Python实现词云舞
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实现词云舞相关的知识,希望对你有一定的参考价值。
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
本文是一个非常完整的Python实战项目,主要内容包含:
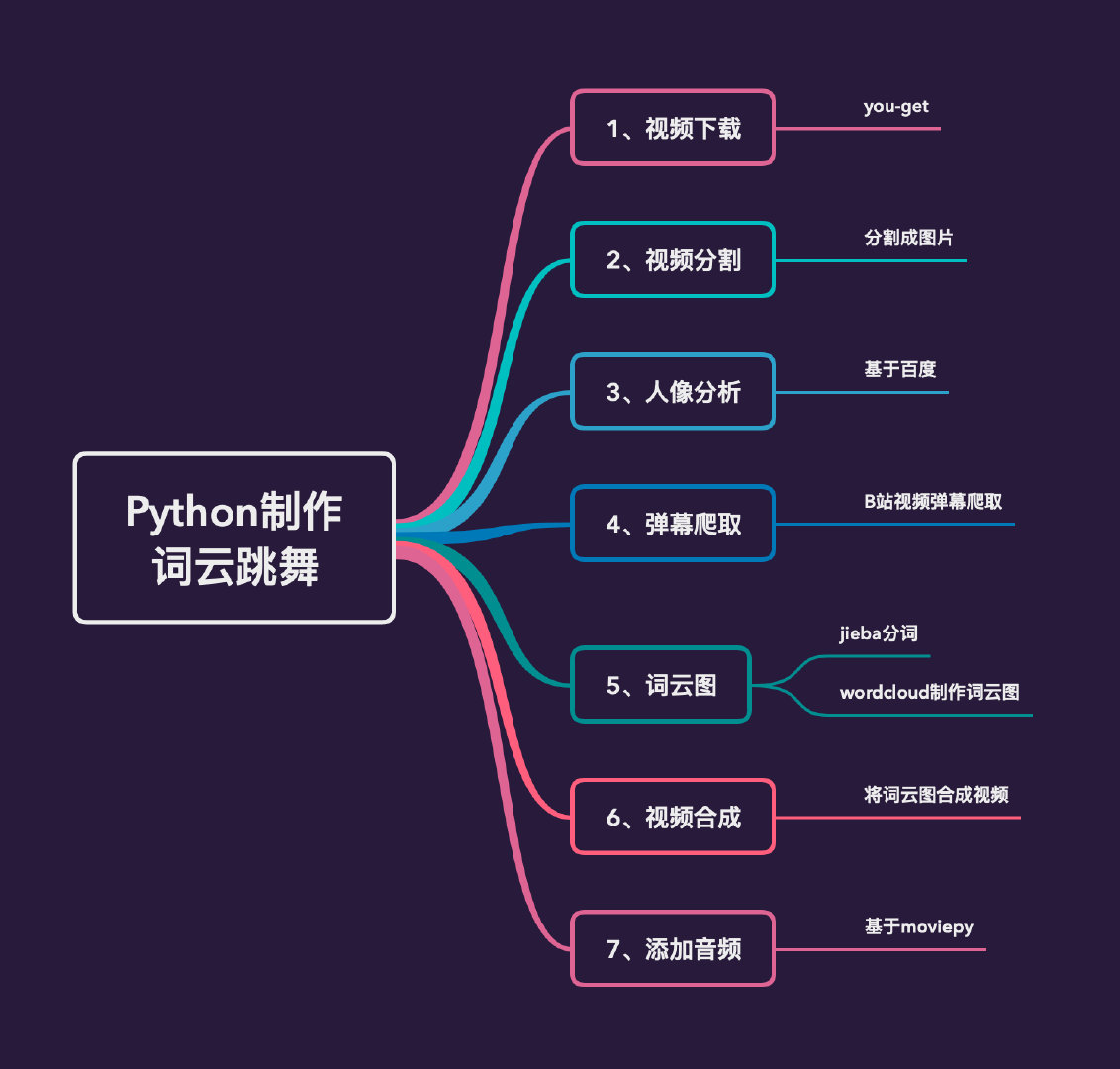
在此感谢周杰伦的《本草纲目》、刘畊宏教练、百度平台以及参考大佬们的方法,本文仅做个人学习使用。
视频下载神器:you-get
you-get是一个下载视频的神器,安装之后一行代码即可下载视频
you-get [url]
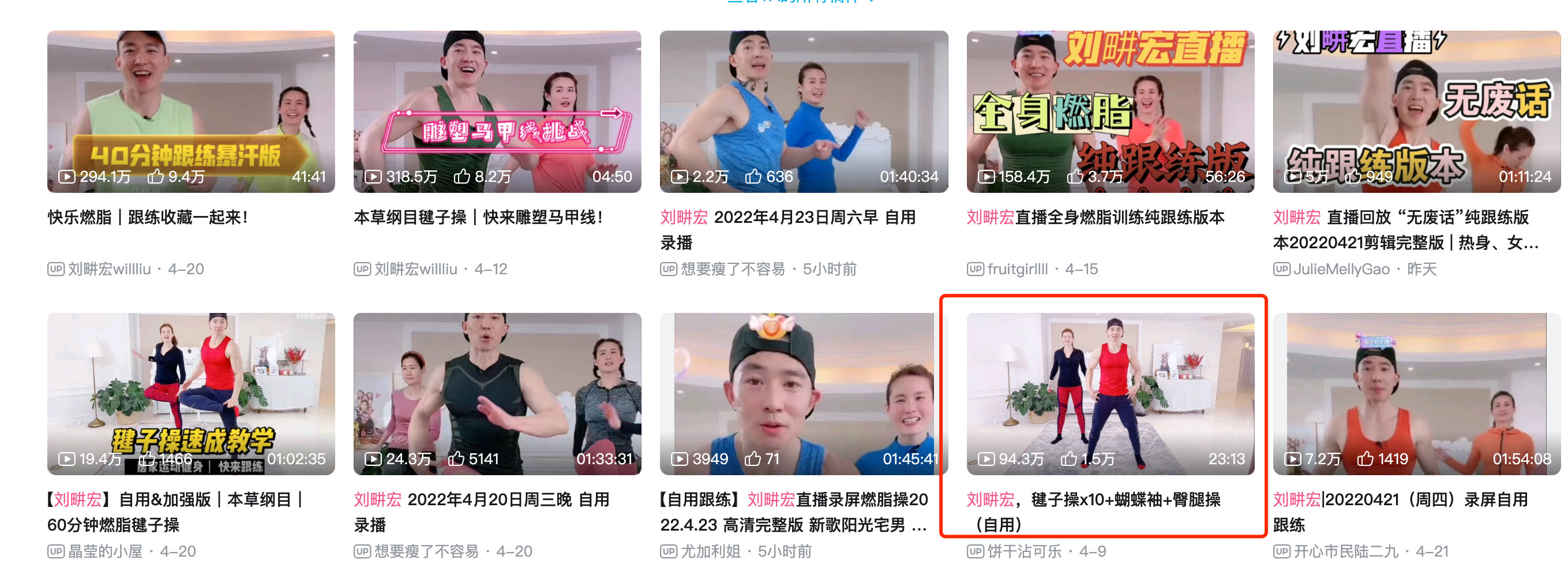
you-get https://www.bilibili.com/video/BV1yY4y1i7Pw?t=1079.2 # 一行代码下载视频

视频切割成图片
下面的代码实现的功能是将上面获取到的代码切割成一张张的图片:
1、opencv中通过VideoCaptrue类对视频进行读取操作以及调用摄像头
-
filename:打开的视频文件名 -
device:打开的视频捕获设备id ,如果只有一个摄像头可以填0,表示打开默认的摄像头
2、videoCapture.read():表示读取视频的下一帧
-
第一个返回值为是否成功获取视频帧:True/False -
第二个返回值为返回的视频帧:帧数
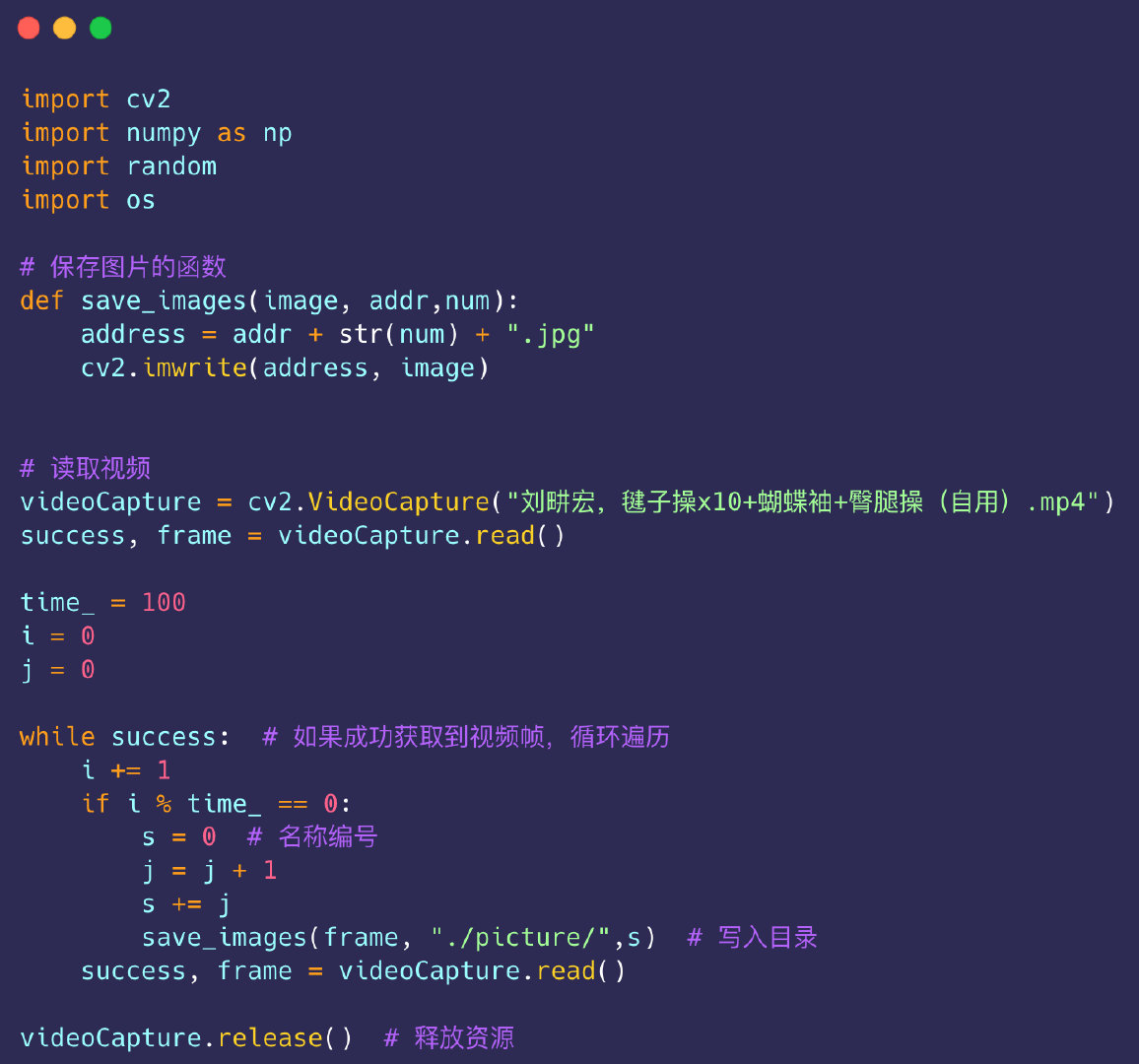
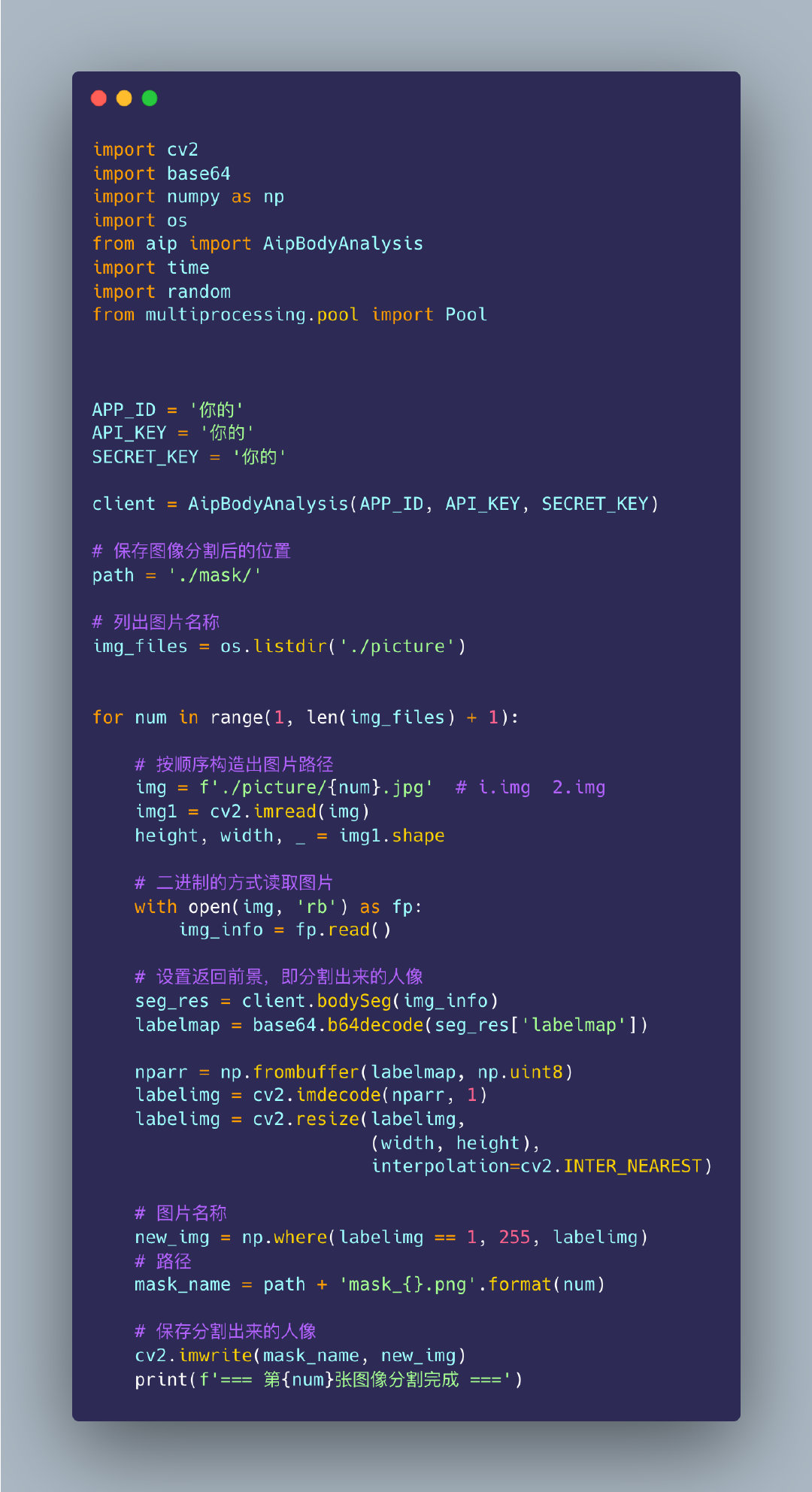
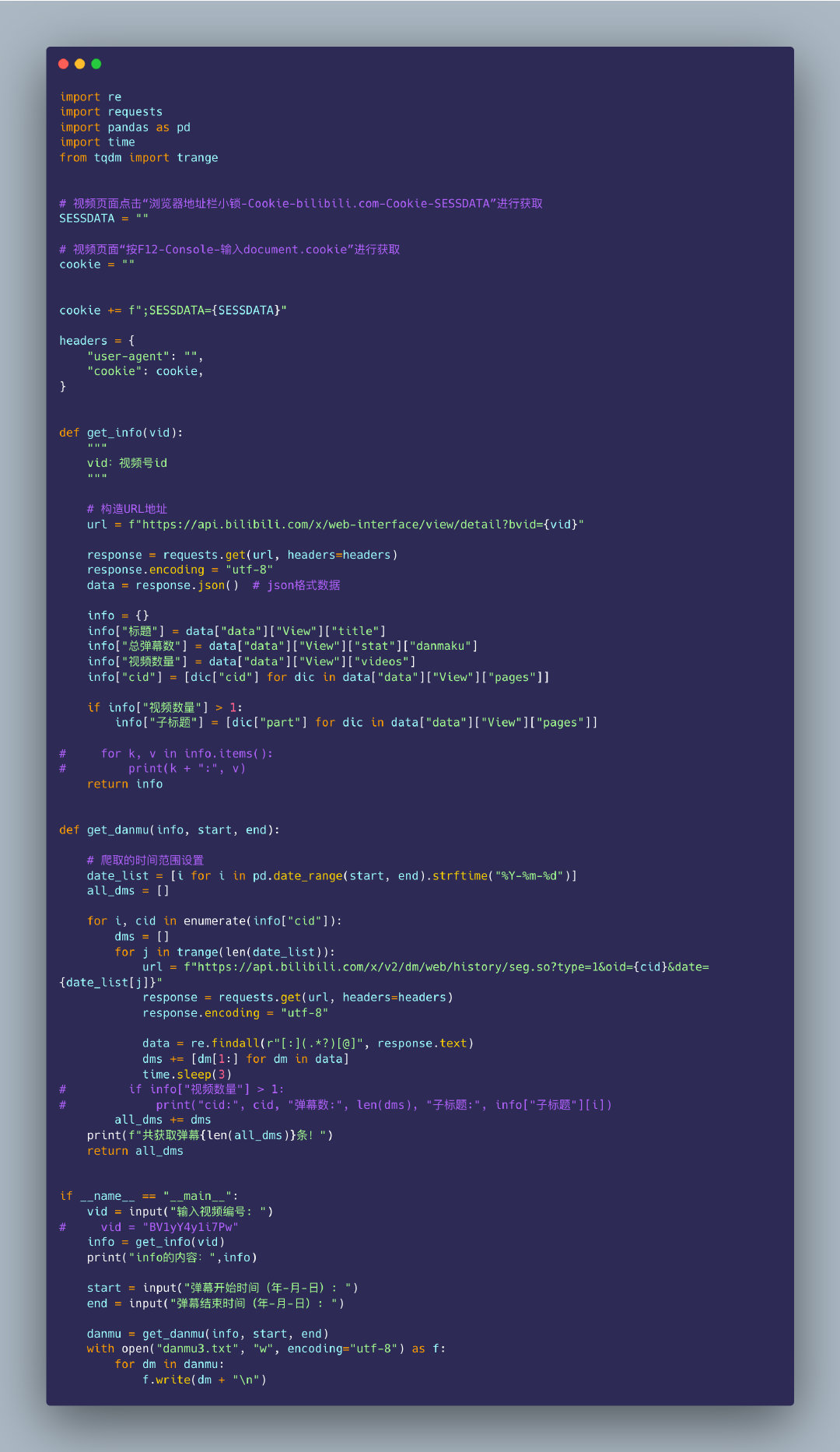
import cv2
import numpy as np
import random
import os
# 保存图片的函数
def save_images(image, addr,num):
address = addr + str(num) + ".jpg"
cv2.imwrite(address, image)
# 读取视频
videoCapture = cv2.VideoCapture("刘畊宏,毽子操x10+蝴蝶袖+臀腿操(自用).mp4")
success, frame = videoCapture.read()
time_ = 100
i = 0
j = 0
while success: # 如果成功获取到视频帧
i += 1
if i % time_ == 0:
s = 0 # 名称的编号
j = j + 1
s += j
save_images(frame, "./picture/",s) # 写入目录后再继续读取
success, frame = videoCapture.read()
videoCapture.release() # 释放资源
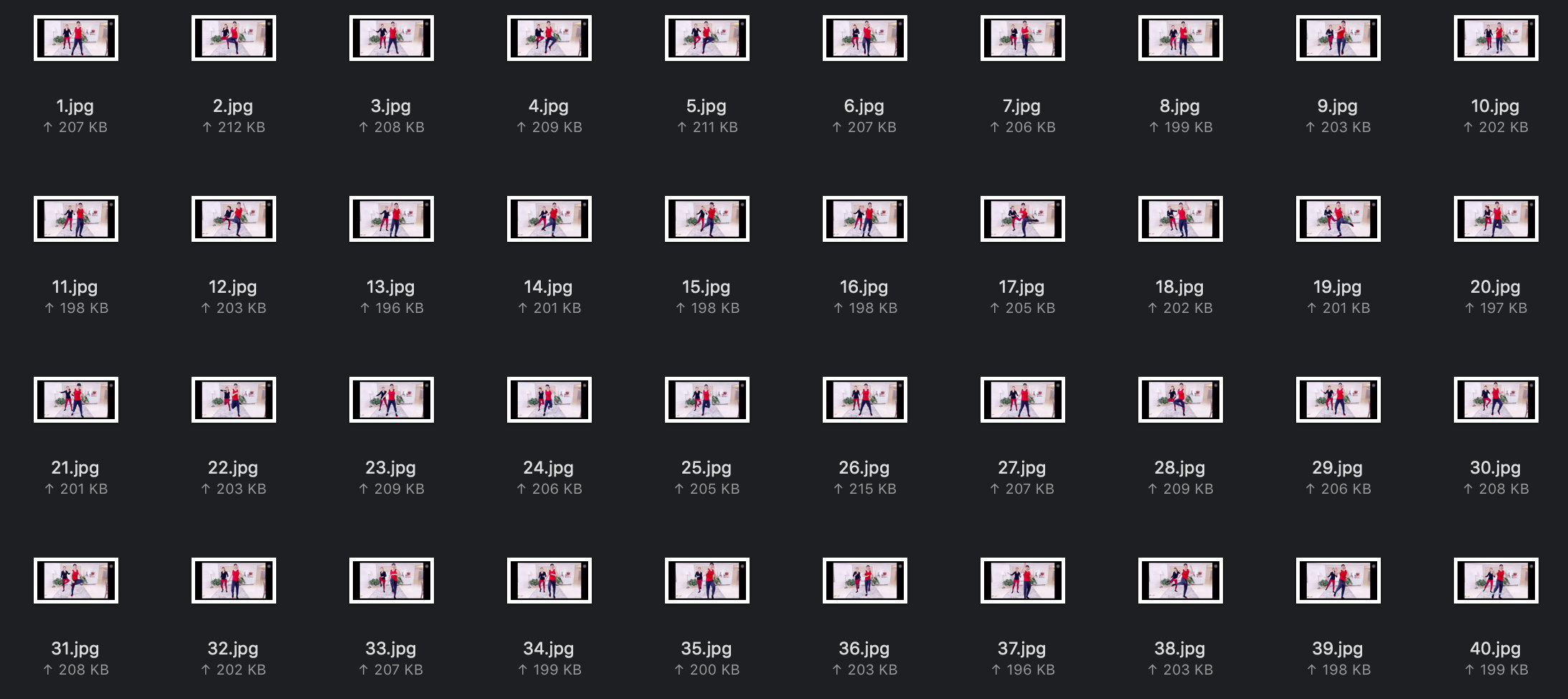
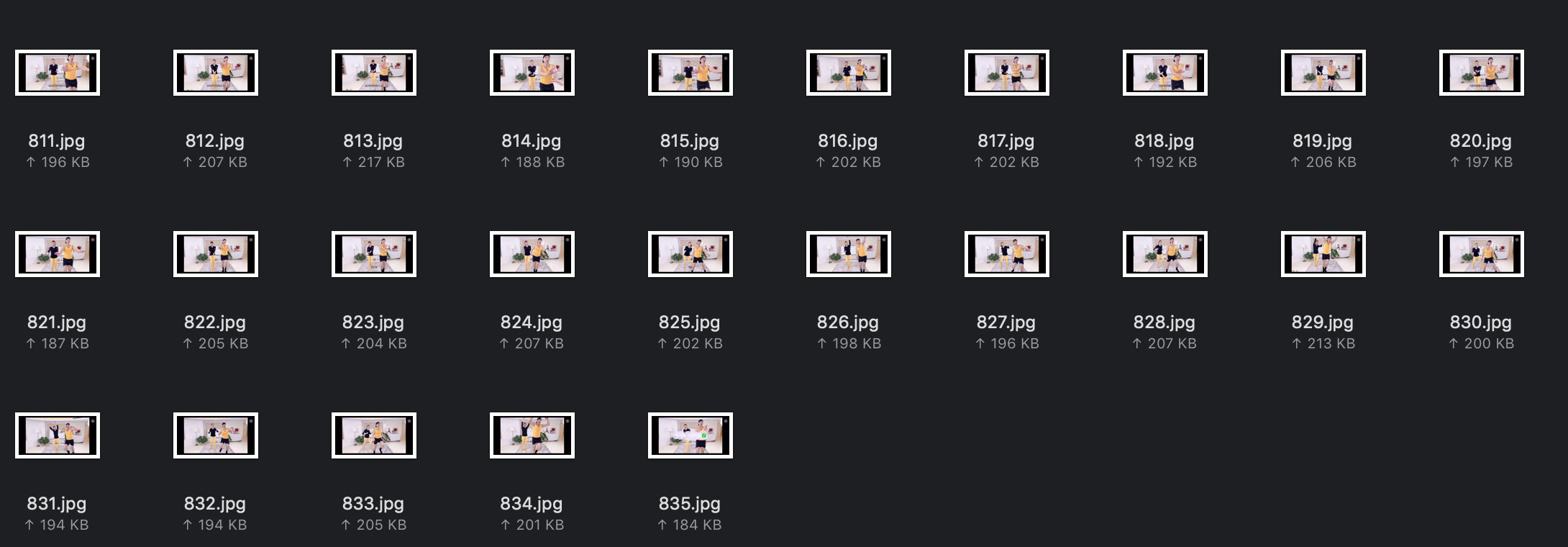
这样最终我们就将这个视频分成了835张图片
百度人像分割
实际使用
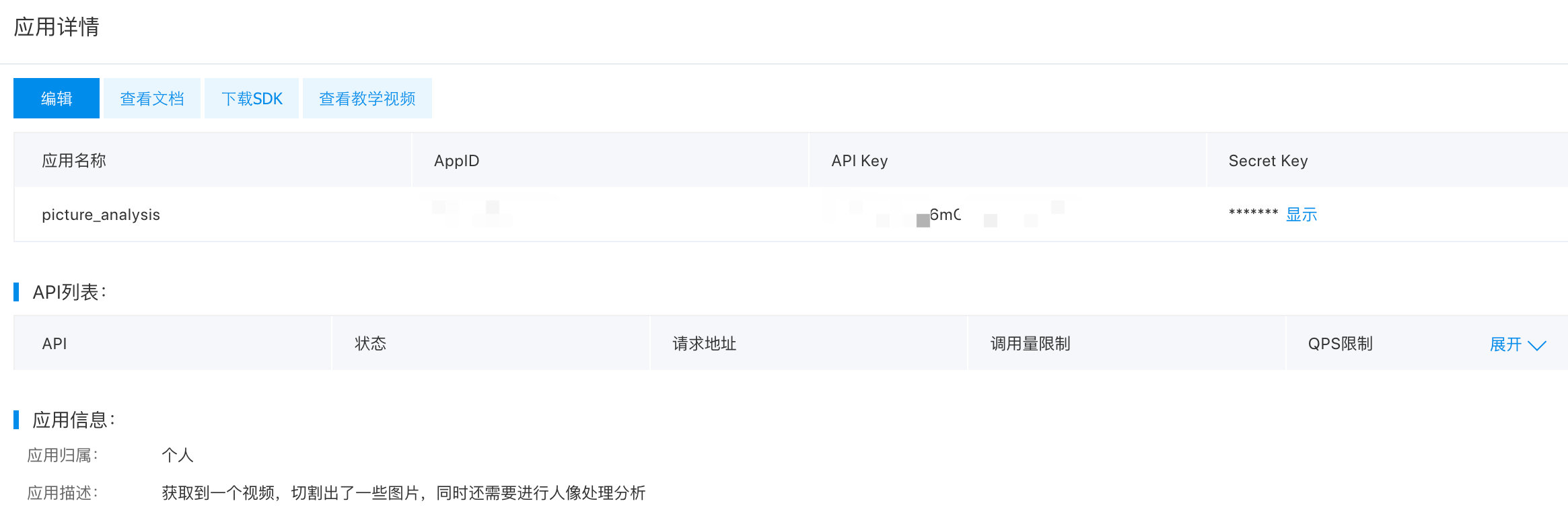
1、先在百度云平台创建人像分割实例
新建一个人像分割的实例,新注册用户可免费领取资源,官网地址:https://cloud.baidu.com/product/body/seg。下面是小编申请的一个实例:
注意点1:一定是安装baidu_aip库,而不是aip
pip install baidu_aip # 安装库,一定要是baidu_aip
注意点2:在当前路径下新建一个mask文件,用来存放分割后的图片。
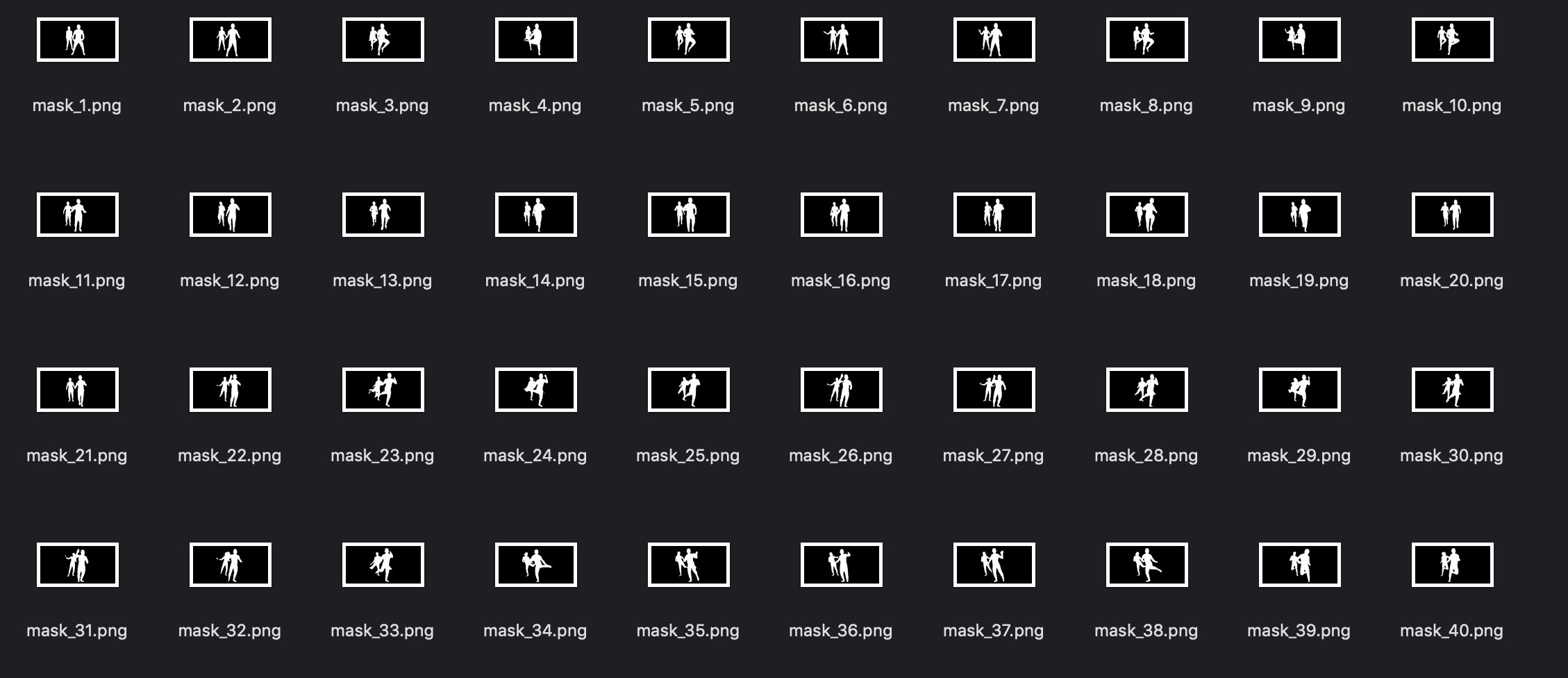
下面是分割之后的二值图效果:

百度demo
具体的百度官方文档请参考:https://cloud.baidu.com/doc/BODY/s/4k3cpyner
百度官方的案例如下:
# 官方demo
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 调用人像分割 """
client.bodySeg(image);
""" 如果有可选参数 """
options =
options["type"] = "labelmap"
""" 带参数调用人像分割 """
client.bodySeg(image, options)
注:返回的二值图像需要进行二次处理才可查看分割效果;灰度图和前景人像图不用处理,直接解码保存图片即可。
获取B站弹幕
接下来是获取上面视频的弹幕,请参考一位NLP大佬:https://github.com/godweiyang/bilibili-danmu
合成词云图
弹幕的分词是自己的方法和收集的一份常用的停用词表:
1、分词使用的jieba分词。关于jieba分词的使用入门,参考:https://github.com/fxsjy/jieba
快速安装jieba:
pip install jieba
import pandas as pd
import numpy as np
import jieba
from wordcloud import WordCloud
from tkinter import _flatten
import matplotlib.pyplot as plt
%matplotlib inline
import collections
import re
import os
from PIL import Image
df = pd.DataFrame()
# 获取了3个和刘教练相关的视频弹幕
txt_list = ["danmu.txt", "danmu1.txt", "danmu2.txt"]
for txt in txt_list:
df1 = pd.read_table(txt, header=None, on_bad_lines='skip')
df1.columns = ["information"] # 重命名
df1.drop_duplicates("information",inplace=True)
df = pd.concat([df, df1])
df.head()

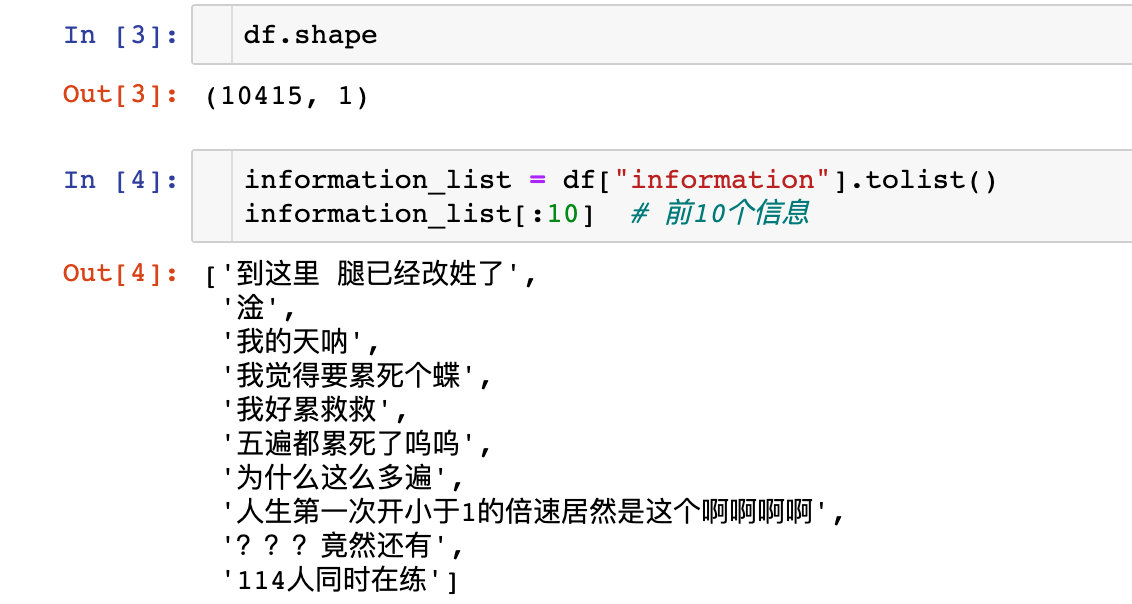
总共是10415个弹幕:查看前10条弹幕信息
2、实施分词


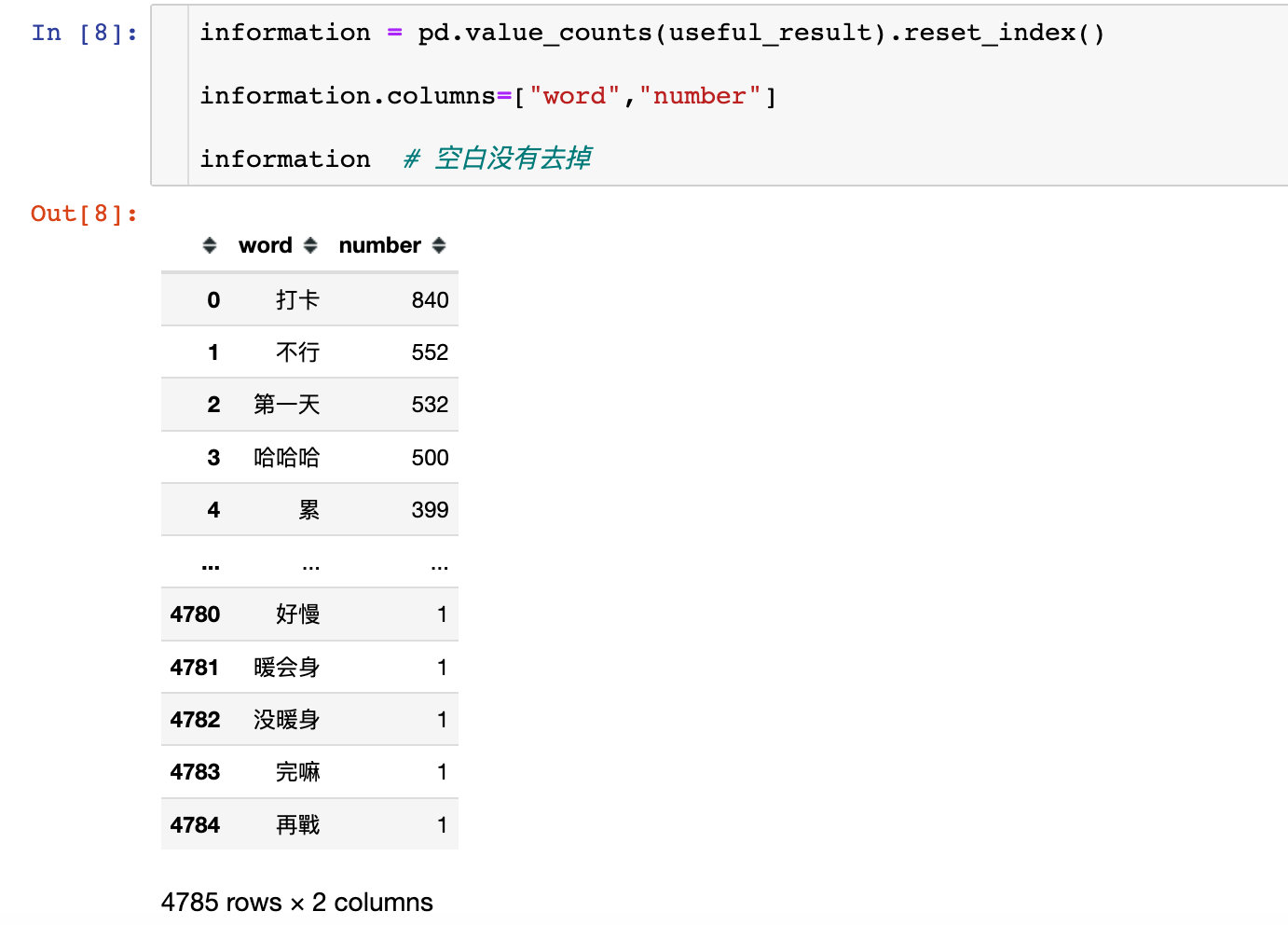
3、统计词频
统计切割之后每个单词的总数:
显示出前80个词云图的效果:
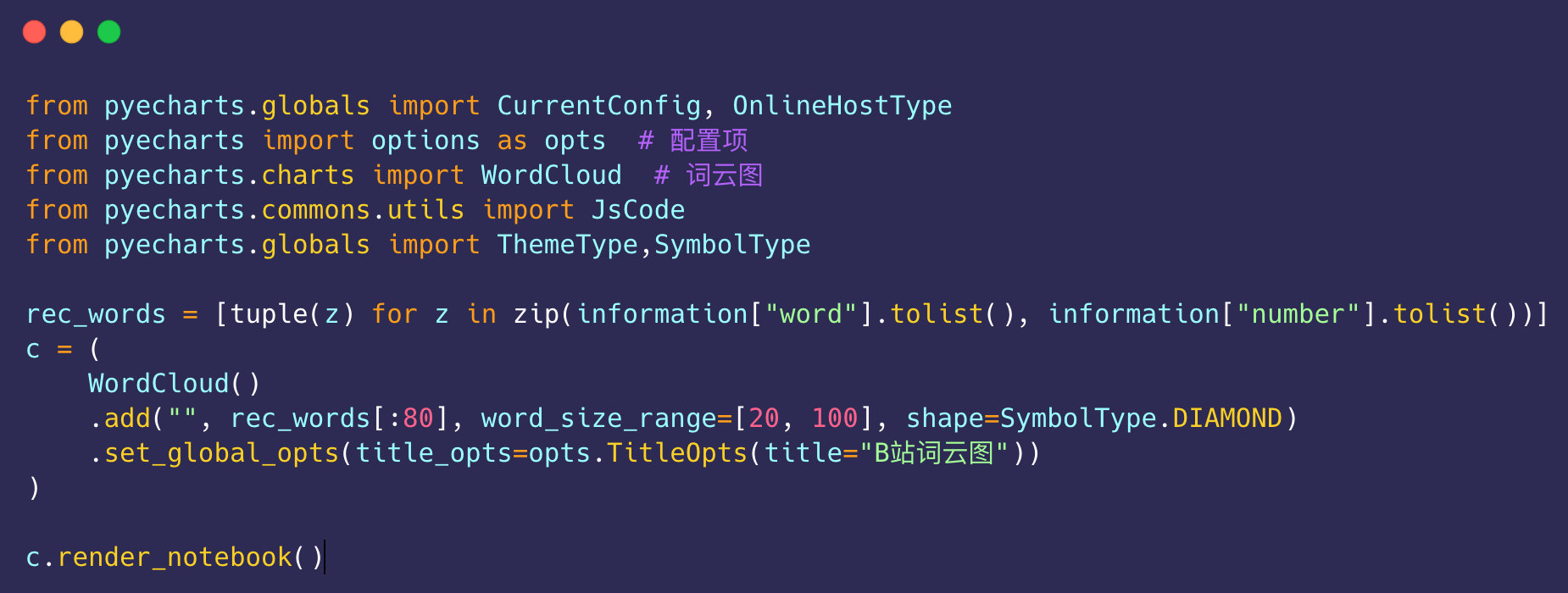
notebook中效果是动态的:

采用的是wordcloud来绘制静态的词云图,并且保存到本地:
wordcloud.WordCloud(
font_path=None, # 字体路径,英文不用设置路径,中文需要,否则无法正确显示图形
width=400, # 默认宽度
height=200, # 默认高度
margin=2, # 边缘
ranks_only=None,
prefer_horizontal=0.9,
mask=None, # 背景图形,如果想根据图片绘制,则需要设置
scale=1,
color_func=None,
max_words=200, # 最多显示的词汇量
min_font_size=4, # 最小字号
stopwords=None, # 停用词设置,修正词云图时需要设置
random_state=None,
background_color='black', # 背景颜色设置,可以为具体颜色,比如white或者16进制数值
max_font_size=None, # 最大字号
font_step=1,
mode='RGB',
relative_scaling='auto',
regexp=None,
collocations=True,
colormap='viridis', # matplotlib 色图,可更改名称进而更改整体风格
normalize_plurals=True,
contour_width=0,
contour_color='black',
repeat=False
通过下面的代码来生成词云图。注意点:需要新建一个目录wordcloud,来存放生成的词云图
word_counts = collections.Counter(useful_result) # 筛选后统计词频
path = './wordcloud/' # 新建:存放词云图的路径
img_files = os.listdir('./mask')
# 遍历mask目录下的全部文件
for num in range(1, len(img_files) + 1):
img = r'./mask/mask_.png'.format(num) # 原图片路径
mask_ = 255 - np.array(Image.open(img)) # 获取蒙版图片
# 绘制词云
plt.figure(figsize=(8, 5), dpi=200)
my_cloud = WordCloud(
background_color='black', # 背景颜色
mask=mask_, # 自定义蒙版
mode='RGBA',
max_words=500,
# 地址路径要改成自己的ttf文件路径
font_path=r'/Users/peter/Desktop/spider/SimHei.ttf'
).generate_from_frequencies(word_counts)
# 显示词云图
plt.imshow(my_cloud)
# 词云图中无坐标轴
plt.axis('off')
wordcloud_name = path + 'wordcloud_.png'.format(num)
my_cloud.to_file(wordcloud_name) # 保存词云图片
对应生成的词云图效果:
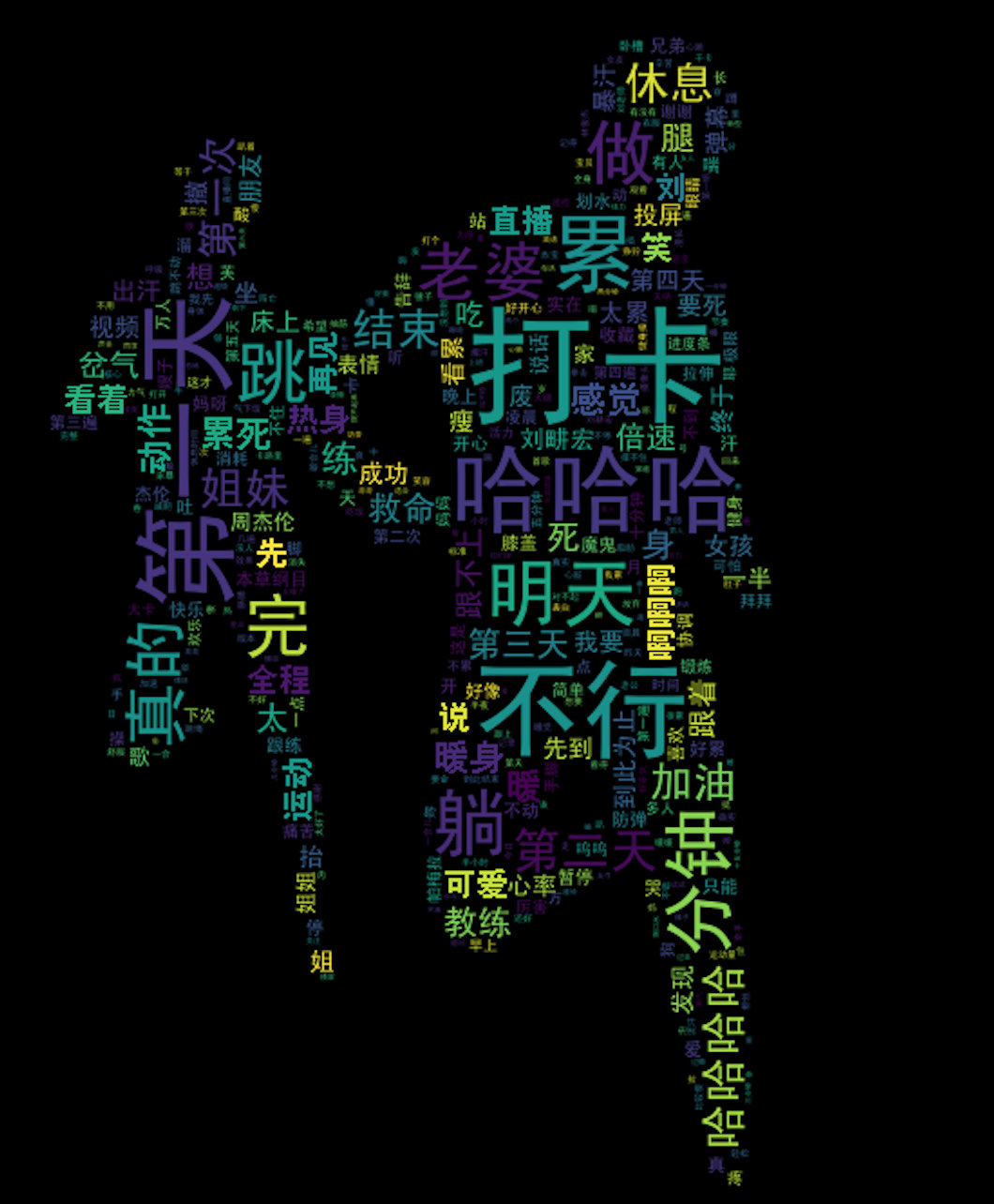

合成词云视频
基于上面的835张词云图来生成视频:
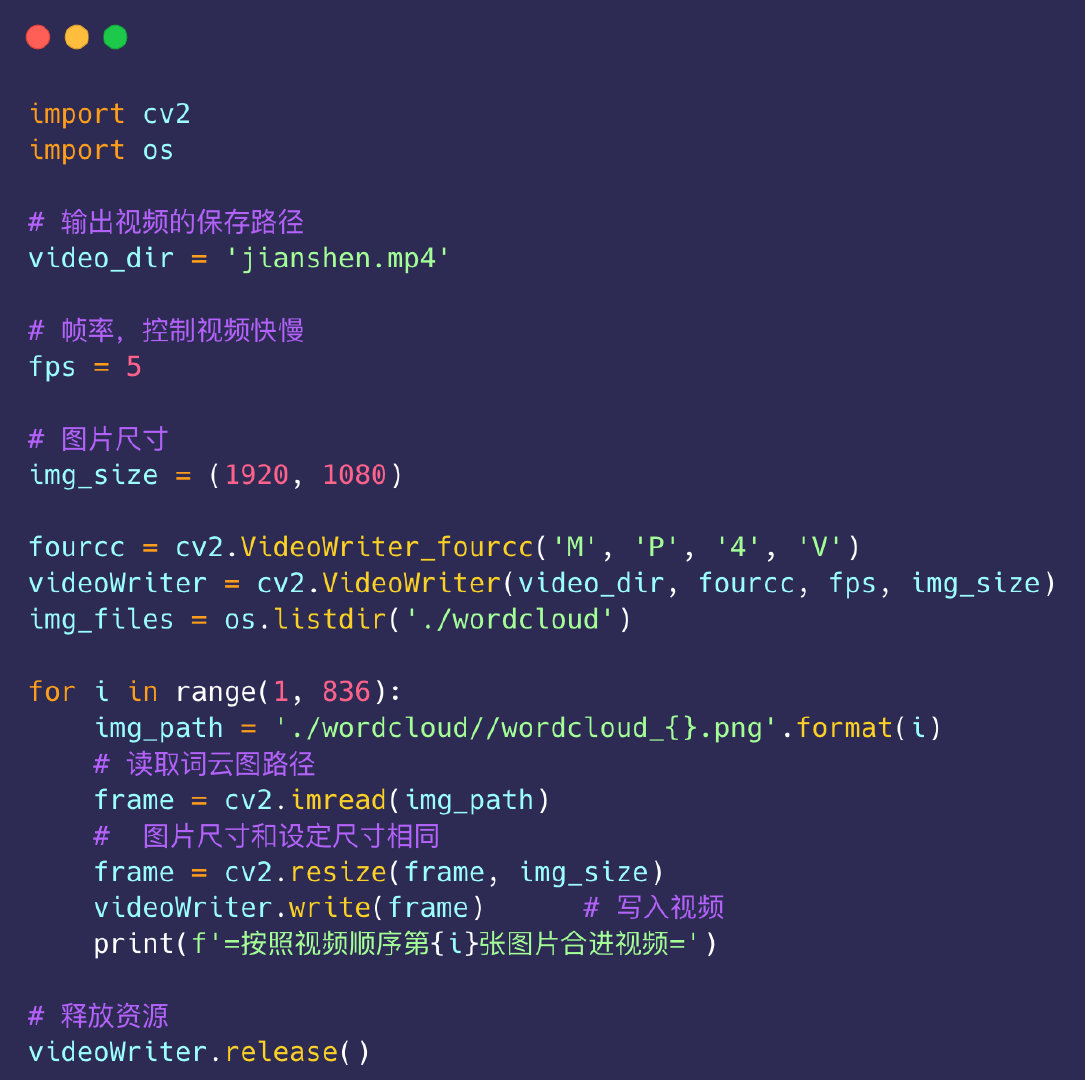
到达这个步骤我们完成了视频的生成,就只剩下添加【本草纲目】的音乐了
添加本草纲目.MP3
添加音频使用的是moviepy。详细使用文档参考官网:
中文:https://moviepy-cn.readthedocs.io/zh/latest/
英文:https://zulko.github.io/moviepy/install.html
pip install moviepy # 安装简单


大功告成👏
整体细节
-
将you-get获取到的视频和【本草纲目.MP3】放到本地 -
本地需要建立3个文件,存放不同的图像 -
代码的步骤参考1-2-3-4-5-6部分;顺序一定不能乱
以上是关于Python实现词云舞的主要内容,如果未能解决你的问题,请参考以下文章