搜索引擎模块设计与实现——集群模块
Posted Dreamchaser追梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎模块设计与实现——集群模块相关的知识,希望对你有一定的参考价值。
文章目录
前言
之前参加了字节青训营后端进阶班,我们选择的题目是搜索引擎,临近ddl,故有此文。
GoDance是一款用go语言编写的分布式搜索引擎,同时也是一款分布式文档数据库。支持分布式搜索以及分布式存储功能,对外提供restful Api接口来操作GoDance。
一、设计目标
- 分布式共识,保证元数据的一致性
- 节点间自动发现
- 保证集群的高可用,支持故障转移、服务降级
- 支持数据分布式存储
- 尽可能快的性能要求
二、设计方案
简述:集群模块整体采用了raft算法来保证分布式共识和集群高可用,借鉴了ES的思路来实现自动发现功能。
1.节点角色
MasterNode
- 可以被选举为Leader节点,集群中只有MasterNode才有选举权和被选举权,其他节点不参与选举
- 负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等
DataNode
- DataNode负责真实文档数据的存储
一个节点可以既是MasterNode,也可以是DataNode,但建议在配置时分开部署
2.节点状态
state状态
- Leader(处于领导者状态)
- Candidate(候选者,处于候选状态,正在进行选举)
- Follower (跟随者状态)
- Dead (节点宕机)
前三者是raft算法中的角色
term任期
节点每次选举都会把任期自增,一个节点在一个任期内只能投一票。任期也会影响到后面的选举规则。
任期的最大作用就是保证任何一个节点在一个任期内仅会投出一票,保证在“大多数”设置合理的情况下,一个任期最多只会有一个Leader被选出,从而避免脑裂现象
3.Leader选举机制
简述:raft算法通过“大多数"来保证集群中只有一个Leader存在,避免脑裂情况产生
3.1 设计方案
基本规则
- Leader会间隔一段时间向Follower发送心跳RPC来告诉Follower自己还活着
- Follower在收到心跳Rpc后会重新计时,之后一段时间不会发生选举
选举时机
- 当节点发现随机超时时间内没有收到心跳时,MasterNode会将自己term自增1,并开始竞选,投自己一票,并向其他MasterNode发送拉票请求
投票策略
- 只会投给任期比自己大的节点(意味着一个节点在一个任期term内只会投一票)
- 只会投给日志完整性(也就是最后一条日志项对应的任期编号值,索引号)和自己一样或者比自己高的节点
- 每次收到投票RPC时,无论是否投票,都会把自己的term更新到较大的值
选举成功条件
当一个候选者向其他节点发起拉票,收到“大多数”选票后晋升为新一任的Leader
其他规则
PS:以下一些规则是自己加的,并不完全是raft算法
-
当一个Leader收到比自己任期高的节点心跳时,由Leader退为Follower,避免脑裂
-
当其他候选者接受到来自任期大于等于自身的节点心跳时停止选举,变为Follwer
-
当收到其他节点的拉票请求时,重置超时时间,避免再次开始选举
-
选举失败后,应该检查自身是否收到了新的符合合规心跳(term>=自己),如果收到则退出选举状态为Follower;如果没有则等待随机超时时间再开始下一次选举
随机超时时间
- 跟随者等待领导者心跳信息超时的时间间隔是随机的
- 重新选举的等待时间是随机的
3.2 情境简述
为了方便理解上述的设计方案,这里举例几个常见的分布式场景
PS:以下示例默认所有节点都是Master节点(raft算法中没有这种概念,这个是为了后面自动发现而增加的)
情境一:正常情况
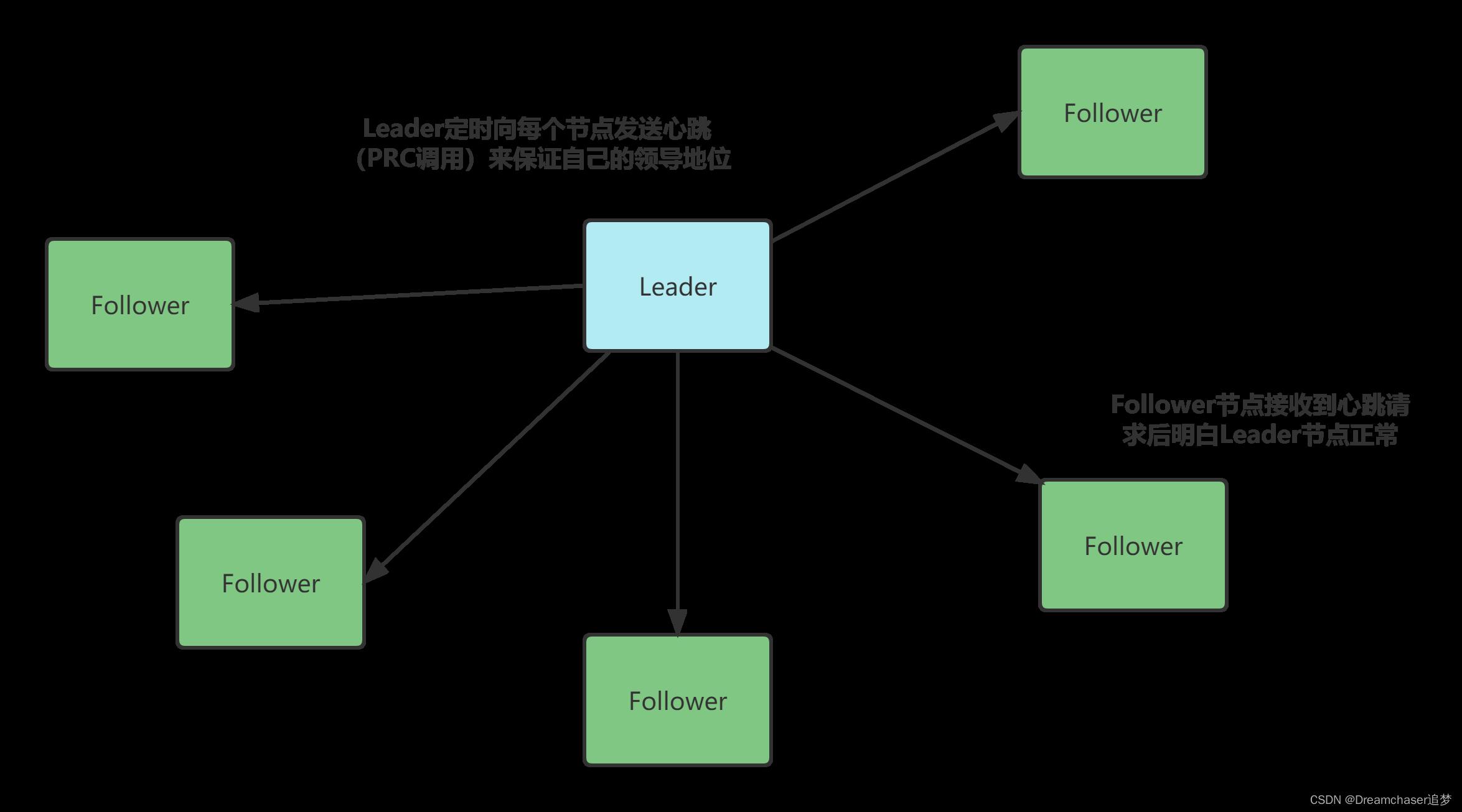
Leader节点定时向其他节点进行RPC调用(心跳)告诉各个从节点——“我还活着,不要造反!”
当Follower节点正常收到该心跳时,在接下来一段时间内不会进行选举操作,同时会返回当前的日志状态(最新提交和最新增加的日志Id)
情境二:Leader宕机
接下来一种情况就是Leader宕机
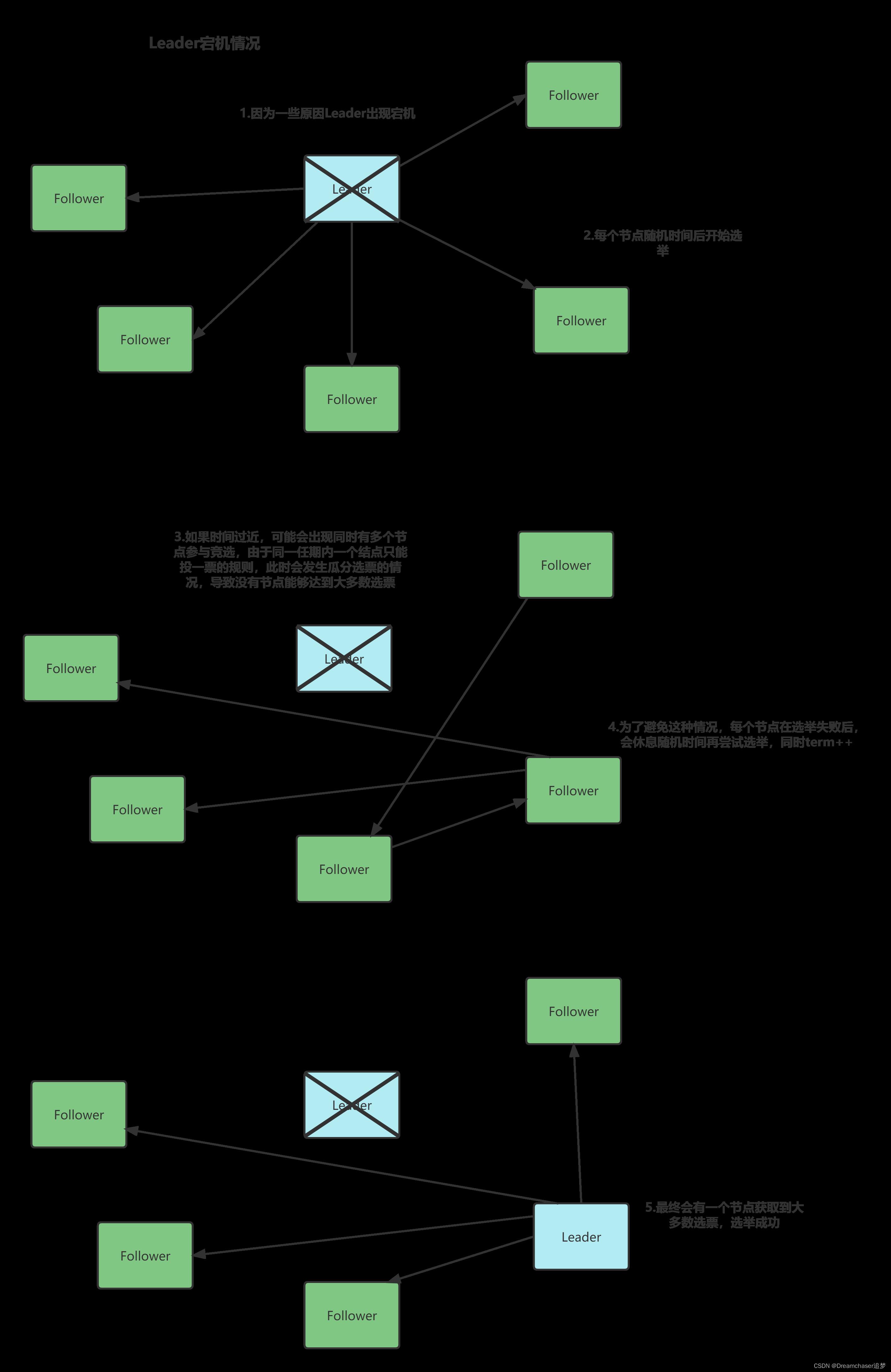
当Leader宕机时会,每个节点随机时间后开始选举,如果时间过近,可能会出现同时有多个节点参与竞选,由于同一任期内一个结点只能投一票的规则,此时会发生瓜分选票的情况,导致没有节点能够达到大多数选票。
为了避免这种情况,每个节点在选举失败后,会休息随机时间再尝试选举,同时term++,最终会有一个Leader节点成功竞选。
而这两个随机时间——跟随者等待领导者心跳信息超时的时间间隔和重新选举等待时间,都是为了避免这种冲突,加快Leader选举而设立的。
当然上述是一种比较复杂的情况,真实场景中可能第一次就能选举成功,不必等待。
情境三:网络时延情况
除了正常宕机外,还有一种情况会触发选举,那就是网络时延
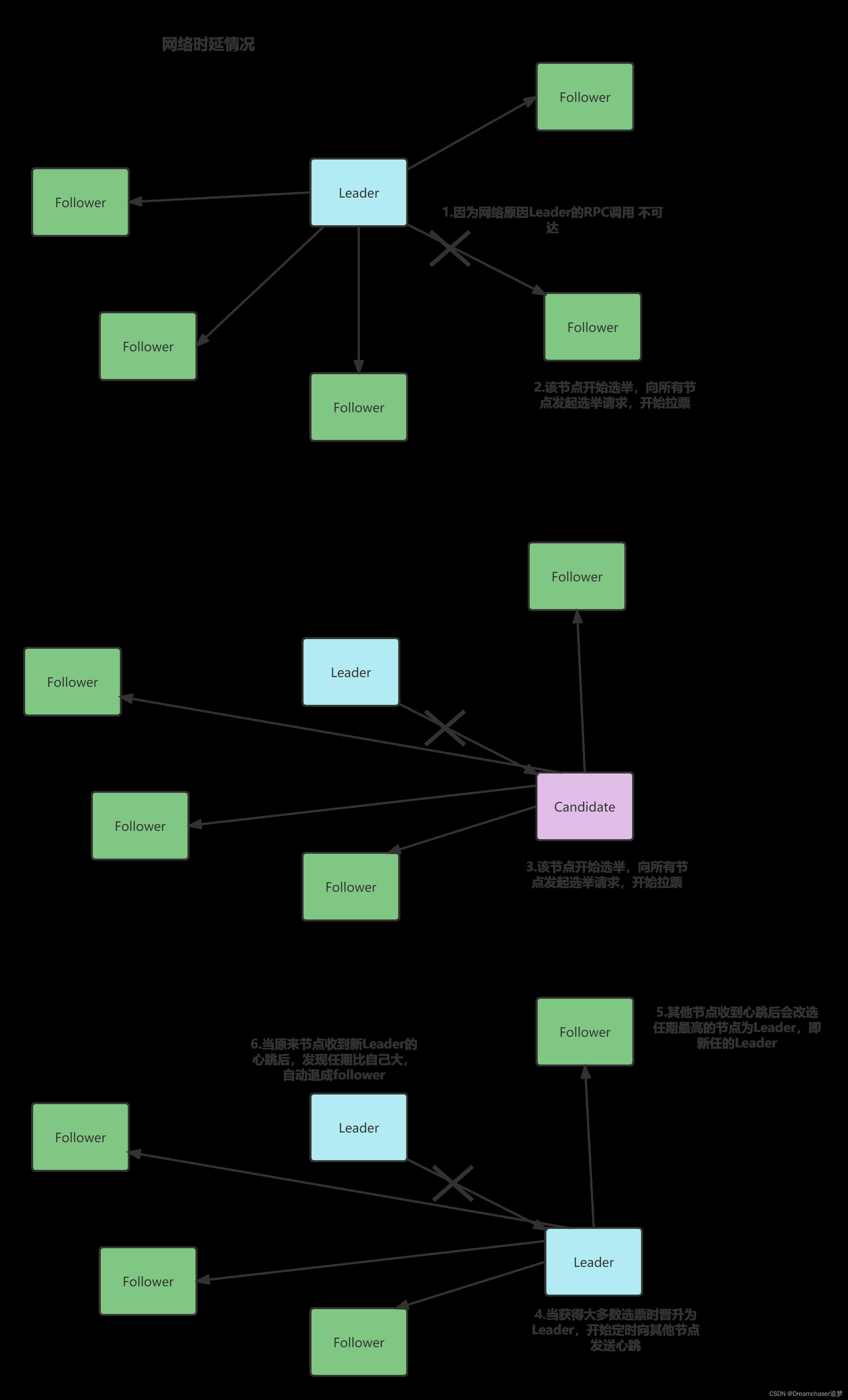
因为网络时延而不能预期收到心跳的节点会开始选举,任期+1,当收到大多数选票时,成为新的Leader。
注意在这种情况下,可能会出现短暂的脑裂现象,但是并不会对集群状态产生影响,因为在这期间集群的状态修改,只有新Leader才可能达到大多数条件从而修改集群状态。
当然在这种情况下,还有一些比较复杂的情景,比如:

情境四:网络分区
这里又可以分为两种情况,Leader分在多数和Leader分在少数

要注意的是Leader可能并不是原来节点,这取决于分区恢复后日志完整性,以及当时的网络情况。具体情况可以参照情景三
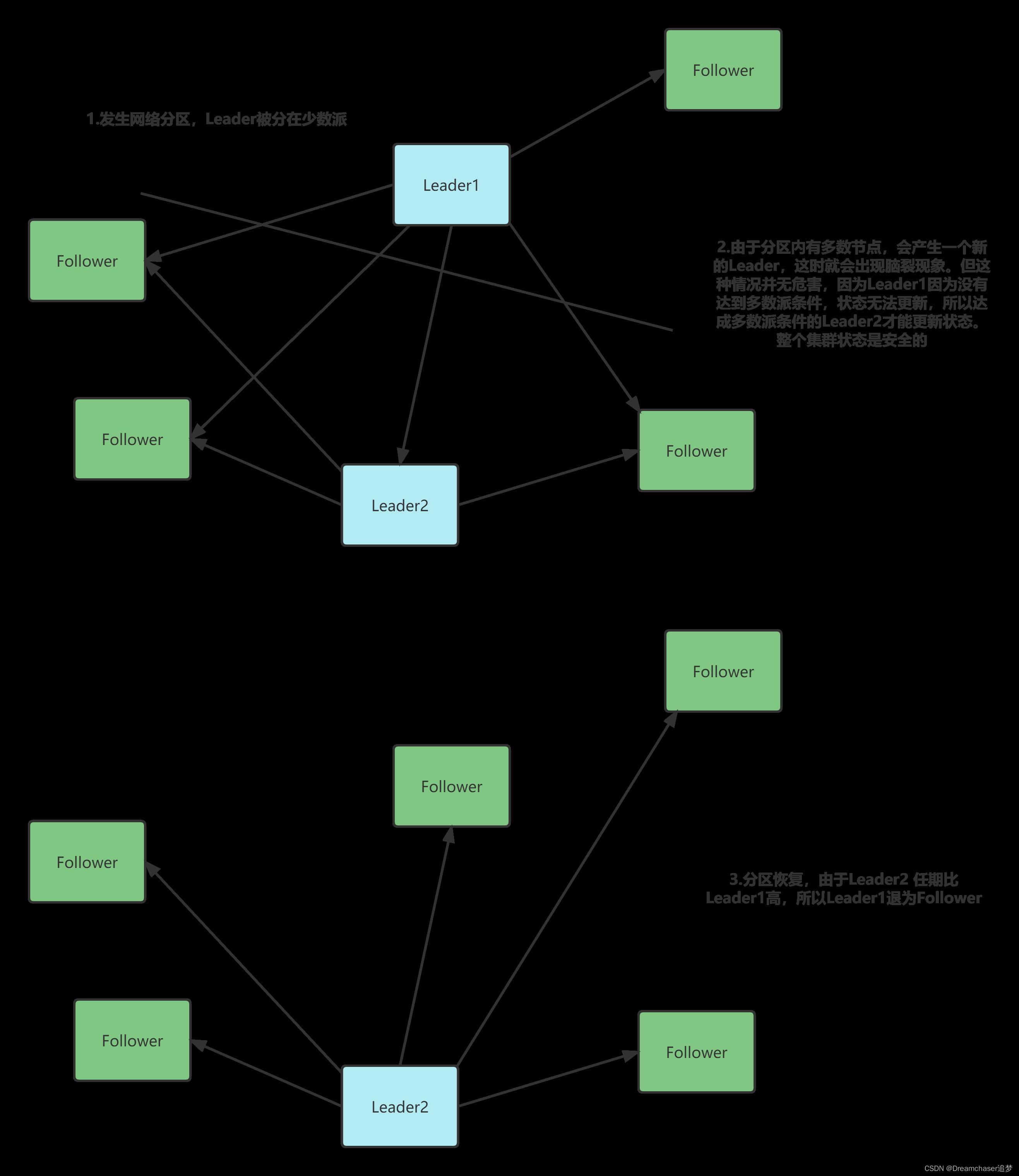
可以看到,无论是否发生了网络分区,集群的状态都能达到一致。
4.集群状态机(集群元数据)
为了保证搜索引擎正常的分布搜索和分布式存储能力,集群中的元数据便必须得是一致且安全的。而集群状态机就是指该集群状态。
该集群状态保存有以下信息:
- 当前主节点Id
- 各节点信息,包括节点id、地址、状态、是否是MasterNode等等
- 分片路由,这个将会在分片模块重点阐述
- 任期term
- 其他集群信息,如集群名称等等
通常情况下,集群状态机会维护在内存中一个数据结构中。
每隔一段时间会讲该状态机持久化到硬盘中,便于宕机后快速恢复。
每个节点都会有一份集群元数据,便于对web层发来的请求做出决策。
5.tranlog机制
在raft算法中,存储集群状态的并不是刚才讲的集群状态机,而是日志。这是因为在分布式场景中,如果要做到分布式一致性以及较少的传输损耗,追加写入的日志将会是分布式共识的不二之选。
参考raft算法,我们也是根据其设计了相应的机制
5.1 tranlog数据结构
tranlog真实含义是操作日志,也就是状态机变更的操作,也就是说我们需要归纳出设计集群状态变更的几种操作
关键字段包括:
- id 日志id,自增
- term 日志任期
- operation 操作指令
- object 操作对象
- committed 日志是否提交
5.2 确保tranlog的分布式一致
简单来说,该方案设计采用了二阶段提交的思路,不过根据自己的实现对其做了优化
第一阶段(prepared):
- 客户端向Leader发起节点变更请求/自身节点变动
- 自身增加一条对应的tranlog
- 向所有节点发送AppendEntry RPC调用
- 各个节点将会判断term是否一致以及该日志的前一条日志id是否和自身节点的当前日志id一致,如果不一致则拒绝,Leader会重新发送一个sendHeart RPC来同步日志,如果成功则返回true,否则返回false;如果一致,就在当前节点中增加一条日志,返回是否成功
- Leader节点判断日志同步成功的MasterNode节点数是否达到了“大多数”,如果是则提交该日志到状态机,给客户端返回成功响应;否则返回失败响应
第二阶段(commit):
PS:这个和原来raft算法的不太一样
确认阶段由心跳RPC去进行日志同步的操作,具体步骤如下:
- 心跳RPC调用,发送最新提交的日志id和前一个节点的id
- Follower判断自身日志是否一致,如果存在该日志但未提交,节点会提交该日志到状态机中
- 如果不一致,则返回自身最新提交日志id和最新增加的日志id
- Leader开始日志同步,将差异数据传输给节点
如果认真阅读上述设计方案,可能会有以下几个疑问:
为什么只计算MaterNode节点作为大多数判断?
因为我们要保证的大多数节点更新后,最新的日志总占大多数。
而这点就是为了确保新一轮选举,选出的Leader一定会是日志完整性最高的节点(不给日志完整性低的节点投票)。而参与竞选的正是MasterNode,所以我们只需对MasterNode计数即可。
如何判断日志一致?
判断一致是根据最新提交日志id和最新增加的日志id的二元组来决定的,两者都一致则意味着日志是一致的
为什么日志复制时要验证term?
为了保证自身节点日志完整度小于投票的节点
提交状态如何保证大多数?
上述机制能保证——如果主节点提交,那么大多数节点则有该日志。但是该机制无法保证选出来的领导者能保证提交日志的大多数。
试想这么一种情况:Leader在提交日志时,突然宕机,那么新选出来的领导者是有该日志的,但是没有提交,可目前已经有节点进行了提交,这肯定是不行。
领导者选举能保证新领导者一定包含这条committed的日志项,但这条日志项在新领导者上处于未提交状态,这时新领导者,需要尝试从最新日志项开始,向其他节点复制日志,如果,某条uncommitted的日志项,被发现已经成功复制到大多数节点上,或者发现该日志已经被提交,这时这条日志项将处于提交状态,并被应用到状态机,通知其他节点提交这条日志。
但还是有一种极其特殊的情况:假设有A B C D E五个节点,A B C成功复制了最新的日志项,leader节点A提交了并返回成功,B C未提交,这时leader节点A挂了,选举出新leader节点B,这时候只能发现2个节点具备某条uncommitted的日志项,不满足大多数。这样尽管Leader提交了,但是其他节点并没有提交同时也满足不了大多数条件,所以在新的Leader看来该日志没有被提交。
而当Leader节点恢复时发现最新的日志是提交状态,所以在日志恢复时,需要做一步额外的验证——检查自己最新的日志是否提交,如果提交则需检查该日志是否在集群也提交了(如果该日志在集群中已经不存在了,则直接复制Leader的state并持久化)
5.3 tranlog加载到集群状态机
在日志提交时,我们需要将tranlog加载到集群状态机中,来影响真正的集群元数据。
要注意的是删除节点的操作有些需要注意的地方:
非Master节点直接移除出cluster状态,Master节点则采取假删的策略,修改节点状态为Dead
这样的好处就是依然会对Master节点发送心跳,而不至于一时的网络延时导致其中一个MasterNode开始无限竞选(其中一个节点因为网络延时开始竞选,但此时其他节点又接受到Leader的日志更新,根据不给日志完整性低的节点投票的原则,网络时延的那个节点会不停选举,但始终不能竞选成功,而集群状态又失去了该节点联系,所以会导致该节点丢失)
不同的指令意味着不同操作,在此就不赘述了。
5.4 tranlog持久化机制——保证crash-safe能力
考虑到极端情况,当日志复制成功后,如果节点宕机,则会丢失tranlog,这样就不能保证大多数节点拥有完整性最高的日志。
所以在日志复制时会直接将增加的日志进行持久化,追加写入到日志文件当中。
一些优化
-
为了节省资源,这里只有MasterNode才会持久化日志,因为非MasterNode不会参与竞选,他们的日志恢复强依赖于Leader节点
-
当发现日志差异过大时,这意味着一项项复制日志性能损耗太大,此时会选择直接复制集群元数据并持久化的方式来进行同步
-
当集群状态机进行持久化之后,那么这之前的日志都可以不必保存,之前写入的文件便可以删除。之后的日志可以追加写入一个新的文件
6.自动发现机制(初始选举问题)
以上采用raft算法解决的集群间的分布式共识问题,但是并没有解决初始的选举问题。换句话讲,上述集群选举机制都是在各个节点彼此知道各自的存在的情况下进行的,但是在真实情况下,各个节点一开始是不知道彼此的存在的,那么如何解决这个问题呢?
这里借鉴了ES的设计思路,引入种子节点的概念。
什么是种子节点?
种子节点可以在配置文件中配置,它是一系列ip地址的集合。
要注意,种子节点必须要保证其可用,不然种子节点挂了就无法进行自动节点发现了
自动发现机制
在节点上线时,会先从种子节点获取当前的集群状态。
如果当前有Leader节点,则会向Leader节点发送加入的RPC。
如果当前没有Leader节点,MasterNode则会开始竞选流程,向其他节点发起拉票RPC,而拉票的对象就包括种子节点;非Master节点则会轮询种子节点,直到当前集群成功出现了一个Leader。
三、具体实现
这里暂时不进行讲解了,详情请看GoDance代码仓库中的cluster模块。
该模块在陆续完善中,未来将实现一个真正可以运行的分布式搜索引擎,敬请期待。
总结
说实话实现raft算法真的有点复杂,尤其是细节部分。在网上搜集的各种资料质量参差不齐,看论文又太煎熬。很多细节都靠猜,靠自己尝试去补全细节,但很多时候自己去尝试推演发现有问题,于是又是各种搜索…最终也算实现了raft算法,自己的推演也终于跑通,之后应该会再写一篇,总结一下这个过程中遇到问题和一些自己的思考。
愿我们以梦为马,不负人生韶华!
与君共勉!
以上是关于搜索引擎模块设计与实现——集群模块的主要内容,如果未能解决你的问题,请参考以下文章