人工智能基础入门——神经网络讲解
Posted 无乎648
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能基础入门——神经网络讲解相关的知识,希望对你有一定的参考价值。
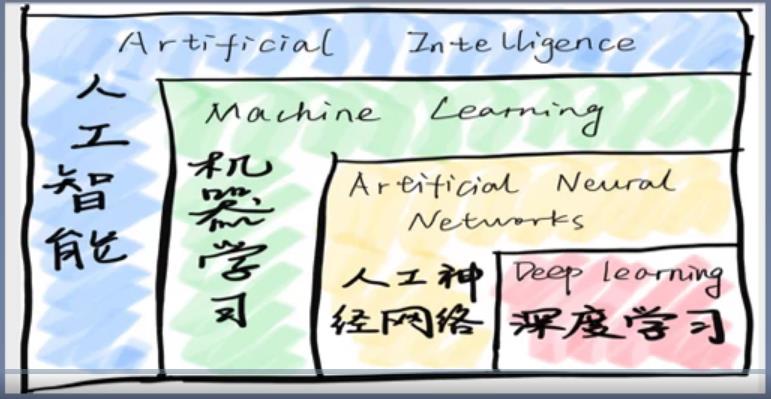
1、人工神经元
人类神经元中抽象出来的数学模型

树突:input
细胞核:处理操作+激活函数
轴突末梢:输出
f(
∑
i
=
1
N
I
i
⋅
W
i
\\sum_i=1^N I_i\\cdot W_i
∑i=1NIi⋅Wi)=y
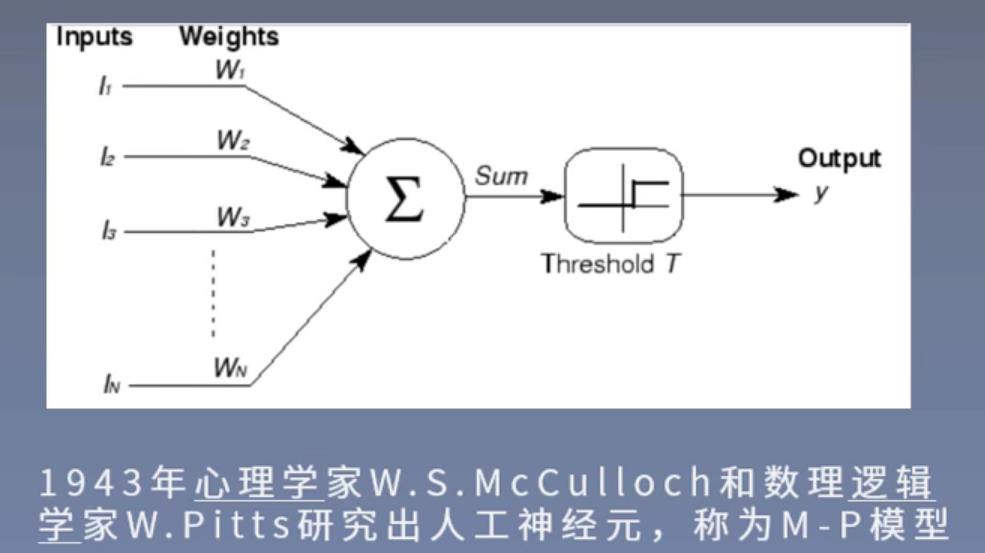
人工神经网络:大量的神经元以某种连接方式构成的机器学习模型。
第一个神经网络:1958年,计算机科学家Rosenblatt提出的Perceptron(感知机)
o=
σ
\\sigma
σ((<w,x>+b)) b是指偏执项
if x>0
σ
\\sigma
σ=1 else
σ
\\sigma
σ=0
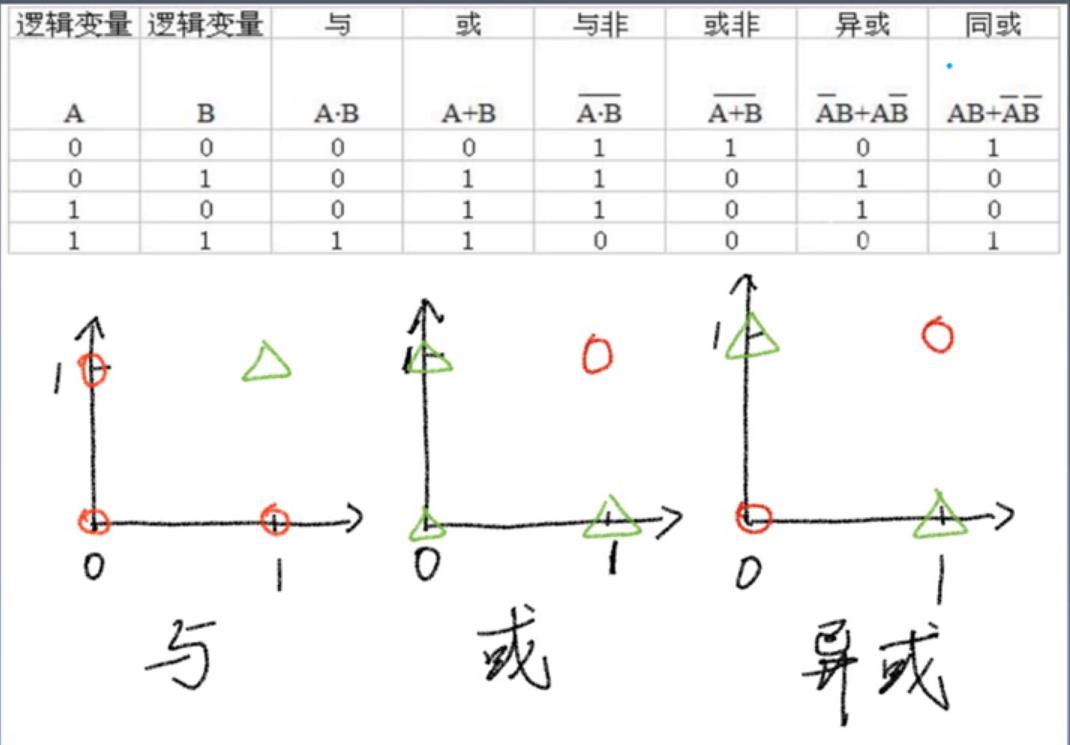
感知机致命缺点:Minsky在1969年证明Perceptron无法解决异或问题。
σ
\\sigma
σ(
X
0
X_0
X0
W
0
W_0
W0+
X
1
X_1
X1
W
1
W_1
W1+b)=0
X
1
X_1
X1=-
W
0
W_0
W0/
W
1
W_1
W1+o/
W
1
W_1
W1-b/
W
1
W_1
W1
所以是一个直线,不能解决异或问题,导致了第一次人工智能发展衰落。
2、多层感知机
多层感知机(Multi Layer Perceptron,MLP):单层神经网络基础上引入一个或多个隐藏层,使神经网络有多个网络层,因而得名多层感知机。
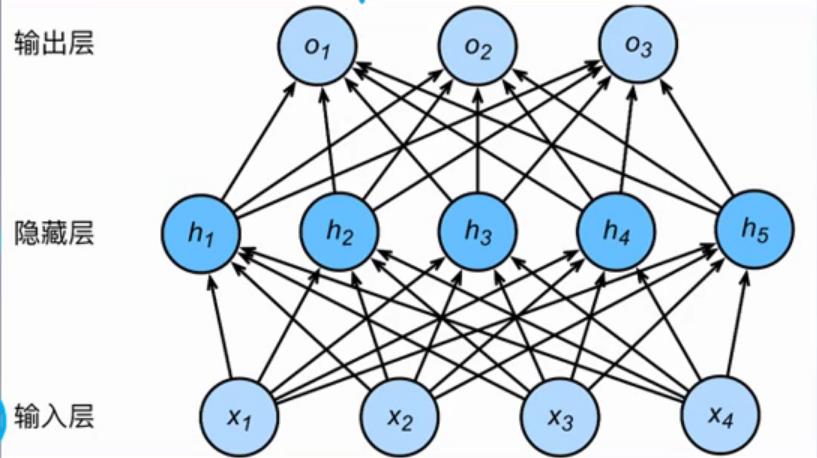
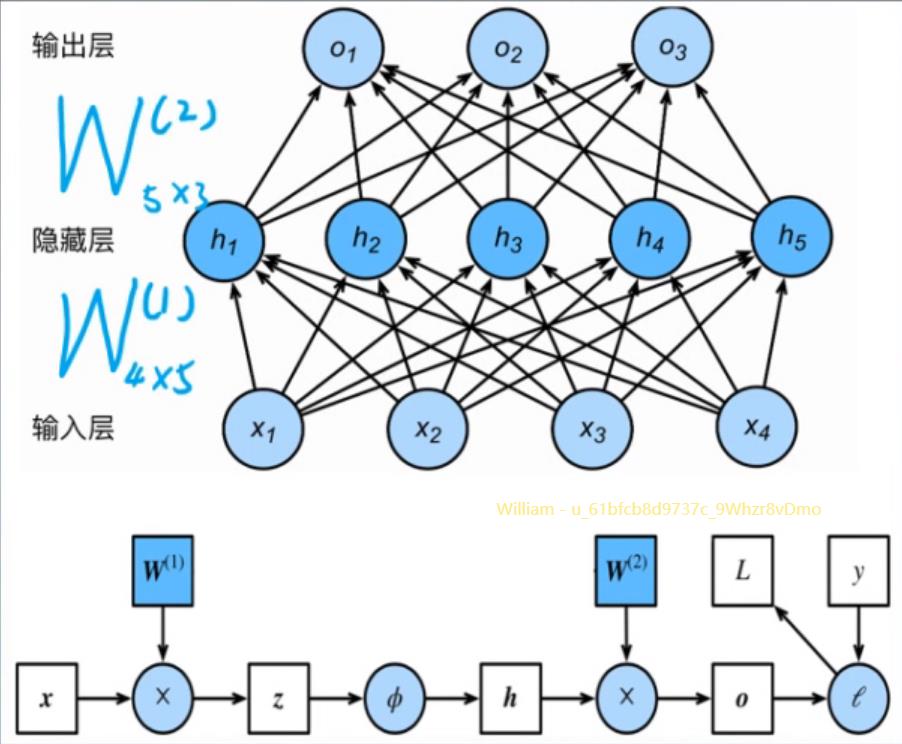
输入就是
W
4
×
5
W_4×5
W4×5
隐藏层输出
W
5
×
3
W_5×3
W5×3
前向传播:
σ
(
X
1
×
4
⋅
W
h
)
=
H
1
×
5
\\sigma(X_1×4\\cdotW_h)=H_1×5
σ(X1×4⋅Wh)=H1×5
σ
(
H
1
×
5
⋅
W
o
5
×
3
)
=
O
1
×
3
\\sigma(H_1×5\\cdotW_o5×3)=O_1×3
σ(H1×5⋅Wo5×3)=O1×3
如果没有激活函数就会导致多层感知机变成单层感知机
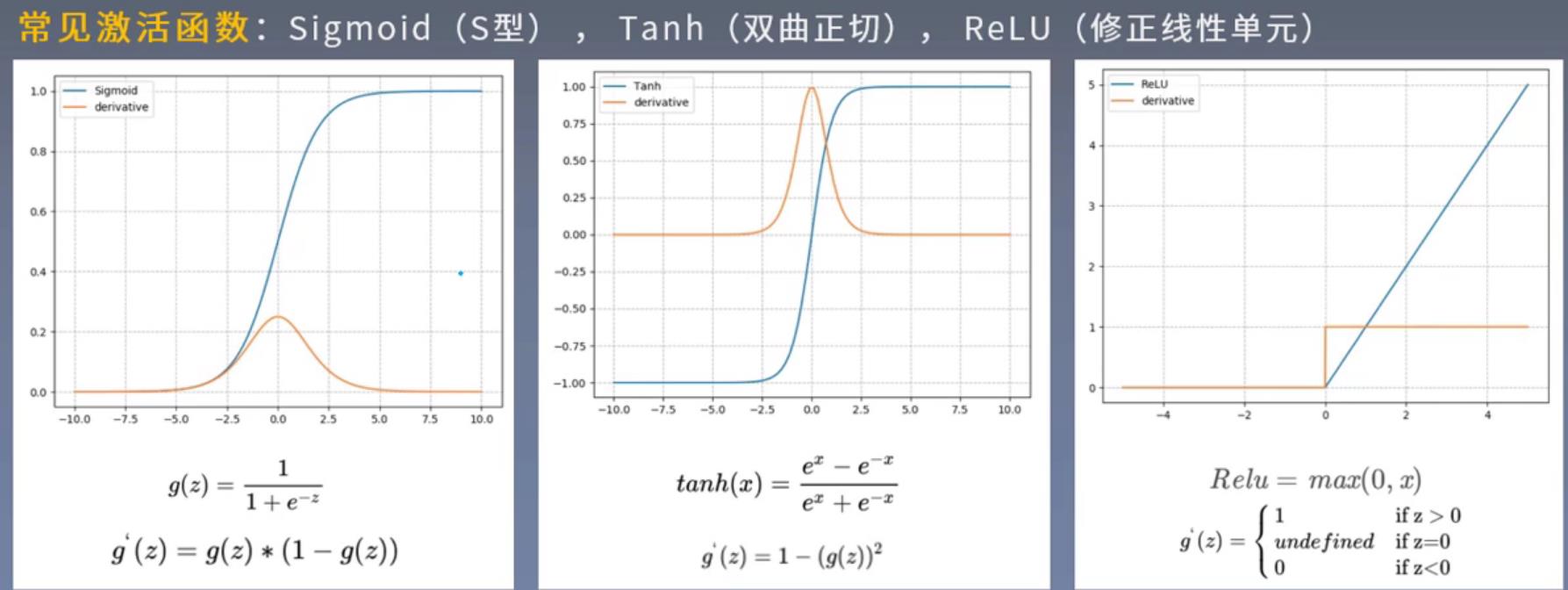
3、激活函数
(1)让多层感知机成为真正的多层,否则等价于一层
(2)引入非线性,使网络可以逼近任意非线性函数(万能逼近定理universal approximator )
激活函数需要具备以下几点性质:
1.连续并可导(允许少数点上不可导),便于利用数值优化的方法来学习网络参数
2.激活函数及其导函数要尽可能的简单,有利于提高网络计算效率
3. 激活函数的导函数的值域要在合适区间内,不能太大也不能太小,否则会影响训练的效率和稳定性
4、反向传播
前向传播︰输入层数据从前向后,数据逐步传递至输出层
反向传播:损失函数开始从后向前,梯度逐步传递至第一层
反向传播作用:用于权重更新,使网络输出更接近标签
损失函数:衡量模型输出与真实标签的差异,Loss = f(y^, y)
反向传播原理:微积分中的链式求导法则 y=f(u),u=g(x),
∂
y
∂
x
=
∂
y
∂
u
∂
u
∂
x
\\frac\\partial y\\partial x=\\frac\\partial y\\partial u\\frac\\partial u\\partial x
∂x∂y=∂u∂y∂x∂u

梯度下降法
(Gradient Decent) :权值沿梯度负方向更新,使函数值减小导数。函数在指定坐标轴上的变化率方向
导数︰指定方向上的变化率
梯度:一个向量,方向为方向导数取得最大值的方向
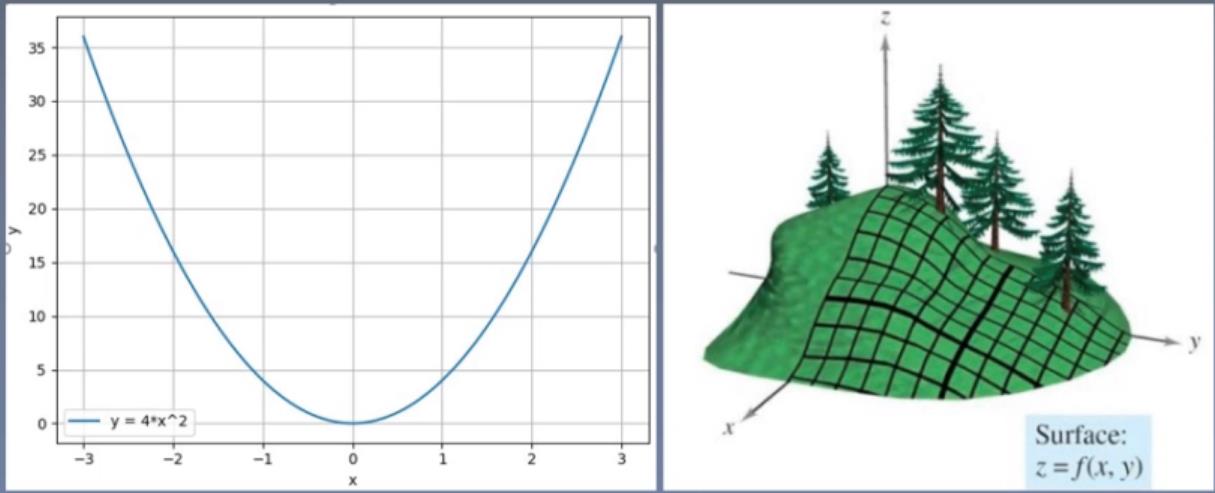 学习率
学习率
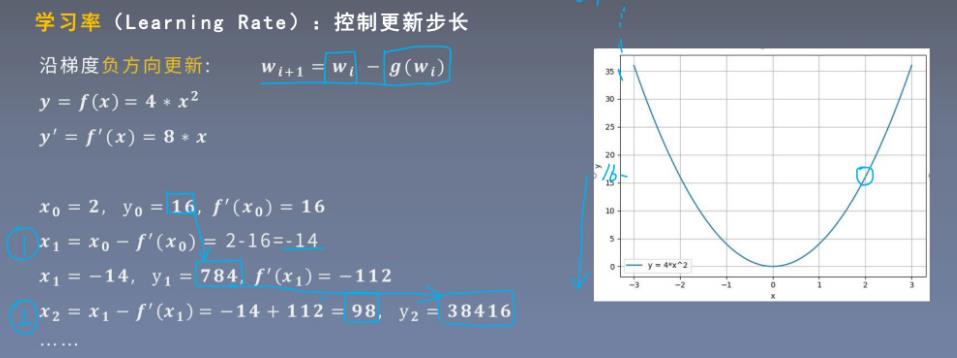

5、损失函数
损失函数:衡量模型输出与真实的标签之间的差距
损失函数(Loss Function): //指单样本
Loss = f (y ^,y)
代价函数(Cost Function): //指总体样本
cost=1/N
∑
i
N
f
(
y
i
^
,
y
i
)
\\sum_i^Nf(y_i^\\hat,y_i)
∑iNf(yi^,yi)
目标函数(objective Function): //正则项
0bj = Cost + Regularization Term

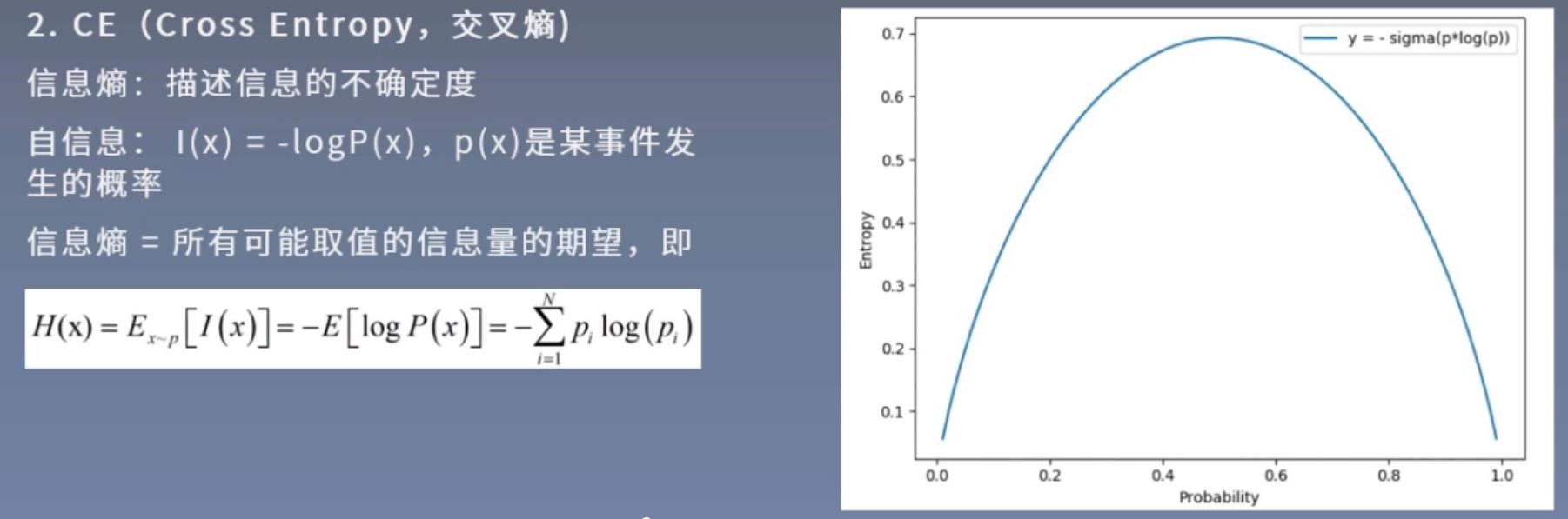


CE (Cross Entropy,交叉嫡)
交叉嫡:衡量两个概率分布的差异
概率有两个性质:
1.概率值是非负的
2.概率之和等于1
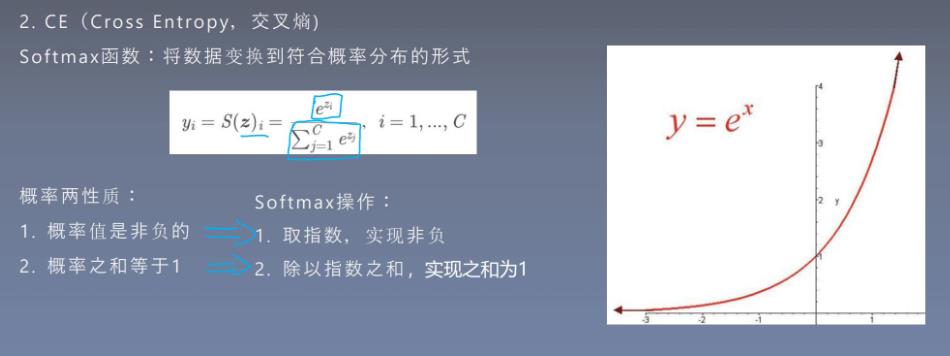
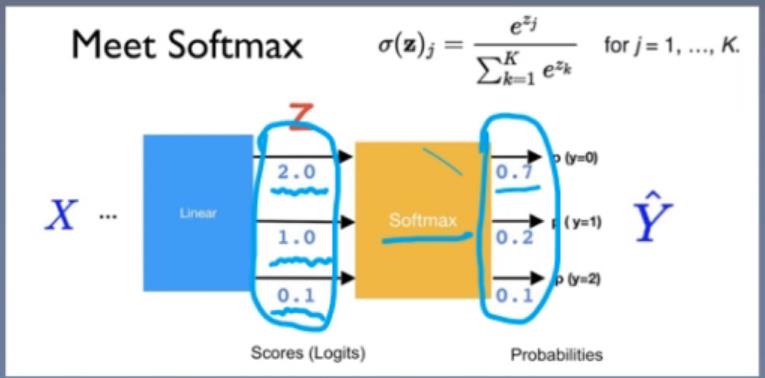
交叉嫡的好伙伴―—Softmax函数:将数据变换到符合概率分布的形式
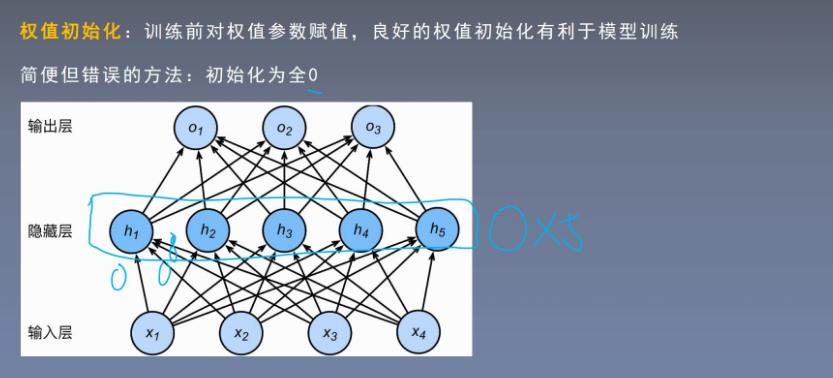
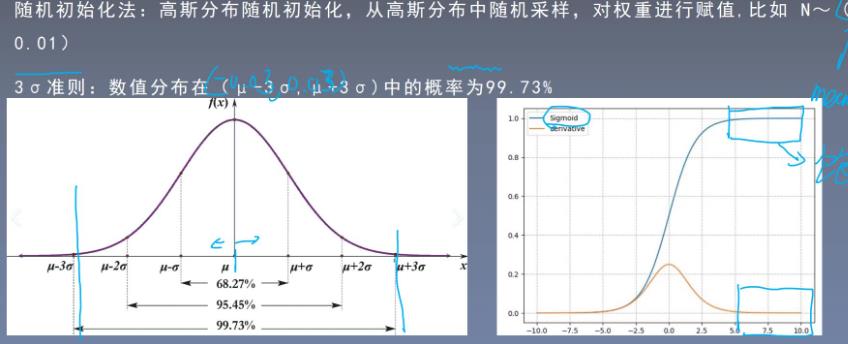
6初始化

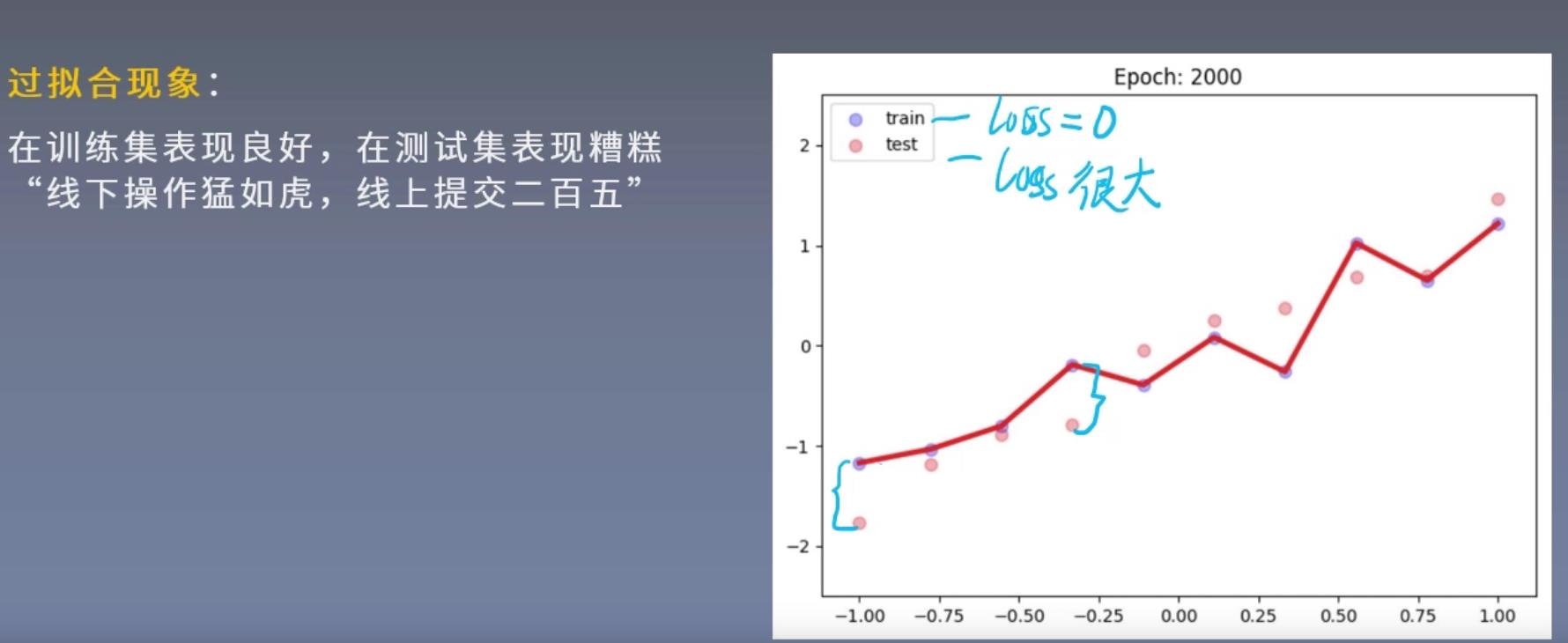
Regularization:减小方差的策略,通俗理解为减轻过拟合的策略
误差可分解为:偏差,方差与噪声之和。即误差=偏差+方差+噪声之和
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界

目的:减少L1或L2的值,
L1=
∑
i
N
∣
W
i
∣
\\sum_i^N |W_i|
∑iN∣Wi∣
可能有权值的吸收性(当
W
i
W_i
Wi)
L2=
∑
i
N
W
i
2
\\sum_i^N W_i^2
∑iNWi2

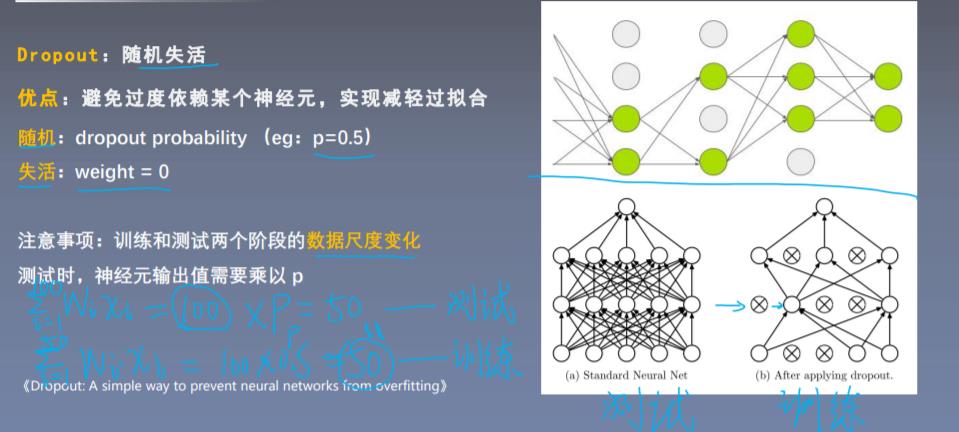
减少过拟合的方法:
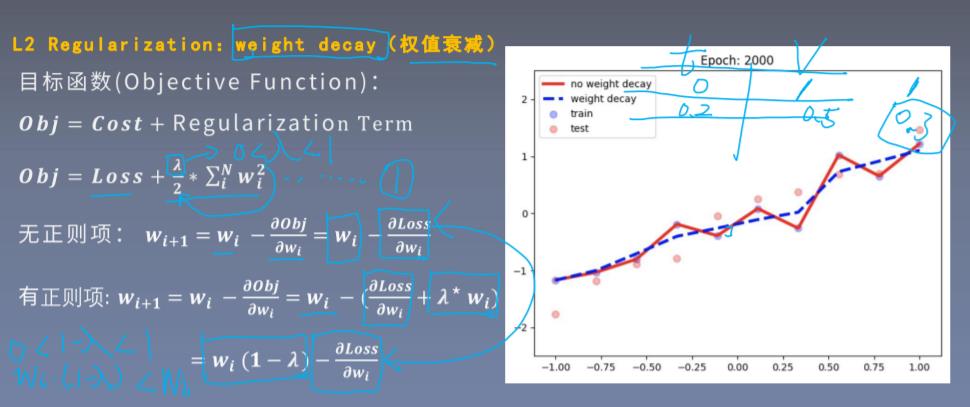
通过对比两个公式,发现正则化是
W
i
(
1
−
λ
)
W_i(1-\\lambda)
Wi(1−λ),而正则化是
W
i
W_i
Wi,会发现正则化导致了权值变小,过拟合现象也变小了。
以上是关于人工智能基础入门——神经网络讲解的主要内容,如果未能解决你的问题,请参考以下文章