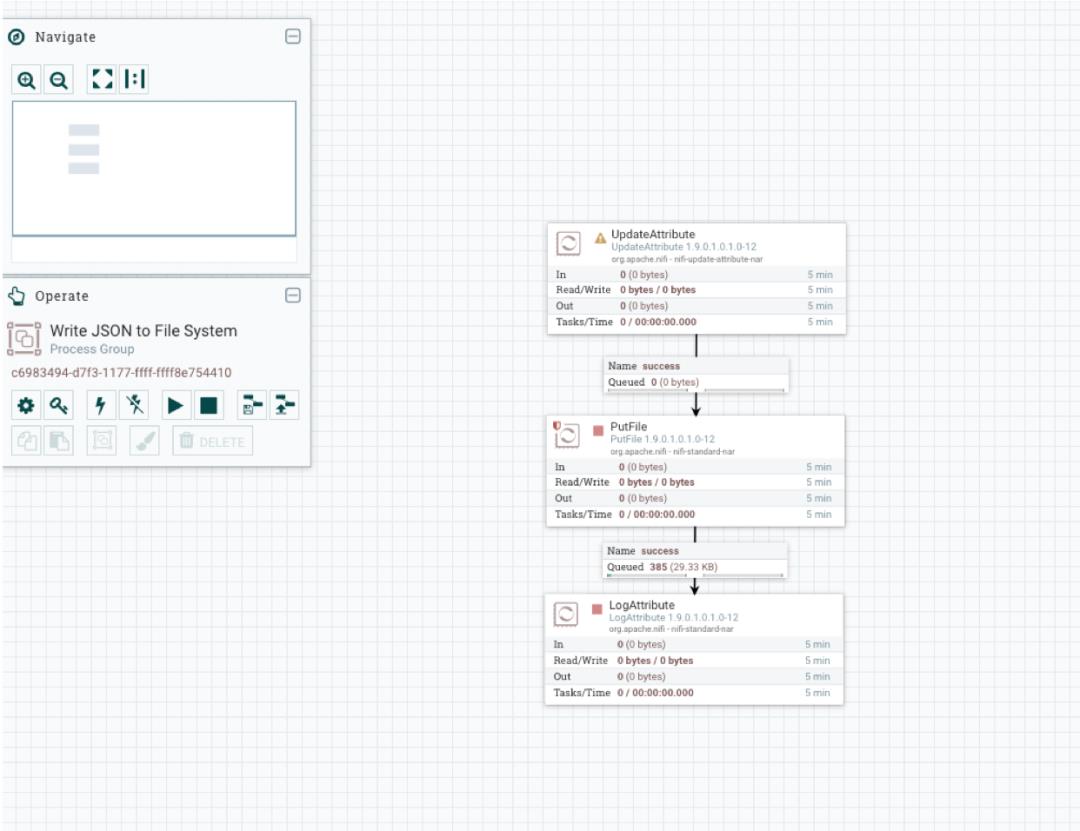
接着将 Write JSON to File System 移动到上一层级,和 CSV to JSON 处理同一级:


到此,我们拥有了两个 Process Group,接下来笔者需要将它们连接起来,这里就会涉及到使用 Input Port 和 Output Port。
我们在 CSV to JSON 中添加 Output Port,名称为 Output_JSON:
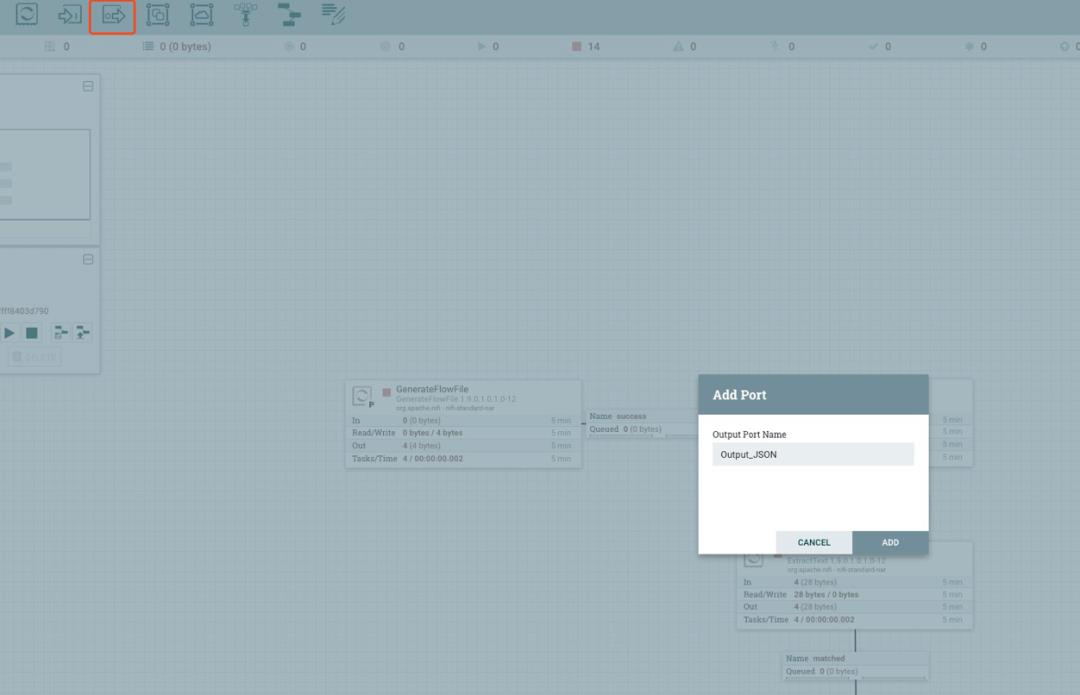
然后将数据流连接到 Output_JSON:

接着继续在 Write JSON to File System 中添加 Input Port,名称为 Input_JSON,并连接到数据流,作为数据源:
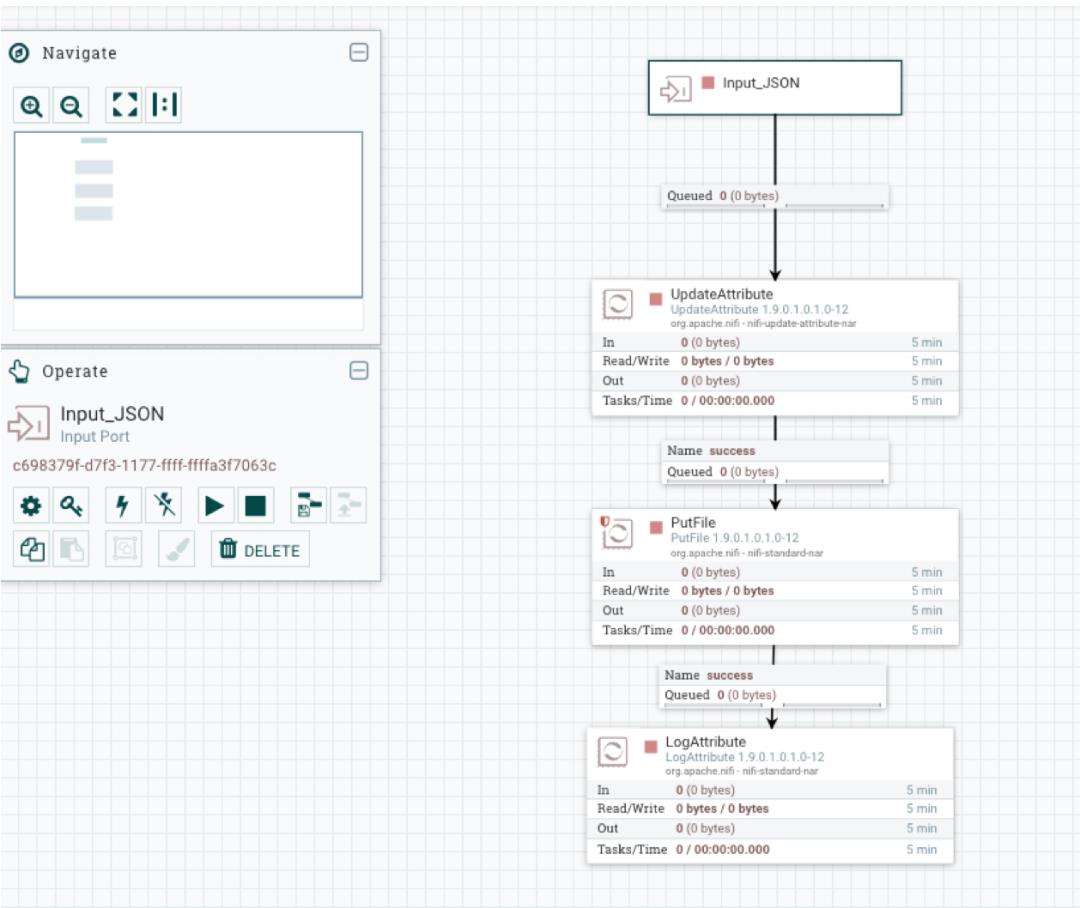
Input Port 和 Output Port 添加完成后,我们将两个 Process Group 连接起来,注意要选择好 Input 和 Output Port 的名称:
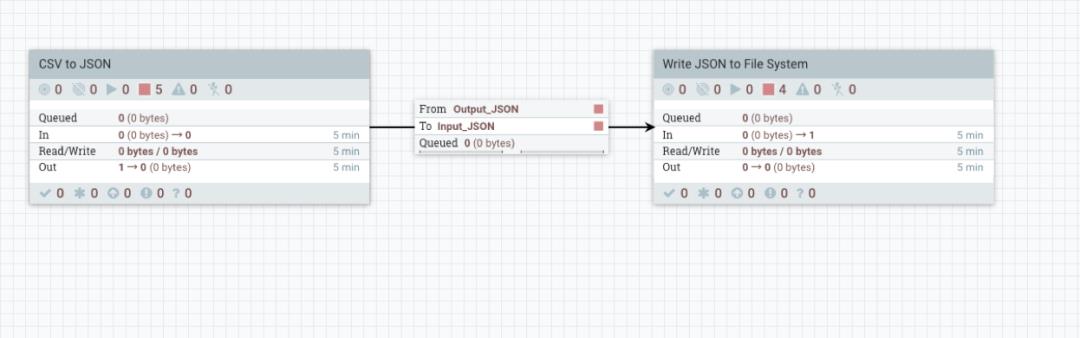
然后执行两个 Process Group(CSV to JSON 和 Write JSON to File System),验证一下结果:
# pwd
/data2/nifi/output
# ll
total 16
-rw-r--r-- 1 nifi nifi 78 Apr 16 17:29 2e74b68d-ddc2-4ce7-8b8c-3e217ecc45fd-2020-04-16_172929.json
-rw-r--r-- 1 nifi nifi 78 Apr 16 17:29 63909e35-3725-4d8b-b12d-58fa8182be65-2020-04-16_172939.json
-rw-r--r-- 1 nifi nifi 78 Apr 16 17:29 6bc134d6-d3d0-43d8-bfd6-034d071532b6-2020-04-16_172944.json
-rw-r--r-- 1 nifi nifi 78 Apr 16 17:29 9df9052f-c7ea-417c-bd62-5129ed7c0804-2020-04-16_172934.json
# cat 2e74b68d-ddc2-4ce7-8b8c-3e217ecc45fd-2020-04-16_172929.json
"field1": "A",
"field2": "B",
"field3": "C",
"field4": "D"
每隔 5s 生成 1 个文件。
Templates 实验

这些问题可以通过 NiFi Template 来解决。
比如,我们根据 CSV to JSON 这个 Process Group 中的某些数据流创建一个模版:
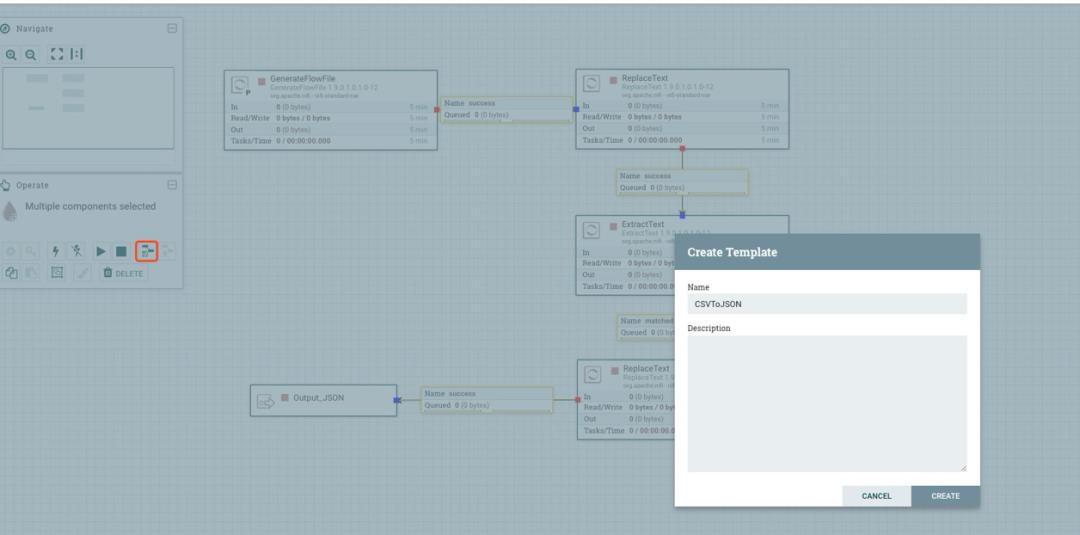
也可以根据 Process Group 来创建:

当然 NiFi 也提供了很多模版:
https://cwiki.apache.org/confluence/display/NIFI/Example+Dataflow+Templates
比如使用 Retry_Count_Loop.xml,只需要下载
https://cwiki.apache.org/confluence/download/attachments/57904847/Retry_Count_Loop.xml?version=1&modificationDate=1433271239000&api=v2&download=true
并导入 NiFi 中即可:

大家可以在 NiFi 右上角查看 Templates 信息:

版本控制

NiFi 数据流的开发往往会涉及到一个团队协同开发,这时就需要进行版本控制。为了解决版本控制的问题,NiFi 使用子项目 NiFi Registry 来实现该功能,这一块后续单独讲解。
NiFi Registry
根据下面的几页 slides,大家能够对 Registry 有一个初步的了解。




Funnel 实验
Funnel 的功能其实很简单,如其名字一样,将来自多个连接的数据流合并到单个连接。
首先看一个问题:
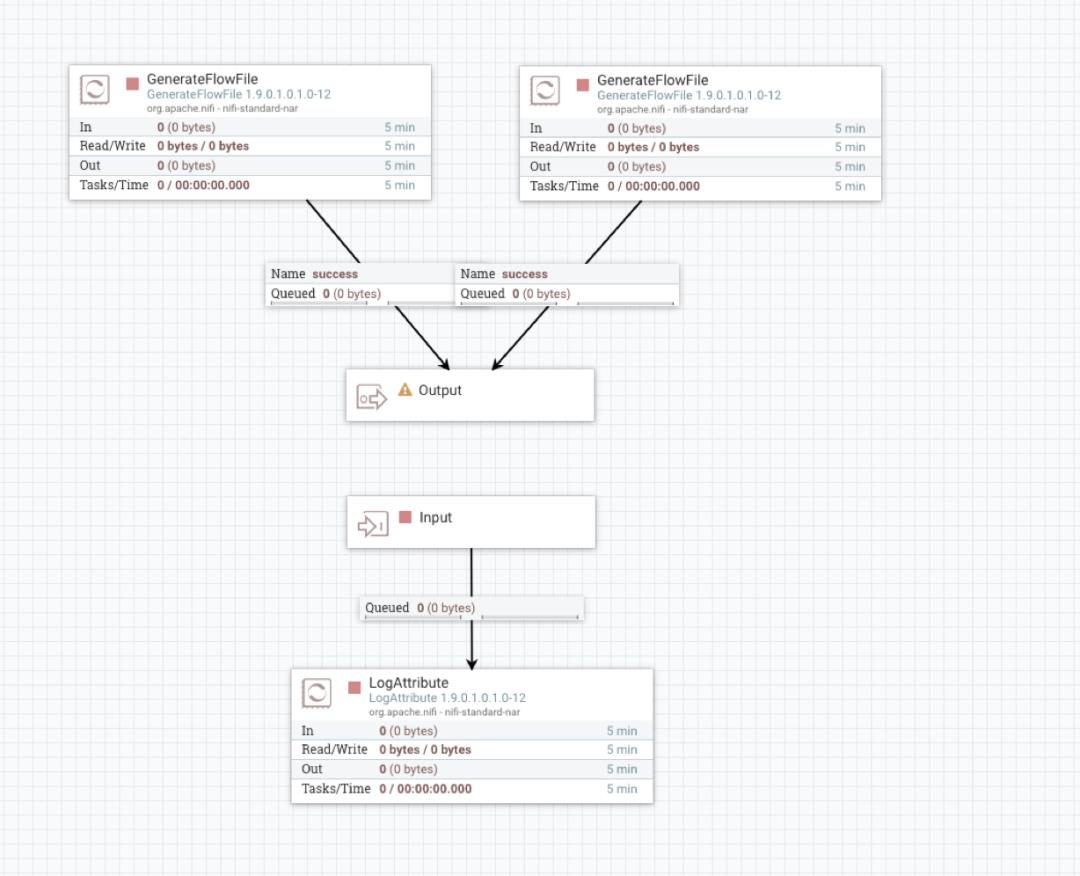
这里 Output 和 Input Port 脱离 Process Group 后是无法连接,不过我们可以使用 Funnel 功能来解决:
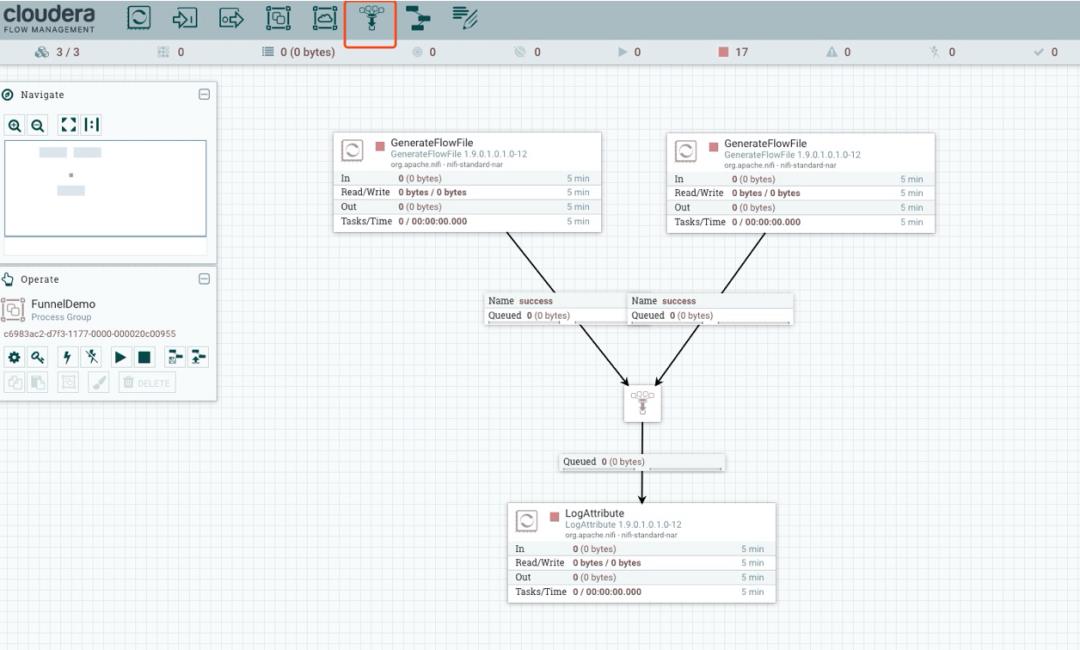
来源的数据流可以有很多个,最后通过 Funnel 汇聚为一个数据流。
NiFi 监控
NiFi 通过 Bulletin Board 提供了非常完善的监控,这一块同样会单独讲解,包括数据流查看和调试等。
决定数据流效率的关键因素

NiFi 集群是可以线性扩展,单个 NiFi 集群每天可以处理数万亿个事件和 PB 级数据,并具有完整的数据来源和血缘。
总结
在本篇文章中,笔者基本上讲解了 NiFi 的所有内容,虽然有的方面只是提及,并未深入说明,但是读者至少明白该如何去研究和实践。
关于 NiFi 的更多内容,等着,我还会再回来的。
你若喜欢,点个在看哦

以上是关于Apache NiFi 如何从入门到不放弃?的主要内容,如果未能解决你的问题,请参考以下文章