100天精通Python(数据分析篇)——第59天:Pandas读写json文件(read_jsonto_json)
Posted 无 羡ღ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了100天精通Python(数据分析篇)——第59天:Pandas读写json文件(read_jsonto_json)相关的知识,希望对你有一定的参考价值。

文章目录
每篇前言
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进千人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
支持大部分主流关系型数据库,例如mysql,需要相应的数据库模块支持,相应接口为read_sql()和to_sql()
一、read_json()
语法格式:
pandas.read_json(
path_or_buf=None,
orient=None,
typ="frame",
dtype: DtypeArg | None = None,
convert_axes=None,
convert_dates=True,
keep_default_dates: bool = True,
numpy: bool = False,
precise_float: bool = False,
date_unit=None,
encoding=None,
encoding_errors: str | None = "strict",
lines: bool = False,
chunksize: int | None = None,
compression: CompressionOptions = "infer",
nrows: int | None = None,
storage_options: StorageOptions = None,
)
参数说明:
1. path_or_buf
需要读取的json文件对象
(1)JSON对象
import pandas as pd
import json
json_str = json.dumps(["name": '小明', "age": 10, "name": '小白', "age": 20])
print(json_str)
print(type(json_str))
df = pd.read_json(json_str)
print(df)
运行结果:
["name": "\\u5c0f\\u660e", "age": 10, "name": "\\u5c0f\\u767d", "age": 20]
<class 'str'>
name age
0 小明 10
1 小白 20
(2)JSON文件:
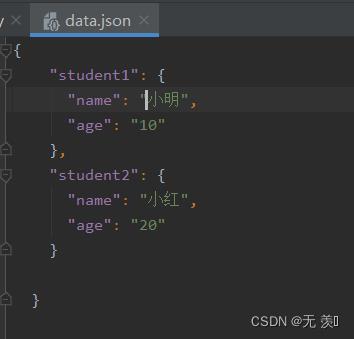
import pandas as pd
import json
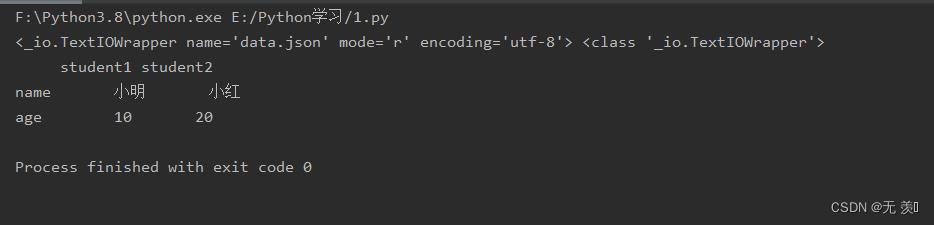
with open('data.json','r',encoding='utf-8')as json_str:
print(json_str,type(json_str))
df = pd.read_json(json_str)
print(df)
运行结果:
2. orient
指定解析json文件的格式,这个参数有多种选择状态,参数如下:
- ‘split’ : dict like index -> [index], columns -> [columns], data -> [values]
- ‘records’ : list like [column -> value, … , column -> value]
- ‘index’ : dict like index -> column -> value
- ‘columns’ : dict like column -> index -> value
- ‘values’ : 数组
- 允许的值和默认值取决于typ参数的值。
- 当typ == 'series’时,允许的方向是‘split’,‘records’,‘index’,默认是“index”,对于orient ‘index’,级数索引必须是唯一的。
- 当typ == ‘frame’,允许的方向是‘split’,‘records’,‘index’, ‘columns’,‘values’,默认是“columns”,对于方向的index和columns, DataFrame索引必须是唯一的。,对于定向’index’, ‘columns’和’records’, DataFrame列必须是唯一的
import pandas as pd
import json
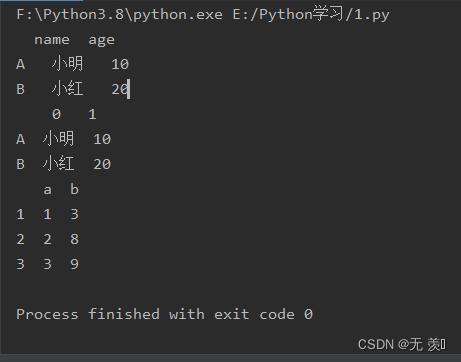
data1 = "A": "name": '小明', "age": 10, "B": "name": '小红', "age": 20
data2 = "A": ['小明', 10], "B": ['小红', 20]
data3 = "index": [1, 2, 3], "columns": ["a", "b"], "data": [[1, 3], [2, 8], [3, 9]]
print(pd.read_json(json.dumps(data1), orient="index"))
print(pd.read_json(json.dumps(data2), orient="index"))
print(pd.read_json(json.dumps(data3), orient="split"))
运行结果:
3. typ
指定要返回的对象类型 (series or frame), 默认值‘frame’
- frame:返回DataFrame
- series:返回Series
import pandas as pd
import json
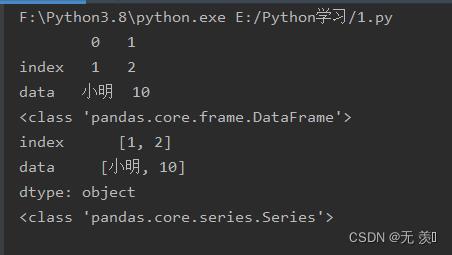
data = "index": [1,2], "data": ['小明',10]
# 返回DataFrame
df1 = pd.read_json(json.dumps(data), orient="index", typ="frame")
print(df1)
print(type(df1))
# 返回Series
df2 = pd.read_json(json.dumps(data), orient="index", typ="series")
print(df2)
print(type(df2))
运行结果:
4. dtype
推断或指定列的数据类型。boolean或dict,默认为True。如果为True,则推断自动类型;False 不推断数据类型。如果列的字典为dtype,根据列名指定数据类型。
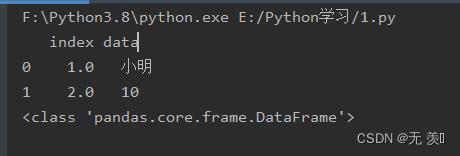
data = "index": [1,2], "data": ['小明',10]
df1 = pd.read_json(json.dumps(data), dtype="index": float)
print(df1)
print(type(df1))
运行结果:
5. convert_axes
接收boolean布尔类型,默认True。尝试将坐标轴转换为适当的dtype。
6. convert_dates
接收boolean布尔类型,默认True。要解析日期的列列表;如果为True,则尝试解析日期类列列标签与日期类似
- 以’_at’结尾,
- 以’_time’结尾,
- 以’timestamp’开头,
- 是’modified’,或者’date’
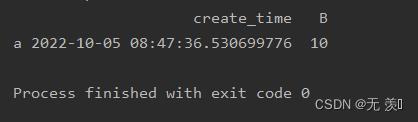
import pandas as pd
import json
import time
data = "create_time": "a": time.time(), "b": time.time(), "B": "a": 10, "b": 20
print(pd.read_json(json.dumps(data)))
运行结果:
7. keep_default_dates
接收boolean布尔类型,默认True。如果解析日期,则解析默认的日期类列
8. numpy
接收boolean布尔类型,默认False。 解析为数组, 直接解码到numpy数组。只支持数字数据,但支持非数字列和索引标签。还要注意,如果numpy=True,则每个术语的JSON顺序必须相同。
9. precise_float
接收boolean布尔类型,默认False。设置为在将字符串解码为双值时启用更高精度(strtod)函数。默认(False)是使用快速但不太精确的内置功能。
10. date_unit
接收字符串类型,默认None。用于检测是否转换日期的时间戳单元。默认行为是尝试检测正确的精度,但如果不需要这样做,则传递’ s ‘、’ ms ‘、’ us ‘或’ ns '中的一个,分别强制解析秒、毫秒、微秒或纳秒。
11. lines
接收boolean布尔类型,默认False。每行将文件作为json对象读取。0.19.0新版功能。
12. encoding
接收字符串类型,默认utf-8。用于解码py3字节的编码。0.19.0新版功能。
二、to_json()
语法格式:
DataFrame.to_json(
self,
path_or_buf: FilePathOrBuffer | None = None,
orient: str | None = None,
date_format: str | None = None,
double_precision: int = 10,
force_ascii: bool_t = True,
date_unit: str = "ms",
default_handler: Callable[[Any], JSONSerializable] | None = None,
lines: bool_t = False,
compression: CompressionOptions = "infer",
index: bool_t = True,
indent: int | None = None,
storage_options: StorageOptions = None,
) -> str | None:
参数说明:
1. path_or_buf
接收参数str、路径对象、文件类对象或None,默认为None。字符串,路径对象(实现os.PathLike[str]),或实现write()函数的文件类对象。如果为None,则结果作为字符串返回。
(1)写入文件:
import pandas as pd
data = 'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]
df = pd.DataFrame(data)
df.to_json('data.json')
运行结果:

(2)写入JSON字符串:
import pandas as pd
data = 'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]
df = pd.DataFrame(data)
json = df.to_json()
print(json)
运行结果:

2. orient
指定预期的JSON字符串格式。
1) Series:默认值为‘index’,允许的值为:‘split’,‘records’,‘index’,‘table’。
2) DataFrame:默认为‘columns’,允许的值为:‘split’,‘records’,‘index’,‘columns’,‘values’,‘table’。
3) JSON字符串格式:
- ‘split’:类似‘index’-> [index],
- ‘columns’-> [columns],‘data’-> [values]的字典
- ‘records’:类似于[column-> value,…,column-> value]的列表
- ‘index’:类似index-> column-> value的字典
- ‘columns’:类似column-> index-> value的字典
- ‘values’:只是值数组
- ‘table’:类似‘schema’:schema,‘data’:data的字典
import pandas as pd
data = 'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]
df = pd.DataFrame(data)
print(df.to_json(orient='split'))
print(df.to_json(orient='records'))
print(df.to_json(orient='index'))
print(df.to_json(orient='columns'))
print(df.to_json(orient='values'))
print(df.to_json(orient='table'))
运行结果:
"columns":["name","age"],"index":[0,1,2],"data":[["\\u5c0f\\u7ea2",10],["\\u5c0f\\u660e",20],["\\u5c0f\\u767d",30]]
["name":"\\u5c0f\\u7ea2","age":10,"name":"\\u5c0f\\u660e","age":20,"name":"\\u5c0f\\u767d","age":30]
"0":"name":"\\u5c0f\\u7ea2","age":10,"1":"name":"\\u5c0f\\u660e","age":20,"2":"name":"\\u5c0f\\u767d","age":30
"name":"0":"\\u5c0f\\u7ea2","1":"\\u5c0f\\u660e","2":"\\u5c0f\\u767d","age":"0":10,"1":20,"2":30
[["\\u5c0f\\u7ea2",10],["\\u5c0f\\u660e",20],["\\u5c0f\\u767d",30]]
"schema":"fields":["name":"index","type":"integer","name":"name","type":"string","name":"age","type":"integer"],"primaryKey":["index"],"pandas_version":"0.20.0","data":["index":0,"name":"\\u5c0f\\u7ea2","age":10,"index":1,"name":"\\u5c0f\\u660e","age":20,"index":2,"name":"\\u5c0f\\u767d","age":30]
3. date_format
日期转换的类型可选参数‘epoch’, ‘iso’,默认为None。‘epoch’= epoch milliseconds,‘iso’= ISO8601。默认值取决于orient。对于 orient=‘table’,默认值为’iso’。对于所有其他东方,默认值为‘epoch’.。
import pandas as pd
import datetime
data = 'time': [datetime.date.today(), datetime.date(2022, 5, 20)]
df = pd.DataFrame(data)
print(df.to_json(date_format='epoch'))
print(df.to_json(date_format='iso'))
运行结果:

4. double_precision
在对浮点值进行编码时要使用的小数位数。接收int类型,默认为10,最大值为15
df.to_json(double_precision=15)
5. force_ascii
强制将字符串编码为ASCII。接收bool布尔类型,默认为True
6. date_unit
要编码的时间单位,控制时间戳和ISO8601精度。接收str,默认为“ms”(毫秒)。“s”,“ms”,“us”,“ns”之一分别表示秒,毫秒,微秒和纳秒。
7. default_handler
callable, 默认为None。如果对象不能转换为适合JSON的格式,则调用。应该接收一个参数,该参数是要转换的对象并返回一个可序列化对象。
8. lines :
接收bool布尔类型, 默认为 False。如果’orient’是’records’,则写出行分隔的json格式。如果不正确的‘orient’将抛出ValueError,因为其他人没有列出。
9. compression
接收参数: ‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None,表示要在输出文件中使用的压缩的字符串,仅在第一个参数是文件名时使用。默认情况下,压缩是从文件名推断出来的。在0.24.0版本中更改:增加了“infer”选项并将其设置为默认
10. index :
接收bool布尔类型, 默认为 True。是否在JSON字符串中包括索引值。仅当Orient是“split”或“table”时,才支持不包括index(index=False)。0.23.0版中的新功能。
11. indent :
接收int类型, 可选。用于缩进每条记录的空白长度。1.0.0版的新功能。
12. storage_options
接收dict类型,可选。对特定存储连接有意义的额外选项,例如主机、端口、用户名、密码等。对于HTTP(S) url,键值对作为报头选项转发到urllib.request.Request。对于其他url(例如以“s3://”和“gcs://”开头),键值对被转发到fspec .open。
13. Returns
接收None 或 str。如果path_or_buf为None,则将生成的json格式作为字符串返回。否则返回None。
三、书籍推荐

【书籍内容简介】
- 本书介绍了数据分析的方法和步骤,并分别通过Excel和Python实施和对比。通过本书一方面可以拓宽对Excel功能的认识,另一方面可以学习和掌握Python的基础操作。
本书分为 11 章,涵盖的主要内容有Excel和Python在数据分析领域的定位与核心功能对比、统计量介绍、Excel与Python实践环境搭建、数据处理与分析的基本方法、ETL方法、数据建模理论、数据挖掘基础、数据可视化的基本方法、分析报告的制作方法。
以上是关于100天精通Python(数据分析篇)——第59天:Pandas读写json文件(read_jsonto_json)的主要内容,如果未能解决你的问题,请参考以下文章