[Linux 006]——grep和正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Linux 006]——grep和正则表达式相关的知识,希望对你有一定的参考价值。
在使用系统时,我们或多或少的有一些搜索、查找的需求,必须要在文本中搜索某个关键字,或者过滤出文本中某些特定的行。grep 命令就为我们提供了这样一个功能,同时,grep 还可以使用正则表达式进行匹配,这是一个强大的功能,有必要好好掌握。
1.grep 初体验
grep PATTERN [OPTIONS] FILE:在文件中按照模式进行查找。FILE 是我们要查找的目标文件,如果不指定目标文件,grep 将会从标准输入中读取输入的内容,然后进行匹配。为了方便起见,本文的所有演示都在命令行中通过标准输入进行。
- grep PATTERN:最基本的用法,根据 PATTERN 进行查找

如果没有高亮显示匹配到的内容,可以手动指定:grep --color PATTER 进行匹配,更可以使用命令别名,减少我们的输入时间:alias grep="grep --color"。
- grep PATTERN -i:忽略大小写匹配
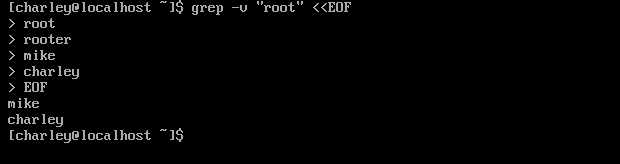
- grep PATTERN -v:反转输出。匹配到的内容不输出,只输出没被匹配到的内容。
- grep PATTERN -o:只显示匹配到的字串(PATTERN)。默认显示匹配到的字串所在的整行文本。
2.grep 和正则表达式
正则表达式(Regular Expression 或 REGEXP)分为基础正则表达式(Basic REGEXP)和扩展正则表达式(Extended REGEXP)。grep 默认采用基础正则表达式,如需使用扩展正则表达式需要附加选项。
由于介绍正则表达式实在太过复杂,我想了很久也无法很好的组织语言,因此这里就不再对正则中的元字符进行一一的介绍了。需要了解这方面的同学,可以去看一下三十分钟入门正则表达式系列的教程,应该很快就能学会。
- 使用 grep 进行简单的正则匹配
"[]" 表示匹配 [] 中出现的任意一个字符,[a-zA-Z] 表示匹配所有的英文字母。

"[^]" 表示匹配出去 [] 中出现的字符之外的任意字符。

在正则表达式中,‘*‘ 号不再表示任意字符,而表示其前的字符可以出现任意次。有时候我们在命令中使用 ‘*‘ 进行通配符匹配文件,要注意它在正则表达式中的不同用法。在正则表示中使用 ‘.‘ 点号来匹配任意字符。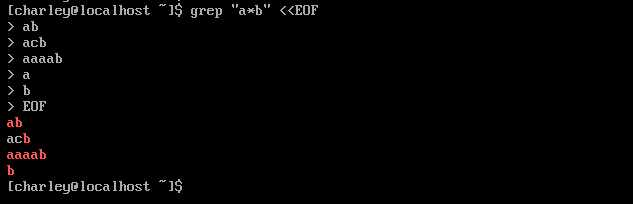
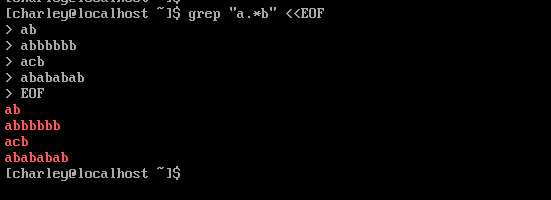
在正则中,‘.‘ 点号表示不为空的任意字符。

".*" 表示匹配出现任意次数的任意字符。正则表达式默认处于贪婪模式,因此在第一次匹配到结果后,还会进行多次匹配,知道没有匹配为止。
"\\?" 表示匹配前面的字符出现 0 次 或者 1 次,注意这个问号需要被转义。

"\\{m,n\\}" 表示前面的字符出现最少 m 次,最大 n 次。"\\{m,\\}" 表示前面的字符至少出现 m 次,"\\{,n\\}" 表示前面的字符至多出现 n 次。

‘^‘ 和 ‘$‘ 是正则表达式中的两个位置锚定。‘^‘ 表示其后的字符必须出现在行首,而 ‘$‘ 表示其前的字符必须出现在行尾,"^$" 表示匹配空白字符。

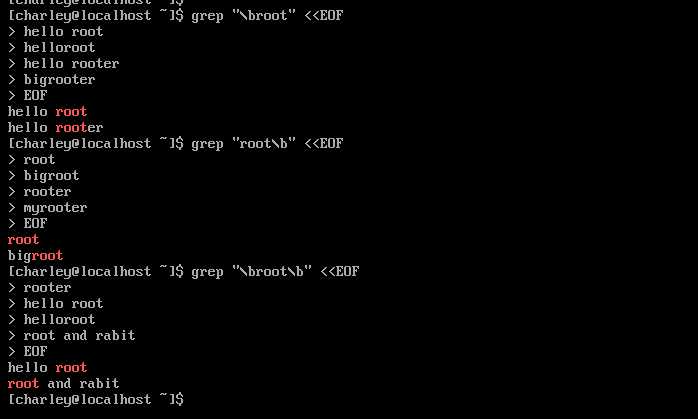
"\\<" 和 "\\>" 用来锚定单词,二者不一定要成对出现,也可以使用 "\\b" 进行锚定。"\\bWORD" (或者 "\\<WORD\\>") 表示匹配以 WORD 开头的单词,"WORD\\b" 表示匹配以 WORD 结尾的单词,"\\bWORD\\b" 表示完完全全匹配 WORD 单词。
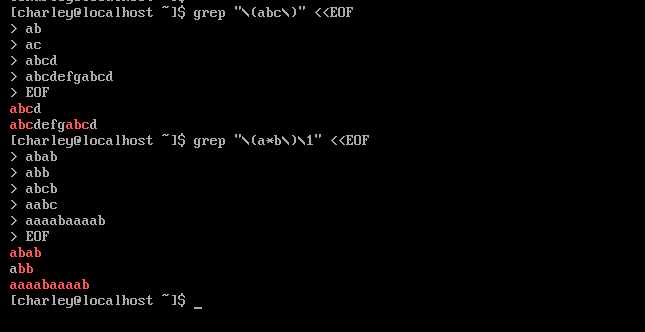
"\\(\\)" 表示对 PATTERN 进行分组,分组还支持后向引用,使用 "\\1","\\2" 等引用前面的分组。后向引用只匹配和前面相同的内容。
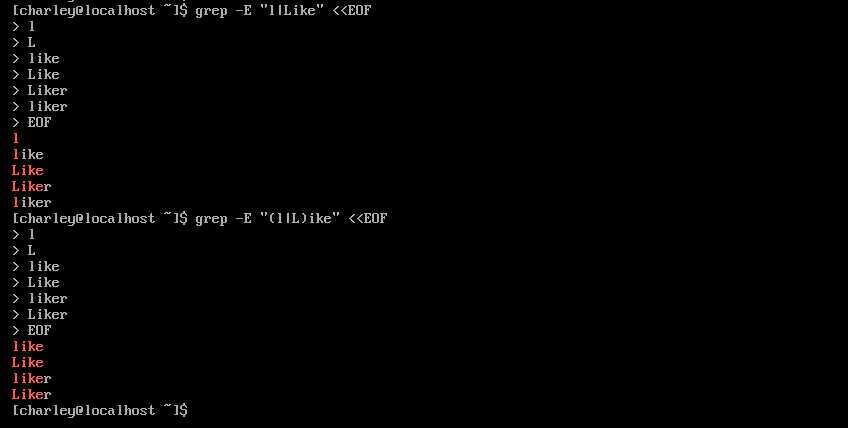
‘|‘ 表示或,匹配其前或者其后的单词,注意并不是匹配字符,如需匹配字符,需要使用分组进行限定。我这里使用的是扩展正则,如需使用基本正则,需要将 ‘|‘ 换为 "\\|"。
3.扩展正则表达式
grep 同时还支持扩展正则表达式,在使用扩展正则表达式是,需要使用 -E 选项。基础正则表达式和扩展正则表达式中的一些区别:
- 基础正则中使用 \\?,扩展正则中使用 ?
- 基础正则中使用 \\(\\),扩展正则中使用 ()
- 基础正则中使用 \\{\\},扩展正则中使用 {}
在基础正则表达式中匹配 ?,(),{} ,不需要进行转移,而在扩展正则表达式中则需要加上转义符号 \\。
扩展正则表达式中的其他选项:
- \\s:匹配空白字符
- \\S:匹配非空白字符
- \\w:匹配字母,数字,相当于 [0-9a-zA-Z]
- \\W:不匹配字母和数字,相当于 [^0-9a-zA-Z]
4.grep 的其他选项
- grep PATTERN FILE -A NUM:使用 grep 进行匹配之后,显示匹配的行,同时向后显示指定的行
- grep PATTERN FILE -B NUM:和上面相反,向后显示指定行
- grep PATTERN FILE -C NUM:进行匹配之后,分别向前和向后显示指定的行,相当于 -AB NUM
- grep PATTERN FILE -c:显示被匹配到的行数
- grep PATTERN FILE -F:相当于 fgrep
- grep PATTERN FILE -P:使用 Perl 风格的正则表达式
- \\d:匹配任意十进制数字,相当于 [0-9]
- \\D:匹配任意非数字字符,相当于 [^0-9]
5.egrep 和 fgrep
在使用 grep 时,如果想要开启扩展正则表达式,需要指定 -E 选项,而 egrep 命令则是默认支持扩展正则表达式。因此在需要使用扩展正则表达式时推荐使用 egrep 代替 grep -E。
fgrep 表示快速匹配,不支持正则表达式,没有转义的概念,会对 PATTERN 中的所有字符进行匹配。
6.总结
本篇我们介绍了 grep 命令和正则表达式的基本使用,grep 是 Linux 下的一个文本处理命令,配合正则表达式使用,其功能非常强大。grep 主要用来查找操作,如果想使用替换等更加强大的功能,就需要使用 sed 或者 awk 命令。grep,sed,awk 被称为 Linux 下的三个文本处理杀器,等学到相应的章节再继续介绍 :)
作者:Charleylla 转载请注明出处:http://www.cnblogs.com/charleylla/p/5988885.html
以上是关于[Linux 006]——grep和正则表达式的主要内容,如果未能解决你的问题,请参考以下文章