cdh6.x 集成spark-sql
Posted 涤生大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cdh6.x 集成spark-sql相关的知识,希望对你有一定的参考价值。
写在前面
CDH系列默认阉割掉了Spark的spark-sql工具,但是很多公司还是有这个使用的需要,因为线上就有这块的需求,所以结合cdh6.x版本,做了具体的对spark-sql工具支持的集成。
版本说明
| 组件名称 | 组件版本 |
| CDH | CDH 6.2.1 |
| spark | spark-2.4.8 |
第一步:下载原生apache spark
# cd /opt/cloudera/parcels/CDH/lib
# wget http://archive.apache.org/dist/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
# tar zxvf spark-2.4.8-bin-hadoop2.7.tgz
# ln -s spark2 spark-2.4.8-bin-hadoop2.7
第二步:修改spark配置文件
2.1 配置spark-env.sh
|
2.2 配置spark-defaults.conf
小提示:建议直接cp 现有spark的配置文件,在此基础上修改。
|
Vim /opt/cloudera/parcels/CDH/lib/spark2/conf/spark-defaults.conf
小提示:修改配置文件时,只需要修改文件中标红部分即可,其他可以保持默认。
|
2.3 配置日志级别
# vim /opt/cloudera/parcels/CDH/lib/spark2/conf/log4j.properties
在配置文件中追加以下配置项,其他保持默认
|
第三步:配置依赖包
3.1 上传spark 依赖jar包
|
3.2 配置lzo jar包
|
第四步:配置spark-sql 的全局变量
vim /etc/profile.d/spark.sh
|
#生效
|
第五步:测试使用
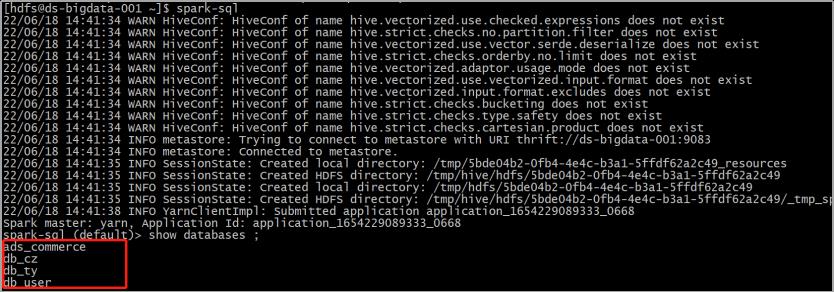
全局的任意位置执行 spark-sql指令(注意:执行的linux用户需要有提交任务到yarn的权限)
如果都没有问题,执行show databases ;会看到集群中的所有库。
补充说明:其他客户端如果需要此环境,将上述配置全部scp过去即可。
以上是关于cdh6.x 集成spark-sql的主要内容,如果未能解决你的问题,请参考以下文章