07-leveldb性能优化
Posted anda0109
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了07-leveldb性能优化相关的知识,希望对你有一定的参考价值。
1-Compaction:清除冗余数据,减少磁盘IO
Compaction为什么能提升查询性能,我们从leveldb的原理说起。
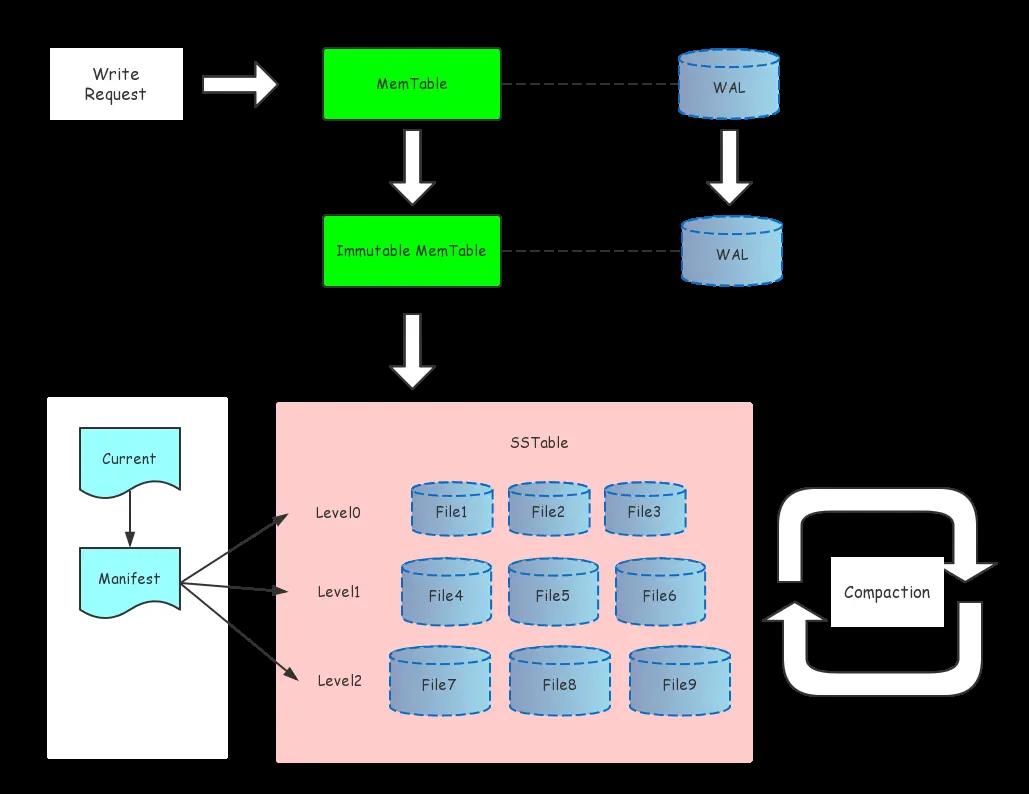
如图所示,数据写入leveldb的过程如下:
- 数据写入Memtable
- Memtable达到一定大小后变为Immutable Memtable
- Immutable Memtable通过Minor Compaction写入0层SSTable
数据读取流程如下:
- 从Memtable中查询;
- 从Immutable Memtable中查询;
- 遍历level 0所有文件,若未查找到,进入下一层查找
- 若未查找到,继续往下一层查询,直到查到为止或返回not found
由上述读取的流程可知,如果在level 0至level n中存在较多冗余数据,则会导致查询较多的文件,即进行多次无效的IO操作。而Compaction正是清理冗余数据的主要过程。leveldb中内置了多种compaction触发策略:
- 当每层文件数或文件大小达到阈值后,触发向下一层的compaction
- 当某个文件被查找但未找到目标值的次数达到1024次后,该文件被触发compaction
同时,我们也可以依据自己业务的特点,制定合适的触发策略。例如在业务低峰期触发,或者针对含有大量删除的范围进行compact,来及时清除冗余数据,从而提升查询性能。
2-布隆过滤器:减少无效磁盘IO
由于leveldb是按范围索引,如果某个key落在某个Block的范围内,则这个Block中可能存在这个数据,也可能不存在。如果没有其他方法,我们只能把这个Block读取出来查找一遍才放心。有没有方法做一个快速判断,如果这个Block不存在我要查找的key,就不要去读磁盘IO了?leveldb为我们提供了布隆过滤器来完成这个目的。使用布隆过滤器的方法如下:
leveldb::Options options;
options.filter_policy = NewBloomFilterPolicy(10);
leveldb::DB* db;
leveldb::DB::Open(options, "/tmp/testdb", &db);
... use the database ...
delete db;
delete options.filter_policy;
NewBloomFilterPolicy的参数是表示每个key用多少位表示,官方推荐值是10,即在此时过滤器的准确率较高。
布隆过滤器是怎么工作的呢?
2.1-字符串存入bitmap中
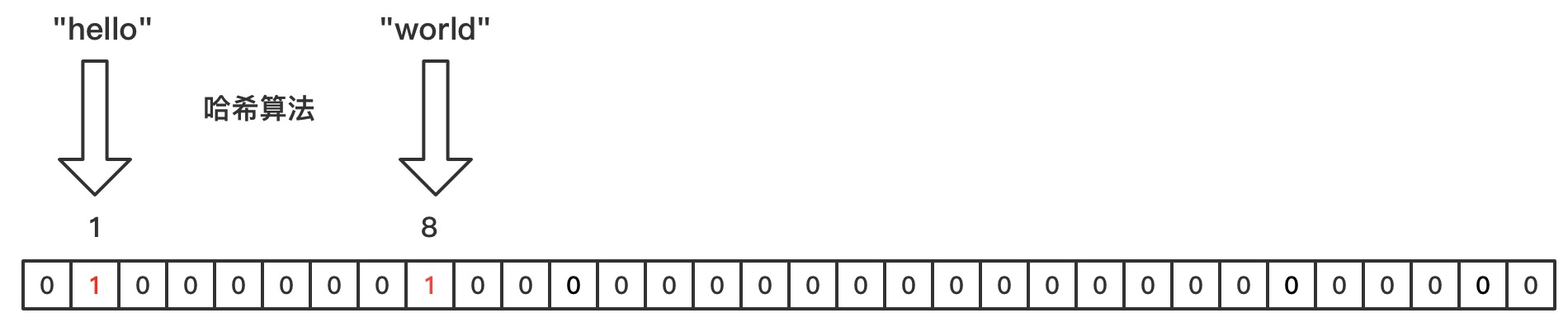
布隆过滤器是一个位图加多个Hash函数组成的一种数据结构,用于快速定位某个数据是否存在。
如下图所示,hello和world的Hash值分别为1和8,则将第1、8位置为1。当我们查询hello和world是否存在时,只需要计算hello和world的hash值,得到结果是1和8,然后在位图中查找这两个位置的值是否为1,如果为1,则存在,若不为1,则不存在。
2.2-Hash碰撞问题
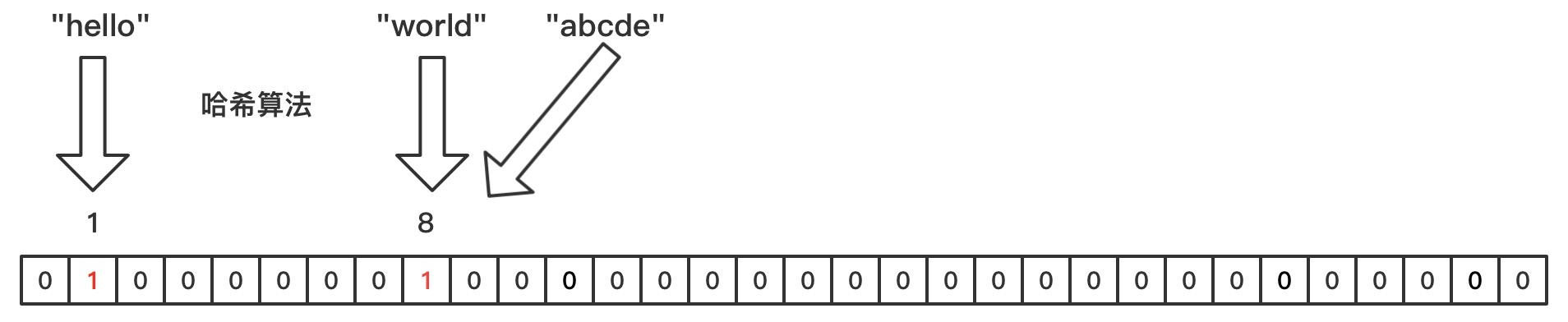
接着上面的问题,当我们要查询abcde是否存在时,首先计算abcde的hash值,abcde的hash值也是8。当我们校验位图时,发现这个数据是存在的,但真实情况却不存在。我们把两个不同数据hash值相同的情况称为Hash碰撞。因此在存在Hash碰撞的情况下,当我们通过位图查询是存在的时候,要查询的值也可能不存在。
2.3-Hash碰撞问题的优化
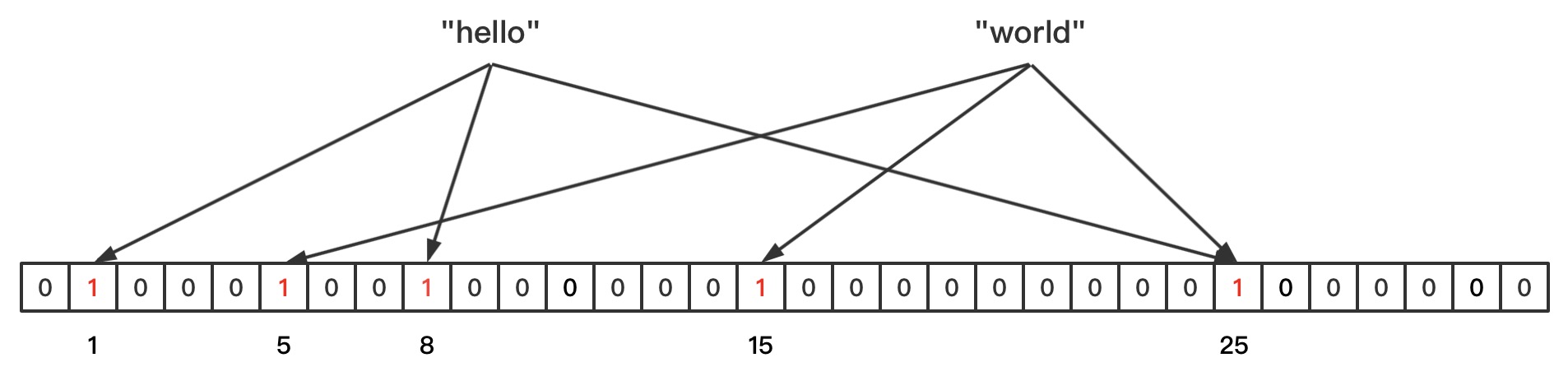
由于Hash碰撞的问题,导致过滤器存在较大的误判率。为了减少上述Hash碰撞的问题,我们通过使用多个Hash函数来减少碰撞的概率。如图字符串hello通过三个Hash函数计算出来的值分别为1、8、25,world计算出来的值为5、15、25,虽然25发生了碰撞,但通过检查三个Hash值,如果都存在则证明数据可能存在,如果某一个hash值不存在,则证明这个值一定不存在。
因此,布隆过滤器的功能如下:
- 布隆过滤器的本质是一个很长的位数组和一系列随机映射哈希函数
- 布隆过滤器判断存在的数据可能存在,布隆过滤器判断不存在的数据肯定不存在;
- 实际存在的数据布隆过滤器肯定判断存在,实际不存在的数据布隆过滤器可能会判断存在。
3-缓存:从内存读取,绕过磁盘IO
3.1-块缓存
leveldb提供了块缓存功能,用以缓存最近查询的数据所在的块,数据块以非压缩的方式缓存。leveldb中使用块缓存的方式如下:
#include "leveldb/cache.h"
leveldb::Options options;
options.block_cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache
leveldb::DB* db;
leveldb::DB::Open(options, name, &db);
... use the db ...
delete db
delete options.block_cache;
块缓存的大小可以进行指定,依据设备可使用的内存情况进行配置,理论上块缓存配置越大,性能越好。
块缓存的淘汰机制使用的LRU。LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
3.2-Table缓存
TableCache缓存了table的基本信息数据,包括table的index block、filter block(如果有),当读取到相应的key数据时,会首先通过index block判断是存在于哪个block,然后再通过相应block的filter来判断key是否存在,决定是否读取对应的data block。
3.3-行缓存
虽然已经有了块缓存,但由于块缓存是缓存了查询的某个数据所在的块,缓存命中率并不一定高。并且当compacion发生后,对应的块缓存也将失效。
我们可以根据业务情况,将查询的行数据进行缓存。这样不仅可以减少缓存的大小,而且可以根据业务缓存真正需要的数据,提高缓存的命中率。
4-总结
本文介绍了优化leveldb查询性能的三种方法:通过compaction清除冗余数据,减少磁盘IO;通过布隆过滤器,避免无效IO;通过缓存,绕过磁盘IO。在使用的过程中,可以根据具体的业务情况来采取合适的措施,以达到最优性能。
以上是关于07-leveldb性能优化的主要内容,如果未能解决你的问题,请参考以下文章