FLINK 基于1.15.2的Java开发-使用AggregateFunction解决以天为单位诸如PVUV等统计的实时计算
Posted TGITCIC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FLINK 基于1.15.2的Java开发-使用AggregateFunction解决以天为单位诸如PVUV等统计的实时计算相关的知识,希望对你有一定的参考价值。
什么样的业务场景适合AggregateFunction

对于这一类的:
统计的数据的窗口为一天内(24小时),然后每X秒刷新一下相关数据的实时变化,每次变化的值是在之前的值上有一个累计,然后每天归0后,重新计算当天的数据。
诸如此类的需求还有:每天的UV、PV。
凡是这一类的业务场景、需求,全部适合使用Flink的AggregateFunction和ReduceFunction。我们今天就精细化的讲一下AggregateFunction的使用。这块是最常用的。
从需求出发如何设计这个架构
很多人一看,哦。。。是当天的数据。互联网应用里当天的数据就是千万级的,那么你要累计,那么我每5秒跑一个批吧,前端用VUE JS或者是小程序、APP做一个轮循就完了。
那好吧,你可以去试试看,我不阻止你,然后系统死了也别再来哭。
因为很多人在考虑问题时要么没有考虑数据量要么考虑了数据量没有考虑另一个重要的点:那就是并发。
我们来看真实的生产环境:2,000个并发,在基于1,000万的数据集上,每五秒做一次按照不同列维度的聚合、去重,再变成API返回出去,这个系统不白屏才怪。
所以,它不是一个跑批可以解决这么简单了。虽然我们用跑批是可以解决的,可是我们逃不过最大的一个梗那就是:2,000个并发,在基于1,000万的数据集上,每X秒要刷新一下。
即:要把这个数据量计算进去、又是相对复杂的聚合计算、又要在X秒-一般5秒一刷新已经算是久了通常都是在1秒或者2秒内一刷新。这时就需要使用实时计算了。
实时计算和跑批计算不仅仅在技术上的不一样,更主要的是区别在“设计思维上的不一样”。实时计算的技术框架我们用的是FLINK,但如果你的设计思路还是跑批的那你设计和做出来一样做出来还是一个传统跑批依旧逃不过上述的这个“梗”。
用实时计算的思路去设计这个需求
实时计算设计有一个口决,此处我用我近8年的实时计算和AI方面的经验总结了出来这“十六字阴阳风水秘术“,那就是:打散IO、化整为零、各个击破、预先准备。
- 打散IO,我们假设参与计算的数据集是1,000万。每5秒一刷新,这5秒内会增加100条订单,传统做法是:第一个5秒数据的基底:1000万零100条,按照各个类别做一次聚合。实时计算做法:我只取这5秒内的数据,把这100条按照订单类别去做统计;
- 化整为零,看似数据基底为1000万,按照类别聚合实际我们看它的输出为5个类,即只有5条数据。我们不应该纠结于这1000万,而要纠结于这个5;
- 各个击破,从上到下的顺序到此步我们这个设计就变成了:第一步:如何先把这个数据的底折成5类,然后根据每一个类统计出一个总数,共5条数据。第二步:如何取得5秒内的进入订单并且按照5个类别再统计出5条数据;第三步:把新进数据+上前面的数据;第四步:循环之前第一步到第三步。这样就可以解决我们的设计了;
- 预先准备,其实这四个字的解释还是需要牵涉上“多少量数据的底基”来谈的。我们说需求:每5秒一刷新刷的是什么内容?刷的是累计的值。每5秒内的数据我们可以通过FLINK的算子轻易得到,关键在于在这个第一个5秒到来前那个数据哪里来呢?预计算。实时计算里有一个很重要的设计思想叫“预计算/预处理”,这个预处理预计算是一个”一次性“的动作。那么对于一次性动作要满足还不简单。此时才有跑批。我们在上线时假设是晚上22:00,那么当天的0点到22:00会已经有一个”当天1000万条订单“,1000万条订单按照类别分成5类,洗出每一类的订单状态,这不过就是一个XXLJOB或者是mysql的store procedure可以解决的问题而己。然后把这个一次性跑批的数据按照后面Flink实时洗出来的数据两相里做不断累加,那么这个问题就变成了一个:2000个并发,每5秒从Redis里取出oldValue+newValue的一个问题了,这种反映在生产环境基本在1-2秒即完成了,还不会开销过多内存和CPU。因此就完全可以满足我们对于这种场景的设计了;
下面我们基于一个已经存在生产环境来给出架构设计。因为如果一切都是新的推倒式设计这太乌托邦。我们工作中实际应用99%场景都是在己有环境上对它进行“大补丸”的。
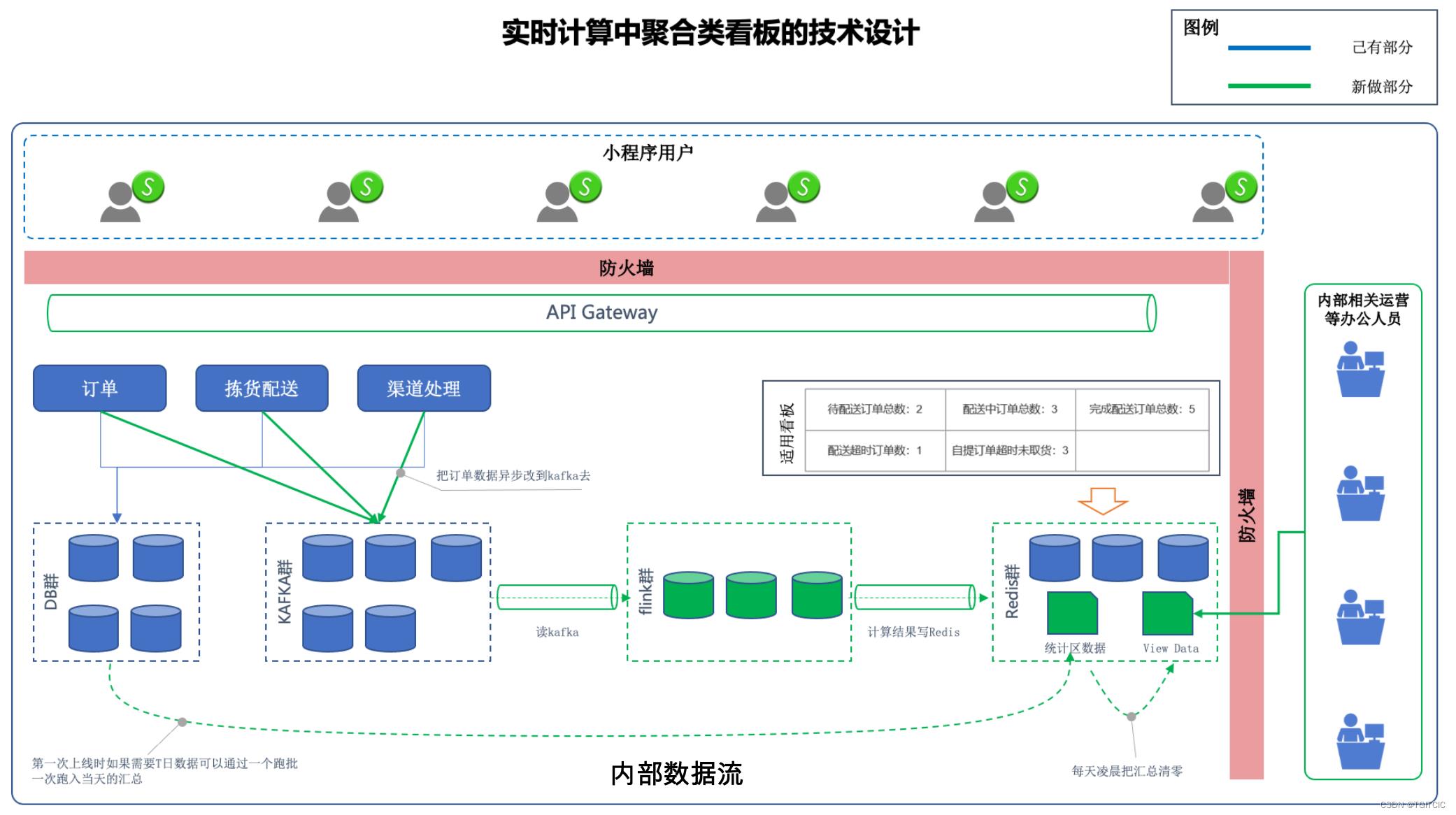
Flink的AggregateFunction
根据上述的设计,我们知道实时计算时会有一个oldValue+newValue的过程。因此这种就属于标准的AggregateFunction应用场景。
我们假设以下是一个“订单类别”、“订单量”的数据结构存在在Redis里。
- 我们先用一个传统跑批在上线前一次性把近一天(因为我们不要历史,只需要一天)的数据预先跑出来塞到redis里(如果你在上线时要求就从上完线后的第二天开始计算,那么你甚至可以省略掉预处理这一步直接从0开始计算)。
- 然后我们每次在Flink的滑动窗口(5秒一次)进行当前窗口内的数据按照订单类别汇总后每次把它加入这个redis的数据结构中去,就完成了这个需求了。
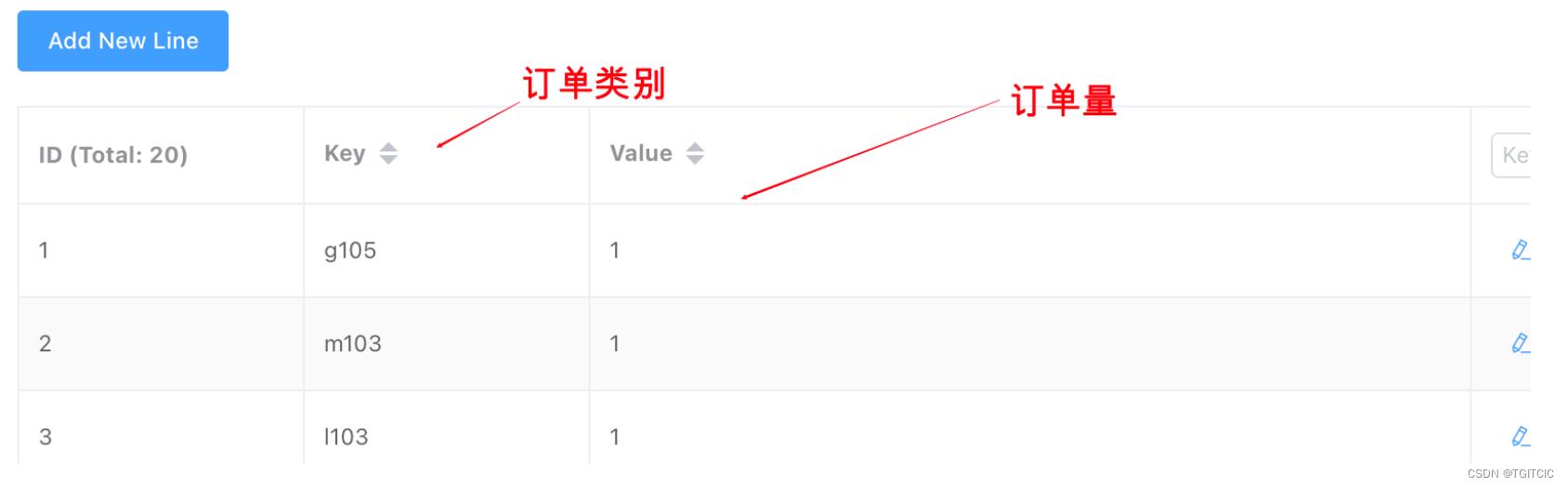
此处会有一个小技巧。
Flink的AggregateFunction是会实时只统计当前窗口内数据的汇总。之前一个窗口的数据它会“丢失”,为了实现累加,我们再设计一个Redis内的数据结构用予保存每一次实时计算窗口的中间值,以此为完成“累加”的动作。

所以我们在代码上做这样的设计:
- 累加发生在“临时结果集”;
- 累加后根据窗口刷新把这个最终结果sink到用于前端取数显示/展示用的view data里;
我们下面来看AggregateFunction的核心代码
KafkaSource<OrderBean> source = KafkaSource.<OrderBean>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new OrderBeanJSONDeSerializer(true, true)))
.build();
DataStream<OrderBean> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
DataStream<Tuple2<String, Integer>> ds = kafkaDS
.flatMap(new FlatMapFunction<OrderBean, Tuple2<String, Integer>>()
public void flatMap(OrderBean order, Collector<Tuple2<String, Integer>> collector)
throws Exception
if (order.getStatus() == 101)
logger.info(">>>>>>orderType->" + order.getOrderType());
collector.collect(new Tuple2<String, Integer>(order.getOrderType(), 1));
);
ds.keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new OrderTypeAggregate())
.addSink(new CountByOrderTypeRedisSink("flinkdemo:kafka:CountByOrderType"));
env.execute();
public static class OrderTypeAggregate
implements AggregateFunction<Tuple2<String, Integer>, OrderCountBean, Tuple2<String, Integer>>
private String orderTypeCountSumKey = "flinkdemo:kafka:OrderTypeAggregate";
@Override
public OrderCountBean createAccumulator()
return new OrderCountBean();
@Override
public OrderCountBean add(Tuple2<String, Integer> value, OrderCountBean accumulator)
int currentVal = 1;
Jedis jedis = null;
try
Configuration conf = new Configuration();
conf = ParamConfig.getParamsFromCurrentCtx().getCofiguredParams();
JedisConfig.JedisConn jedisConn = JedisConfig.getInstance(conf).getConn();
jedis = jedisConn.getJedis();
if (jedis.exists(orderTypeCountSumKey))
String strOrderCount = jedis.hget(orderTypeCountSumKey, value.f0);
if (strOrderCount != null)
currentVal = Integer.valueOf(strOrderCount);
logger.info(">>>>>> " + value.f0 + "->" + currentVal);
currentVal += 1;
jedis.hset(orderTypeCountSumKey, value.f0, String.valueOf(currentVal));
catch (Exception e)
logger.error(">>>>>>createAccumulator error: " + e.getMessage(), e);
finally
try
jedis.close();
catch (Exception e)
accumulator.setOrderType(value.f0);
accumulator.setOrderCount(currentVal);
return accumulator;
@Override
public Tuple2<String, Integer> getResult(OrderCountBean accumulator)
logger.info(">>>>>>getResult->" + accumulator);
return new Tuple2<String, Integer>(accumulator.getOrderType(), accumulator.getOrderCount());
@Override
public OrderCountBean merge(OrderCountBean a, OrderCountBean b)
// logger.info(">>>>>>merge a->" + a + " b->" + b);
return new OrderCountBean();
核心代码解说
AggregateFunction的参数说明
通过上面代码我们可以看到AggregateFunction,它属于一个implements 自 AggregateFunction<上游流类型, 累加器, 输出流类型>的一个类。它里面需要3个输入的参数,这3个输入的参数都为泛型。因此网上很多教程也不解释也不说怎么用,直接就来实现业务了,因此很多人卡在这个地方。我们用一个实际例子来说明这3个输入的类型怎么理解法:
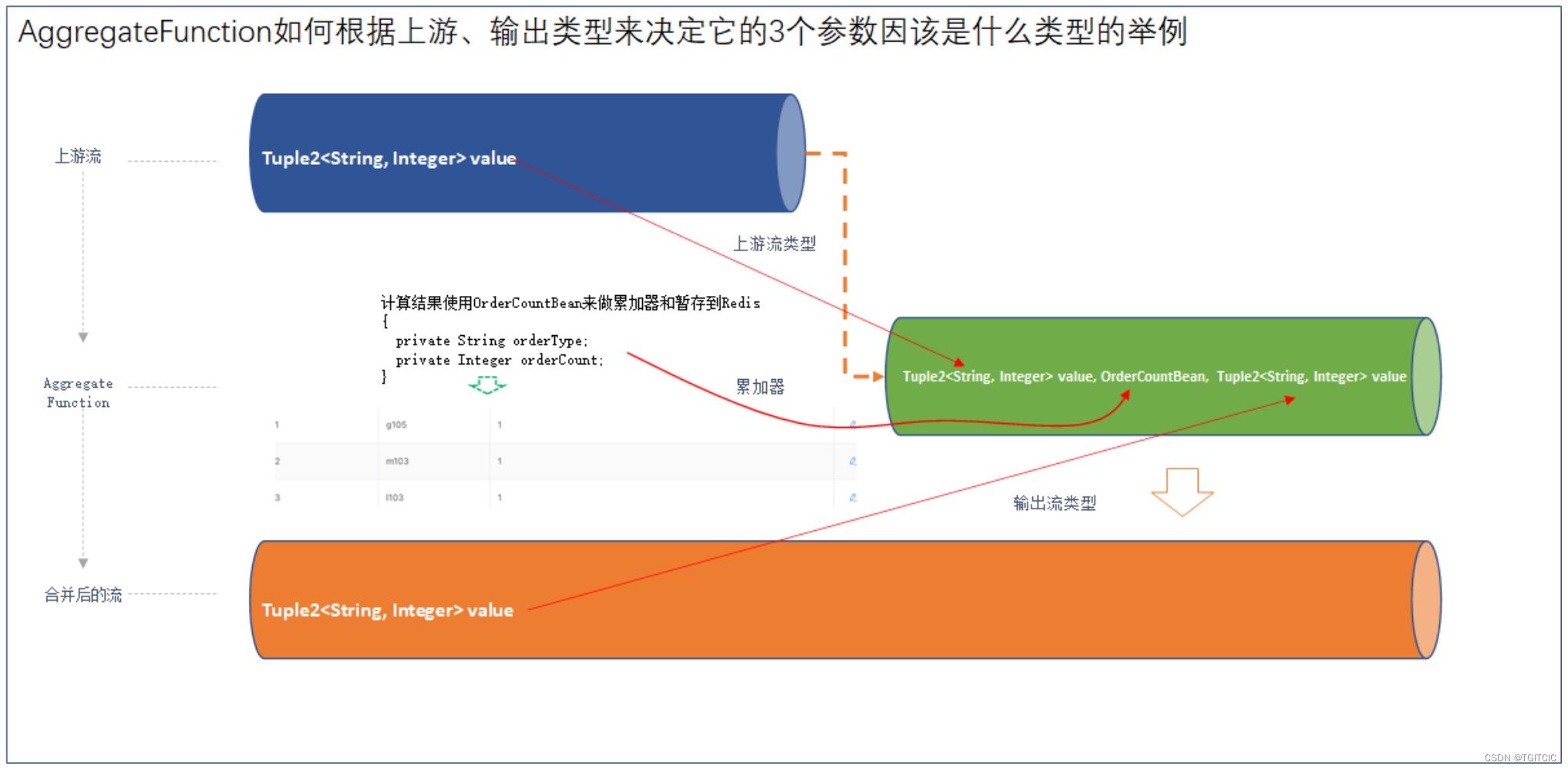
因此我们才有了:
public static class OrderTypeAggregate
implements AggregateFunction<Tuple2<String, Integer>, OrderCountBean, Tuple2<String, Integer>> AggregateFunction的使用
该方法需要重写以下4个方法
@Override
public OrderCountBean createAccumulator()
@Override
public OrderCountBean add(Tuple2<String, Integer> value, OrderCountBean accumulator)
@Override
public Tuple2<String, Integer> getResult(OrderCountBean accumulator)
@Override
public OrderCountBean merge(OrderCountBean a, OrderCountBean b)
createAccumulator方法
就是我们在类的声明时第二个参数类型,此处为初始化一个累加器。每次流的窗口事件被触发就会先触发这个方法,因此这边一般都是直接return new;
add方法
这个方法的返回必须类型为累加器的类型,同时它需要两个参数:
- 第1个参数为类声明中的第一个参数
- 第2个参数为累加器类型;
该方法一定会在每个窗口事件被触发时跟着createAccumulator方法后被触发。
getResult方法
- 返回值必须为类的声明时的第三个参数即“输出类型”;
- 入参只有一个即:累加器;
该方法在流结束时被调用例如.print或者.addSink时就会被触发。
merge方法
- 返回值必须为类声明中的第二个参数即“累加器类型”;
- 入参有两个:都为类加器类型
AggregateFunction中的merge方法仅SessionWindow会调用该方法,如果time window是不会调用的,merge方法即使返回null也是可以的。因此不常用,此处案例中直接return null或者new都是无所谓的。
回到我们的业务逻辑
我们用业务伪代码来描述我们这段代码到底在干了一件什么样的事,一共6个核心步骤:
- 我们接上一个Kafka输入的的这样的流:流中的内容为:"orderType": "123", "status", "101",它先以一个JSON在KAFKA里被传进来,如果orderType为一样,同时它的状态为“101”即有效,那么记成:orderType="123"收到一条,并且以Tuple2<String, Integer>输出;
- 接上自定义的AggregateFunction,以OrderCountBean来做累加器,并最终返回orderType=123在当前时间窗口已经有几条了;
- 在类加器内我们以OrderCountBean来做累加器;
- 然后在add方法内,我们从Redis里找一下有没有orderType=123的当前记录?如果有拿出来加1,再塞回去以做中间结果flinkdemo:kafka:OrderTypeAggregate。如果没有那么往Redis的中间结果flinkdemo:kafka:OrderTypeAggregate里直接塞一条“orderType=123,数量=1“的记录;
- 返回时,把类加器的OrderCountBean结构直接按照Tuple2<String, Integer>返回出去就行了;
- 返回到了最外层后套上.addSink(new CountByOrderTypeRedisSink("flinkdemo:kafka:CountByOrderType"))写到前端小程序或者是APP每5秒刷一下结果用的另一个Redis Key:flinkdemo:kafka:CountByOrderType里;
此处为什么要在Add方法里用Redis暂存的主要目的就在于:
外层因为是一个5秒一触发的滑动窗口,我们假设在生产上遇到了以下这样的一组时间序列动作:

然后我们如果不在AggregateFunction的add方法里做中间计算结果的保存,在9:10分我们可以算出并得到:美团:1单,但是前面的结果就全没了。因为Flink的窗口里的数据是只会保存当前的。一旦.window(TumblingProcessingTimeWindows.of(Time.seconds(5))),5秒一刷新,前面的数据会统统没有。
这就得不到我们每隔5秒可以看到当前各类订单不断的值变化这么一个过程了,而我们只能看到的是当前窗口内的数据的变化,这不是我们想要的。
最后附上全代码。
package org.mk.flink.demo;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.mk.flink.demo.util.JedisConfig;
import org.mk.flink.demo.util.ParamConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.fastjson.JSON;
import redis.clients.jedis.Jedis;
public class CountByOrderTypeAggregateWindow
private final static Logger logger = LoggerFactory.getLogger(CountByOrderTypeAggregateWindow.class);
/**
* main(这里用一句话描述这个方法的作用) (这里描述这个方法适用条件 – 可选)
*
* @param args void
* @exception
* @since 1.0.0
*/
// 序列化
public static class OrderBeanJSONDeSerializer implements KafkaDeserializationSchema<OrderBean>
private final String encoding = "UTF8";
private boolean includeTopic;
private boolean includeTimestamp;
public OrderBeanJSONDeSerializer(boolean includeTopic, boolean includeTimestamp)
this.includeTopic = includeTopic;
this.includeTimestamp = includeTimestamp;
@Override
public TypeInformation<OrderBean> getProducedType()
return TypeInformation.of(OrderBean.class);
@Override
public boolean isEndOfStream(OrderBean nextElement)
return false;
@Override
public OrderBean deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception
if (consumerRecord != null)
try
String value = new String(consumerRecord.value(), encoding);
OrderBean order = JSON.parseObject(value, OrderBean.class);
return order;
catch (Exception e)
logger.error(">>>>>>deserialize failed : " + e.getMessage(), e);
return null;
public static void main(String[] args) throws Exception
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool argParas = ParameterTool.fromArgs(args);
String propertiesFilePath = argParas.get("config_path");
if (logger.isDebugEnabled())
logger.debug(">>>>>>start to load properties from ", propertiesFilePath);
ParameterTool paras = ParameterTool.fromPropertiesFile(propertiesFilePath);
// ParameterTool configname = ParameterTool.fromPropertiesFile(path);
// env.getConfig().setGlobalJobParameters(paras);
Configuration conf = new Configuration();
conf = ParamConfig.getInstance(propertiesFilePath).getCofiguredParams();
if (conf == null)
throw new Exception(">>>>>>init config.properties into flink error");
env.getConfig().setGlobalJobParameters(conf);
KafkaSource<OrderBean> source = KafkaSource.<OrderBean>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new OrderBeanJSONDeSerializer(true, true)))
.build();
DataStream<OrderBean> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
DataStream<Tuple2<String, Integer>> ds = kafkaDS
.flatMap(new FlatMapFunction<OrderBean, Tuple2<String, Integer>>()
public void flatMap(OrderBean order, Collector<Tuple2<String, Integer>> collector)
throws Exception
if (order.getStatus() == 101)
logger.info(">>>>>>orderType->" + order.getOrderType());
collector.collect(new Tuple2<String, Integer>(order.getOrderType(), 1));
);
ds.keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new OrderTypeAggregate())
.addSink(new CountByOrderTypeRedisSink("flinkdemo:kafka:CountByOrderType"));
env.execute();
public static class OrderTypeAggregate
implements AggregateFunction<Tuple2<String, Integer>, OrderCountBean, Tuple2<String, Integer>>
private String orderTypeCountSumKey = "flinkdemo:kafka:OrderTypeAggregate";
@Override
public OrderCountBean createAccumulator()
return new OrderCountBean();
@Override
public OrderCountBean add(Tuple2<String, Integer> value, OrderCountBean accumulator)
int currentVal = 1;
Jedis jedis = null;
try
Configuration conf = new Configuration();
conf = ParamConfig.getParamsFromCurrentCtx().getCofiguredParams();
JedisConfig.JedisConn jedisConn = JedisConfig.getInstance(conf).getConn();
jedis = jedisConn.getJedis();
if (jedis.exists(orderTypeCountSumKey))
String strOrderCount = jedis.hget(orderTypeCountSumKey, value.f0);
if (strOrderCount != null)
currentVal = Integer.valueOf(strOrderCount);
logger.info(">>>>>> " + value.f0 + "->" + currentVal);
currentVal += 1;
jedis.hset(orderTypeCountSumKey, value.f0, String.valueOf(currentVal));
catch (Exception e)
logger.error(">>>>>>createAccumulator error: " + e.getMessage(), e);
finally
try
jedis.close();
catch (Exception e)
accumulator.setOrderType(value.f0);
accumulator.setOrderCount(currentVal);
return accumulator;
@Override
public Tuple2<String, Integer> getResult(OrderCountBean accumulator)
logger.info(">>>>>>getResult->" + accumulator);
return new Tuple2<String, Integer>(accumulator.getOrderType(), accumulator.getOrderCount());
@Override
public OrderCountBean merge(OrderCountBean a, OrderCountBean b)
// logger.info(">>>>>>merge a->" + a + " b->" + b);
return new OrderCountBean();
以上是关于FLINK 基于1.15.2的Java开发-使用AggregateFunction解决以天为单位诸如PVUV等统计的实时计算的主要内容,如果未能解决你的问题,请参考以下文章