编译原理学习笔记
Posted hesorchen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理学习笔记相关的知识,希望对你有一定的参考价值。
目录
引论
什么是编译程序
翻译程序:把某一种语言程序(源语言程序)等价地转换成另一种语言程序(目标语言程序)的程序。

编译程序:编译程序也是一种翻译程序,把某一种高级语言等价的转换为另一种低级语言程序(如汇编语言或机器语言程序)的程序。

解释程序:解释程序也是一种翻译程序,把源语言的源程序作为输入,但不产生目标程序,而是边解释边执行源程序。
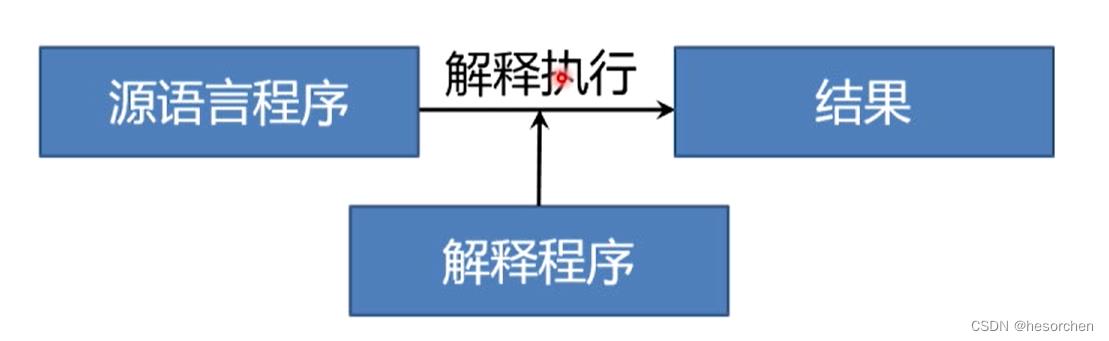
为什么要学习编译原理
从计算机科学与技术中学什么?
一系列广泛的计算机科学的思维方法:
- 抽象
- 自动化
- 问题分解
- 递归
- 权衡
- 保护、冗余、容错、纠错、恢复
- 利用启发式推理来寻求解答
- 在不确定情况下的规划、学习和调度
… …
这些方法在日常生活中也会产生作用。
编译原理是理论和实践相结合的最好典范。
抽象
-
忽略一个主题中与当前问题(或目标)无关的那些方面,以便更充分地注意与当前问题(或目标)有关的方面
-
以众多的事物中抽取出共同、本质性的特征,舍弃其非本质的特征
-
是一种从个体把握一般、从现象把握本质的认知过程和思维方法
-
图灵机
自动化
- 有限自动机、预测分析程序、算符优先分析、LR分析
问题分解
-
将大规模的复杂问题分解成若干个较小规模、更简单的问题加以解决
-
层次化管理
-
编译程序引入中间语言
-
编译过程分成多个阶段(语法分析、词法分析等)
递归
-
问题的解决依赖于类似问题的解决,只不过后者的复杂度更小
-
一旦将问题的复杂程度和规模化简化到足够小时,问题的解法非常简单。
-
递归下降分析法
-
基于树遍历的属性计算
-
语法制导翻译
权衡
-
理论可实现 VS 实际可实现
-
理论研究重在探寻问题求解的方法,对于理论成果的研究运用有需要在能力和运用中做出权衡
-
用上下文无关文法来描述和处理高级程序语言
-
优化措施的选择
编译原理的应用
html、xml分析、语言处理工具、Shell、http、SQL、翻译
编译过程
用中英文翻译类比
| 中英文翻译 | 编译 |
|---|---|
| 识别出句子中的一个个单词 | 词法分析 |
| 分析句子的语法结构 | 语法分析 |
| 根据句子的含义进行初步翻译 | 语义分析、中间代码生成 |
| 对译文进行修饰 | 优化 |
| 写出最后的译文 | 目标代码产生 |

编译程序的结构
编译程序总框

遍
所谓“遍”,是指对程序扫描一遍。
阶段与遍是不同的概念
一遍可以包含若干个阶段 - 词法分析、语法分析
一个阶段也可以分成多遍 - 优化
编译前后端
- 前端
与源语言有关,如词法分析,语法分析,语义分析与中间代码产生,与机器无关的优化
- 后端
与目标机有关的优化,目标代码的产生
- 带来的好处
可移植性更强、程序逻辑结构清晰
高级程序设计语言概述
常用的高级程序设计语言
| 语言 | 特点 |
|---|---|
| Fortran | 数值计算 |
| Cobol | 事务处理 |
| Pascal | 结构化程序设计 |
| Lisp | 函数式程序设计 |
| Prolog | 逻辑程序设计 |
| C | 系统程序设计 |
| Smalltalk | 面向对象程序设计 |
| Java | Internet应用 |
| Python | 解释型语言 |
相对于机器语言或汇编语言,高级程序设计语言。
- 更接近于数学语言和工程语言,更直观、自然和易于理解
- 更容易验证其正确性
- 编写程序的效率更高
- 更容易移植
程序设计语言的定义
- 词法规则
一般包括:常数、标识符、基本字、算符、界符等
描述工具:有限自动机
- 语法规则
语法单位通常包括:表达式、语句、分程序、过程、函数、程序等
描述工具:上下文无关文法
E -> i :一个标识符可以单独构成一个算术表达式
E -> E + E:一个算术表达式可以由两个算术表达式构成
E -> E * E:一个算术表达式可以由两个算术表达式构成
E -> (E):一个算术表达式加上括号还是一个算术表达式
高级程序设计语言的一般特性
高级语言的分类
- 过程式语言
- 应用式语言
- 基于规则的语言
- 面向对象的语言
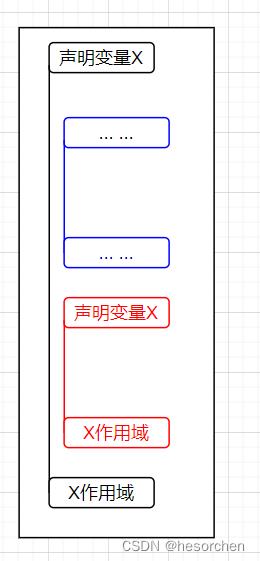
最近嵌套原则
- 一个在子程序B1中说明的名字只在B1中有效
- 如果B2是B1的一个内层子程序且B2中对标识符X没有新的说明,则原来的名字X在B2中仍然有效。【蓝色部分】
- 如果B2对X重新做了说明,那么,B2对X的任何引用都是指重新说明过的这个X。【红色部分】
数据类型与操作
数据类型三要素
- 数据对象的属性
- 数据对象的取值
- 可用于数据对象的操作
常见语句类型:
-
数值类型
整形、浮点型
可使用+、-、*、/ -
布尔类型
true、false
可使用&、|
标识符与名字
名字的绑定是指将标识符与所代表的程序数据或代码进行关联
静态绑定:在编译过程中的绑定称为静态绑定。如声明一个整形变量。
动态绑定:在运行时的绑定称为动态绑定。如C++中的多态性、虚函数。
- 标识符
语法概念
以字母开头的,由数字和字母组成的字符串。
- 名字
语义概念
名字有确切的意义和属性。
数据结构
- 数组
数组是有同一类型数据组成的某种n维矩形结构,沿着每一维的距离,称为下标。
编译时确定长度的称为不可变数组,否则称为可变数组。
还分为按行存放、按列存放。
- 记录
由已知的数据组合在一起的一种结构
record
char name[20];
interger age;
cards[1000];
访问:cards[k].name
其他常用数据结构:字符串、栈、队列、表格、链表等。
表格:本质上是记录数组
抽象数据类型
对类型对象的封装,即,除了使用类型中所定义的运算外,用户不能对这些对象进行操作。
高级程序设计语言的语法描述
上下文无关文法
-
字母表:一个有穷字符集,记为 Σ \\Sigma Σ
-
字母表中每个元素称为字符
-
Σ \\Sigma Σ上的字(也叫字符串)是指由 Σ \\Sigma Σ中的字符所构成的一个又穷序列。
-
不包含任何字符的序列称为空字,记为 ε \\varepsilon ε
-
Σ \\Sigma Σ* 表示 Σ \\Sigma Σ上的所有字的全体,包含 ε \\varepsilon ε
例如, Σ \\Sigma Σ=a,b,则 Σ \\Sigma Σ= ε \\varepsilon ε,a,b,aa,ab,ba,bb,aaa,… …*
- Σ \\Sigma Σ*的子集 U U U和 V V V的连接(积)定义为 U V UV UV= α β \\alpha\\beta αβ| α ∈ U & β ∈ V \\alpha \\in U \\& \\beta \\in V α∈U&β∈V
例如, U U U= a , b a,b a,b, V V V= c , d c,d c,d,则 U V UV UV= a c , a d , b c , b d ac,ad,bc,bd ac,ad,bc,bd
-
一个字符集 V V V 的 n n n次积记作 V n = V V . . . V V^n=V V ...V Vn=VV...V(共n个 V V V)。特别的, V 0 V ^ 0 V0= ε \\varepsilon ε
-
V V V *是 V V V的闭包: V V V * = $V^0 \\cup V^1 \\cup V^2 \\cup … … $
-
V V V+是 V V V的正规闭包: V V V+ = V V V V VV *
闭包与正规闭包的区别:假设V中不包含空字 ε \\varepsilon ε,那么闭包中包含空字,而正规闭包中不包含空字
上下文无关文法G是一个四元组 G = ( V T , V N , S , P ) G= (V_T,V_N,S,P) G=(VT,VN,S,P),其中
V
T
V_T
VT:终结符(Terminator)集合
V
N
V_N
VN:非终结符(Nonterminator)集合
P
P
P:产生式
S
S
S:文法开始的符号,这是一个特殊的非终结符
一般约定:
- 第一条产生式的左部是开始符号。
- 用大写字母表示非终结符,小写字母表示终结符
- 设文法G开始符号为S,我们可以将文法写成G[S]
- 为了简洁,将相同左部的多个产生式,右部用“|”符号连接
有时候不需要将文法G的四元组显式地表示出来,只将产生式写出即可。因为产生式中已经包含了所有非终结符、终结符。
下面几种文法的表示方法都是等价的:
G=(S,A,a,b,P,S)
其中P:
S -> Ad
A -> a
A -> b
A -> c
G[S]:
S -> Ad
A -> a
A -> b
A -> c
G[S]:
S -> Ad
A -> a|b|c
文法与语言
推导
推导:将某个非终结符用某个产生式的右部进行替换展开,直到产生式中全部为终结符为止,这个过程称为推导。
对文法G(E):E->E+E|E*E|i|(E)进行推导:
E ⇒ E + E ⇒ i + E ⇒ i + i E\\Rightarrow E+E\\Rightarrow i+E\\Rightarrow i+i E⇒E+E⇒i+E⇒i+i

句型、句子和语言
- 文法G推导过程中产生的所有符号串称为句型。
- 仅包含终结符的句型称为句子。
- 所有句子的集合称为文法G的语言。
证明i*(i+i)是文法E->(E)|E*E|E+E|i的一个句子:
E ⇒ E ∗ E ⇒ E ∗ ( E ) ⇒ E ∗ ( E + E ) ⇒ i ∗ ( E + E ) ⇒ i ∗ ( i + E ) ⇒ i ∗ ( i + i ) E\\Rightarrow E*E\\Rightarrow E*(E)\\Rightarrow E*(E+E)\\Rightarrow i*(E+E)\\Rightarrow i*(i+E)\\Rightarrow i*(i+i) E⇒E∗E⇒E∗(E)⇒E∗(E+E)⇒i∗(E+E)⇒i∗(i+E)⇒i∗(i+i)
利用递归思维,解决 给出语言求文法、给出文法求语言 相关问题:
- 请求出 a n b n ∣ n > 0 a^nb^n|n>0 anbn∣n>0的文法
- 请求出文法G(E):
E -> ab
E -> aEb
产生的语言
语法树与二义性
最左推导和最右推导
从一个句型到另一个的推导往往不唯一
E ⇒ E + E ⇒ i + E ⇒ i + i E\\Rightarrow E+E\\Rightarrow i+E\\Rightarrow i+i E⇒E+E⇒i+E⇒i+i
E ⇒ E + E ⇒ E + i ⇒ i + i E\\Rightarrow E+E\\Rightarrow E+i\\Rightarrow i+i E⇒E+E⇒E+i⇒i+i
最左推导:任何一步推导都是对当前句型中的最左非终结符进行替换
最右推导:任何一步推导都是对当前句型中的最右非终结符进行替换
语法树
E ⇒ E ∗ E ⇒ E ∗ ( E ) ⇒ E ∗ ( E + E ) ⇒ i ∗ ( E + E ) ⇒ i ∗ ( i + E ) ⇒ i ∗ ( i + i ) E\\Rightarrow E*E\\Rightarrow E*(E)\\Rightarrow E*(E+E)\\Rightarrow i*(E+E)\\Rightarrow i*(i+E)\\Rightarrow i*(i+i) E⇒E∗E⇒E∗(E)⇒E∗(E+E)⇒i∗(E+E)⇒i∗(i+E)⇒i∗(i+i)
以下是上述文法的语法树
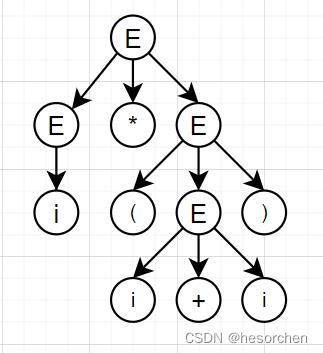
最左推导和最右推导最后得到的语法树是一样的,只不过生长顺序不同。
二义性:
-
文法的二义性:如果一个文法存在某个句子对应两颗不同的语法树,则说这个文法是二义的。
-
语言的二义性:如果能找到一个二义性的、能产生该语言的文法,该语言是二义的。
形式语言鸟瞰
0/1/2/3型文法,四种文法都包含终结符、非终结符、开始符号,但是对产生式的限制不一样。

