手撕 CNN 经典网络之 AlexNet(理论篇)
Posted 红色石头Will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手撕 CNN 经典网络之 AlexNet(理论篇)相关的知识,希望对你有一定的参考价值。
大家好,我是红色石头!
第一个典型的CNN是LeNet5网络,而第一个大放异彩的CNN却是AlexNet。2012年在全球知名的图像识别竞赛 ILSVRC 中,AlexNet 横空出世,直接将错误率降低了近 10 个百分点,这是之前所有机器学习模型无法做到的。

AlexNet的作者是多伦多大学的Alex Krizhevsky等人。Alex Krizhevsky是Hinton的学生。网上流行说 Hinton、LeCun和Bengio是神经网络领域三巨头,LeCun就是LeNet5的作者(Yann LeCun)。
在正式介绍AlexNet之前,简单讲一下该网络是用来干嘛的。AlexNet跟LeNet-5类似也是一个用于图像识别的卷积神经网络。AlexNet网络结构更加复杂,参数更多。在ILSVRC比赛中,AlexNet所用的数据集是ImageNet,总共识别1000个类别。
论文《ImageNet Classification with Deep Convolutional Neural Networks》
论文传送门:
http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
1. 网络结构
AlexNet整体的网络结构包括:1个输入层(input layer)、5个卷积层(C1、C2、C3、C4、C5)、2个全连接层(FC6、FC7)和1个输出层(output layer)。下面对网络结构详细介绍。

上面这张图就是AlexNet的网络结构。初看这张图有的读者可能会觉得有个疑问:网络上部分是不是没有画完?其实不是的。鉴于当时的硬件资源限制,由于AlexNet结构复杂、参数很庞大,难以在单个GPU上进行训练。因此AlexNet采用两路GTX 580 3GB GPU并行训练。也就是说把原先的卷积层平分成两部分FeatureMap分别在两块GPU上进行训练(例如卷积层55x55x96分成两个FeatureMap:55x55x48)。上图中上部分和下部分是对称的,所以上半部分没有完全画出来。
值得一提的是,卷积层 C2、C4、C5中的卷积核只和位于同一GPU的上一层的FeatureMap相连,C3的卷积核与两个GPU的上一层的FeautureMap都连接。
1.1 输入层(Input layer)
原论文中,AlexNet的输入图像尺寸是224x224x3。但是实际图像尺寸为227x227x3。据说224x224可能是写paper时候的手误?还是后来对网络又做了调整?
1.2 卷积层(C1)
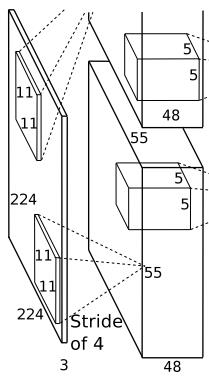
该层的处理流程是:卷积-->ReLU-->局部响应归一化(LRN)-->池化。
卷积:输入是227x227x3,使用96个11x11x3的卷积核进行卷积,padding=0,stride=4,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(227+2*0-11)/4+1=55,得到输出是55x55x96。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
局部响应归一化:局部响应归一化层简称LRN,是在深度学习中提高准确度的技术方法。一般是在激活、池化后进行。LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN的公式如下:

a为归一化之前的神经元,b为归一化之后的神经元;N是卷积核的个数,也就是生成的FeatureMap的个数;k,α,β,n是超参数,论文中使用的值是k=2,n=5,α=0.0001,β=0.75。
局部响应归一化的输出仍然是55x55x96。将其分成两组,每组大小是55x55x48,分别位于单个GPU上。
池化:使用3x3,stride=2的池化单元进行最大池化操作(max pooling)。注意这里使用的是重叠池化,即stride小于池化单元的边长。根据公式:(55+2*0-3)/2+1=27,每组得到的输出为27x27x48。
1.3 卷积层(C2)
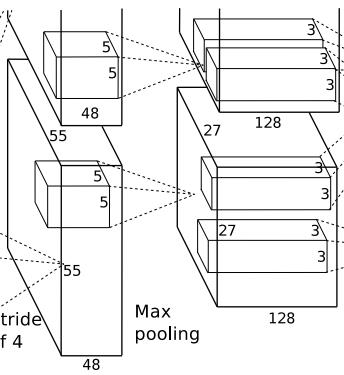
该层的处理流程是:卷积-->ReLU-->局部响应归一化(LRN)-->池化。
卷积:两组输入均是27x27x48,各组分别使用128个5x5x48的卷积核进行卷积,padding=2,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(27+2*2-5)/1+1=27,得到每组输出是27x27x128。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
局部响应归一化:使用参数k=2,n=5,α=0.0001,β=0.75进行归一化。每组输出仍然是27x27x128。
池化:使用3x3,stride=2的池化单元进行最大池化操作(max pooling)。注意这里使用的是重叠池化,即stride小于池化单元的边长。根据公式:(27+2*0-3)/2+1=13,每组得到的输出为13x13x128。
1.4 卷积层(C3)

该层的处理流程是: 卷积-->ReLU
卷积:输入是13x13x256,使用384个3x3x256的卷积核进行卷积,padding=1,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到输出是13x13x384。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。将输出其分成两组,每组FeatureMap大小是13x13x192,分别位于单个GPU上。
1.5 卷积层(C4)
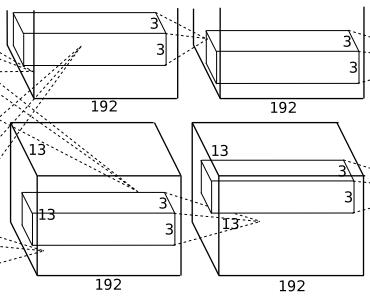
该层的处理流程是:卷积-->ReLU
卷积:两组输入均是13x13x192,各组分别使用192个3x3x192的卷积核进行卷积,padding=1,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到每组FeatureMap输出是13x13x192。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
1.6 卷积层(C5)
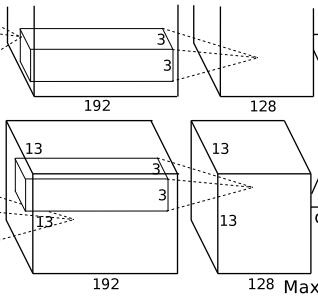
该层的处理流程是:卷积-->ReLU-->池化
卷积:两组输入均是13x13x192,各组分别使用128个3x3x192的卷积核进行卷积,padding=1,stride=1,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到每组FeatureMap输出是13x13x128。
ReLU:将卷积层输出的FeatureMap输入到ReLU函数中。
池化:使用3x3,stride=2的池化单元进行最大池化操作(max pooling)。注意这里使用的是重叠池化,即stride小于池化单元的边长。根据公式:(13+2*0-3)/2+1=6,每组得到的输出为6x6x128。
1.7 全连接层(FC6)

该层的流程为:(卷积)全连接 -->ReLU -->Dropout (卷积)
全连接:输入为6×6×256,使用4096个6×6×256的卷积核进行卷积,由于卷积核尺寸与输入的尺寸完全相同,即卷积核中的每个系数只与输入尺寸的一个像素值相乘一一对应,根据公式:(input_size + 2 * padding - kernel_size) / stride + 1=(6+2*0-6)/1+1=1,得到输出是1x1x4096。既有4096个神经元,该层被称为全连接层。
ReLU:这4096个神经元的运算结果通过ReLU激活函数中。
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。4096个神经元也被均分到两块GPU上进行运算。
1.8 全连接层(FC7)

该层的流程为:(卷积)全连接 -->ReLU -->Dropout
全连接:输入为4096个神经元,输出也是4096个神经元(作者设定的)。
ReLU:这4096个神经元的运算结果通过ReLU激活函数中。
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。
4096个神经元也被均分到两块GPU上进行运算。
1.9 输出层(Output layer)
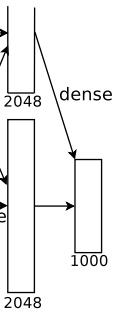
该层的流程为:(卷积)全连接 -->Softmax
全连接:输入为4096个神经元,输出是1000个神经元。这1000个神经元即对应1000个检测类别。
Softmax:这1000个神经元的运算结果通过Softmax函数中,输出1000个类别对应的预测概率值。
2. 网络参数
2.1 AlexNet神经元数量
层数 | 定义 | 数量 |
C1 | C1层的FeatureMap的神经元个数 | 55x55x48x2=290400 |
C2 | C2层的FeatureMap的神经元个数 | 27x27x128x2=186624 |
C3 | C3层的FeatureMap的神经元个数 | 13x13x192x2=64896 |
C4 | C4层的FeatureMap的神经元个数 | 13x13x192x2=64896 |
C5 | C5层的FeatureMap的神经元个数 | 13x13x128x2=43264 |
FC6 | FC6全连接层神经元个数 | 4096 |
FC7 | FC7全连接层神经元个数 | 4096 |
Output layer | 输出层神经元个数 | 1000 |
整个AlexNet网络包含的神经元个数为:
290400 + 186624 + 64896 + 64896 + 43264 + 4096 + 4096 + 1000 = 659272
大约65万个神经元。
2.2 AlexNet参数数量
层数 | 定义 | 数量 |
C1 | 卷积核11x11x3,96个卷积核,偏置参数 | (11x11x3+1)x96=34944 |
C2 | 卷积核5x5x48,128个卷积核,2组,偏置参数 | (5x5x48+1)x128x2=307456 |
C3 | 卷积核3x3x256,384个卷积核,偏置参数 | (3x3x256+1)x384=885120 |
C4 | 卷积核3x3x192,192个卷积核,2组,偏置参数 | (3x3x192+1)x192x2=663936 |
C5 | 卷积核3x3x192,128个卷积核,2组,偏置参数 | (3x3x192+1)x128x2=442624 |
FC6 | 卷积核6x6x256,4096个神经元,偏置参数 | (6x6x256+1)x4096=37752832 |
FC7 | 全连接层,4096个神经元,偏置参数 | (4096+1)x4096=16781312 |
Output layer | 全连接层,1000个神经元 | 1000x4096=4096000 |
整个AlexNet网络包含的参数数量为:
34944 + 307456 + 885120 + 663936 + 442624 + 37752832 + 16781312 + 4096000 = 60964224
大约6千万个参数。
设定每个参数是32位浮点数,每个浮点数4个字节。这样参数占用的空间为:
60964224 x 4 = 243856896(Byte) = 238141.5(Kb) = 232.56(Mb)
参数共占用了大约232Mb的空间。
2.3 FLOPs
FLOPS(即“每秒浮点运算次数”,“每秒峰值速度”),是“每秒所执行的浮点运算次数”(floating-point operations per second)的缩写。它常被用来估算电脑的执行效能,尤其是在使用到大量浮点运算的科学计算领域中。正因为FLOPS字尾的那个S,代表秒,而不是复数,所以不能省略掉。
一个MFLOPS(megaFLOPS)等于每秒一佰万(=10^6)次的浮点运算,
一个GFLOPS(gigaFLOPS)等于每秒十亿(=10^9)次的浮点运算,
一个TFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算,(1太拉)
一个PFLOPS(petaFLOPS)等于每秒一千万亿(=10^15)次的浮点运算,
一个EFLOPS(exaFLOPS)等于每秒一佰京(=10^18)次的浮点运算。
在AlexNet网络中,对于卷积层,FLOPS=num_params∗(H∗W)。其中num_params为参数数量,H*W为卷积层的高和宽。对于全连接层,FLOPS=num_params。
层数 | 定义 | 数量 |
C1 | num_params∗(H∗W) | 34944x55x55=105705600 |
C2 | num_params∗(H∗W) | 307456x27x27=224135424 |
C3 | num_params∗(H∗W) | 885120x13x13=149585280 |
C4 | num_params∗(H∗W) | 663936x13x13=112205184 |
C5 | num_params∗(H∗W) | 442624x13x13=74803456 |
FC6 | num_params | 37752832 |
FC7 | num_params | 16781312 |
Output layer | num_params | 4096000 |
AlexNet整体的网络结构,包含各层参数个数、FLOPS如下图所示:

3. AlexNet创新之处
3.1 Data Augmentation
在本文中,作者采用了两种数据增强(data augmentation)方法,分别是:
镜像反射和随机剪裁
改变训练样本RGB通道的强度值
镜像反射和随机剪裁的做法是,先对图像做镜像反射:

然后在原图和镜像反射的图(256×256)中随机裁剪227×227的区域:

测试的时候,对左上、右上、左下、右下、中间分别做了5次裁剪,然后翻转,共10个裁剪,之后对结果求平均。
改变训练样本RGB通道的强度值,做法是对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
3.2 激活函数ReLU
在当时,标准的神经元激活函数是tanh()函数,这种饱和的非线性函数在梯度下降的时候要比非饱和的非线性函数慢得多,因此,在AlexNet中使用ReLU函数作为激活函数。

ReLU函数是一个分段线性函数,小于等于0则输出0;大于0的则恒等输出。反向传播中,ReLU有输出的部分,导数始终为1。而且ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
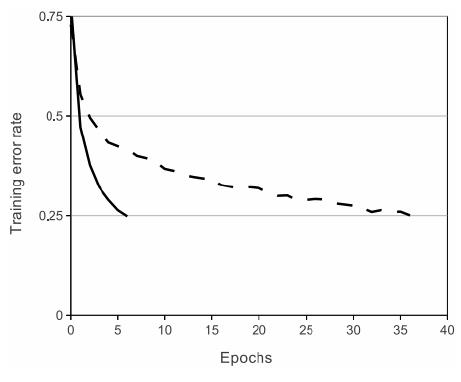
下图展示了在一个4层的卷积网络中使用ReLU函数在CIFAR-10数据集上达到25%的训练错误率要比在相同网络相同条件下使用tanh函数快6倍。(黑实线是使用ReLU激活函数,黑虚线是使用tanh激活函数)
3.3 局部响应归一化
局部响应归一化(LRN)对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
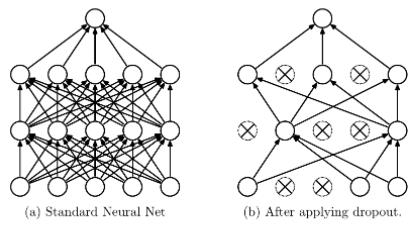
3.4 Dropout Dropout
是神经网络中比较常用的抑制过拟合的方法。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
在AlexNet网络中,全连接层FC6、FC7就使用了Dropout方法。
Dropout应该算是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。
3.5 重叠池化
在以前的CNN中普遍使用平均池化层(average pooling),AlexNet全部使用最大池化层 max pooling。避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。
3.6 双GPU训练
受当时硬件水平限制,AlexNet训练作者使用了双GPU,这是工程上的一种创新做法。双GPU网络的训练时间比单GPU网络更少,分别将top-1和top-5错误率分别降低了1.7%和1.2%。
3.7 端到端训练
AlexNet网络,CNN的输入直接是一张图片,而当时比较多的做法是先使用特征提取算法对RGB图片进行特征提取。AlexNet使用了端对端网络,除了将每个像素中减去训练集的像素均值之外,没有以任何其他方式对图像进行预处理,直接使用像素的RGB值训练网络。
手撕 CNN 系列:
手撕 CNN 经典网络之 LeNet-5(MNIST 实战篇)
手撕 CNN 经典网络之 LeNet-5(CIFAR10 实战篇)
如果觉得这篇文章有用的话,麻烦点个在看或转发朋友圈!
推荐阅读
(点击标题可跳转阅读)
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 
以上是关于手撕 CNN 经典网络之 AlexNet(理论篇)的主要内容,如果未能解决你的问题,请参考以下文章