MIGraphX框架解析
Posted qianqing13579
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MIGraphX框架解析相关的知识,希望对你有一定的参考价值。
前言
之前写过TNN框架解析,其实早在TNN之前我就研究过AMD开源的推理框架MIGraphX,MIGraphX的架构跟TNN完全不同,TNN其实还是受到Caffe的影响比较大,里面很多方面的设计都有Caffe的影子,很多地方命名都是基本一致的,但是MIGraphX不同,MIGraphX的算子粒度更细,更加灵活,整体架构是按照AI编译器思路来构造的,与AI编译器最大的区别在于MIGraphX的代码生成部分采用的是手工编写kernel的方式,卷积和gemm是直接用的miopen和rocblas。其实MIGraphX整体架构还是非常清晰的,里面有很多东西值得我们去学习,比如里面用到了很多高级的编程技法(比如模板和函数式编程的各种高级特性),还有很多pass也值得学习,比如内存复用优化pass用到了图着色算法,指令调度pass。本文先重点阐述MIGraphX的基本设计思想以及基本使用方法,对框架更加深入的解析等后面有时间再详细展开讨论。
目录
MIGraphX整体架构
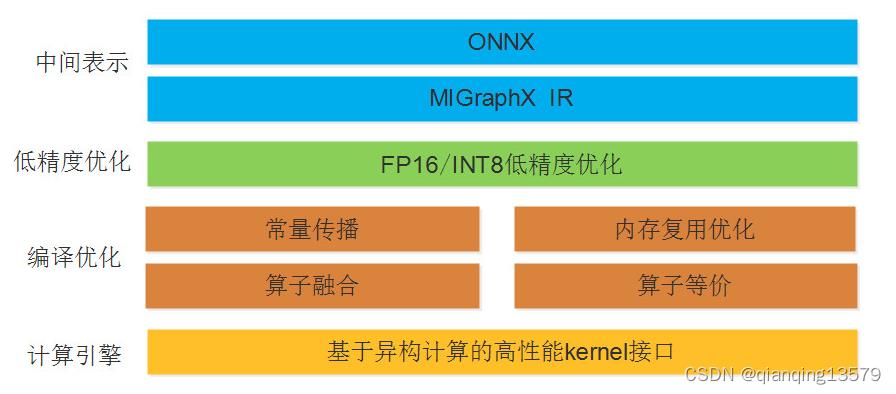
MIGraphX整体架构主要分为三层:
- 中间表示层。主要将用户训练好的onnx格式的算法模型转换为MIGraphX IR。
- 编译优化层。基于MIGraphX IR完成各种优化,比如常量折叠,内存复用优化,算子融合等。
- 计算引擎层。这一层主要包含了底层计算库的接口,包括MIOpen和rocblas ,MIGraphX后端的实现主要是通过调用计算库的方式实现的。
MIGraphX IR
AI编译中的IR从层级上分一般可以分为两种类型:多级IR和单级IR。使用多级IR可以使得系统优化更加灵活,各级IR只需要负责本级优化,但是多级IR会带来如下的问题:
- 需要在不同IR之间进行转换,IR转换做到完全兼容很难而且工作量大。
- 不同IR转换可能带来信息的损失。
- 多级IR有些优化既可以在上一层IR进行, 也可以在下一层IR进行, 让系统开发者很难选择。
MIGraphX采用了单级IR的设计,MIGraphX IR是一种基于SSA形式的线性IR,这种形式的IR可以表达计算图中的控制流信息和数据依赖关系,方便后面的编译优化。
编译优化
MIGraphX采用静态图模式,在编译优化阶段,MIGrahpX实现了如下的优化:
- 机器无关优化。包括删除公共子表达式,删除无用的代码,常量传播,常量折叠,代数化简,算子融合等。
- 内存复用优化。MIGraphX采用了图着色的方法实现无计算依赖的节点间的内存复用,显著减低内存消耗。
- 指令调度。主要是根据计算图分析指令之间的依赖关系,根据这些依赖关系优化各指令的执行顺序,从而提高计算性能。
基本概念
这里主要是对MIGraphX的几个重要的数据结构做个简单的介绍。
program
MIGraphX中使用program结构表示一个神经网络模型。
program中常用的成员函数:
- compile():编译模型,其参数是一个target
- eval(): 执行推理并返回推理结果,返回类型为std::vector,注意这是一个同步的方法
- get_parameter_shapes():返回模型的参数信息,常用来获取模型的输入参数信息,类型为std::unordered_map<std::string, shape>
instruction
MIGraphX中program是由指令组成的,可以通过module中的add_instruction()成员函数添加指令。MIGraphX中的指令相当于onnx模型中的一个节点或者caffe模型中的一个层。指令由算子加上算子的参数组成。
Shape
用来表示数据的形状。
可以通过如下方式构造一个shape对象:
- shape(type_t t, std::vector < std::size_t > l);
- shape(type_t t, std::vector < std::size_t > l, std::vector < std::size_t > s);
其中:
- t:shape的类型,shape支持的类型包括:1. bool_type,half_type,float_type,double_type,uint8_type,int8_type,uint16_type,int16_type,int32_type,int64_type,uint32_type,uint64_type
- l:每一个维度的大小
- s:每一个维度的步长,如果没有指定步长,则按照shape为standard的形式根据l自动计算出步长,关于standard的含义下文会详细阐述。
示例:
resnet50中第一个卷积层的卷积核大小为7x7,输出特征图个数为64,即有64个7x7的卷积核,如果输入的是一个3通道的图像,则该卷积核的shape可以表示为migraphx::shapemigraphx::shape::float_type, 64, 3, 7, 7,其中float_type表示shape的数据类型,这里采用float类型, 64, 3, 7, 7表示每一个维度的大小,注意64, 3, 7, 7对应的是NCHW的内存模型,由于这里没有提供每一维的步长,所以步长会自动计算。自动计算出来的每一维的步长为147,49,7,1
shape中常用的成员函数:
- lens():返回每一维的大小,维度顺序为(N,C,H,W),类型为std::vector < std::size_t >
- elements():返回所有元素的个数,类型为std::size_t
- bytes():返回所有元素的字节数,类型为std::size_t
什么是standard的shape?
在shape中有一个很重要的概念:standard。standard表示该shape没有填充且没有转置,没有填充表示内存数据是连续的,没有转置表示步长从高维到低维降序排列。下图表示一个4行6列的二维数组,该数组按照行主序的方式在内存中连续存储(与C语言中的数组一致),所以在列这个维度上步长为1,在行这个维度上的步长为6,假设该数组元素类型为float类型,则该二维数组的shape可以表示为migraphx::shapemigraphx::shape::float_type, 4,6,这里没有显式指定每一维的步长,migraphx会自动计算出步长。这里的二维数组的shape就是一个standard的shape。

MIGraphX支持视图操作(view),其中视图与原始数据是数据共享的,如果我们在该二维数组中创建一个view,如下图所示:
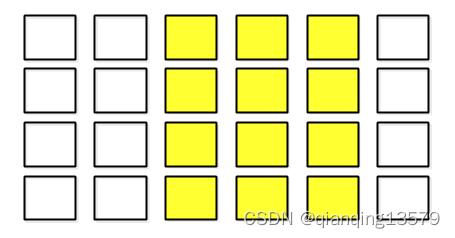
图中黄色区域表示在该二维数组中创建的一个view,该view表示一个4行3列的二维数组且与原来的二维数组共享数据,由于此时该view表示的二维数组在内存中有填充,所以该view在内存中并不是连续的,此时就不能自动计算步长了,我们就需要显式指定每一维的步长了,该view的shape可以表示为migraphx::shapemigraphx::shape::float_type, 4,3,6,1,由于该shape对应的内存中有填充,所以该shape就不是一个standard的shape。对于非standard的shape中元素的访问是通过多维索引实现的,比如访问该view的第3行第2列的元素,该元素对应的多维索引为(2,1),实际访问元素的时候需要将多维索引转换为一维索引(也就是内存索引),一维索引为多维索引和步长的内积,这里(2,1)元素对应的一维索引等于6*2+1=13,我们可以从上图看到(2,1)对应的元素相对于起始元素的内存偏移量是13,所以通过多维索引与步长的内积的方式可以正确访问到非standard的数据元素。
argument
用来保存参数的值,常用来保存指令的执行结果。
可以通过如下方式构造一个argument对象:
- argument(const shape& s);
- template argument(shape s, T* d)
- template argument(shape s, std::shared_ptr d)
第1种方式只需要提供shape就可以,系统会自动申请一段内存,该内存的大小等于shape的bytes()方法返回值的大小。第2种方式和第3种方式除了提供shape之外,还需要提供该argument的数据,argument不会自动释放该数据。
argument中常用的成员函数:
- get_shape():返回数据的形状,类型为shape
- data():返回argument的数据,类型为char *
literal
用来表示常量。MIGraphX中通常使用literal表示算子的参数,比如卷积算子中卷积核的值。实际上literal是一种特殊的argument,literal中的值不能修改,而argument中的值可以修改。
可以通过如下方式构造一个literal对象:
- template literal(const shape& s, const std::vector& x)
- template literal(const shape& s, T* x)
- template literal(const shape& s, const std::initializer_list& x)
也可以通过generate_literal()方法创建一个随机值的literal:migraphx::generate_literal(migraphx::shapemigraphx::shape::float_type, 64, 3, 7, 7, 0),其中第2个参数表示随机数的种子,不同种子会生成不同的随机数。
literal中常用的成员函数:
- get_shape():返回数据的形状,类型为shape
- data():返回literal的数据,类型为const char *,注意:不能通过data()返回的指针修改literal的值
target
表示编译模式,在MIGraphX中有两种编译模式:CPU模式和GPU模式
MIGraphX的设计思想
其实MIGraphX里面有很多设计值得我们学习,这里只讨论几个我觉得比较重要的,更多的设计思想有机会再展开讨论。
自动内存管理
MIGraphX中没有采用手动管理内存的方式,因为这样容易导致内存泄漏,特别是在发生异常的时候。MIGraphX中的自动内存管理主要采用如下两种方式:
- 对于原始内存的申请,使用std::make_unique 或者 std::make_shared ,对于数组类型的元素,使用std::vector
- 对于非内存类型的资源,比如文件FILE*,使用MIGRAPHX_MANAGE_PTR 宏来创建一个std::unique_ptr,MIGRAPHX_MANAGE_PTR 宏是对std::unique_ptr的一种封装,通过MIGRAPHX_MANAGE_PTR可以正确的调用和释放资源。
示例1:
using file_ptr = MIGRAPHX_MANAGE_PTR(FILE*, fclose);
file_ptr ffopen("some_file", "r");
示例2:
using hip_stream_ptr = MIGRAPHX_MANAGE_PTR(hipStream_t, hipStreamDestroy);
hip_stream_ptr create_stream()
hipStream_t result = nullptr;
auto status = hipStreamCreateWithFlags(&result, hipStreamNonBlocking);
if(status != hipSuccess)
MIGRAPHX_THROW("Failed to allocate stream");
return hip_stream_ptrresult;
使用标准库中的算法
MIGraphX中使用标准库中提供的算法来代替使用原始的循环结构,因为原始的循环接口有如下缺点:
- 带来了隐式的性能开销
- 容易出错,特别是在处理边界的时候
- 难以解释并且难以证明后续条件
使用算法比原始的循环结果更加高效,而且算法更加容易优化,如果没有一个合适的算法来替代原始循环结果,添加一个新的算法是个好办法。
示例:
对于下面一段程序
void f(vector<string>& v)
string val;
cin >> val;
// ...
int index = -1;
for (int i = 0; i < v.size(); ++i)
if (v[i] == val)
index = i;
break;
// ...
我们可以使用标准库中的std::find算法来代替:
void f(vector<string>& v)
string val;
cin >> val;
// ...
auto p = find(begin(v), end(v), val);
// ...
通过类型擦除(Type Erasure)机制实现多态
MIGraphX中有许多函数的实现需要使用到多态机制,比如在MIGraphX中神经网络是使用program表示,program中包含了许多指令,添加指令需要用到如下函数:
instruction_ref module::add_instruction(const operation& op, std::vector<instruction_ref> args)
该函数的第一个参数表示该指令执行的操作,MIGraphX中使用算子表示,但是实际中有很多算子,比如卷积算子、relu算子等,也就是说operation类型需要能够被多种类型的算子赋值,能够表示不同类型的算子,这就是多态机制,MIGraphX采用了类型擦除机制来实现多态。
关于类型擦除的原理,参考这篇博客:C++多态的另一种实现:类型擦除
下面我们先从一个简单的分类示例看一下如何使用MIGraphX。
如何使用MIGraphX
#include <string>
#include <vector>
#include <migraphx/onnx.hpp>
#include <migraphx/gpu/target.hpp>
#include <migraphx/quantization.hpp>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
using namespace cv::dnn;
using namespace migraphx;
int main(int argc, char *argv[])
// 加载模型
migraphx::program net= migraphx::parse_onnx("AlexNet.onnx");
// 获取模型输入属性
std::pair<std::string, migraphx::shape> inputAttribute=*(net.get_parameter_shapes().begin());
string inputName=inputAttribute.first;
migraphx::shape inputShape=inputAttribute.second;
int N=inputShape.lens()[0];
int C=inputShape.lens()[1];
int H=inputShape.lens()[2];
int W=inputShape.lens()[3];
printf("input name:%s\\n",inputName.c_str());
printf("input shape:%d,%d,%d,%d\\n",N,C,H,W);
// 使用FP16
migraphx::quantize_fp16(net);
// 编译模型
migraphx::compile_options options;
options.offload_copy=true; // 设置offload_copy
net.compile(migraphx::gpu::target,options);// GPU模式
// 预处理并转换为NCHW
int batchSize=N;
Mat srcImage=imread("Test.jpg");
vector<Mat> srcImages;
for(int i=0;i<batchSize;++i)
srcImages.push_back(srcImage);
Mat inputBlob;
blobFromImages(srcImages,inputBlob,0.0078125,cv::Size(W,H),cv::Scalar(127.5,127.5,127.5),false,false);
// 输入数据
migraphx::parameter_map inputData;
inputData[inputName]= migraphx::argumentinputShape, (float*)inputBlob.data;
// 推理
std::vector<migraphx::argument> results = net.eval(inputData);
// 获取输出节点的属性
migraphx::argument result = results[0]; // 获取第一个输出节点的数据
migraphx::shape outputShape=result.get_shape(); // 输出节点的shape
std::vector<std::size_t> outputSize=outputShape.lens();// 每一维大小,维度顺序为(N,C,H,W)
int numberOfOutput=outputShape.elements();// 输出节点元素的个数
float *resultData=(float *)result.data();// 输出节点数据指针
// 获取推理结果
int numberOfPerImage=numberOfOutput/N; // 每张图像的输出个数
printf("output size:%d\\n",numberOfPerImage);
for(int i=0;i<N;++i)
printf("==========%d image output=============\\n",i);
int startIndex=numberOfPerImage*i;
for(int j=0;j<numberOfPerImage;++j)
printf("%f,",resultData[startIndex+j]);
printf("\\n");
return 0;
首先通过parse_onnx()方法加载onnx模型(MIGraphX目前只支持onnx格式),然后通过compile方法编译网络,这里将网络编译为GPU类型,如果需要编译为CPU类型,需要使用migraphx::cpu::target。输入数据需要转换为NCHW的格式,这里使用了OpenCV的blobFromImage函数将数据转换为了NCHW格式。Program的eval用来执行推理计算。这里需要注意,在编译网络的时候,需要设置offload_copy为true。如果我们想加速推理,可以使用FP16或者INT8。使用FP16进行推理只需要在compile之前加上下面一句话:
migraphx::quantize_fp16(net);
使用INT8推理
目前MIGraphX是支持INT8推理的,虽然性能不太好。使用INT8模式进行推理需要用户提供量化校准数据,MIGraphX采用线性量化算法,通过校准数据计算量化参数并生成量化模型。为了保证量化精度,建议使用验证集或者测试集中多个典型的数据作为量化校准数据,如果用户没有提供量化校准数据,MIGraphX会使用默认的量化参数,这样可能会导致严重的精度下降。MIGraphX的INT8量化流程如下:
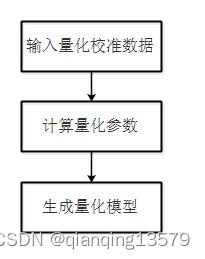
使用INT8模式推理需要在compile之前加上下面一段代码:
// 读取校准数据,本示例这里采用OpenCV读取
Mat srcImage=imread("CalibrationData.jpg",1);
std::vector<cv::Mat> srcImages;
for(int i=0;i<inputShape.lens()[0];++i)
srcImages.push_back(srcImage);
Mat inputBlob;
blobFromImages(srcImages,inputBlob,0.0078125,cv::Size(W,H),cv::Scalar(127.5,127.5,127.5),false,false);
migraphx::parameter_map inputData;
inputData[inputName]= migraphx::argumentinputShape, (float*)inputBlob.data;
// 创建量化数据,这里只使用了一张图像,实际使用时为了提高量化精度,建议使用多张图像创建多个inputData进行量化
std::vector<migraphx::parameter_map> calibrationData = inputData;
// INT8量化
migraphx::quantize_int8(net, migraphx::gpu::target, calibrationData);
在Python中使用MIGraphX
MIGraphX是可以支持python接口的,下面看一下基本使用方法:
from PIL import Image
import numpy as np
import migraphx
def ReadImage(pathOfImage,inputShape):
resizedImage = Image.open(pathOfImage).resize( (inputShape[3], inputShape[2]) )
srcImage = np.asarray(resizedImage).astype("float32")
# 转换为NCHW
srcImage_NCHW = np.transpose(srcImage, (2, 0, 1))
# 预处理
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inputData = np.zeros(srcImage_NCHW.shape).astype("float32")
for i in range(srcImage_NCHW.shape[0]):
inputData[i, :, :] = (srcImage_NCHW[i, :, :]/ 255 - mean[i]) / std[i]
# 增加batch维度
imageData = np.expand_dims(inputData, axis=0)
return imageData
def Softmax(x):
return np.exp(x)/sum(np.exp(x))
if __name__ == '__main__':
# 加载模型
model = migraphx.parse_onnx("alexnet.onnx")
inputName=model.get_parameter_names()[0]
inputShape=model.get_parameter_shapes()[inputName].lens()
print("inputName:0 \\ninputShape:1".format(inputName,inputShape))
# FP16
migraphx.quantize_fp16(model)
# 编译
model.compile(migraphx.get_target("gpu"))
# 读取图像
pathOfImage ="Test.jpg"
image = ReadImage(pathOfImage,inputShape)
# 推理
results = model.run(inputName: migraphx.argument(image))
# 获取输出节点属性
result=results[0] # 获取第一个输出节点的数据,migraphx.argument类型
outputShape=result.get_shape() # 输出节点的shape,migraphx.shape类型
outputSize=outputShape.lens() # 每一维大小,维度顺序为(N,C,H,W),list类型
numberOfOutput=outputShape.elements() # 输出节点元素的个数
# 获取输出结果
resultData=result.tolist() # 输出数据转换为list
result = np.array(resultData)
scores = Softmax(result) # 计算softmax
print(scores)
MIGraphX中的dynamic shape(动态shape)
到目前为止,MIGraphX还不能支持动态shape,虽然官方很早就说动态shape的功能已经在开发了,但是直到现在还不能支持,现在AI领域很多模型都需要动态shape的支持,所以这会限制MIGraphX的使用,期待MIGraphX团队能尽快实现动态shape功能。
结束语
本文只是简单介绍了MIGraphX的基本架构、基本概念设计思想和基本的使用方法,对于更加深入的框架解析后面有空再展开讨论。欢迎大家留言一起讨论。
以上是关于MIGraphX框架解析的主要内容,如果未能解决你的问题,请参考以下文章