大数据仓库技术实训任务3
Posted 陈希瑞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据仓库技术实训任务3相关的知识,希望对你有一定的参考价值。
大数据仓库实训-任务3
淘宝双11数据分析与预测
案例简介
淘宝双11数据分析与预测课程案例,涉及数据预处理、存储、查询和可视化分析等数据处理全流程所涉及的各种典型操作,涵盖Linux、mysql、Hadoop、Hive等系统和软件的安装和使用方法。通过本案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据分析操作。
案例目的
- 熟悉Linux系统、MySQL、Hadoop、Hive等系统和软件的安装和使用;
- 了解大数据处理的基本流程;
- 熟悉数据预处理方法;
- 熟悉使用hive进行数据分析处理。
时间安排
3天
预备知识
需要案例使用者,已经学习过大数据相关课程,了解大数据相关技术的基本概念与原理,了解Windows操作系统、Linux操作系统、大数据处理架构Hadoop的关键技术及其基本原理、数据仓库概念与原理、关系型数据库概念与原理等相关知识。
硬件要求
本案例可以在单机上完成,也可以在集群环境下完成。
软件工具
本案例所涉及的系统及软件:
- Linux系统
- MySQL
- Hadoop
- Hive
……
数据集
淘宝购物行为数据集 (5000万条记录,数据有偏移,不是真实的淘宝购物交易数据,但是不影响学习)
案例任务
- 安装Linux操作系统
- 安装关系型数据库MySQL
- 安装大数据处理框架Hadoop
- 安装数据仓库Hive
- 对文本文件形式的原始数据集进行预处理
- 把文本文件的数据集导入到数据仓库Hive中
- 对数据仓库Hive中的数据进行查询分析
实验步骤
| 步骤零:实验环境准备 |
| 步骤一:本地数据集上传到数据仓库Hive |
| 步骤二:Hive数据分析 |
| 步骤三:数据可视化分析(可选) |
每个实验步骤所需要的知识储备、训练技能和任务清单如下:
步骤零:实验环境准备
| 所需知识储备 | Windows操作系统、Linux操作系统、大数据处理架构Hadoop的关键技术及其基本原理、列族数据库HBase概念及其原理、数据仓库概念与原理、关系型数据库概念与原理 |
| 训练技能 | 操作系统安装、虚拟机安装、Linux基本操作、Hadoop安装、Hive安装等 |
| 任务清单 | 1. 安装Linux系统;2. 安装Hadoop;3. 安装MySQL;4. 安装Hive |
步骤一:本地数据集上传到数据仓库Hive
| 所需知识储备 | Linux系统基本命令、Hadoop项目结构、分布式文件系统HDFS概念及其基本原理、数据仓库概念及其基本原理、数据仓库Hive概念及其基本原理 |
| 训练技能 | Hadoop的安装与基本操作、HDFS的基本操作、Linux的安装与基本操作、数据仓库Hive的安装与基本操作、基本的数据预处理方法 |
| 任务清单 | 1. 安装Linux系统;2. 数据集下载与查看;3. 数据集预处理;4. 把数据集导入分布式文件系统HDFS中;5. 在数据仓库Hive上创建数据库 |
步骤二:Hive数据分析
| 所需知识储备 | 数据仓库Hive概念及其基本原理、SQL语句、数据库查询分析 |
| 训练技能 | 数据仓库Hive基本操作、创建数据库和表、使用SQL语句进行查询分析 |
| 任务清单 | 1. 启动Hadoop和Hive;2. 创建数据库和表;3. 简单查询分析;4. 查询条数统计分析;5. 关键字条件查询分析;6. 根据用户行为分析;7. 用户实时查询分析等 |
步骤零:实验环境准备
安装的相应的Linux,Hadoop,MySQL,Hive等。
步骤一:本地数据集上传到数据仓库Hive
任务清单:
- 数据集下载与查看
- 数据集预处理
- 把数据集导入分布式文件系统HDFS中
- 在数据仓库Hive上创建数据库
任务步骤:
本案例采用的数据集压缩包为data_format.zip,该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv。数据集已在案例任务打包文件中。
下面列出这3个文件的数据格式定义:
用户行为日志user_log.csv,日志中的字段定义如下:
-
user_id | 买家id
-
item_id | 商品id
-
cat_id | 商品类别id
-
merchant_id | 卖家id
-
brand_id | 品牌id
-
month | 交易时间:月
-
day | 交易时间:日
-
action | 行为,取值范围0,1,2,3,0表示点击,1表示加入购物车,2表示购买,3表示关注商品
-
age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
-
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
-
province| 收货地址省份
回头客训练集train.csv和回头客测试集test.csv,训练集和测试集拥有相同的字段,字段定义如下:
-
user_id | 买家id
-
age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
-
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
-
merchant_id | 商家id
-
labe- | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
接下来请操作以下内容。
1. 首先建立一个用于运行本案例的目录:
1)在/root目录下建立一个新的目录dbtaobao
mkdir dbtaobao

2)给hadoop用户赋予针对dbtaobao目录的各种操作权限。
chmod 777 dbtaobao

3)dbtaobao下面创建一个dataset目录,用于保存数据集。
cd dbtaobao
mkdir dataset

4)将数据集压缩包data_format.zip拷贝到dataset目录下
- 查看在dataset目录下是否有三个文件:test.csv、train.csv、user_log.csv,并用命令取出user_log.csv前面5条记录看一下,如下图所示。(提示:head -n目标文件)
cd dataset
head -5 user_log.csv

2. 数据集的预处理
1)user_log.csv的第一行都是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,请删除文件第一行记录,即字段名称。(提示:sed -i ‘nd’ 目标文件,这里的n指的是行数)
sed -i '1d' user_log.csv

2)用命令取出user_log.csv前面5条记录看一下是否如下图所示,检查是否删除成功。
head -5 user_log.csv

3.获取数据集中双11的前10000条数据
由于数据集中交易数据太大,这里只截取数据集中在双11的前10000条交易数据作为小数据集small_user_log.csv。
1)在/root/dbtaobao/dataset目录下面通过vim建立一个脚本文件名叫predeal.sh,请在这个脚本文件中加入下面代码并保存:
vim predeal.sh
#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在’这两个字符的后面
awk -F "," 'BEGIN
id=0;
if($6==11 && $7==11)
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000)
exit
' $infile > $outfile

2)执行predeal.sh脚本文件,截取数据集中在双11的前10000条交易数据作为小数据集small_user_log.csv,命令如下:
chmod +x ./predeal.sh
./predeal.sh ./user_log.csv ./small_user_log.csv

之后在dataset目录下应有以下文件:

可以查看下small_user_log.csv的前5条数据如下:
head -5 small_user_log.csv

4. 上传文件到分布式文件系统HDFS中
1)启动Hadoop。
start-all.sh

- 在HDFS的根目录下面创建一个新的目录dbtaobao,并在这个目录下创建一个子目录dataset/user_log,命令如下:
hadoop fs -mkdir -p /dbtaobao/dataset/user_log

3)把Linux本地文件系统中的small_user_log.csv上传到分布式文件系统HDFS的“/dbtaobao/dataset/user_log”目录下。
hadoop fs -put "/root/dbtaobao/dataset/small_user_log.csv" /dbtaobao/dataset/user_log

4)查看一下HDFS中的small_user_log.csv的前10条记录验证是否成功。(提示:hadoop fs -cat 目标文件 | head -n)
hadoop fs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10

5. small_user_log.csv中数据导入数据仓库Hive
1)启动MySQL,启动Hive,进入hive交互界面,创建一个新的数据库dbtaobao。
systemctl start mysqld
hive

2)在数据库dbtaobao中创建一个外部表user_log,它包含字段user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING),每个字段之间由’,‘分割,以TEXTFILE方式保存, 同时指定外部表存放数据的路径(指向路径)为’/dbtaobao/dataset/user_log’(注意:如果指定了存放路径,就不会默认存放在user/hive/warehouse/dbtaobao.db中了,注意思考一下这个指定存放路径的意义)
--创建数据库
create database dbtaobao;
--查看数据库
show databases;
use dbtaobao;
--创建外部表user_log
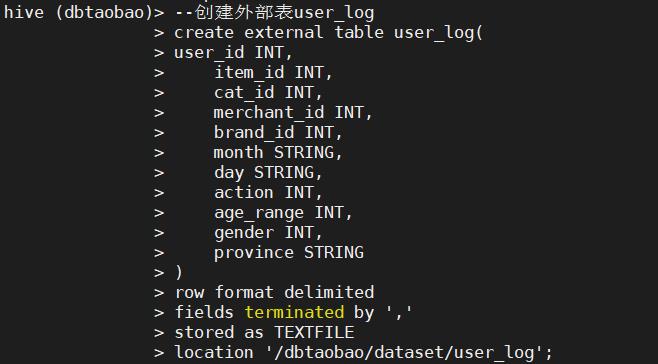
create external table user_log(
user_id INT,
item_id INT,
cat_id INT,
merchant_id INT,
brand_id INT,
month STRING,
day STRING,
action INT,
age_range INT,
gender INT,
province STRING
)
row format delimited
fields terminated by ','
stored as TEXTFILE
location '/dbtaobao/dataset/user_log';


步骤二:Hive数据分析
任务清单
-
启动Hadoop和Hive
-
创建数据库和表
-
简单查询分析
-
查询条数统计分析
-
关键字条件查询分析
-
关联查询,联合查询分析
-
函数查询分析
-
根据用户行为分析
-
用户实时查询分析等
接下来请操作以下内容。
注意本步骤需要在MySQL、Hadoop和Hive三者都启动的前提下进行。
1. Hive中简单查询分析
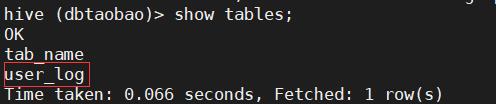
1)使用dbtaobao数据库,显示数据库中所有表,查看user_log表的简单结构
use dbtaobao;
show tables;
desc user_log;

2)查看user_log表的各种属性(查看表的详细的建表语句)。
show create table user_log;
--或者
describe formatted user_log;


3)查看user_log表日志前10个交易日志的商品品牌。
select brand_id from user_log limit 10;

4)查询user_log表前20个交易日志中购买商品时的时间和商品的种类。
select month, day, cat_id form user_log limit 20;

2. Hive中统计分析
1)统计出user_log表内有多少条行数据。(10000)
select count(*) from user_log;

2)统计出user_log表中总共有多少客户(统计不重复的user_id)。(358)
select count(distinct user_id) from user_log;

3)统计出user_log表中年龄段小于18岁和大于等于50岁的买家有多少位。(注意去重)(322)
select count(distinct user_id) from user_log where age_range in (1,7,8);

4)统计购买了商品类别为1280号的女性有多少位。(2)
select count(distinct user_id) from user_log where gender=0 and cat_id=1280;

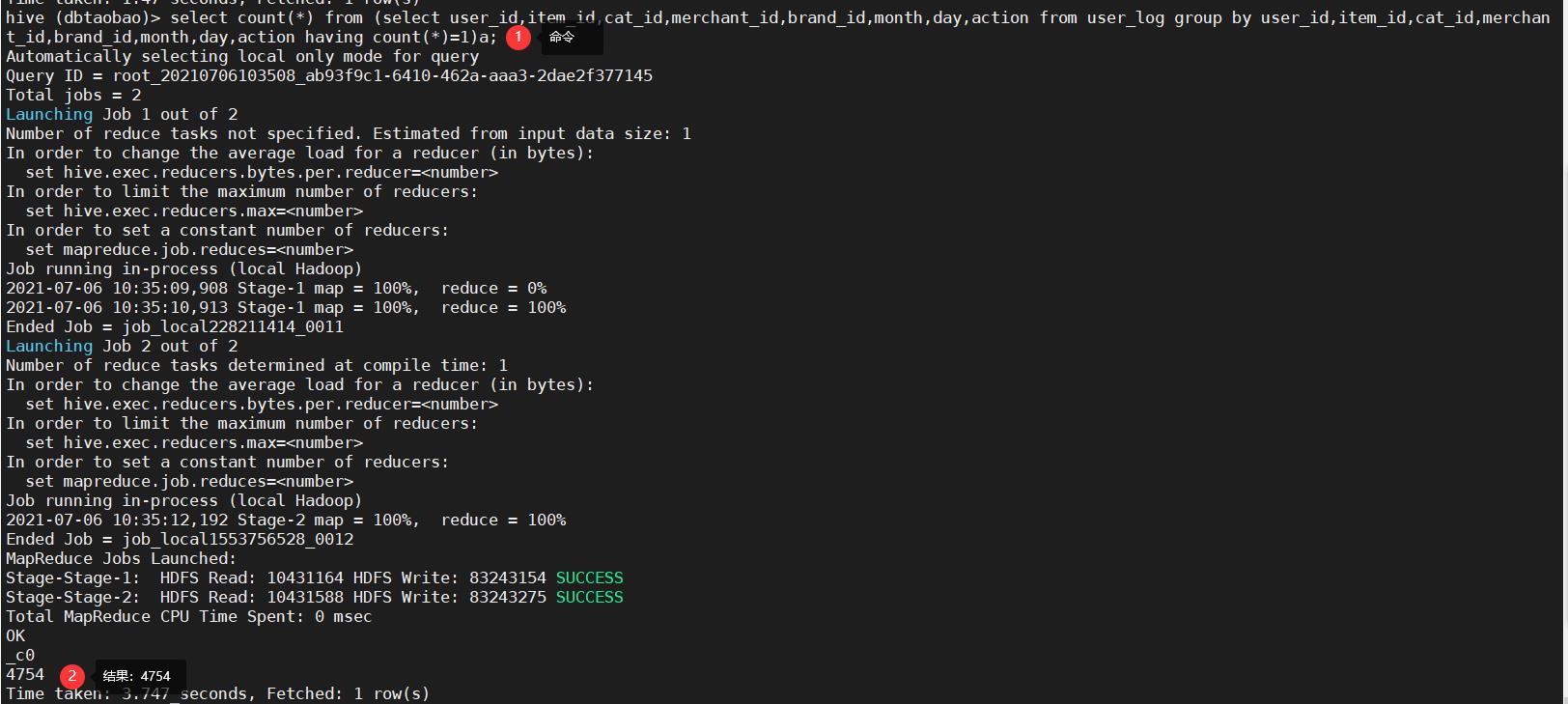
5)统计出user_log表不重复的数据有多少条(为了排除客户刷单情况)(重复的数据是指所有字段的数据一致)。(注意:嵌套语句最好取别名)(4754)
select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;
3. Hive中关键字条件查询分析
1)根据user_log表查询双11那天有多少人关注了商品(注意人要去重)。(60)
select count(distinct user_id) from user_log where action=3;

2)求当天购买2661品牌商品的数次。(3)
select count(user_id) from user_log where action=2 and month=11 and day=11 and brand_id=2661;

4. Hive中根据用户行为分析
1)查询有多少用户在双11购买了商品。(注意去重)(358)
select count(distinct user_id) from user_log where action=2 and month=11 and day=11;

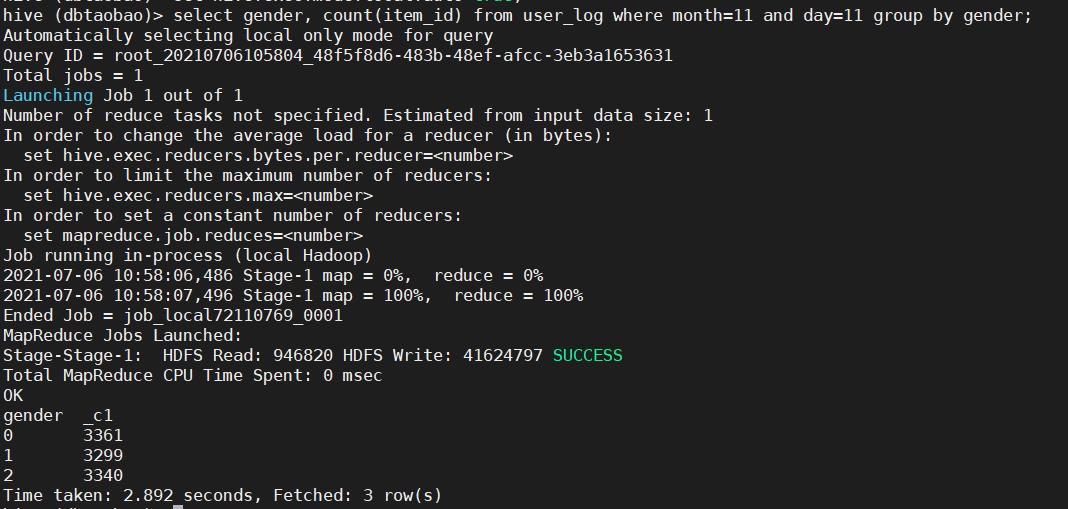
2)查询双11那天,按照男女以及未知性别买家分类所购买商品的数量。
select gender, count(item_id) from user_log where month=11 and day=11 group by gender;
3)查询在该网站购买商品超过5次的用户id
select user_id from user_log where action='2' group by user_id having count(action='2')>5;

5. Hive中用户实时查询分析
1)创建新的数据表scan, 有字段brand_id INT(品牌),scan INT(品牌被购买次数),每个字段之间由’\\t '分割
create table scan(
brand_id INT,
scan INT
)
row format delimited
fields terminated by '\\t';

2)将user_log中统计出的品牌和对应购买了该品牌的次数的数据传入表scan中,并按照brand_id升序排序,如下图所示:
insert into table scan select brand_id,count(action) from user_log where action='2' group by brand_id order by brand_id asc;
--查看数据行数
select count(*) from scan;

6. 预处理test.csv数据集
这里列出test.csv和train.csv中字段的描述,字段定义如下:
-
user_id | 买家id
-
age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
-
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
-
merchant_id | 商家id
-
labe- | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
请进行以下操作:
1)这里需要预先处理test.csv数据集,把这test.csv数据集里label字段表示-1值剔除掉,保留需要分析的数据.并假设需要分析的数据中label字段均为1。在/root/dbtaobao/dataset目录下使用vim编辑器新建一个predeal_test.sh脚本文件,请在这个脚本文件中加入下面代码。
#!/bin/bash
#下面设置输入文件,把用户执行predeal_test.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_test.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在’这两个字符的后面
awk -F "," 'BEGIN
id=0;
if($1 && $2 && $3 && $4 && !$5)
id=id+1;
print $1","$2","$3","$4","1
if(id==10000)
exit
' $infile > $outfile
下面就可以执行predeal_test.sh脚本文件,截取测试数据集需要预测的数据到test_after.csv,命令如下:
chmod +x ./predeal_test.sh
./predeal_test.sh ./test.csv ./test_after.csv

然后请在/root/dbtaobao/dataset目录下查看脚本与处理后的数据test_after.csv是否都在。
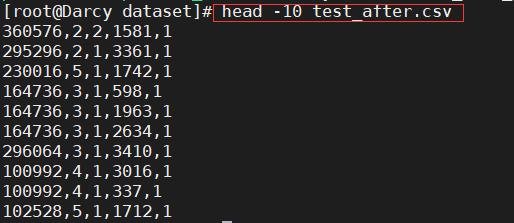
截取前十行看看。
head -10 test_after.csv
7. 预处理train.csv数据集
1)数据集train.csv的第一行都是字段名称,不需要第一行字段名称,请对train.csv做数据预处理,删除第一行。
sed -i '1d' train.csv

2)接下来剔除掉train.csv中字段值部分字段值为空的数据。使用vim编辑器新建了一个predeal_train.sh脚本文件,请在这个脚本文件中加入下面代码:
#!/bin/bash
#下面设置输入文件,把用户执行predeal_train.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal_train.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在’这两个字符的后面
awk -F "," 'BEGIN
id=0;
if($1 && $2 && $3 && $4 && ($5!=-1))
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000)
exit
' $infile > $outfile

执行predeal_train.sh脚本文件,截取测试数据集需要预测的数据到train_after.csv,命令如下:
chmod +x ./predeal_train.sh
./predeal_train.sh ./train.csv ./train_after.csv
然后请在usr/local/dbtaobao/dataset目录下查看脚本与处理后的数据test_after.csv是否都在。

截取前十行看看。

8.数据集处理
1)启动Hadoop,在HDFS的根目录下面目录dbtaobao/dataset创建子目录,命令如下:
hadoop fs -mkdir -p /dbtaobao/dataset/test_log
hadoop fs -mkdir -p /dbtaobao/dataset/train_log
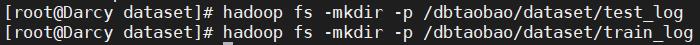
把Linux本地文件系统中的test_after.csv,train_after.csv上传到分布式文件系统HDFS的“/dbtaobao/dataset/ test_log”和“/dbtaobao/dataset/ train_log”目录下。
hadoop fs -put "/root/dbtaobao/dataset/test_after.csv" /dbtaobao/dataset/test_log
hadoop fs -put "/root/dbtaobao/dataset/train_after.csv" /dbtaobao/dataset/ train_log

查看一下HDFS中的test_after.csv,train_after.csv的前10条记录。
hadoop fs -cat /dbtaobao/dataset/test_log/test_after.csv | head -10
hadoop fs -cat /dbtaobao/dataset/train_log/train_after.csv | head -10

2)在hive中dbtaobao数据库中新建外部表test_log和train_log,并指向test_after.csv和train_after.csv,路径指定为:
‘/dbtaobao/dataset/test_log’和’/dbtaobao/dataset/train_log’。
--新建外部表test_log
create external table test_log(
user_id int,
age_range int,
gender int,
merchant_id int,
label int
)
row format delimited
fields terminated by ','
location '/dbtaobao/dataset/test_log';
--新建外部表train_log
create external table train_log(
user_id int,
age_range int,
gender int,
merchant_id int,
label int
)
row format delimited
fields terminated by ','
location '/dbtaobao/dataset/train_log';
查询两个表的前十行看是否已经有数据。
select * from test_log limit 10;
select * from train_log limit 10;

9.数据集分析
1)查询train_log中分别有多少回头客(买家不重复计算)。(556)
select count(distinct user_id) from train_log where label=1;

2)在train_log表中,按照商家id分类,查询每一个不同商家被回头客选择的次数,按照次数升序排序,找出回头客最喜欢买的商家ID。
select merchant_id,count(distinct user_id) a from train_log where label=1 group by merchant_id order by a asc;


(截取部分),598
3)分析train_log表中按照年龄段分类,每个年龄段的回头客分别是多少。
select age_range,count(distinct user_id) from train_log where label=1 group by age_range order by age_range asc;

4)请根据表user_log和train_log,查询回头客都买了哪些商品?商品号升序展示。
select t1.user_id,t1.item_id from user_log t1 full join (select * from train_log where label=1) t2 on t1.user_id=t2.user_id order by t1.item_id asc;

5)请查询联合查询union的用法,联合查询表user_log和train_log中的用户id,商家id,按照用户id排序,取前15行。
select user_id, merchant_id from user_log union select user_id, merchant_id from train_log order by user_id limit 15;

10.数据集分析的函数应用
1)在hive中查看系统自带的函数(提示:functions)。
show functions;

2)统计user_log表中前10行收获地址的字符串长度(提示length(province))。
select length(province) from user_log limit 10;

3)截取user_log表中前10行的收获地址,显示收获地址从第二位字符到最后。(提示:substr(province,2))
select substr(province,2) from user_log limit 10;

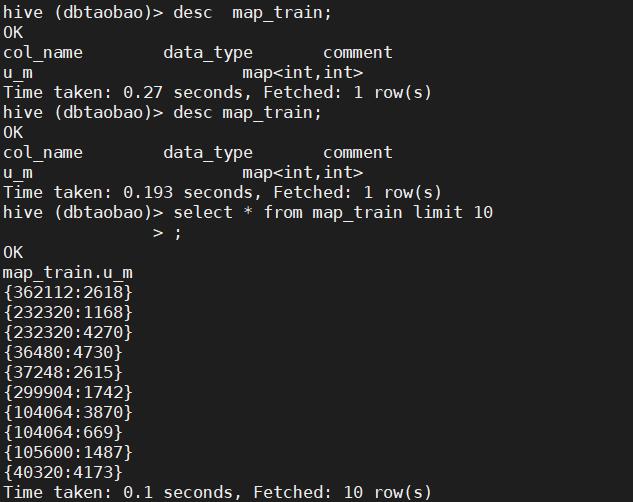
4)建立一个新表map_train, 把train_log中的user_id和merchant_id 通过map函数整合成表map_train中的一个map类型的字段u_m,并传入数据。检查map_train的结构和前十行数据。
--建立一个新表map_train
create table map_train(u_m map<int,int>)
row format delimited
map keys terminated by ':';
--传入数据
insert into map_train select map(user_id,merchant_id) from train_log;
--检查map_train的结构和前十行数据
desc map_train;
select * from map_train limit 10;


11.数据集分区处理
1)建立内部分区表train_log_par, user_id INT,gender INT,merchant_id INT,label INT,以age int分区,每个字段之间由’,'分割。
create table train_log_par(
user_id INT,
gender INT,
merchant_id INT,
label INT
) partitioned by (age int)
row format delimited
fields terminated by ',';

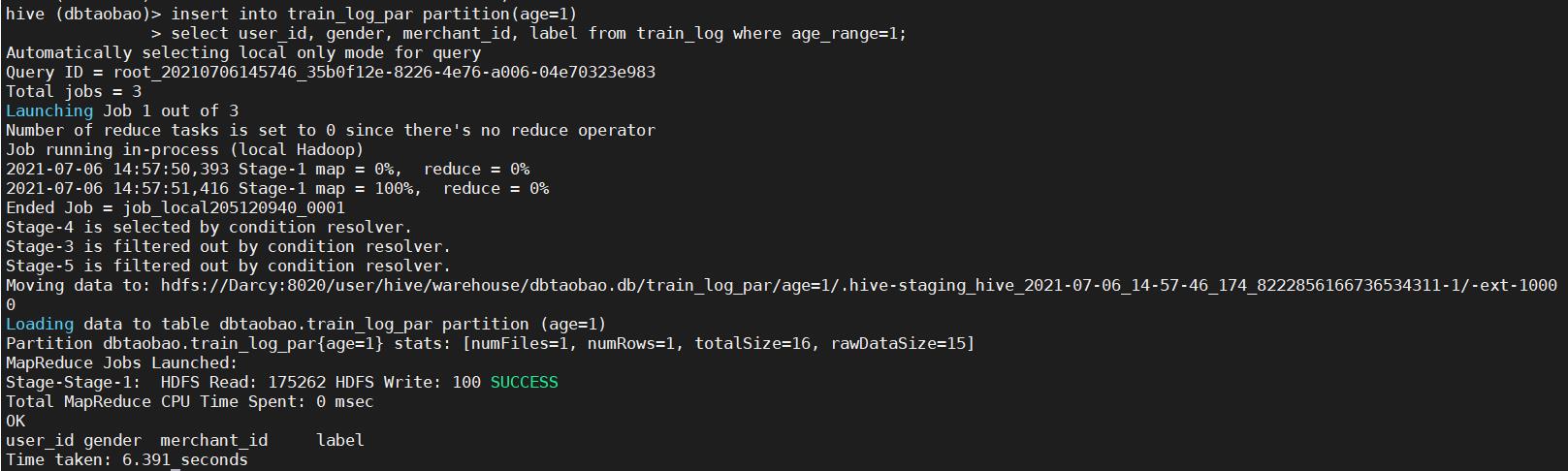
2)从train_log表中将买家id,性别,商家id,是否是回头客和age_range=1的数据插入到train_log分区表age=1中。
insert into train_log_par partition(age=1)
select user_id, gender, merchant_id, label from train_log where age_range=1;

3)为train_log_par增加分区:age=2,age=3,age=4,age=5,age=6,age=7,age=8(提示:alter…add)
alter table train_log_par add partition(age=2);
alter table train_log_par add partition(age=3);
alter table train_log_par add partition(age=4);
alter table train_log_par add partition(age=5);
alter table train_log_par add partition(age=6);
alter table train_log_par add partition(age=7);
alter table train_log_par add partition(age=8);

4)分别从train_log表中将买家id,性别,商家id,是否是回头客和age_range=2,age_range=3,age_range=4,age_range=5,age_range=6,age_range=7,age_range=8的数据插入到train_log分区表age=1中。
insert into train_log_par partition(age=2) select user_id, gender, merchant_id, label from train_log where age_range=2;
insert into train_log_par partition(age=3) select user_id, gender, merchant_id, label from train_log where age_range=3;
insert into train_log_par partition(age=4) select user_id, gender, merchant_id, label from train_log where age_range=4;
insert into train_log_par partition(age=5) select user_id, gender, merchant_id, label from train_log where age_range=5;
insert into train_log_par partition(age=6) select user_id, gender, merchant_id, label from train_log where age_range=6;
insert into train_log_par partition(age=7) select user_id, gender, merchant_id, label from train_log where age_range=7;
insert into train_log_par partition(age=8) select user_id, gender, merchant_id, label from train_log where age_range=8;

以上是关于大数据仓库技术实训任务3的主要内容,如果未能解决你的问题,请参考以下文章