InnoDB索引不能只知道B+树
Posted hello_读书就是赚钱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了InnoDB索引不能只知道B+树相关的知识,希望对你有一定的参考价值。
本文主要总结介绍InnoDB索引的相关知识点,为后面的问题排查定位做准备.本文不会深入讲解算法,但是会用通俗易懂的话总结索引的一些知识.站在懒人的角度,统揽一些做为业务开发该懂的InnoDB索引知识,每个点读者都可以继续深入研究
1、了解索引的重要性
我们都知道索引只能在事前增加,不能事后添加.因为随着数据的增加,online DDL消耗的性能与时间就会越来越多.
而不正确的使用索引会导致IO变大,插入修改缓慢.所以我们需要抱着正确使用索引的目的,来探究InnoDB索引的奥秘.
2、了解B+树算法
终归了解InnoDB还是先从B+树入手.
B+树,这其中的B是平衡的意思.B+树是从二叉平衡树演化而来的多叉平衡树,它的树高一般控制在2到4层,有多叉节点,每个节点可以容纳多个数据.
下面我们先看看从二叉树到B+树的演绎过程
2.1、二叉搜索树
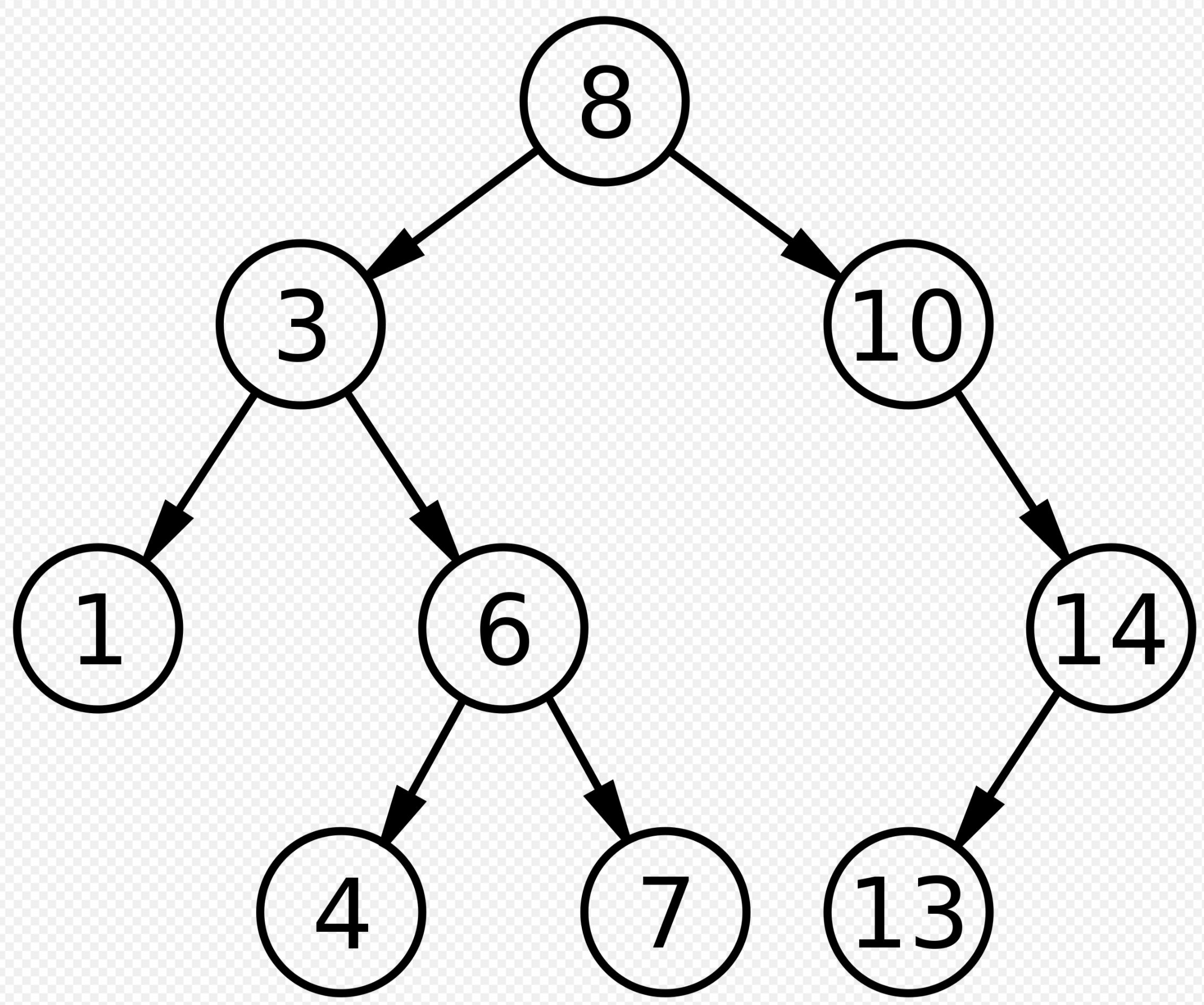
如图所示,在二叉搜索树中,以根节点为例,会把所有小于根节点的数都放在左子树中,把大于根节点的数都放在右子树中.
如果我们利用二叉树来做搜索的话,算法复杂度为O(logN)
但是二叉树存在一种情况如下,时间复杂度会退化成O(N)
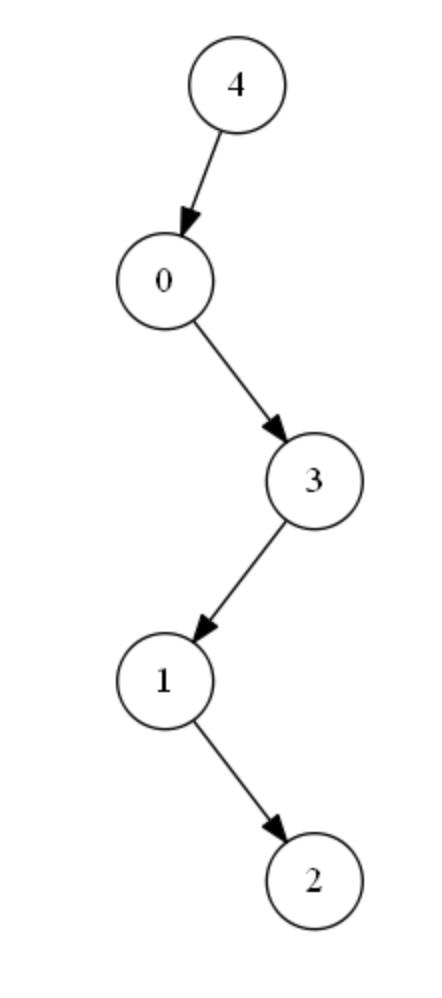
所以,我们需要尽量的让二叉树左右子树平衡,让时间复杂度保持在O(logN)
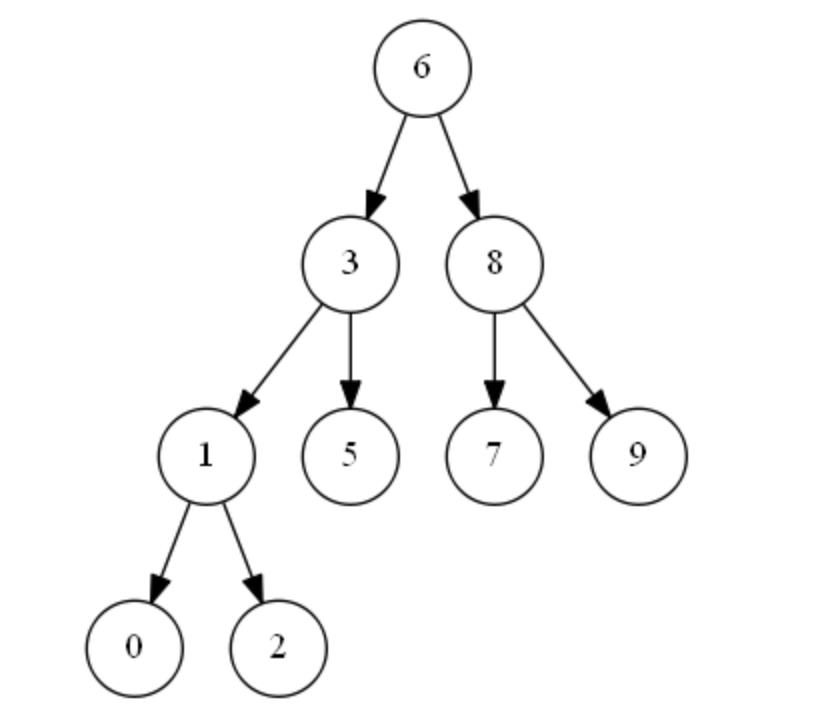
2.2 B+树
B+树是一个平衡的多叉搜索树.
在每一个树非叶子节点中存放的是索引数据
在叶子节点中存放的是所有数据,并且在叶子节点中存在next指针,从第一个叶子节点开始,可以通过next指针顺序遍历完所有的叶子节点.这也是B+树适合用来做范围查询的知识点.
下面,是B+树的插入过程动画,包含的插入与分裂过程,总结来说就是让B+树一直保持低层高,且平衡状态

下面是B+树的删除过程动画,包含的是删除与合并过程,总结来说还是与插入的目的一致
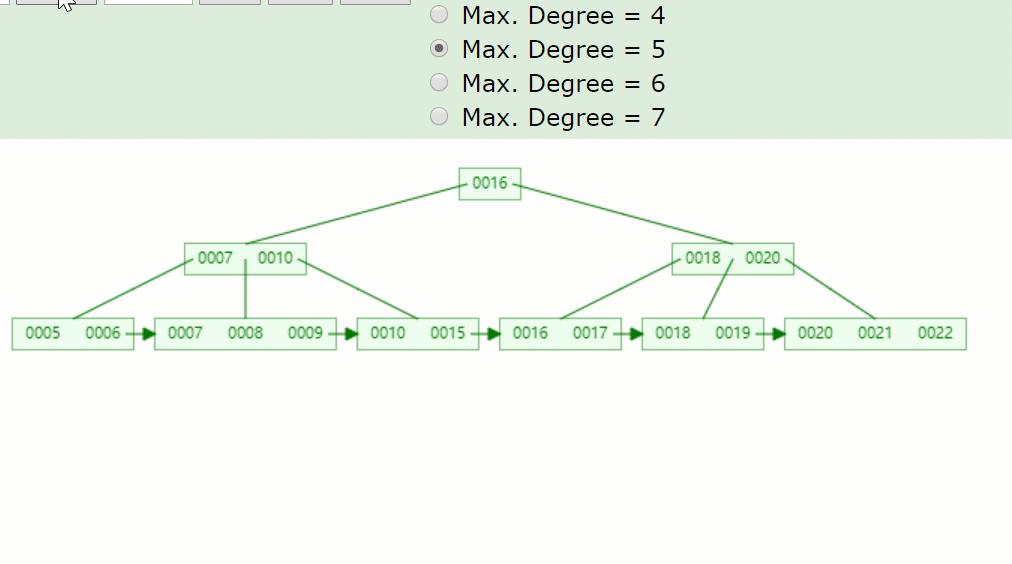
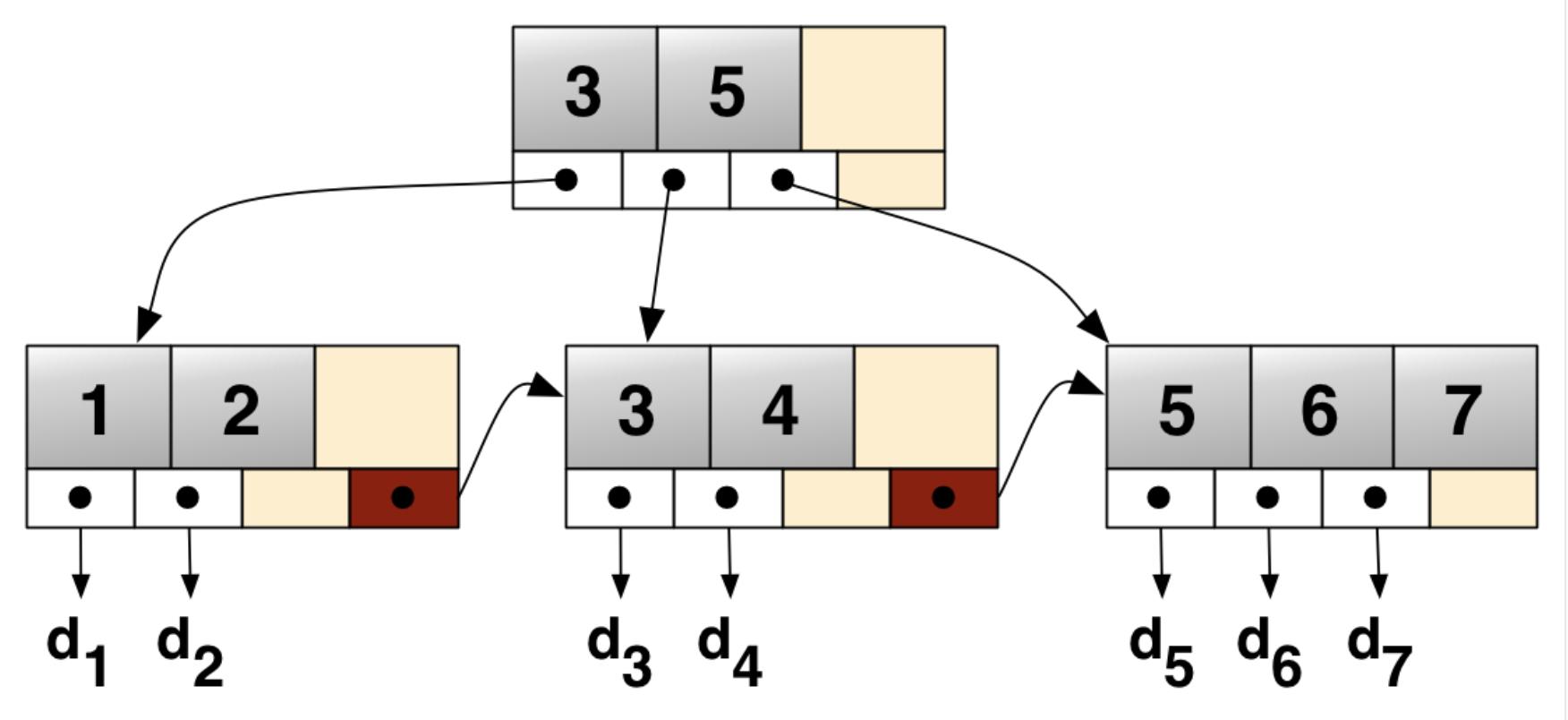
3、B+树构成的索引
3.1、索引使用B+树好处
- 支持范围查询.注意这个也经常拿来做与红黑树比较的点,就是因为红黑树是二叉平衡树,且没有next指针,无法执行范围查询
- 层次低,一般是控制在2到4层,在机械盘中 100次io/s 所以平均执行一次B+树查询操作,大概话费20~40ms.作者在腾讯的tdsql执行索引查询,基本维持在18ms左右
3.2、B+树在InnoDB中的用途
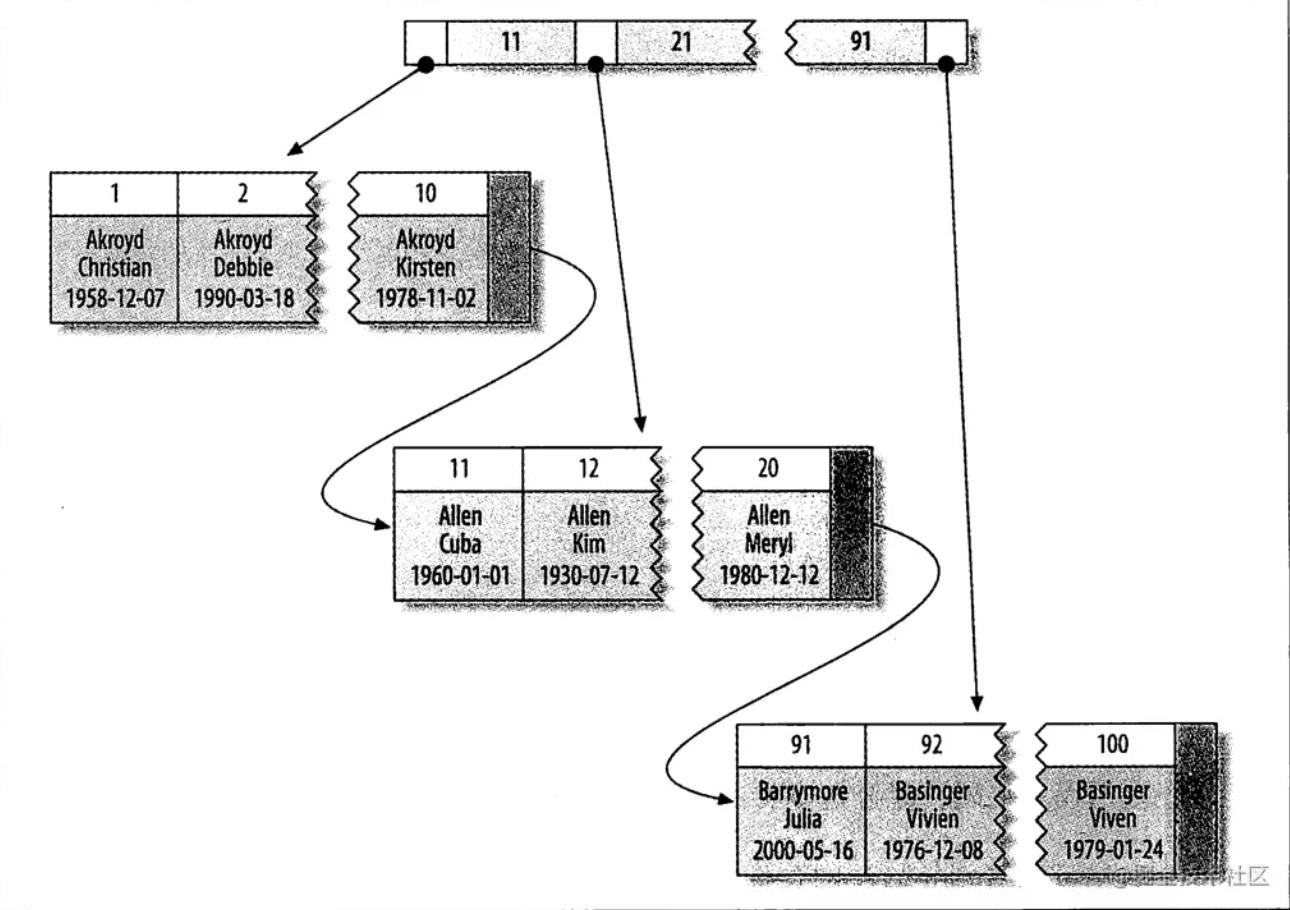
用在聚集索引中.
如下图所示,在聚集索引中,B+树的非叶子节点是由每一条数据的ID所构成,B+树的叶子节点是由数据页组成,数据页里面记录的是整条数据所有字段内容
注意叶子节点的数据存储中遵循逻辑顺序而不是物理顺序,在磁盘上并不是顺序排放的.
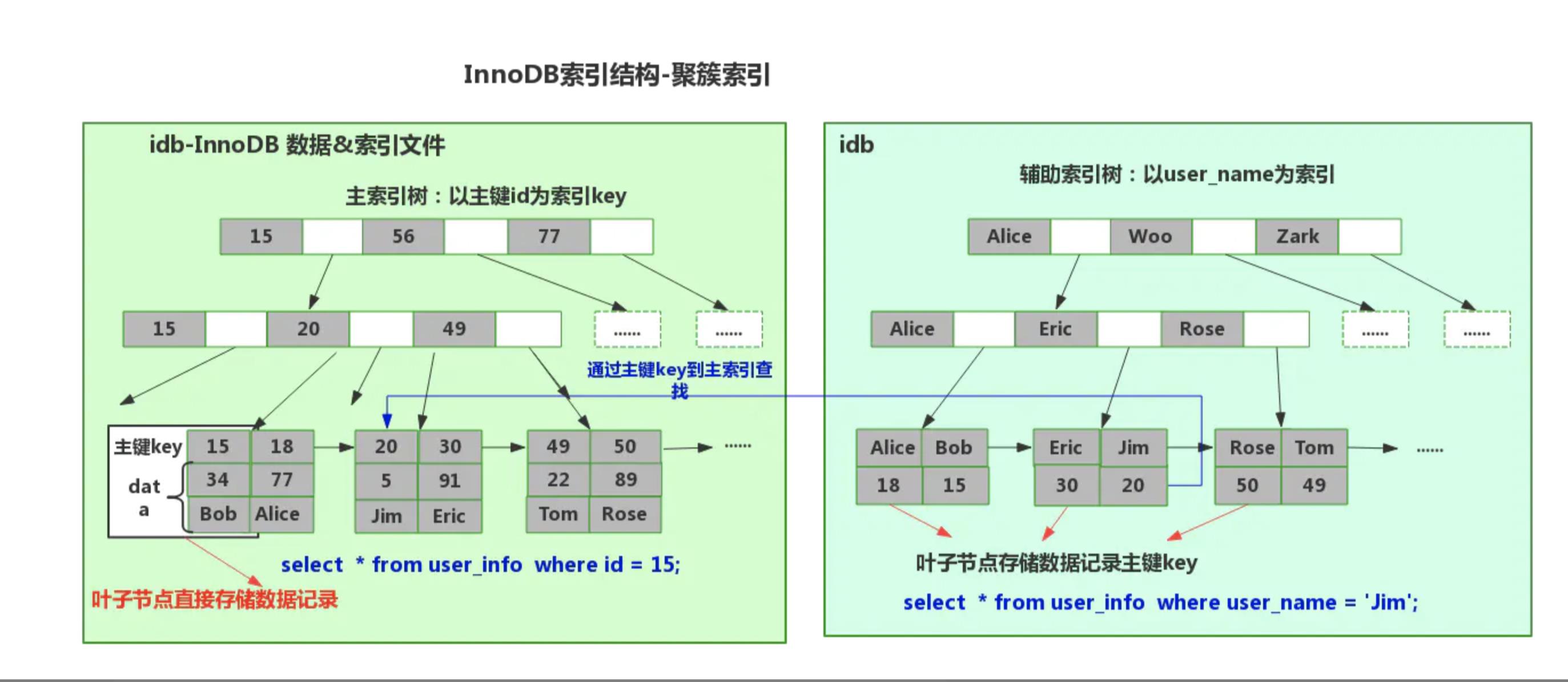
用在辅助索引中.
如下图所示,辅助索引的
非叶子节点中记录的是索引数据,
而叶子节点中记录的是数据页,数据页里面记录的是每一条数据的主键.
所以当使用辅助索引无法覆盖索引查询的时候,将会回表到聚集索引中二次查询,下面会继续说明这个点,现在主要说明辅助索引的数据结构
3.2 索引的管理
3.2.1 创建索引的DDL语法
方式一,留意后面的参数值是支持online DDL配置:
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
[index_type]
ON tbl_name (key_part,...)
[index_option]
[algorithm_option | lock_option] ...
key_part:
col_name [(length)] [ASC | DESC]
index_option:
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
index_type:
USING BTREE | HASH
algorithm_option:
ALGORITHM [=] DEFAULT | INPLACE | COPY
lock_option:
LOCK [=] DEFAULT | NONE | SHARED | EXCLUSIVE
方式二,同样支持 online DDL的形式
ALTER TABLE tbl_name
[alter_option [, alter_option] ...]
[partition_options]
alter_option:
table_options
| ADD INDEX | KEY [index_name]
[index_type] (key_part,...) [index_option] ...
以上语句的具体使用用法均可参考mysql官方文档
3.2.2 评估索引性能
通过,下面sql我们可以看到这个表的索引情况
show index from tables_name;
结果如下:
Table: members
Non_unique: 0
Key_name: phone
Seq_in_index: 1
Column_name: phone
Collation: A
Cardinality: 406567
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
注意,这里我们主要要留意字段Cardinality,表示索引键的基数,基数越小越没存在的必要,是根据随机采样统计出来的,比如对性别做基数计算,那么算出来的值是 2/数据总数,这个2是男跟女.但是这个结果并不是准确实时统计的,可以通过analyze table语句使其更新,但是要考虑一下analyze table的性能,会加读锁(analyze table用法).这个参数的计算算法也可以了解一下,算法如下:
取得B+树索引中叶子节点的数量,记为A
随机取得B+树索引中的8个叶子节点.统计每个页不同记录的个数,即为P1到P8
根据采样信息给出预估值:cardinality=(P1+P2…P8)*A/8
3.3 索引变更的四个方案
索引变更总是要在线运行的,如果数据量大的话往往都是会让人头疼,下面讲一下在InnoDB索引变更的几种机制原理
3.3.1 原始方式
锁表
建新表并加好索引
倒入旧数据
这种原始操作方式只会在MySQL的旧版本中存在,因为会有阻塞操作,一般不会被使用
3.3.2 fast index creation
加索引时.加读锁,并在原来的表什么进行变更
删索引时.把辅助索引标志为不可用,并删除辅助索引
这种方式也是MySQL原生提供的,比原始方式的改进点是不需要再建立一个新的表,直接在原表操作,不过输在还要加一个读锁,那么也是会影响线上的写操作.
3.3.3 online schema change
这种方式是需要用第三方脚本的,所以我们也是按书籍里面所说,给出它的运行方式,提供给我们一个参考方案,它的执行算法如下:
初始化
创建新表并增加索引等
创建临时表,用于记录在执行操作时发生的增量数据
将原表数据写入新表
回放增量数据
锁表,并且重命名两张表
可见它运行方式也是通过创建一个新表的方式运行,把增量数据同步到一个增量表,在同步完成后,再倒入增量数据,加锁并进行重命名操作
3.3.4 online DDL
online DDL之前有在上一篇文章讲过,所以这里就不再细说,总结一下它的操作原理
操作原理,在旧表上面进行表更,把增量数据写入到缓冲区,完成变更后重放缓冲区数据
从上面几个操作流程中我们可见所有的热切换的动作,都是把增量数据先写到某一个地方再同步过去.这大概也是热切的一套避免不了的方案,像redis的分片迁移也是类似的道理.
3.4 索引的准确用法
有了上面的基础知识铺垫后,我们来了解一下索引的几个常用的用法,用对性能高效百倍
3.4.1 联合索引
联合索引指的是我们创建索引的时候指定多个字段来做联合索引,关于这个点,我们要谨记最左原则.
比如建立联合索引(a,b)那么索引是按a键比较建立的,但是会包含字段b,当a相同时,字段b也会进行排序,但是如果查询条件只有b的话,那就没法走索引查询了.
原因很简单,就是辅助索引B+树的非叶子节点的索引值就是最左的那个字段构成的.
3.4.2 覆盖索引
指的是在使用辅助索引时,我们select后面的字段最好是跟辅助索引上面的字段完全匹配的,因为这样直接查询一次辅助索引就好了,不需要重新回表去聚集索引查询其他字段信息,性能至少能快一倍
3.4.3 count操作
其实我们count操作都是在辅助索引上面进行统计的,这个点我们需要知道它是这么做就好,注意在InnoDB上面count是被实时统计出来的
3.4.4 优化器不一定走辅助索引
当数据量大的时候,发现查询后还要回表,那么优化器会选择直接走覆盖索引查询,可以通过强制执行索引来避过,但是请相信优化器的能力.
所以,当我们执行SQL语句的时候最好是先explain一下看下执行计划,尽量把SQL语句优化好,让它走好辅助索引这条路
3.4.5 index condition pushdown优化
也就是常常说的索引下推,就是如果查询where条件覆盖了辅助索引的键,那么将会在辅助索引那里做好过滤操作,再去回表操作.这个都是老生常谈的点,跟#3.4.2 的一样道理,谨记,在这里
在explain中如果显示using index condition的时候就是代表使用了索引下推
3.4.6 multi-range read优化
当我们使用辅助索引进行搜索时,都是要换取主键ID然后去聚集索引里面反查一次,这个过程是随机读取的,会比较慢.
MRR(multi-range read)优化方式就是通过收集这些换取后的主键ID,放在内存中并进行排序,当需要范围查询的时候直接通过顺序读取的方式在聚集索引中把数据load出来.
适用MRR主要有以下好处:
- MRR能基于索引做顺序读取,读取数据时更高效便利
- MRR能提供类似缓存的效果,当数据曾经被获取过的时候,不需要重新回表获取
MRR运行的场景算法如下:
1.让索引元组的一部分累积在缓冲区中。
2.讲缓冲区中的元组按其数据行 ID 排序。
3.根据排序的索引元组序列访问数据行。
当我们开启了MRR优化时,我们通过explain来看到sql语句执行计划带上了Using MRR.
注意,MRR默认是没有开启的,当我们不需要经常获取批量数据的时候,我们是不需要开启MRR的,毕竟也是一个空间换时间的过程,开启的话可以通过环境变量直接开启,具体可以查阅文档MySQL关于MRR的介绍
4.hash算法构建的索引
在InnoDB中并没有由hash算法构建的索引.没有存在的必要性.
但是并不代表hash算法不会在引擎中被使用.在InnoDB中什么时候使用hash算法是由引擎自己控制的,无法人为控制,比如做id精确查询的时候就是,它可以用hash进行优化,在数据量较小的时候提高查询效率,这样的场景不多,我们也知道就好了.
5.全文索引
我相信在正常的系统中,一般都不会用MySQL来做全文索引,毕竟它的使用限制很多,但是本文也要提及相关知识点,主要是为了后面入手搜索引擎做好铺垫.
5.1 倒排索引
了解全文索引离开不了了解倒排索引,用一句话总结就是把文档分好单词,再通过单词去反关联到文章的ID,我们就称为倒排索引
以英文为例,下面是要被索引的文本:
0:"it is what it is"
1: "what is it"
2: "it is a banana"
我们就能得到下面的反向文件索引:
"a": 2
"banana": 2
"is": 0, 1, 2
"it": 0, 1, 2
"what": 0, 1
5.2 InnoDB中的全文索引实现方式
画了一张架构图
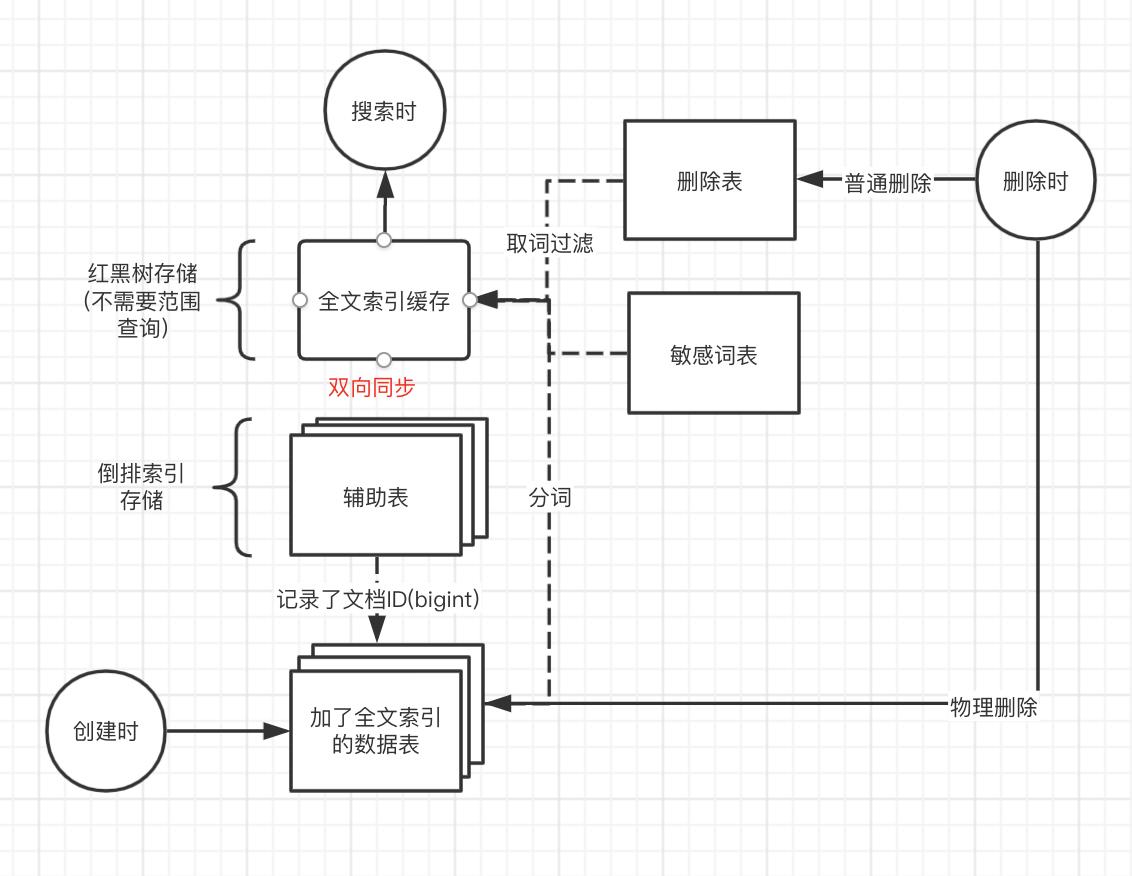
我们从这个架构图入手来看,从使用的几个阶段来说
1.在创建索引时,我们会把数据插入数据表,此时引擎会对文档进行分词,把分词后的信息存入由红黑树做成的缓存,在一定的时间同步到倒排索引的辅助表中.
2.在搜索时,直接查询全文索引缓存,当没击中缓存的时候再去辅助表里面做查询,注意,引擎还提供了一张类似于敏感词表的东西,让用户过滤一些敏感词汇
3.在删除时,会把要删除的数据记录到一张删除表,并不是立刻用物理删,这也是空间与性能的一个平衡,当然了也可以人为的强制进行物理删除
5.3 全文索引的限制
正因为全文索引的限制我们才无法利用MySQL来做全文索引
- 每张表只能有一个全文索引
- 多列组合而成的全文索引必须使用相同的字符集与排序规则
- 不支持没有单词界定符的语音,如中文,日语,韩语等
所以,即使全文索引的适用方式多丰富也不适用我们中国的场景
以上是关于InnoDB索引不能只知道B+树的主要内容,如果未能解决你的问题,请参考以下文章