图像描述文献阅读Comprehending and Ordering Semantics for Image Captioning
Posted 安静到无声
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像描述文献阅读Comprehending and Ordering Semantics for Image Captioning相关的知识,希望对你有一定的参考价值。

1. 摘要
理解图像中丰富的语义并按语言顺序排序,对于为图像标题编写一个有视觉基础的、语言上连贯的描述至关重要。现代技术通常利用预先训练好的物体检测器/分类器来挖掘图像中的语义,而对语义的内在语言排序却没有充分开发。在本文中,作者基于Transformer提出了一种新方法COS-Net,将语义理解和排序过程统一到新的框架内。首先利用一个跨模态的检索模型搜索每个图像相关的句子,并将搜索到的句子中的所用单词作为主要语义线索。接下来,我们设计了一个新的语义编译器来过滤掉主要语义线索中的不相关的语义词,同时推断出图像中缺少的相关语义词的视觉基础。然后,我们将所有筛选和丰富的语义词输入到一个语义排名器中,该排名器学习像人类一样按照语言顺序分配所有语义词。这种有序的语义词序列与图像的视觉标记进一步整合,从而触发句子生成。这种有序的语义词序列与图像的视觉标记进一步整合,从而触发句子生成。
2. 概述
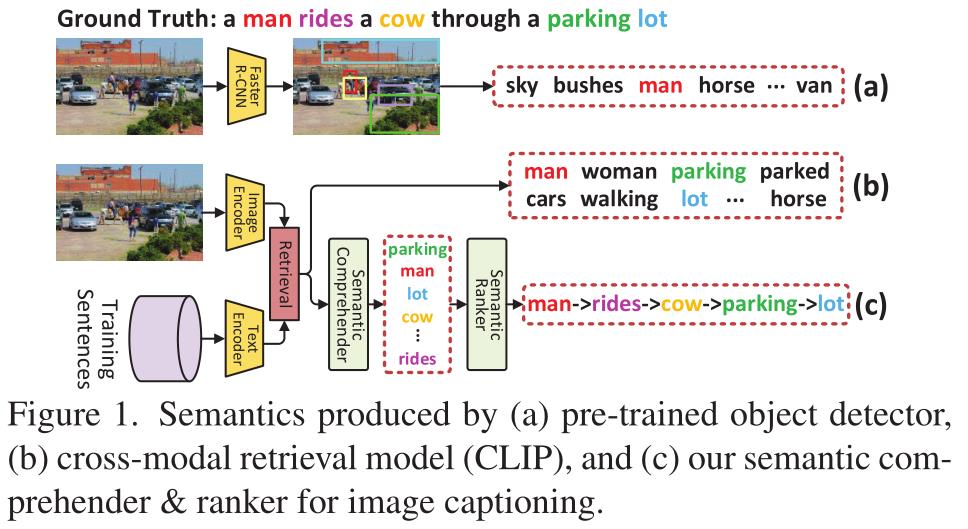
文章主要出发点是将语义理解和词汇排列统一到一个框架内,使其能够被共同优化,以更好地对句子进行解码,其主要过程如下:
- 首先将现成的CLIP作为跨模式检索模型,为输入图像检索语义相似的句子,如上图b的情况所示。
- 其次,基于CLIP中图像编码器输出网格特征,利用视觉编码器通过自注意机制将每个网格特征上下文编码为视觉标记。
- 语义理解器(semantic comprehender)以初级语义线索和视觉表征为输入,过滤掉初级语义线索中不相关的语义词(例如过滤掉Woman,walking),同时通过交叉注意机制重建缺失的相关语义词(如lot cow等)
- 语义排序器(semantic ranker)通过更新每个语义词的编码,使其在语言学上的位置得到估计,从而学会将所有精炼的语义词分配到合适的顺序。
- 最后,视觉标记和有序语义词都通过注意力机制动态地整合起来,从而对输出句子进行逐字解码(encode)。
总结来讲,COS-Net利用transformer风格构造了大多数模块(如visual encoder, sentence decoder, and semantic comprehender),所以可以认为是基于transformer的编码器-解码器方案。
3. 方法细节
总体来讲,该方法主要有视觉内容编码;语义理解;语义排序和句子解码四部分组成。实现如图1所示: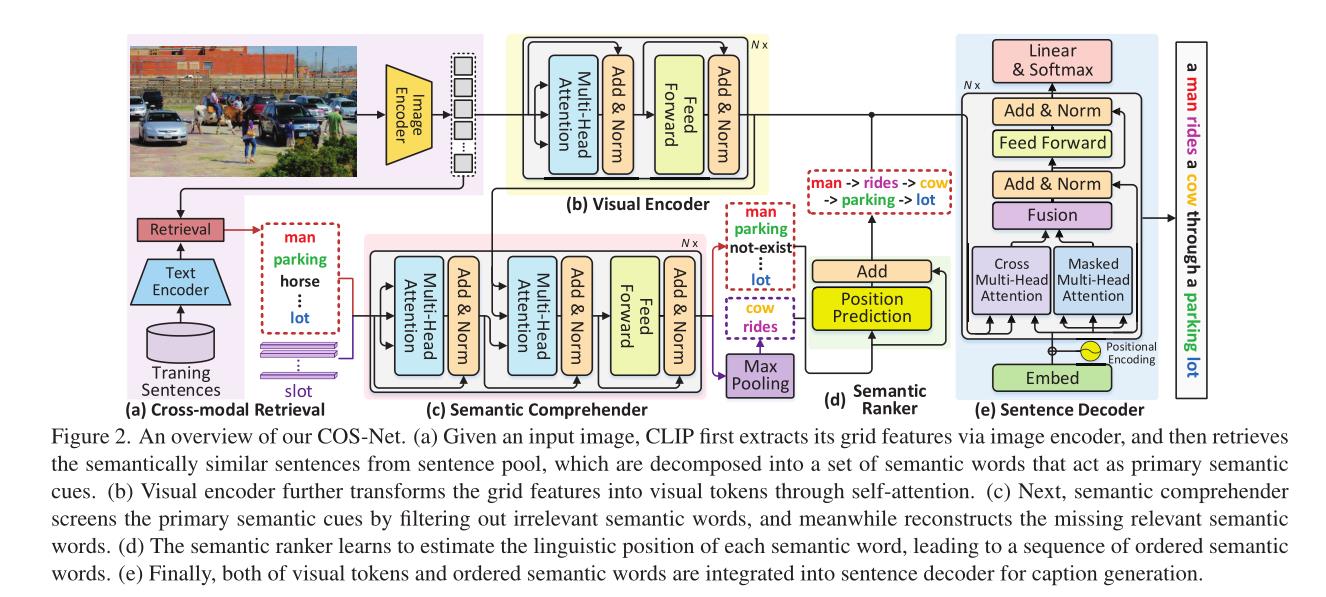
3.1 视觉内容编码
作者利用多个堆叠的Transformer,将是视觉内容编码为中间视觉标记。输入图像为
I
I
I,作者利用CLIP提取图像的网格特
V
I
=
v
i
∣
i
=
1
N
I
\\mathcalV_I=\\left.\\mathbfv_i\\right|_i=1 ^N_I
VI=vi∣i=1NI,其中
N
I
N_I
NI 是网格数,并结合全局的特征
v
c
v_c
vc,然后我们将全局特征和网格特征转化为新的嵌入空间( embedding space),然后级联得到
V
I
(
0
)
=
[
v
c
(
0
)
,
v
i
(
0
)
∣
i
=
1
N
I
]
\\mathcalV_I^(0)=\\left[\\mathbfv_c^(0),\\left.\\mathbfv_i^(0)\\right|_i=1 ^N_I\\right]
VI(0)=[vc(0),vi(0)∣
∣i=1NI],然后利用视觉编码器对得到的全局和网格特征
V
I
(
0
)
\\mathcalV_I^(0)
VI(0) 进行上下文的编码,从而得到丰富的视觉标记
V
I
(
N
v
)
=
[
v
c
(
N
v
)
,
v
i
(
N
v
)
∣
i
=
1
N
I
]
\\mathcalV_I^\\left(N_v\\right)=\\left[\\mathbfv_c^\\left(N_v\\right),\\left.\\mathbfv_i^\\left(N_v\\right)\\right|_i=1 ^N_I\\right]
VI(Nv)=[vc(Nv),vi(Nv)∣
∣i=1NI],具体说作者是通过多个
N
v
N_v
Nv Transformer blocks和多头注意力机制形成的。以第
i
i
i 个Transformer block为例,操作过程如下(公式1):
V
I
(
i
+
1
)
=
F
(
norm
(
V
I
(
i
)
+
MultiHead
(
V
I
(
i
)
,
V
I
(
i
)
,
V
I
(
i
)
)
)
)
MultiHead
I
(
Q
,
K
,
V
)
=
Concat
(
h
e
a
d
1
,
…
,
head
h
)
W
O
head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
)
V
\\beginaligned &\\mathcalV_I^(i+1)=\\mathcalF\\left(\\operatornamenorm\\left(\\mathcalV_I^(i)+\\operatornameMultiHead\\left(\\mathcalV_I^(i), \\mathcalV_I^(i), \\mathcalV_I^(i)\\right)\\right)\\right) \\\\ &\\text MultiHead _I(\\mathbfQ, \\mathbfK, \\mathbfV)=\\operatornameConcat\\left(h e a d_1, \\ldots, \\text head _h\\right) W^O \\\\ &\\text head _i=\\operatornameAttention\\left(\\mathbfQ W_i^Q, \\mathbfK W_i^K, \\mathbfV W_i^V\\right) \\\\ &\\text Attention (\\mathbfQ, \\mathbfK, \\mathbfV)=\\operatornamesoftmax\\left(\\frac\\mathbfQ \\mathbfK^T\\sqrtd\\right) \\mathbfV \\endaligned
VI(i+1)=F(norm(VI(i)+MultiHead(VI(i),VI(i),VI(i)))) MultiHead I(Q,K,V)=Concat(head1,…, head h)WO head i=Attention(QWiQ,KWiK,VWiV) Attention (Q,K,V)=softmax(dQKT)V 其中
F
\\mathcalF
F 代表前向传播层,
norm
\\operatornamenorm
norm 代表了层归一化,
W
i
Q
,
W
i
K
,
W
i
V
,
W
O
W_i^Q, W_i^K, W_i^V, W^O
WiQ,WiK,WiV,WO 是权重标准,
d
d
d 为缩放因子。同时,为了使层间全局特性交互,我们额外连接了来自所有Transformer块的输出全局特性,这些输出全局特性进一步转换为整体全局特性:
v
~
c
=
W
c
[
v
c
(
0
)
,
v
c
(
1
)
,
…
,
v
c
(
N
v
)
]
\\tilde\\mathbfv_c=W_c\\left[\\mathbfv_c^(0), \\mathbfv_c^(1), \\ldots, \\mathbfv_c^\\left(N_v\\right)\\right]
v~