AutoML之NAS
Posted luchi007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AutoML之NAS相关的知识,希望对你有一定的参考价值。
前言
autoML最近非常火热,在调参、特征选择等方面都有了不少的进展,与其同时,在深度网络日益复杂化的今天,如何为任务设计合适的网络结构成了每位炼丹工程师的日常,而在缺乏先验知识的情况下,调整网络结构往往需要较长的时间和精力,如何自适应的调整网络结构就成了一个值得研究的问题。今天主要介绍的是autoML下面的一种自适应调整网络结构的方法: NEURAL ARCHITECTURE SEARCH (下面简称NAS),NAS主要作用是自适应构建网络结构,减轻人为调整的繁复劳动,还是值得一看的。
NAS 开篇
【论文地址:NEURAL ARCHITECTURE SEARCH WITH
REINFORCEMENT LEARNING】
基本思路是通过构建一个controller来搜索行为空间,根据行为空间构建网络图,并根据网络图的rewards(一般是在验证集上的指标收益等)调整控制器的参数,主要结构见下图:
上图看上去很熟,其实就是强化学习的框架,可以把controller看做是RL里的agent,搜索空间看做是action,子网络看做是environment,在验证集上的指标看作是reward,如此一比,其实就很清楚了,本质上是个RL的问题。
网络结构
以一个卷积网络为例,日常我们在设计CNN的时候,一般考虑到的参数有卷积核个数、卷积核的height和width、 stride-height、stride-width,在使用NAS搜索的时候,使用RNN作为controller,结构见下图:
每一个卷积层设计为如下步骤:
- RNN接收前一层的输出作为当前的input,同时根据前一层的hidden_vec,生成当前cell的hidden_vec以及output
- output接一个softmax层,softmax类别个数为搜索空间的个数,选择概率最高的为当前的action
- 当前cell的输出会作为下一个cell的输入,不断循环,就能依次拿到卷积核个数、卷积核的height和width、 stride-height、stride-width等参数
- 拿到参数后就可以构建当前的卷积layer
- 依次循环就可以构建一个卷积网络
- 根据卷积网络训练,并在验证集上拿到一个指标,也就是reward
param learning
controller的参数学习是RL里面的policy-gradient方法,其loss是:
其中
m
m
m表示探索的次数,
T
T
T表示的是一次探索设计的超参数(可以理解为RNN的output个数),
P
P
P函数表示的是action的预估概率,
R
k
R_k
Rk是设计的网络在验证集上的准确率指标。
为了减少模型方差,后面作者改了一个新的loss:
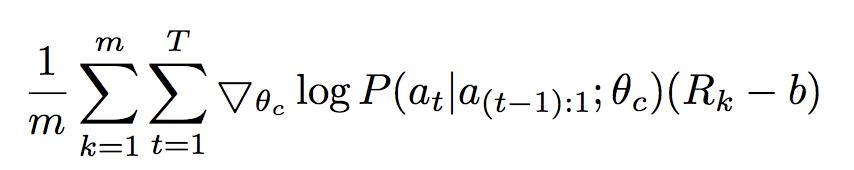 其中
b
b
b表示的是baseline的准确率
其中
b
b
b表示的是baseline的准确率
NAS 进化:ENAS
【论文地址 Efficient Neural Architecture Search via Parameter Sharing 】
ENAS相比NAS的主要改动在于shareing subgraph weight,比如设计一个rnn网络,对于RNN的每一个cell单元,由N个block组成,下面以N=4举例,其block的构建过程如下:
- 初始化输入 x t x_t xt和前一时刻隐向量 h t − 1 h_t-1 ht−1,controller的action空间为 选择前一个输入以及选择激活函数
- controller接收输入,输出「激活函数」 action概率并选一个激活函数,假设是tanh,那么node1的输出为 h 1 = t a n h ( x t W x + h t − 1 ∗ W 1 h ) h_1 = tanh(x_tW_x + h_t-1*W_1^h) h1=tanh(xtWx+ht−1∗W1h)
- controller继续run rnn并输出「前一个输入」action概率并选择一个输入,假设是 h 1 h_1 h1,继续输出「激活函数」action概率并选择一个激活函数,假设是Relu,那么node2的输出为 h 2 = R e L U ( h 2 W 2 , 1 h ) h_2 = ReLU(h_2W_2,1^h) h2=ReLU(h2W2,1h)
- controller继续run rnn并输出「前一个输入」action概率并选择一个输入,假设是 h 2 h_2 h2,继续输入「激活函数」action概率并选择一个激活函数,假设是tanh,那么node2的输出为 h 2 = t a n h ( h 2 W 3 , 2 h ) h_2 = tanh(h_2W_3,2^h) h2=tanh(h2W3,2h)
- controller继续run rnn并输出「前一个输入」action概率并选择一个输入,假设是 h 1 h_1 h1,继续输入「激活函数」action概率并选择一个激活函数,假设是tanh,那么node2的输出为 h 2 = t a n h ( h 1 W 4 , 1 h ) h_2 = tanh(h_1W_4,1^h) h2=tanh(h1W4,1h)
- 由于 h 3 h_3 h3和 h 4 h_4 h4没有后向依赖,最终该RNN的cell隐向量输出为 h t = ( h 3 + h 4 ) / 2 h_t = (h_3+h_4)/2 ht=(h3+h4)/2
上图的controller可用下图表示: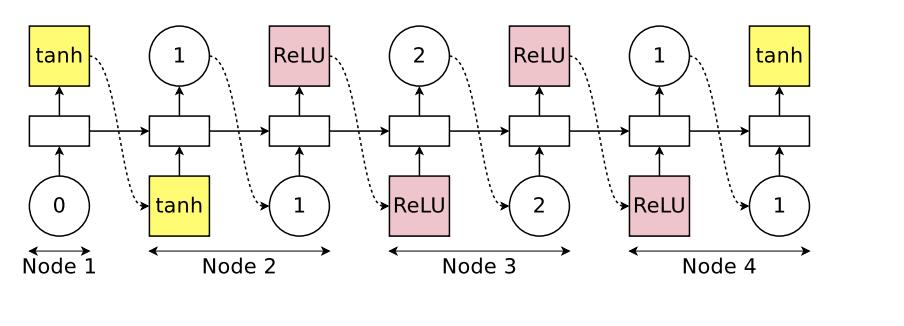
而RNN cell的构建过程可用下图表示:
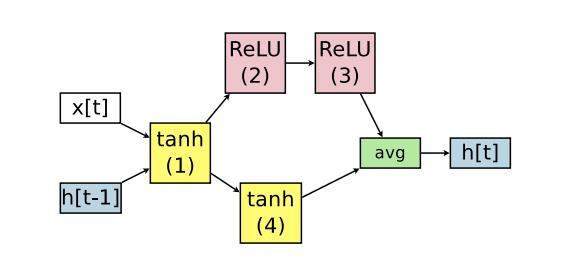
该RNN cell的构建有向图可以表示为:

注意到在构建RNN cell步骤中,
W
i
,
j
h
W_i,j^h
Wi,jh在不同的cell中间是共享的,这也是本paper提出的idea的核心,也就是share子图的weight
参数学习和NAS一样,也是基于policy gradient更新controller参数
DARTS: one-shot learning
【论文地址DARTS: DIFFERENTIABLE ARCHITECTURE SEARCH 】
DARTS的思路比较简单,是将所有的子图全部汇集在一个超图里一起训练,在最后通过选择子图的weight来决定用哪个子图。
- 假设有个图网络结构是这样的:

问号的部分指的是不通的node直接可以有不同的operation,比如max-pooling之类的 - 假设operation有N的action空间,首先就是构建一个包含所有空间的超图,如下:
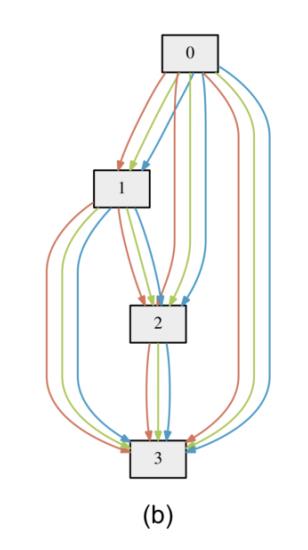
3. 将每个node直接构建所有的action,使用参数对action加权: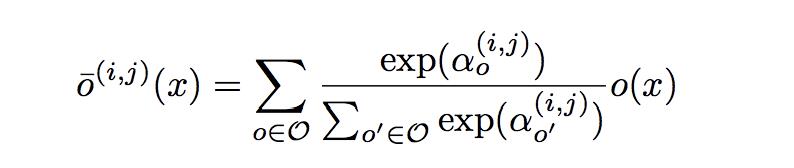
4. 然后通过梯度下降直接训练
α
\\alpha
α参数得到不同action的weight, 训练loss如下: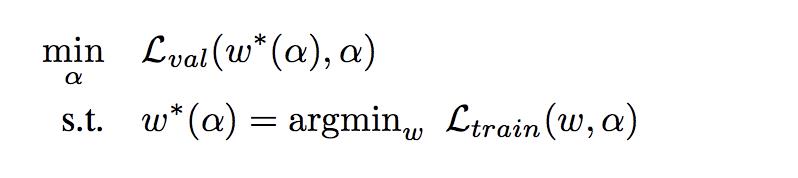
loss先约束求解使得loss最小的图网络参数
w
w
w,然后再求解在此图参数下的
α
\\alpha
α最优值,因为上式直接求解比较麻烦,实际的训练过程如下:
主要改动是在第一步中,把先优化
w
w
w约束条件变成了先对
w
w
w根据梯度下降求一个更新值,然后利用此更新值去优化
α
\\alpha
α
5. 最终训练得到
α
\\alpha
α之后,根据最大值取action,得到最终的subgraph: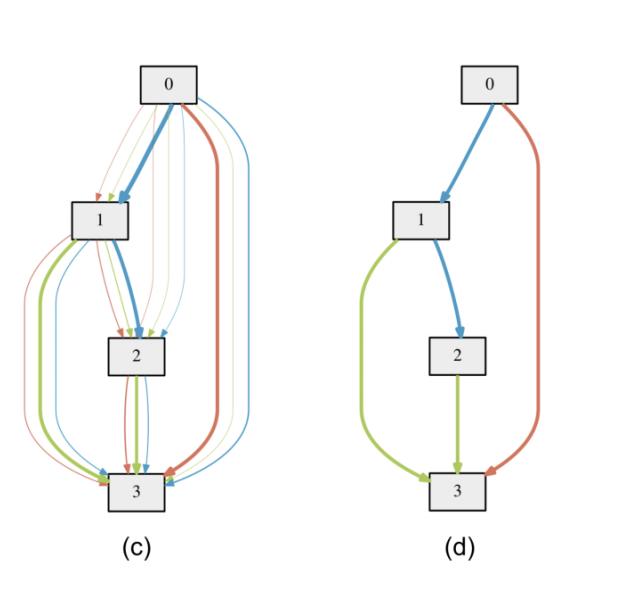
上图左边边表示各个连接的
α
\\alpha
α权重,颜色越深表示权重越大,挑出最大的权重,就得到右边的最终子图。
以上是关于AutoML之NAS的主要内容,如果未能解决你的问题,请参考以下文章