flink sql clinet 实战:upsert kafka connector -- flink-1.12
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink sql clinet 实战:upsert kafka connector -- flink-1.12相关的知识,希望对你有一定的参考价值。
文章目录
前言
在某些场景中,比方GROUP BY聚合之后的后果,须要去更新之前的结果值。这个时候,须要将 Kafka 音讯记录的 key 当成主键解决,用来确定一条数据是应该作为插入、删除还是更新记录来解决。在Flink1.11中,能够通过 flink-cdc-connectors 项目提供的 changelog-json format 来实现该性能。
在Flink1.12版本中, 新增了一个 upsert connector(upsert-kafka),该 connector 扩大自现有的 Kafka connector,工作在 upsert 模式(FLIP-149)下。新的 upsert-kafka connector 既能够作为 source 应用,也能够作为 sink 应用,并且提供了与现有的 kafka connector 雷同的基本功能和持久性保障,因为两者之间复用了大部分代码。
一、upsert kafka connector
本文将以Flink1.12为例,介绍该性能的根本应用步骤,以下是全文,心愿对你有所帮忙。
Upsert Kafka Connector容许用户以upsert的形式从Kafka主题读取数据或将数据写入Kafka主题。
作为 Source ,upsert-kafka Connector 会生产一个 changelog 流,其中每条数据记录都示意一个更新或删除事件。更精确地说,如果不存在对应的key,则视为 INSERT 操作。如果曾经存在了绝对应的key,则该key对应的value值为最初一次更新的值。
用表来类比,changelog 流中的数据记录被解释为 UPSERT,也称为 INSERT/UPDATE,因为任何具备雷同 key 的现有行都被覆盖。另外,value 为空的记录将会被视作为 DELETE 音讯。
作为 Sink ,upsert-kafka Connector 会生产一个 changelog 流。它将 INSERT / UPDATE_AFTER 数据作为争产的 Kafka 消息值写入(即 INSERT 和 UPDATE 操作,都会进行正常写入,如果是更新,则同一个 key 会存储多条数据,但在读取该表数据时,只保留最初一次更新的值),并将 DELETE 数据以 value 为空的 Kafka 记录写入( key 被打上墓碑标记,示意对应 key 的消息被删除)。Flink 将依据主键列的值对数据进行分区,从而保障主键上的记录有序,因而同一主键上的更新/删除的记录将落在同一分区中。
二、案例
2.1、计算pv、uv 插入 upsert-kafka sink
1、模拟数据
package com.chb.flink.combat.ch1
import org.apache.kafka.clients.producer.KafkaProducer, ProducerConfig, ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
import java.time.LocalDateTime
import java.time.format.DateTimeFormatter
import java.util.Properties, Random
/**
* 造模拟数据
*/
object MockData2Kafka2
def main(args: Array[String]): Unit =
val users = Array(1, 2, 3, 4, 5, 6)
val pageIds = Array(1001, 1002, 1003, 1004)
val userRegions = Array(10001, 10002, 10003, 10004)
val kafkaProps = new Properties()
kafkaProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "chb1:6667")
kafkaProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
kafkaProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
val producer = new KafkaProducer[String, String](kafkaProps)
val topic = "pageviews"
val random = new Random()
while (true)
val value = users(random.nextInt(users.length)) + "," + pageIds(random.nextInt(pageIds.length)) + "," +
LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")) + "," +
userRegions(random.nextInt(userRegions.length))
producer.send(new ProducerRecord[String, String](topic, value))
Thread.sleep(300)
2、数据源 kafka
-- 数据源
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP(3),
user_region STRING,
WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'pageviews',
'properties.bootstrap.servers' = 'chb1:6667',
'format' = 'csv',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset' -- 从起始 offset 开始读取
);
3、upsert-kafka sink
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED -- 设置主键
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = 'chb1:6667',
'key.format' = 'csv',
'value.format' = 'csv'
);
4、计算插入 upsert kakfa sink
INSERT INTO pageviews_per_region
SELECT
user_region,
COUNT(*),
COUNT(DISTINCT user_id)
FROM pageviews
GROUP BY user_region;
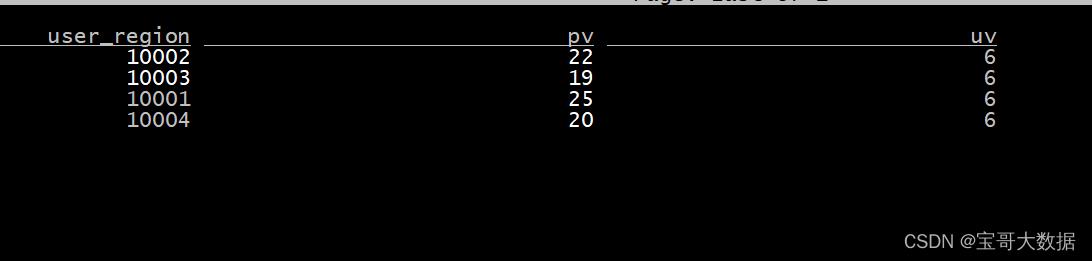
记住DDL语句中,一定要设置主键Primary key。
上面的pageviews_per_region表中计算的pv,uv结果就是统计结果,当数据源端进行了增删改,对应的pv uv结果就会同步更新,这就是upsert kafka的魅力。
这是基于kafka的统计计算,前提条件是topic pageviews中的数据是changelog格式的。
changelog格式数据怎么来,怎么导入kafka,还有upsert到mysql、hbase呢,且看下回分解。
二、特性
Key and Value Formats
See the regular Kafka connector for more explanation around key and value formats. However, note that this connector requires both a key and value format where the key fields are derived from the PRIMARY KEY constraint.
The following example shows how to specify and configure key and value formats. The format options are prefixed with either the ‘key’ or ‘value’ plus format identifier.
CREATE TABLE KafkaTable (
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
PRIMARY KEY (`user_id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
...
'key.format' = 'json',
'key.json.ignore-parse-errors' = 'true',
'value.format' = 'json',
'value.json.fail-on-missing-field' = 'false',
'value.fields-include' = 'EXCEPT_KEY'
)
主键约束
Upsert Kafka 始终以 upsert 方式工作,并且需要在 DDL 中定义主键。在具有相同主键值的消息按序存储在同一个分区的前提下,在 changlog source 定义主键意味着 在物化后的 changelog 上主键具有唯一性。定义的主键将决定哪些字段出现在 Kafka 消息的 key 中。
一致性保证
默认情况下,如果启用 checkpoint,Upsert Kafka sink 会保证至少一次将数据插入 Kafka topic。
这意味着,Flink 可以将具有相同 key 的重复记录写入 Kafka topic。但由于该连接器以 upsert 的模式工作,该连接器作为 source 读入时,可以确保具有相同主键值下仅最后一条消息会生效。因此,upsert-kafka 连接器可以像 HBase sink 一样实现幂等写入。
为每个分区生成相应的 watermark
Flink 支持根据 Upsert Kafka 的 每个分区的数据特性发送相应的 watermark。当使用这个特性的时候,watermark 是在 Kafka consumer 内部生成的。 合并每个分区 生成的 watermark 的方式和 stream shuffle 的方式是一致的。 数据源产生的 watermark 是取决于该 consumer 负责的所有分区中当前最小的 watermark。如果该 consumer 负责的部分分区是 idle 的,那么整体的 watermark 并不会前进。在这种情况下,可以通过设置合适的 table.exec.source.idle-timeout 来缓解这个问题。
如想获得更多细节,请查阅 Kafka watermark strategies.
数据类型映射
Upsert Kafka 用字节存储消息的 key 和 value,因此没有 schema 或数据类型。消息按格式进行序列化和反序列化,例如:csv、json、avro。因此数据类型映射表由指定的格式确定。请参考格式页面以获取更多详细信息。
参考:
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/table/upsert-kafka/
以上是关于flink sql clinet 实战:upsert kafka connector -- flink-1.12的主要内容,如果未能解决你的问题,请参考以下文章