Distillation based Multi-task Learning: A Candidate GenerationModel for Improving Reading Duration
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Distillation based Multi-task Learning: A Candidate GenerationModel for Improving Reading Duration相关的知识,希望对你有一定的参考价值。
目录
摘要
在feed流推荐中,第一步是召回。大多数召回模型都是基于 CTR 预估的,没有考虑用户对被点击的 item (商品)的满意度。可能会向用户推荐质量低但有吸引人的标题的商品 ,这会恶化用户体验。解决这个问题的一个方法是在多任务学习(MTL)框架下同时建模点击和阅读时长。建模中有两个挑战。第一个问题是如何处理负样本的零阅读时长,零阅读时长并不一定表示不喜欢。第二个问题是如何在召回的双塔结构的模型中进行多任务学习,该模型只能对单个任务进行建模。本文提出了一种基于蒸馏的多任务学习(DMTL)方法来解决这两个挑战。我们通过考虑MTL中点击的依赖性对阅读时长进行建模,然后通过蒸馏将从MTL教师模型学到的知识转移到学生召回模型。在 Tencent Kandian’s 推荐系统的流量日志数据集上进行的实验表明,该方法在建模阅读时长方面明显优于竞争对手,这证明了该召回模型的有效性。
1 引言
CTR 预估是许多推荐系统中广泛采用的排序方法。近年来提出了许多基于深度学习的模型来预估CTR。至于feed推荐, predicted CTR( pCTR )可以反映用户点击该商品的可能性,但不能反映用户点击并阅读内容后喜欢该商品的几率。例如,低质量但标题党的商品通常获得较高的 pCTR ,但用户从不喜欢它们。因此,仅对 CTR 建模无法确保用户对所点击的商品的满意度。为了改善用户体验,还应该对阅读时长进行建模,这在工业应用中非常重要,例如 feed 流推荐。
本文主要研究阅读时长建模及其在大规模feed推荐召回中的应用。在我们的实际实践中有两个主要挑战。第一个挑战是如何处理负样本的零阅读时长。负样本的阅读时长为零,只是因为它们没有被点击,这并不一定表明用户不喜欢该 item 。这与正样本的零阅读时长有很大不同,后者表示不喜欢。直接使用零阅读时长作为建模目标可能导致估计不准确。第二个挑战是由第一个挑战引起的。为了解决第一个挑战的问题,采用了多任务学习。然而,在召回模型中很难实现多任务学习。众所周知,大多数基于深度学习的召回模型都采用双塔结构。它们有一个用户塔和一个商品塔,分别用于计算用户向量和商品 向量,并使用 user - item 内积作为 ANN 搜索的相似性度量,这种召回方式的效率是比较高的。由于内积只能对单个任务建模,因此很难将多任务学习直接应用于召回模型。据我们所知,很少有论文讨论阅读时长建模。在实际操作中,常用的方法是在单个任务中通过回归对阅读时长建模,其中所有负样本的阅读时长设置为零,并使用平方损失。如前所述,将负样本的阅读时长设置为零可能会对不喜欢(短持续时间)和未点击(零阅读时长,但不一定不喜欢)进行类似的处理,这可能会误导模型培训。
为了应对上述挑战,我们提出了一种基于蒸馏的多任务学习方法,我们称之为 DMTL ( distillation
based multi-task learning approach ),用于在召回模型中建模阅读时长。我们通过在多任务学习框架中考虑阅读时长对点击的依赖性来克服现有阅读时长模型的问题,该框架同时分别为阅读时长任务、点击任务建模 CTR 和 CTCVR 。然后,我们使用蒸馏技术将多任务模型学习到的知识转移到双塔召回模型,使召回模型在保持其高效的召回能力的同时,获得了建模阅读时长的能力。
为了评估该方法的性能,我们对从腾讯 Kandian 推荐系统的流量日志中收集的数据集进行了实验。离线和在线实验的结果表明,该方法明显优于其他阅读时长模型,这表明了该方法在为召回模型建模阅读时长方面的有效性。
2 提出的方法
2.1 多任务学习建模阅读时长
召回的目的是从可能包含数百万甚至数十亿个商品的整个商品库中选择数百或数千个与用户兴趣相关的商品。本文提出的 DMTL 同时对点击和阅读时长建模,而不是仅仅对点击建模,从而提高了召回的质量。对于点击任务,正样本是被点击的样本,负样本是根据被点击概率从整个商品库中随机选择的。这与使用点击样本作为正样本、未点击样本作为负样本的排序模型有很大不同。对于阅读时长任务,正样本是阅读时长超过50秒的点击商品(即所有阅读时长的中位数),其余是负样本。
分别用  和
和 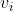 表示用户特征和商品特征,它们通常是多个特征的embedding 拼在一起的结果。用
表示用户特征和商品特征,它们通常是多个特征的embedding 拼在一起的结果。用  表示所有特征(即 、 和其他dense 特征拼在一起的结果)。 click 任务的正样本
表示所有特征(即 、 和其他dense 特征拼在一起的结果)。 click 任务的正样本  表示被点击过的样本,负样本
表示被点击过的样本,负样本  表示随机选择的那些。阅读时长任务的正样本
表示随机选择的那些。阅读时长任务的正样本  表示阅读时长超过50s的那些,其他的则为负样本。阅读时长任务就是当给定 , 的概率,即
表示阅读时长超过50s的那些,其他的则为负样本。阅读时长任务就是当给定 , 的概率,即 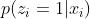 。如前所述,
。如前所述, 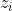 依赖
依赖 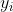 ,因为当 时一定有
,因为当 时一定有  。 我们利用阅读时长和点击的依赖来更好的建模。例如将 重写为
。 我们利用阅读时长和点击的依赖来更好的建模。例如将 重写为

其中,  是预测的 CTR ( PCTR ),
是预测的 CTR ( PCTR ), 是预测的 CVR ( PCVR ),
是预测的 CVR ( PCVR ), 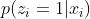 是预测的点击转化率 ( PCTCVR )。在建模阅读时长的时候为了减小样本选择偏差和数据稀疏的问题,采用 ESMM 中的方式。在这个任务中 click 任务对应 ESMM 的 CTR 任务,阅读时长任务对应 CTCVR 任务。
是预测的点击转化率 ( PCTCVR )。在建模阅读时长的时候为了减小样本选择偏差和数据稀疏的问题,采用 ESMM 中的方式。在这个任务中 click 任务对应 ESMM 的 CTR 任务,阅读时长任务对应 CTCVR 任务。
采用 MMoE 框架来建模 CTR 和 CVR 。 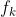 代表第 k 个专家网络,
代表第 k 个专家网络,  代表第 k 个专家网络的输出。对于 CTR 任务,门是
代表第 k 个专家网络的输出。对于 CTR 任务,门是 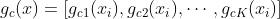 ,其中
,其中 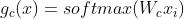 ,
,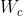 是可学习矩阵,K 是专家网络的数目,
是可学习矩阵,K 是专家网络的数目,  是
是  的第 k 个元素。 CTR 专家网络的输出是
的第 k 个元素。 CTR 专家网络的输出是

CVR 任务的专家网络的输出是
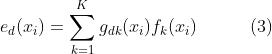
样本 的 pCTR 和 pCVR 建模为

pCTCVR 如下

因为用 CTCVR 的任务对应的阅读时长任务,所以阅读时长的交叉熵损失如下

式子(6)和(7)通过将  用来计算
用来计算 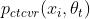 建模了点击和阅读的依赖。点击任务作为辅助任务,其损失如下
建模了点击和阅读的依赖。点击任务作为辅助任务,其损失如下
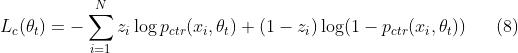
两个任务的损失的加权和就是多任务的损失

2.2 召回模型的蒸馏
在大多数基于深度学习的召回模型中,双塔结构用于计算用户向量和商品向量,其中商品向量用于构建商品索引。对于给定的用户向量, user-item 的内积作为 ANN 搜索的相似性, top-k 项作为候选商品返回。然而,召回模型无法通过多任务学习来建模阅读时长,因为内积只能建模一个任务。为了使召回模型在其高效的双塔结构框架内获得建模阅读时长的额外能力,我们使用蒸馏技术将第 2.1 节中 MTL 模型学习到的知识迁移到召回模型。
召回模型使用双塔结构, 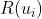 和
和 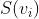 分别代表用户向量和商品向量。其中
分别代表用户向量和商品向量。其中 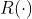 和
和 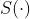 是分别用来将输入 embedding 转换为输出向量的神经网络。给定 和 ,召回模型的 CTCVR 预测为
是分别用来将输入 embedding 转换为输出向量的神经网络。给定 和 ,召回模型的 CTCVR 预测为

其中  是 和
是 和  的内积,
的内积,  是 和 的参数,我们期待
是 和 的参数,我们期待  和
和  越相近越好。这样在保证召回模型高效的同时我们就可以用式子(10)来准确的预估 CTCVR (阅读时长)。我们将 MTL 模型(式子 9 )作为 teacher model ,双塔召回模型(式子 10 )作为 student model 。蒸馏的损失用 KL 散度表示为
越相近越好。这样在保证召回模型高效的同时我们就可以用式子(10)来准确的预估 CTCVR (阅读时长)。我们将 MTL 模型(式子 9 )作为 teacher model ,双塔召回模型(式子 10 )作为 student model 。蒸馏的损失用 KL 散度表示为
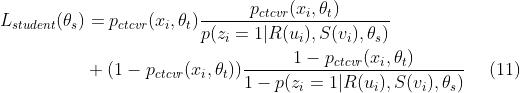
将 teacher model 和 student model 的损失相加,就得到了 基于知识蒸馏的多任务学习 的损失

为了使 teacher model 在训练的时候不受 student model 的影响, student model 和 teacher model 的参数是分开的,并且在计算 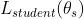 的时候冻结 teacher model 的 pCTCVR 。这样的话最小化式子 12 等价于交替最小化 teacher 的损失 和 student 的损失。在推断阶段,我们只使用 student model 计算用户向量和商品向量,其中商品向量用于构建索引,用户向量用作查询, ANN 搜索用于从索引中为用户提取 top-k 候选商品。该模型的网络结构如图1所示。
的时候冻结 teacher model 的 pCTCVR 。这样的话最小化式子 12 等价于交替最小化 teacher 的损失 和 student 的损失。在推断阶段,我们只使用 student model 计算用户向量和商品向量,其中商品向量用于构建索引,用户向量用作查询, ANN 搜索用于从索引中为用户提取 top-k 候选商品。该模型的网络结构如图1所示。

以上是关于Distillation based Multi-task Learning: A Candidate GenerationModel for Improving Reading Duration的主要内容,如果未能解决你的问题,请参考以下文章