Go源码阅读——map.go
Posted Wang-Junchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go源码阅读——map.go相关的知识,希望对你有一定的参考价值。
【博文目录>>>】 【项目地址>>>】
Go Map实现
map.go文件包含Go的映射类型的实现。
映射只是一个哈希表。数据被安排在一系列存储桶中。每个存储桶最多包含8个键/元素对。哈希的低位用于选择存储桶。每个存储桶包含每个哈希的一些高阶位,以区分单个存储桶中的条目。
如果有8个以上的键散列到存储桶中,则我们会链接到其他存储桶。
当散列表增加时,我们将分配一个两倍大数组作为新的存储桶。将存储桶以增量方式从旧存储桶阵列复制到新存储桶阵列。
映射迭代器遍历存储桶数组,并按遍历顺序返回键(存储桶#,然后是溢出链顺序,然后是存储桶索引)。为了维持迭代语义,我们绝不会在键的存储桶中移动键(如果这样做,键可能会返回0或2次)。在扩展表时,迭代器将保持对旧表的迭代,并且必须检查新表是否将要迭代的存储桶(“撤离”)到新表中。
选择loadFactor:太大了,我们有很多溢出桶,太小了,我们浪费了很多空间。一些不同负载的统计信息:(64位,8字节密钥和elems)
loadFactor %overflow bytes/entry hitprobe missprobe
4.00 2.13 20.77 3.00 4.00
4.50 4.05 17.30 3.25 4.50
5.00 6.85 14.77 3.50 5.00
5.50 10.55 12.94 3.75 5.50
6.00 15.27 11.67 4.00 6.00
6.50 20.90 10.79 4.25 6.50
7.00 27.14 10.15 4.50 7.00
7.50 34.03 9.73 4.75 7.50
8.00 41.10 9.40 5.00 8.00
%overflow = 具有溢出桶的桶的百分比
bytes/entry = 每个键值对使用的字节数
hitprobe = 查找存在的key时要检查的条目数
missprobe = 查找不存在的key要检查的条目数
数据结构
重要常量
const (
// 桶可以容纳的最大键/值对数量。
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// 触发增长的存储桶的最大平均负载为6.5。表示为loadFactorNum/loadFactDen,以允许整数数学运算。
loadFactorNum = 13
loadFactorDen = 2
// 保持内联的最大键或elem大小(而不是每个元素的malloc分配)。
// 必须适合uint8。
// 快速版本不能处理大问题 - cmd/compile/internal/gc/walk.go中快速版本的临界大小最多必须是这个元素。
maxKeySize = 128
maxElemSize = 128
// 数据偏移量应为bmap结构的大小,但需要正确对齐。对于amd64p32,
// 即使指针是32位,这也意味着64位对齐。
dataOffset = unsafe.Offsetof(struct
b bmap
v int64
.v)
// 可能的tophash值。我们为特殊标记保留一些可能性。
// 每个存储桶(包括其溢出存储桶,如果有的话)在迁移状态下将具有全部或没有条目
//(除了evacuate()方法期间,该方法仅在映射写入期间发生,因此在此期间没有其他人可以观察该映射)。
// 所以合法的 tophash(指计算出来的那种),最小也应该是4,小于4的表示的都是我们自己定义的状态值
// 此单元格是空的,并且不再有更高索引或溢出的非空单元格。
emptyRest = 0
// 这个单元格是空的
emptyOne = 1
// 键/元素有效。条目已被迁移到大表的前半部分。
evacuatedX = 2
// 与上述相同,但迁移到大表的后半部分。
evacuatedY = 3
// 单元格是空的,桶已已经被迁移。
evacuatedEmpty = 4
// 一个正常填充的单元格的最小tophash
minTopHash = 5
// 标志位
iterator = 1 // 可能有一个使用桶的迭代器
oldIterator = 2 // 可能有一个使用oldbuckets的迭代器
hashWriting = 4 // 一个goroutine正在写映射
sameSizeGrow = 8 // 当前的映射增长是到一个相同大小的新映射
noCheck = 1<<(8*sys.PtrSize) - 1 // 用于迭代器检查的哨兵桶ID
)
const maxZero = 1024 // 必须与cmd/compile/internal/gc/walk.go:zeroValSize中的值匹配
var zeroVal [maxZero]byte // 用于:1、指针空时,返回unsafe.Pointer;2、用于帮助判断空指针;3、防止指针越界
存储结构定义
hmap是go中map结构的定义,其内容如下
type hmap struct
// 注意:hmap的格式也编码在cmd/compile/internal/gc/reflect.go中。确保这与编译器的定义保持同步。
// #存活元素==映射的大小。必须是第一个(内置len()使用)
count int
flags uint8
// 桶数的log_2(最多可容纳loadFactor * 2 ^ B个元素,再多就要扩容)
B uint8
// 溢出桶的大概数量;有关详细信息,请参见incrnoverflow
noverflow uint16
// 哈希种子
hash0 uint32 // hash seed
// 2^B个桶的数组。如果count == 0,则可能为nil。
buckets unsafe.Pointer
// 上一存储桶数组,只有当前桶的一半大小,只有在增长时才为非nil
oldbuckets unsafe.Pointer
// 迁移进度计数器(小于此的桶表明已被迁移)
nevacuate uintptr
// 可选择字段,溢出桶的内容全部在这里
extra *mapextra
mapextra是ma的溢出数据的定义,内容如下:
/**
* mapextra包含并非在所有map上都存在的字段。
**/
type mapextra struct
// 如果key和elem都不包含指针并且是内联的,则我们将存储桶类型标记为不包含指针。这样可以避免扫描此类映射。
// 但是,bmap.overflow是一个指针。为了使溢出桶保持活动状态,我们将指向所有溢出桶的指针存储在hmap.extra.overflow
// 和hmap.extra.oldoverflow中。仅当key和elem不包含指针时,才使用overflow和oldoverflow。
// overflow包含hmap.buckets的溢出桶。 oldoverflow包含hmap.oldbuckets的溢出存储桶。
// 间接允许在Hiter中存储指向切片的指针。
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow拥有一个指向空闲溢出桶的指针。
nextOverflow *bmap
bmap是map的桶定义,其他内容如下
/**
* go映射的桶结构
**/
type bmap struct
// tophash通常包含此存储桶中每个键的哈希值的最高字节。如果tophash[0] < minTopHash,
// 随后是bucketCnt键,再后是bucketCnt元素。
tophash [bucketCnt]uint8
// 注意:将所有键打包在一起,然后将所有elems打包在一起,使代码比交替key/elem/key/elem/...复杂一些,
// 但是它使我们可以省去填充,例如,映射[int64] int8。后跟一个溢出指针。
hiter是map的替代器定义,其他内容如下
/**
* 哈希迭代结构。
* 如果修改了hiter,还请更改cmd/compile/internal/gc/reflect.go来指示此结构的布局。
**/
type hiter struct
// 必须处于第一位置。写nil表示迭代结束(请参阅cmd/internal/gc/range.go)。
key unsafe.Pointer
// 必须位于第二位置(请参阅cmd/internal/gc/range.go)。
elem unsafe.Pointer
t *maptype // map类型
h *hmap
// hash_iter初始化时的bucket指针
buckets unsafe.Pointer
// 当前迭代的桶
bptr *bmap
// 使hmap.buckets溢出桶保持活动状态
overflow *[]*bmap
// 使hmap.oldbuckets溢出桶保持活动状态
oldoverflow *[]*bmap
// 存储桶迭代始于指针位置
startBucket uintptr // bucket iteration started at
// 从迭代期间开始的桶内距离start位置的偏移量(应该足够大以容纳bucketCnt-1)
offset uint8
// 已经从存储桶数组的末尾到开头缠绕了,迭代标记,为true说明迭代已经可以结束了
wrapped bool
B uint8 // 与hmap中的B对应
i uint8
bucket uintptr
checkBucket uintptr
其他数据结构
map中还使用到maptype数据结构。可以说明可见:https://github.com/Wang-Jun-Chao/go-source-read/blob/master/reflect/type_go.md
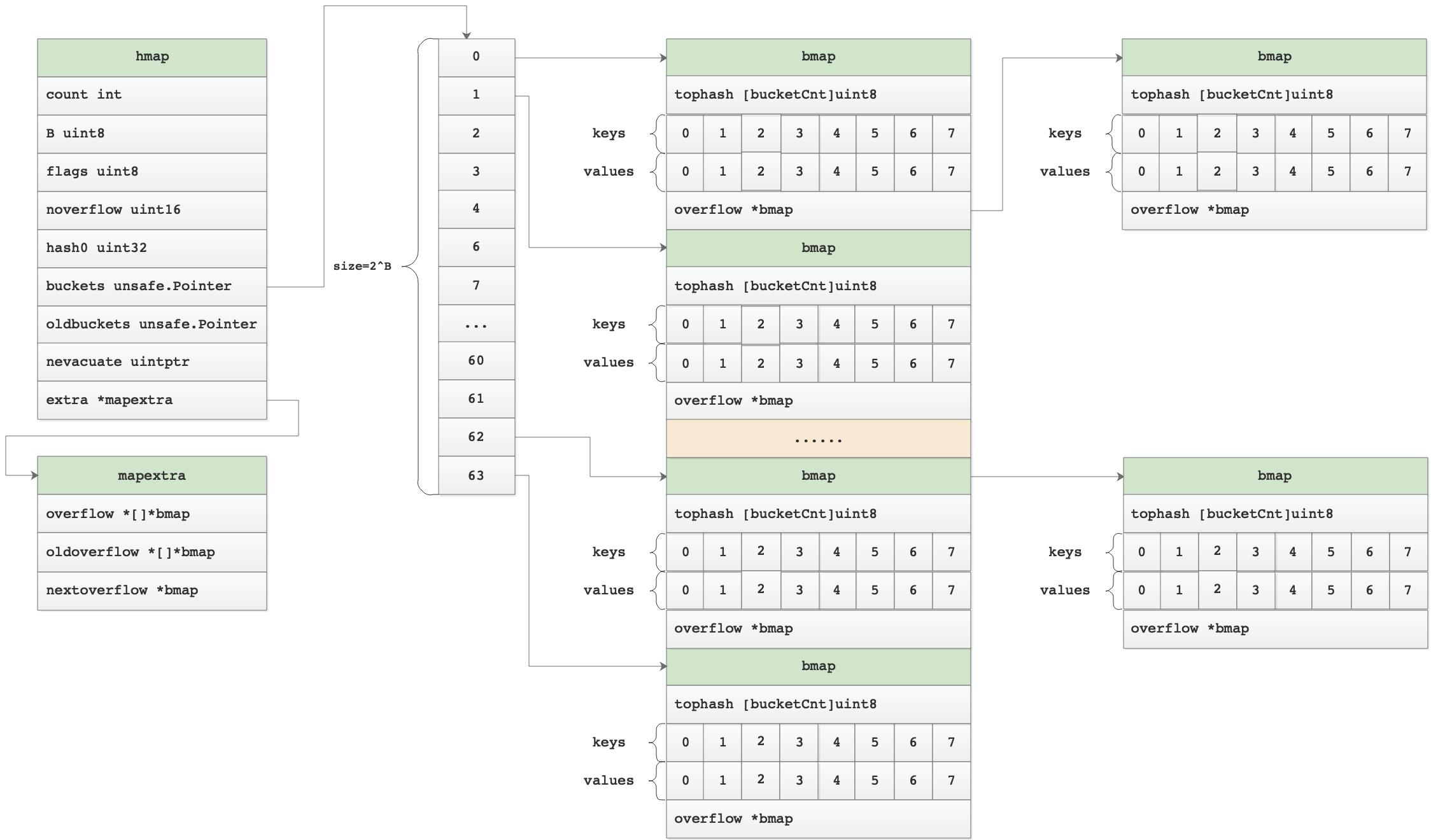
map存储结构示意图
创建map
go map创建
make(map[k]v),(map[k]v, hint)
小map创建
/**
* 当在编译时已知hint最多为bucketCnt并且需要在堆上分配映射时,
* makemap_small实现了make(map[k]v)和make(map[k]v, hint)的Go映射创建。
**/
func makemap_small() *hmap
h := new(hmap)
h.hash0 = fastrand()
return h
大map创建
/**
* 创建hmap,主要是对hint参数进行判定,不超出int可以表示的值
**/
func makemap64(t *maptype, hint int64, h *hmap) *hmap
if int64(int(hint)) != hint
hint = 0
return makemap(t, int(hint), h)
/**
* makemap实现Go map创建,其实现方法是make(map[k]v)和make(map[k]v, hint)。
* 如果编译器认为map和第一个 bucket 可以直接创建在栈上,h和bucket 可能都是非空
* 如果h!= nil,则可以直接在h中创建map。
* 如果h.buckets != nil,则指向的存储桶可以用作第一个存储桶。
**/
func makemap(t *maptype, hint int, h *hmap) *hmap
// 计算所需要的内存空间,并且判断是是否会有溢出
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc // 有溢出或者分配的内存大于最大分配内存
hint = 0
// 初始化hmap
if h == nil
h = new(hmap)
h.hash0 = fastrand() // 设置随机数
// 找到用于保存请求的元素数的大小参数B。
// 对于hint<0,由于hint < bucketCnt,overLoadFactor返回false。
B := uint8(0)
// 按照提供的元素个数,找一个可以放得下这么多元素的 B 值
for overLoadFactor(hint, B)
B++
h.B = B
// 如果B == 0,则分配初始哈希表,则稍后(在mapassign中)延迟分配buckets字段。
// 如果hint为零,则此内存可能需要一段时间。
// 因为如果 hint 很大的话,对这部分内存归零会花比较长时间
if h.B != 0
var nextOverflow *bmap
// 创建数据桶和溢出桶
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil // 溢出桶不为空就将溢出桶挂到附加数据上
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
return h
实际选用哪个函数很复杂,涉及的判定变量有:
- 1、hint值,以及hint最终类型:
- 2、逃逸分析结果
- 3、BUCKETSIZE=8
创建map选择的map函数分析在代码:/usr/local/go/src/cmd/compile/internal/gc/walk.go:1218中
case OMAKEMAP:
t := n.Type
hmapType := hmap(t)
hint := n.Left
// var h *hmap
var h *Node
if n.Esc == EscNone
// Allocate hmap on stack.
// var hv hmap
hv := temp(hmapType)
zero := nod(OAS, hv, nil)
zero = typecheck(zero, ctxStmt)
init.Append(zero)
// h = &hv
h = nod(OADDR, hv, nil)
// Allocate one bucket pointed to by hmap.buckets on stack if hint
// is not larger than BUCKETSIZE. In case hint is larger than
// BUCKETSIZE runtime.makemap will allocate the buckets on the heap.
// Maximum key and elem size is 128 bytes, larger objects
// are stored with an indirection. So max bucket size is 2048+eps.
if !Isconst(hint, CTINT) ||
hint.Val().U.(*Mpint).CmpInt64(BUCKETSIZE) <= 0
// var bv bmap
bv := temp(bmap(t))
zero = nod(OAS, bv, nil)
zero = typecheck(zero, ctxStmt)
init.Append(zero)
// b = &bv
b := nod(OADDR, bv, nil)
// h.buckets = b
bsym := hmapType.Field(5).Sym // hmap.buckets see reflect.go:hmap
na := nod(OAS, nodSym(ODOT, h, bsym), b)
na = typecheck(na, ctxStmt)
init.Append(na)
if Isconst(hint, CTINT) && hint.Val().U.(*Mpint).CmpInt64(BUCKETSIZE) <= 0
// Handling make(map[any]any) and
// make(map[any]any, hint) where hint <= BUCKETSIZE
// special allows for faster map initialization and
// improves binary size by using calls with fewer arguments.
// For hint <= BUCKETSIZE overLoadFactor(hint, 0) is false
// and no buckets will be allocated by makemap. Therefore,
// no buckets need to be allocated in this code path.
if n.Esc == EscNone
// Only need to initialize h.hash0 since
// hmap h has been allocated on the stack already.
// h.hash0 = fastrand()
rand := mkcall("fastrand", types.Types[TUINT32], init)
hashsym := hmapType.Field(4).Sym // hmap.hash0 see reflect.go:hmap
a := nod(OAS, nodSym(ODOT, h, hashsym), rand)
a = typecheck(a, ctxStmt)
a = walkexpr(a, init)
init.Append(a)
n = convnop(h, t)
else
// Call runtime.makehmap to allocate an
// hmap on the heap and initialize hmap's hash0 field.
fn := syslook("makemap_small")
fn = substArgTypes(fn, t.Key(), t.Elem())
n = mkcall1(fn, n.Type, init)
else
if n.Esc != EscNone
h = nodnil()
// Map initialization with a variable or large hint is
// more complicated. We therefore generate a call to
// runtime.makemap to initialize hmap and allocate the
// map buckets.
// When hint fits into int, use makemap instead of
// makemap64, which is faster and shorter on 32 bit platforms.
fnname := "makemap64"
argtype := types.Types[TINT64]
// Type checking guarantees that TIDEAL hint is positive and fits in an int.
// See checkmake call in TMAP case of OMAKE case in OpSwitch in typecheck1 function.
// The case of hint overflow when converting TUINT or TUINTPTR to TINT
// will be handled by the negative range checks in makemap during runtime.
if hint.Type.IsKind(TIDEAL) || maxintval[hint.Type.Etype].Cmp(maxintval[TUINT]) <= 0
fnname = "makemap"
argtype = types.Types[TINT]
fn := syslook(fnname)
fn = substArgTypes(fn, hmapType, t.Key(), t.Elem())
n = mkcall1(fn, n.Type, init, typename(n.Type), conv(hint, argtype), h)
访问map元素
go中访问map元素是通过map[key]的方式进行,真正的元素访问在go语言中有如下几个方法
- func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer …:mapaccess1返回指向h[key]的指针。从不返回nil,如果键不在映射中,它将返回对elem类型的零对象的引用。对应go写法:v := m[k]
- func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) …:方法同mapaccess1,仅多返回一个值用于表示是否找到对应元素。对应go写法:v, ok := m[k]
- func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer) …:返回key和elem。由map迭代器使用,与mapaccess1相类似,只多返回了一个key。。对应go写法:k,v := range m[k]。
- func mapaccess1_fat(t *maptype, h *hmap, key, zero unsafe.Pointer) unsafe.Pointer …:mapaccess1的包装方法,获取map中key对应的值,如果没有找到就返回zero。对应go写法:v := m[k]
- func mapaccess2_fat(t *maptype, h *hmap, key, zero unsafe.Pointer) (unsafe.Pointer, bool) …:mapaccess2的包装方法,获取map中key对应的值,如果没有找到就返回zero,并返回是否找到标记。。对应go写法:v, ok := m[k]
其中mapaccess1,mapaccess2,mapaccessK方法大同小异,我们选择mapaccesssK进行分析:
/**
* 返回key和elem。由map迭代器使用,与mapaccess1相类似,只多返回了一个key
* @param
* @return
**/
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)
if h == nil || h.count == 0 // map 为空,或者元素数为 0,直接返回未找到
return nil, nil
hash := t.hasher(key, uintptr(h.hash0)) // 计算hash值
// 计算掩码:(1<<h.B)- 1,B=3,m=111;B=4,m=1111
m := bucketMask(h.B)
// 计算桶数
// unsafe.Pointer(uintptr(h.buckets):基址
// (hash&m)*uintptr(t.bucketsize)):偏移量,(hash&m)就是桶数
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// h.oldbuckets不为空,说明正在扩容,新的 buckets 里可能还没有老的内容
// 所以一定要在老的桶里面找,否则有可能可能找不到
if c := h.oldbuckets; c != nil
if !h.sameSizeGrow()
// 如果不是同大小增长,那么现在的老桶,只有新桶的一半,对应的mask也林减少一位
m >>= 1
// 计算老桶的位置
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) // 如果没有迁移完,需要从老桶中找
b = oldb
// tophash 取其高 8bit 的值
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t)
// 一个 bucket 在存储满8个元素后,就再也放不下了
// 这时候会创建新的 bucket挂在原来的bucket的overflow指针成员上
for i := uintptr(0); i < bucketCnt; i++
// 循环对比 bucket 中的 tophash 数组,
// 如果找到了相等的 tophash,那说明就是这个 bucket 了
if b.tophash[i] != top
// 如果找到值为emptyRest,说明桶后面是空的,没有值了,
// 无法找到对应的元素,,跳出bucketloop
if b.tophash[i] == emptyRest
break bucketloop
continue
// 到这里说明找到对应的hash值,具体是否相等还要判断对应equal方法
// 取k元素
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey()
k = *((*unsafe.Pointer)(k))
if t.key.equal(key, k) // 如果为值,说明真正找到了对应的元素
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem()
e = *((*unsafe.Pointer)(e))
return k, e
return nil, nil
元素访问示意图

map元素赋值
map元素的赋值都通过方法mapassign进行
/**
* 与mapaccess类似,但是如果map中不存在key,则为该key分配一个位置。
* @param
* @return key对应elem的插入位置指针
**/
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
if h == nil // mil map不可以进行赋值
panic(plainError("assignment to entry in nil map"))
if raceenabled
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
if msanenabled
msanread(key, t.key.size)
if h.flags&hashWriting != 0 // 不能并发读写
throw("concurrent map writes")
hash := t.hasher(key, uintptr(h.hash0)) // 计算hash值
// 在调用t.hasher之后设置hashWriting,因为t.hasher可能会出现panic情况,在这种情况下,我们实际上并未执行写入操作。
h.flags ^= hashWriting
if h.buckets == nil // 如果桶为空,就创建大小为1的桶
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
again:
// 计算桶的位置,实际代表第几个桶,(1<<h.B)-1
bucket := hash & bucketMask(h.B)
if h.growing() // 是否在扩容
growWork(t, h, bucket) // 进行扩容处理
// 计算桶的位置,指针地址
b := (*bmap)(unsafe.Pointer(uint以上是关于Go源码阅读——map.go的主要内容,如果未能解决你的问题,请参考以下文章