libco简介
Posted E-HERO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了libco简介相关的知识,希望对你有一定的参考价值。
好久都没在CSDN上发博客了,大概两年了吧,看着以前写的博客,感觉自己更像是个前端工程师了,其实工作上我应该算是后端的吧。最近换了一份工作,新公司用到一个叫Colib的库,也在GitHub上开源了,虽然开源之后并没有人怎么维护,但这里面的代码的确也在线上用,这里面的思想也是挺有趣儿的,就研究了一下,也算是和后端相关了
https://github.com/Tencent/libco
1. 协程
1. 1 概念
协程这个概念其实在《操作系统》系统里面应该有了解过,进程(process),线程(thread),协程(routinue),其中大部分博客,论文对进程和线程都有介绍,协程的介绍却比较少。协程其实是在线程里面跑的,比线程更细粒度。线程里面其实是有当前执行的上下文信息,里面装了当前执行的位置,将要执行什么代码。如果我们有多个这样的上下文,并且可以在里面各种跳转,就类似于我们在线程里面实现了一种更细粒度的“线程”。你可以把这种上下文理解成一个函数,相当于有A,B两个函数,我在执行A的时候,还没执行完,然后暂停了一下,去执行B,然后还没等B执行完,又暂停一下,去继续执行A,就像线程调度一样,但这个不是线程,因为A和B不能并发(有些框架其实是可以的,例如,在上一家公司用的一个叫BRPC的框架,后面我会写博客介绍这个框架,这里的协程就是指在一个线程里面的那种协程),也就是A执行的时候,B不能执行,B执行的时候,A不能执行,所以这种协程不用考虑锁的问题,因为不会发生竞争。另外和线程不同的是,这种协程调度不是由操作系统来调度的,是由开发者,也就是人通过代码来调度的。线程是操作系统执行的最小单位,对于操作系统来说,他只能看到线程,不知道这个线程里面是怎么调度的。这是这种“子程序”或者“运行模式”(我也不知道用什么名词比较合适)就是协程。下面附一个博客,这里面用一个例子解释了什么是协程,更加简单易懂
1.2 优势
那么协程的优势在哪儿呢,看起来协程并不能并发,似乎用处不大。但回想一下我们在一些耗时操作的时候,例如网络请求,有段时间我们会等待请求回来,这种等待其实就是一种CPU资源的浪费。这时候如果有协程,我们在知道要等待的时候,在代码里面切换一下,去执行其他操作,等那个请求回来了,我们再切回去执行那个返回的结果,这样不就把等待那部分时间给利用起来了么。如果是在多线程里面,一个线程的请求没回来,我们可能用一个thread_yield,或者wait的方法,让这个线程休眠,但这样中间就会有一次线程切换,会浪费一些消耗,而协程切换就不会有这个影响,因为在操作系统看来,这全部都是在一个线程里面去完成的。所以这也是协程的最大的优势:协程切换开销远小于线程,进程切换。
2. libco
2. 1 协程调度
libco是我们部门底层大量使用的一个基础库,这个并发度传言很高,具体多高我也不太清楚,但经受住业务的考验这倒是真的。这个库就是一个C++的协程库,代码不多,主要有几个常用的方法:

这里主要介绍一下这三个,create,resume,yield
co_create: 参数里面有一个函数指针,用于创建一个新协程,可以理解为创建了一个上下文,但只是创建,啥都没干,就像pthread_create。
co_resume:执行某一个协程,可以看里面的实现,里面有一个pCallStack,这里面装的其实就是协程栈,要执行的时候,就取出当前执行的协程,也就是栈里面最后一个协程,然后对传进来的协程判断一下,做一个初始化,压入栈,然后和当前的协程swap一下。这个swap其实就是在把当前这个线程要执行的下一条指令,指向这个新的协程(图中那个co)。
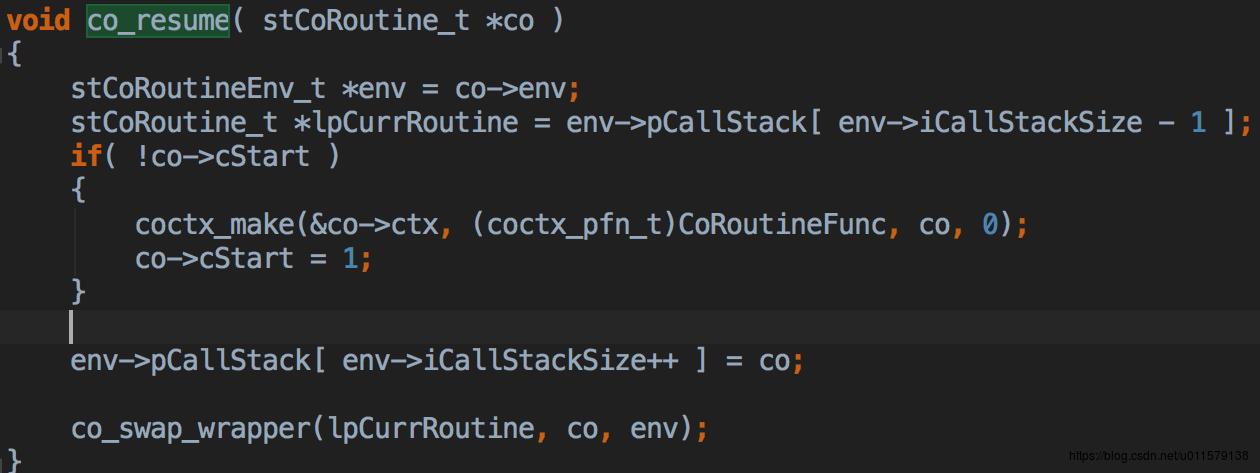
这里的swap是怎么实现的呢,其实就是用汇编,复制,保存寄存器中的值,改变CPU寄存器里面跳转下一个指令的地址,实现上下文切换,也就是改CPU下一行要执行的代码。这里的汇编是针对不同的CPU架构,写不同的汇编,所以汇编还是很强大的。虽然协程的切换基本都是通过汇编来实现的,但是还是有很多种方法。已经有一些库,例如boost中已经提供了上下文切换,所以如果业务需要这方面的功能,不用自己去写汇编,这里附一篇博客,里面有提及一些库可以实现协程切换。
https://blog.csdn.net/waruqi/article/details/53201416
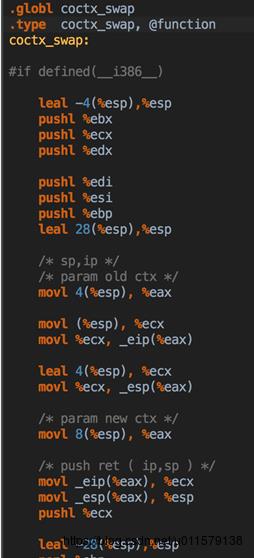
co_yield:让某个线程(可以认为一个线程,关联一个stCoRotinueEnv_t)当前正在执行的协程,yield让出时间片(在操作系统里面,yield一般是指主动把CPU时间片让出来,也就是暂停运行,直到被唤醒)。这里可以看到里面的实现其实就是找到当前执行的协程(iCallStackSize - 1,我们称作A)和上一个协程(iCallStackSize - 2,我们称作B),然后swap一下这两个协程,并且注意,这里iCallStackSize -- 了,也就是把这个yield的协程A从协程栈里面去掉了,但是由于这个A协程已经执行了一些代码了,所以在这个A协程的上下文中也保存了执行的进度,如果下次这个A被co_resume,会从A停止的地方开始执行,而不是重新开始,所以co_resume的名字叫作resume(resume:继续的意思)。
2.2 Echo Server
介绍完简单的协程切换,这里用给一个具体的例子,来看看这个libco的具体用法(PS:这里不得不批斗一下,这群开源的人真的仅仅只是开源,社区没人维护就算了,但这个例子本身也是有bug,server demo好歹还有一个help解释,client demo就完全没有,并且随便传点参数就core了,真的不够用心,不过对于整体代码理解影响不大,所以这个demo也真的只是个demo)
先大概介绍一下在这个echo server里面的三种协程,因为后面介绍的时候会涉及到这三种协程相互切换,比较蛋疼,可以先了解这三种协程,方便理解
1. readwrite协程
2.accept协程
3.eventloop协程(或者是说主协程,但主协程前面是在创建readwrite协程和accept协程,创建完之后才执行的eventloop)
一开始就是惯用的套路,先创建server socket fd,然后起进程,起的进程里面执行那个readwrite_routinue,co_create只是创建这个协程,但是并没有真正的去实行,co_resume才是真正去执行这个协程,这里创建的就是readwrite协程
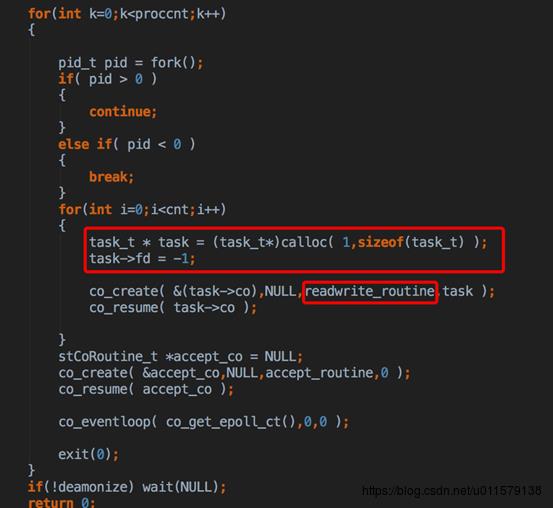
然后进入那个协程执行的函数,因为初始化的fd是-1,所以会执行co_yield_env,这个函数和pthread_yield很像,让出时间片,也就是把这个协程挂起了,然后继续回到之前那个地方执行,也就是切回主协程了(这就是协程,跳来跳去,很烦)
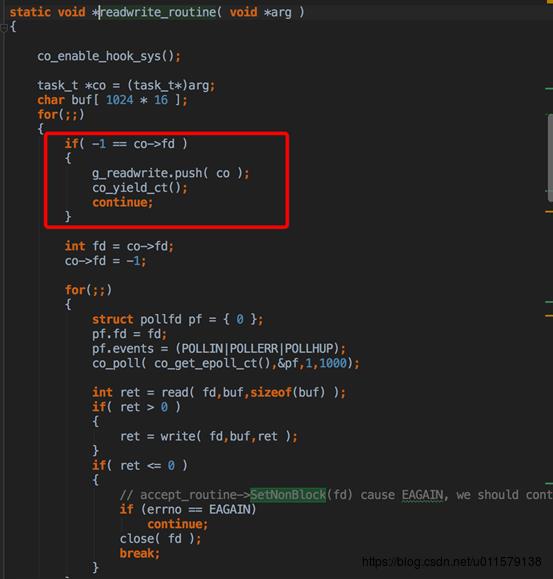
然后又是重复上图后面那个流程,执行那个accept_routinue,这里就创建了accept协程
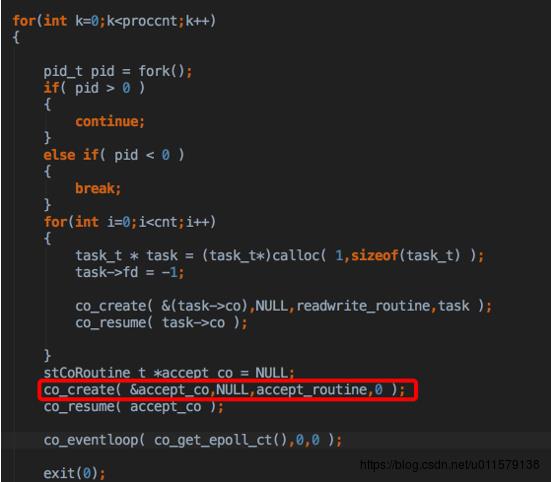
然后看这个accept_routinue,作为一个开源的代码,居然把一行不要的代码用注释放在代码中,也是不走心啊,然后用一个poll,猜猜是干啥,居然是sleep,关键这个poll,还不是Linux库里面的,是自己封装的,看了好久,后来才发现,这里只是为了做一个sleep,为啥用epoll,不是sleep呢,我猜他应该是要做毫秒级的:
- 这里调用也没有用到这么精准,居然这么麻关系都好几层何必呢
- 就算要这么精准,居然用自己封装的poll,只是sleep毫秒也有很多简单的用法,最简单的一个epoll_wait也行啊,或者futex,还可以到微秒,这是公司级开源代码 = =
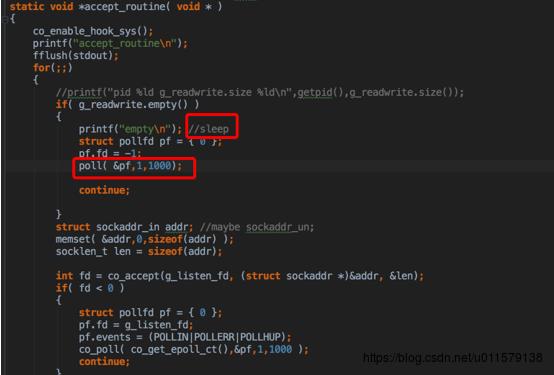
然后到下面就是co_accept,就是监听accept,这里多做的一步就是alloc_by_fd,另外这里在顺道说一下,这里的socket fd是非阻塞的,在main函数里面有一个SetNonBlock,所以这里是不会阻塞的,没有连接接入会马上返回
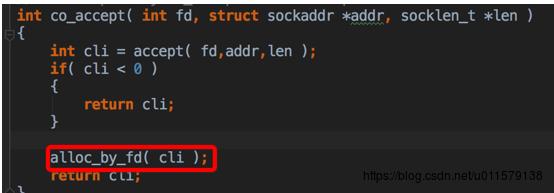
这里其实就是在全局把一个rpchook和一个fd给绑定了,这里的fd数组也是有范围的,如果超过这个范围……那就GG了,虽然一般情况下生产环境应该不至于会超……但这个貌似也算是一个小缺陷吧
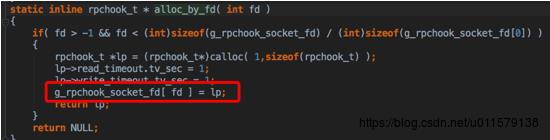

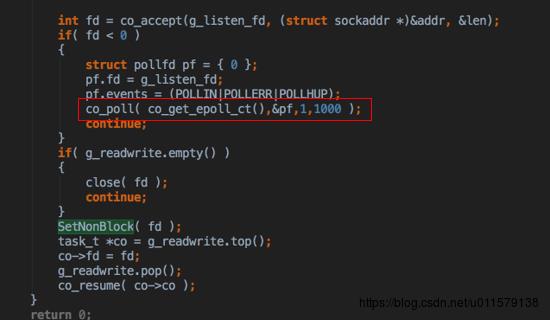
由于是非阻塞,这里的co_accept刚开始会马上返回(假设刚开始没有连接接入,所以fd < 0 ),下面就是co_poll,这个算是比较重要的一个函数了
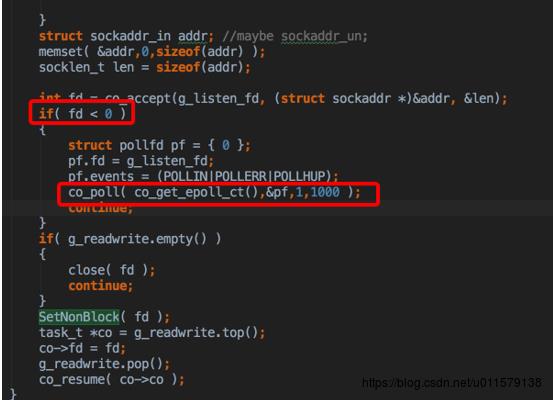

Co_poll_inner也是做一些注册初始化的工作,然后用epoll注册时间和回调,如果注册失败了,就用原来的poll
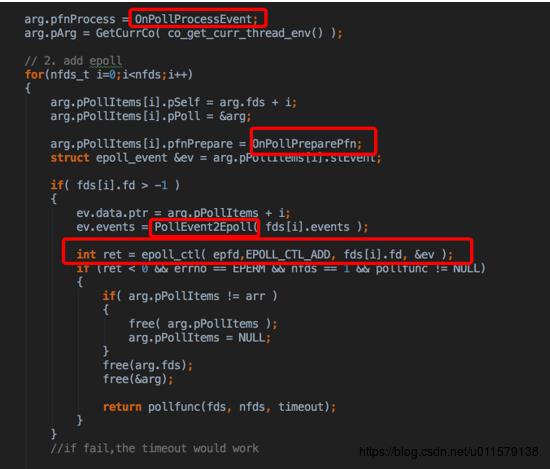
然后后面又yield了一下,让出了时间片
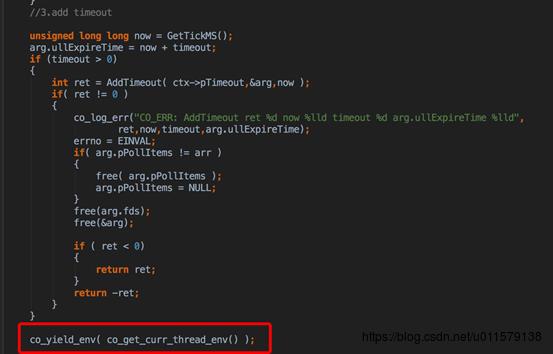
让出时间片后,也就是从accept协程,切回到主协程去了,终于又到了main里面(所以说跳来跳去比较烦),然后就是co_loopevent(听着这名字是不是很像js里面的eventloop)
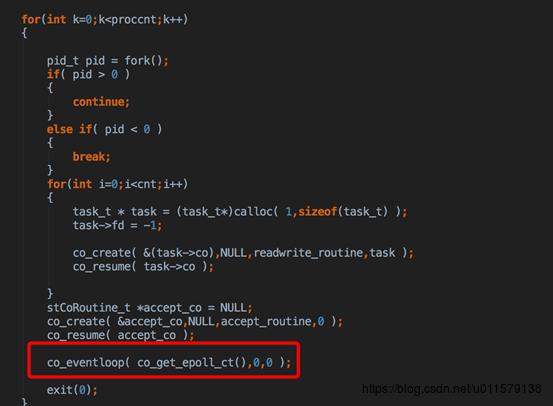
在eventloop里面,这里用了epoll_wailt,这里为啥用1ms,貌似是因为这里面有一个时间轮盘的概念,刚好一格就是1ms,具体这个时间轮盘我也不太清楚,大体是用来算超时时间的,也是看一篇文章提到了一下,这里拿出的item就是在co_poll_inner里面看到的那个pPolltems,所以这点pfnPrepare其实也就是上面有幅图标出来的OnPollPreparePfn。这个函数(本图第二个红框那个)看着不起眼,但是很重要,开始看了半天都没看到怎么收到epoll事件后回调对应的函数的,就是通过这个,注意这里传进去的第一个参数是他自己,也就是item,
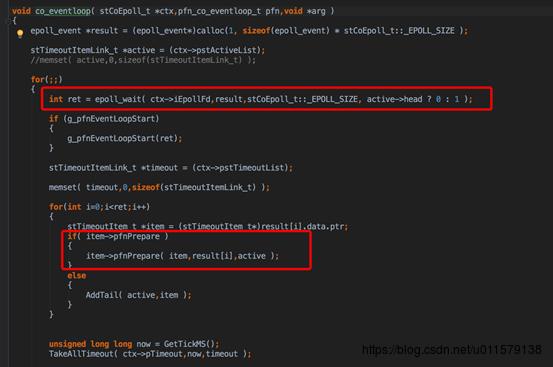
这里的item就是pPolItems ,回过去看一眼(在co_poll_inner里面),发现item里面的pPoll是arg,arg的pfnProcess被注册了一个processEvent,所以这个时候其实大概猜到了OnPollPreparePfn和pfnProcess这个是干啥的了,这两个函数肯定和切换协程有关,按照这个框架的剧情,收到epoll事件之后,应该要交给业务逻辑协程去处理业务,所以中间肯定存在一次协程切换,那怎么切换协程,肯定和这两个函数相关
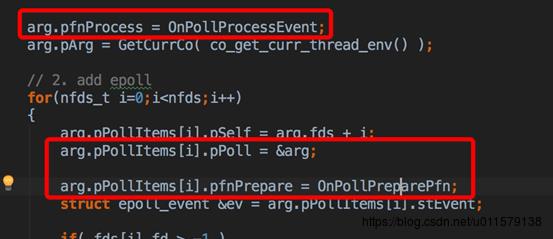
所以再看看那个pfnPrepare(也就是前面说的OnPollPreparePfn)这个函数拿到了之前arg(下图中的pPoll),然后这个加到尾部
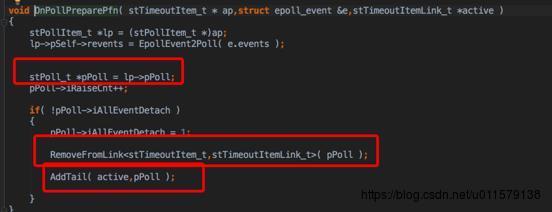
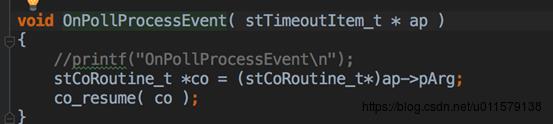
再回到co_eventloop里面,发现后面在遍历这个active(这个是个list),然后在执行pfnProcess,也就是执行了arg里面注册的那个OnPollProcessEvent,
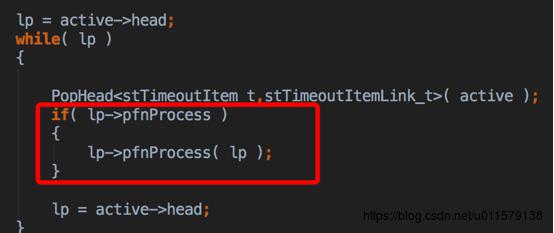
再看看process里面做了啥,找到注册的那个协程,也就是调用epoll_add的那个协程,也就是调用co_epoll_inner这个函数的协程,在libco里面,由于hook了read,write,这些比较基础的函数,这些函数里面其实也会调用co_epoll_inner,所以等epoll事件触发之后,就在这儿把eventloop那个协程切换成原来注册epoll的那个协程,所以看到这里,是不是找到了一点眉目,所以这里又从主协程,或者说是从eventloop协程切换回了注册的协程(这个例子中就是accept协程)

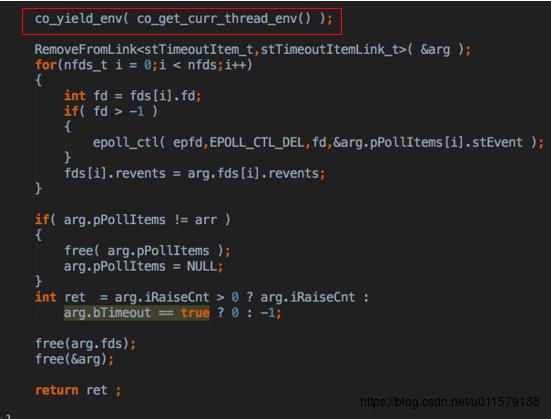
接到刚才那个accept那里注册了一个监听事件,也就是在accept那里 co_poll_inner,又回到yield那儿(因为accept是由那个协程注册的,所以自然就找到了那个accpet的协程),接着刚刚yield那个地方,然后这里把epoll删了然后处理一会儿,又回到accept那儿了(这里的图是接着上面yield那个地方,之前就是在红框那个地方accept协程让出时间片的,在co_poll_inner里面,所以这里切换回来又接着这里执行,这里有点跳,这就是协程,所以可以自己用笔画画栈调用关系)
然后就回到刚刚说的accept里面去了,从红框里面跳出来的,Demo的实现就是从readwrite协程池里面找一个空闲的协程出来,然后切换成它,这里就是从accept协程,切换成readwrite协程
回到readwrite协程,由于开始readwrite协程刚开始yield了一下,现在到continue那里,又再次循环,由于在accept后fd已经改成了那个accpet后的读写fd(就是已经建立好连接的那个fd,不是监听的fd),所以这里就到下面那个for,这里还是老样子注册一个poll,监听读事件(这里就还是老套路了,走了co_poll_innner,也是涉及到协程切换,由于上面已经介绍了,参考上面说的co_poll_innner那段逻辑就行了),这里省略内部那些协程切换了,假设监听之后很快又触发了读事件,协程又回切换到这里,然后进行读,也就是执行read
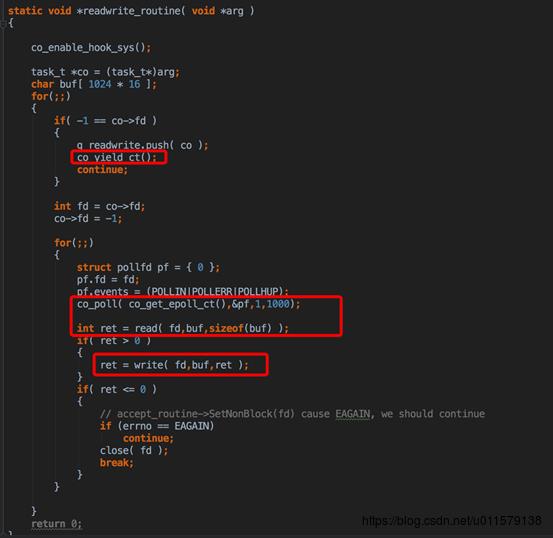
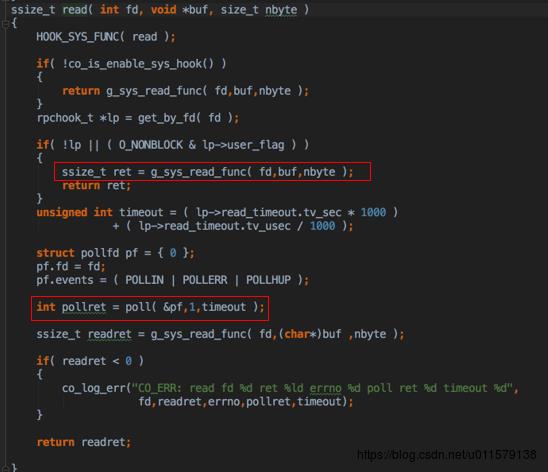
这里的read其实不是Linux那个read,是hook了的(也就是用自己的函数复写了,类似于类的多态,类似啊,可以这样理解)也是先判断一堆,然后这里又执行了poll,刚看到这里的时候在想这里是不是有点问题,明明在外面已经poll了一下,这里又poll一下,这里可能也是为了一种异常情况,上面介绍过,alloc_by_fd这个其实是有个范围,如果超了那个范围,返回的rpchook其实是null,这里就会执行第二个if,执行原生的那个read函数。所以如果不在外面监听一下,直接read,如果fd超范围了,那可能会引起阻塞,前面说过,在libco里面只要有一个协程阻塞了,这个线程上面所有协程都会阻塞。而这个协程其实是在等待数据来,为了不阻塞,所以要在外面监听一下。但为啥不把这个read里面的epoll,这个我也很好奇,感觉在这种场景下的确可以这么干,但由于是个底层函数,所以也不好啥考虑,可能有其他用意
PS:从这里其实也可以看从,这里的用的epoll触发是水平触发(LT),如果是ET模式的话,这里会有问题。为啥呢,这里其实有两次epoll监听了,一次在外面,一次在read里面,如果是ET的话,外面触发了一次事件,里面再监听一次,是不会触发epoll事件的,所以只能用LT(简单来说,ET就是消息来了我就提醒你一次,不管你读没读,高冷型,LT就是只要你没读完我就提醒还要读,热心型)
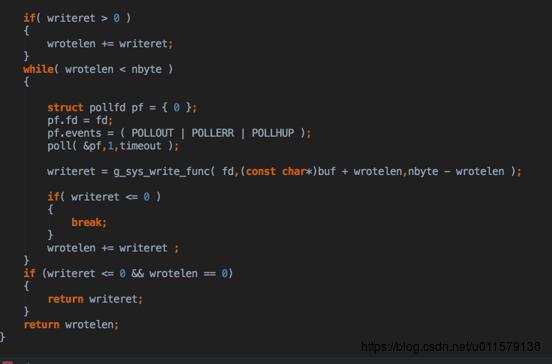
然后写读完之后,就写一样的套路,先监听一下可以写了再写,写完之后这个协程就空了,yield,然后accpet协程也是一样的走那个for循环,至此,就是整个一个echo server demo的运行流程
这里稍微说一下 糖糖 疼讯的这个开源echo server,运行一下github上的demo就是知道了,你随便输错几个参数运行echo client,直接core dump了,mac os 10.13稳定复现
不过在看libco这个echo server的时候,也顺手了解了一下惊群,其实在一些版本的linux上有这个demo有惊群问题,也就是一个消息来,唤醒了一群线程或者进程,当时还顺便自己验证了一下,的确稳定复现,这个惊群效应来自两个方面,一个是accept,这个貌似在Linux2.6之后修复了,还有一个就是epoll,这个貌似后面也有一个解决的机制
https://jin-yang.github.io/post/linux-details-of-thundering-herd.html
https://github.com/torvalds/linux/commit/df0108c5da561c66c333bb46bfe3c1fc65905898
总的来说,libco其实是一种C++的协程rpc实现方式(不能算是rpc框架吧,libco应该只是个底层库),尽量在同一线程中执行更多的东西。但协程只能同线程调度,所以一旦出现一个协程较慢,或者卡死,会导致这个线程上所有协程卡死,使用的时候需要小心。而Baidu的brpc,可以跨线程调度,少数协程慢或者卡死不会影响其他协程,或者说受影响较小(后面有空我也会写一下brpc,这个框架的确是我目前见过最好的RPC框架了)。但libco最大的优势应该在于其hook了底层的write,read,connect这样的阻塞函数,所以如果要迁移,成本应该较低,不用改原来底层的代码就可以用其特性。并且libco里面基本都是同步编程,也不会有线程安全的问题(虽然看着是协程并发,但不涉及多线程),所以开发也相对简单。libco作为微信内部框架的底层库,在线上也承受了巨大的流量,经受住了线上的考验,也算得上一个不错的底层库了。
因为前人,才能更高
1. libco github 地址:https://github.com/Tencent/libco
2.简单通俗介绍协程:
3.协程上下文切换相关介绍:https://blog.csdn.net/waruqi/article/details/53201416
4.惊群问题:https://jin-yang.github.io/post/linux-details-of-thundering-herd.html
5.epoll解决惊群问题:https://github.com/torvalds/linux/commit/df0108c5da561c66c333bb46bfe3c1fc65905898
以上是关于libco简介的主要内容,如果未能解决你的问题,请参考以下文章