联邦学习系列---读书个人总结
Posted 35岁北京一套房
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习系列---读书个人总结相关的知识,希望对你有一定的参考价值。
联邦学习系列----1
引言
最近刚开源了FedML, 对于这个领域挺好奇,觉得好好读一读。
文章: https://arxiv.org/pdf/2007.13518.pdf
库的代码:https://github.com/FedML-AI/FedML-docs
对于《联邦学习》一书,进行一章一章的总结,也就是重新的排列,无新知识的补充。
引言介绍人工智能面临的挑战和联邦学习可作为一个幼小的方案去解决,最后介绍分类和发展。
1 人工智能面临的挑战
人工智能的快速发展,带动了多领域的发展,但也存在很多挑战
- 大数据时代,很难获得统一格式的数据,而且很多数据都是小规模和碎片化的,比较难处理和分享使用。
- 法律层面,欧盟的《通用数据保护条例》、美国的《加利福尼亚消费者隐私法》、中国的《中国人民共和国网络安全法》都对新数据的收集和处理提出严格的约束和控制;
- 共享数据后的模型益处分配效果不明显,可能失去数据的掌握权,阻碍了人工智能的前进。
2 联邦学习的来源和挑战
2.1 联邦学习的由来
在大数据背景下,数据往往是小规模、碎片化存在的,数据之间彼此独立,在掌握权不丢失的情况下,多方参与共同搭建高性能模型,保护数据的隐私,同时最大化云系统下终端设备的计算能力。
2.2 联邦学习的挑战
- 参与方与聚合器之间通信,可能存在参与方过多,或者速度很慢,不稳定、数据非独立同分布等。
- 样本数量、特征数量不同,参与方的计算能力和产生的模型误差, 导致聚合的结果不理想。
- 容易受到攻击,导致模型可用性降低(如投毒攻击等)。
3 联邦学习的定义
联邦学习基于分布式数据集建立模型,包括训练和推理,训练可以交换相关信息或者加密形式交换,但是不包括数据。
Note
- 有两个或以上的参与方协作构成建一个共享的机器学习模型
- 训练过程中,数据不离开参与方
- 相关信息可以以加密的方式传输或传换,并且不能通过这些信息推测出其他方的原始数据
- 性能充分逼近理想模型
例:有N个参与方Fi和N个数据集Di,分为传统训练和联邦训练:
传统:将所有的数据集传送到云服务器,进行训练,得到模型Msum
联邦:各个参与方Fi 在本地训练数据集,形成模型,与聚合器多次交互,得到模型MFED
设非负实数a, 当Msum-MFED<a , 我们认为就可以采用联邦学习,适当地下降性能,而起到保护数据的作用,我们是可以接受的。
联邦学习的分类
| 种类 | 划分标准 |
|---|---|
| 横向联邦 | 当特征重叠较多时 |
| 纵向联邦 | 当样本重叠较多时 |
| 迁移联邦 | 重叠都比较少时 |
如图

这是联邦学习的简易图:
原书是这样子的:
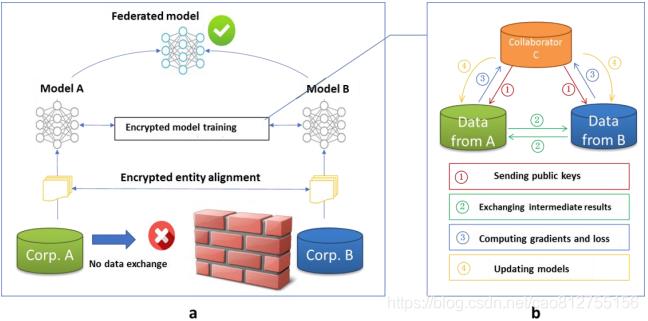
自己练手。勿喷。
以上是关于联邦学习系列---读书个人总结的主要内容,如果未能解决你的问题,请参考以下文章