秒懂MyBatis之读写分离简单实现
Posted ShuSheng007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了秒懂MyBatis之读写分离简单实现相关的知识,希望对你有一定的参考价值。
[版权申明] 非商业目的注明出处可自由转载
出自:shusheng007
文章目录
概述
多年前在springboot中集成mybatis访问数据库后,一下就被其强大的功能征服了,从此再也没有用过纯JDBC的API,但是当时心中隐约还是有个疑问:要是我们的APP要同时访问两个数据库,那MyBatis咋办呢?因为只是想了下,于是还是不知道…直到有一天要搞读写分离…最近又看到了这个话题,于是就叨叨几句。
在生产环境中搞读写分离一般采用成熟的第三方方案,例如代理模式的mycat,以及客户端模式的sharding-jdbc,但是手动实现一个读写分离方案对我们理解底层的原理帮助是巨大的。今天我们就手动实现一下如何使用mybati实现读写分离,同时这种方法也适用于切换多数据源的场景。
原理
首先要明白所谓的读写分离就是要在读操作和写操作的时候访问不同的数据库服务器,所以问题就转化为如何动态切换数据源的问题了。
一般情况下,我们只有一个数据源,例如你经常在application.yml中配置数据源:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ss007_db?characterEncoding=UTF-8&useSSL=false
username: xxxx
password: xxxx
driver-class-name: com.mysql.cj.jdbc.Driver
然后你引入了MyBatis的starter:mybatis-spring-boot-starter,然后这个数据源呢就会被springboot自动配置给MyBatis的SqlSessionFactory,然后MyBatis就可以使用它产生SqlSesson来访问数据库了。但现在我们有两个数据源了,所以就必须自己手动生成SqlSessionFactory了。
实现
搭建主备份数据库
这块查看:秒懂MySql之从零搭建主从架构
配置多数据源
这块最为关键的就是org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource这个类,这个类在spring-jdbc里,在引入mybatis的starter时会自动引入。
使用这个抽象类用来构建我们的多数据源,以及实现在这些数据源中切换的功能。
- 构建一个用来切换数据源的类
考虑到多线程访问,我们需要将当前状态保存在ThreadLocal中。
/**
* Created by shusheng007
*
* @author benwang
* @date 2022/10/1 10:40
* @description:
*/
@Slf4j
public class DataSourceSwitcher
private static final ThreadLocal<DataSourceType> DB_TYPE_CONTAINER = new ThreadLocal<>();
private static void switchDb(DataSourceType dbType)
DB_TYPE_CONTAINER.set(dbType);
log.info("切换数据源:",dbType);
public static void useMaster()
switchDb(DataSourceType.MASTER);
public static void useSlave()
switchDb(DataSourceType.SLAVE);
public static DataSourceType getCurrentDb()
return DB_TYPE_CONTAINER.get();
...
- 构建可以路由的数据源
AbstractRoutingDataSource 是spring-jdbc提供给我们的一个抽象类,它是一个DataSource,可以设置给MyBatis的SqlSessionFactory,它的原理很简单。
里面有一个Map,这个map用来保存多个数据源,例如我们这里有master和slave两个数据源,我们把这两个数据源保存在这个map里,然后在使用的时候通过key获取对应的value即可。
@Nullable
private Map<Object, Object> targetDataSources;
其中只有一个抽象方法determineCurrentLookupKey需要实现。这个方法就是用来动态指定我们的key的,例如写的时候我们就返回DataSourceType.MASTER这个key,读的时候返回DataSourceType.SLAVE,通过这个key就可以拿到对应的数据源了。
/**
* Created by shusheng007
*
* @author benwang
* @date 2022/10/1 10:36
* @description: 切换数据源
*/
public class DefaultRoutingDataSource extends AbstractRoutingDataSource
@Override
protected Object determineCurrentLookupKey()
return DataSourceSwitcher.getCurrentDb();
- 构建数据源配置文件
在属性文件中提供数据库连接信息:
spring:
ss007-datasource:
master:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3001/ss007_01?characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai&autoReconnect=true
username: root
password: root
slave:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3002/ss007_01?characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai&autoReconnect=true
username: root
password: root
上面配置了两个数据源,这块相信大家已经非常熟悉了
使用配置文件构建数据:
/**
* Created by shusheng007
*
* @author benwang
* @date 2022/10/2 09:38
* @description: 多数据源配置文件,用来构建一个多数据源的DataSource
*/
@Configuration
public class DataSourceConfig
@Bean
@ConfigurationProperties("spring.ss007-datasource.master")
public DataSource masterDs()
return DataSourceBuilder.create().build();
@Bean
@ConfigurationProperties("spring.ss007-datasource.slave")
public DataSource slaveDs()
return DataSourceBuilder.create().build();
@Bean
public DataSource targetDs(@Qualifier("masterDs") DataSource masterDs,
@Qualifier("slaveDs") DataSource slaveDs)
Map<Object,Object> targetDs = new HashMap<>();
targetDs.put(DataSourceType.MASTER,masterDs);
targetDs.put(DataSourceType.SLAVE,slaveDs);
DefaultRoutingDataSource routingDs = new DefaultRoutingDataSource();
//绑定所有的数据源
routingDs.setTargetDataSources(targetDs);
//绑定默认数据源
routingDs.setDefaultTargetDataSource(masterDs);
return routingDs;
上面的配置非常关键,targetDs返回的是我们的自定义数据源DefaultRoutingDataSource,里面保存了我们的master和slave两个数据源。一会我们会把这个数据源配置给Mybatis。
至此,多数据源已经成功构建了,接下里我们需要配置mybatis了。
配置MyBatis
/**
* Created by shusheng007
*
* @author benwang
* @date 2022/10/2 09:48
* @description:
*/
@MapperScan(basePackages = "top.shusheng007.readwritesplit.demo.persistence.mapper")
@Configuration
@EnableTransactionManagement
public class MyBatisConfig
@Qualifier("targetDs")
@Autowired
private DataSource dataSource;
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath:/mapper/*.xml"));
return bean.getObject();
...
这一步我们只需要将上一步生成的那个数据源DefaultRoutingDataSource(targetDs)配置给MyBatis的SqlSessionFactory即可。
至此其实已经OK了,在我们读写数据库的时候手动切换数据源就好了,例如:
public void save()
DataSourceSwitcher.useMaster();
//访问master数据库
mapper.insert();
但是相信聪明的你很快就发现了问题,在每个数据库操作之前都要写一句切换数据库的代码,烦死个人,有没有什么办法可以简化一下呢?对了,那就是AOP!
使用AOP改进
- 定义两个注解
@Write和@Read
- 定义一个切面
@Aspect
@Component
public class DataSourceAop
/**
* 读切点
*/
@Pointcut("@annotation(top.shusheng007.readwritesplit.anotation.Read)")
public void readPointcut()
/**
* 写切点
*/
@Pointcut("@annotation(top.shusheng007.readwritesplit.anotation.Write)")
public void writePointcut()
@Before("readPointcut()")
public void beforeRead()
DataSourceSwitcher.useSlave();
@Before("writePointcut()")
public void beforeWrite()
DataSourceSwitcher.useMaster();
如何使用
在使用的时候,用@Write或者@Read来标记相应的方法即可。
@Slf4j
@RequiredArgsConstructor
@Service
public class DemoService
private final StudentMapper studentMapper;
@Write
public Student saveStudent(StudentReq param)
Student student = new Student();
...
studentMapper.insert(student);
return student;
测试:
- 查看数据库当前状态
主库:
MariaDB [mysql]> use ss007_01;
Database changed
MariaDB [ss007_01]> show tables;
+--------------------+
| Tables_in_ss007_01 |
+--------------------+
| student |
+--------------------+
1 row in set (0.001 sec)
MariaDB [ss007_01]> select * from student;
Empty set (0.001 sec)
从库:
MariaDB [(none)]> use ss007_01;
MariaDB [ss007_01]> select * from student;
Empty set (0.001 sec)
可见主从库中student表都为空。
- 插入数据(写)
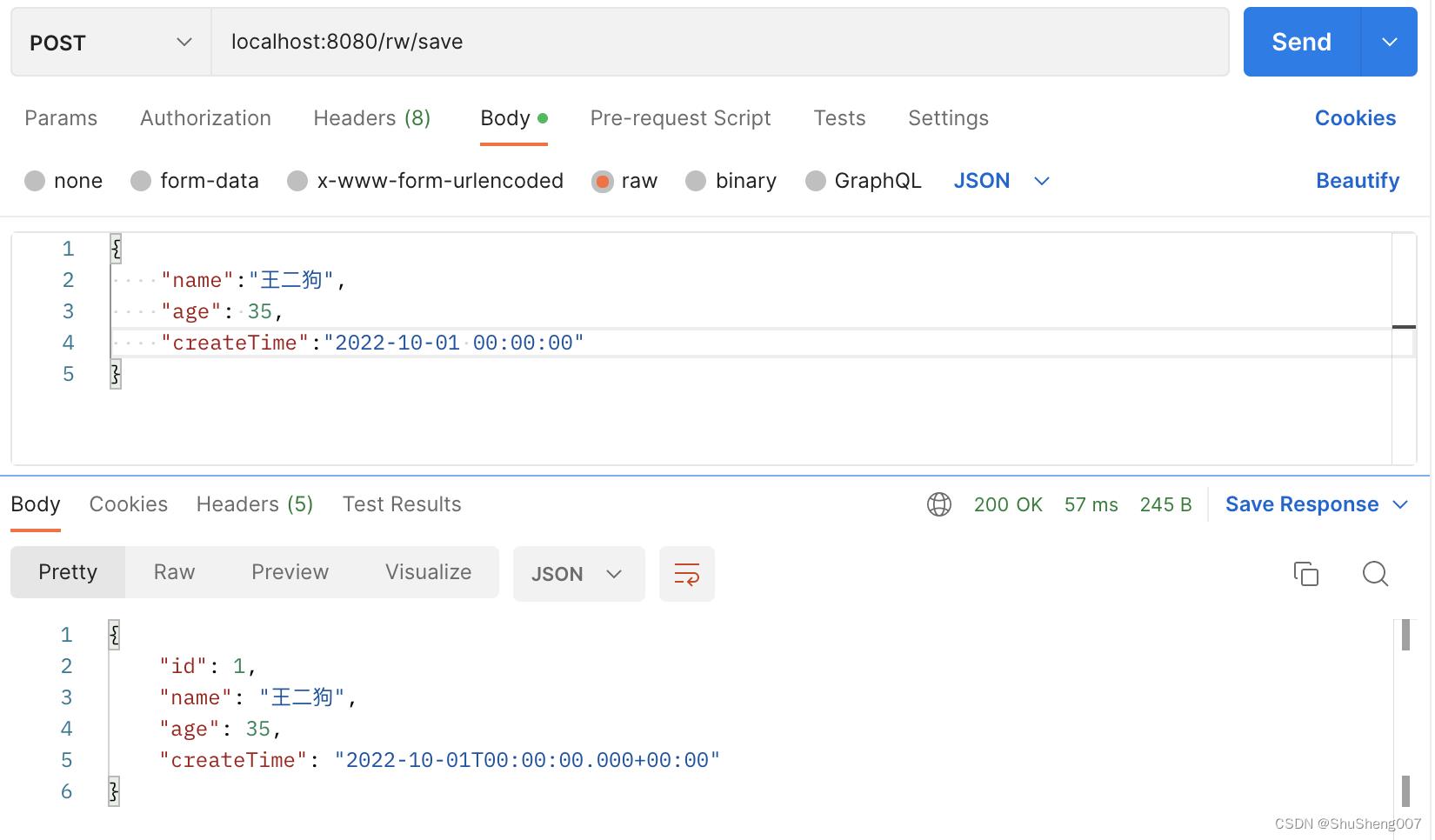
查看数据库状态:
主库:
MariaDB [ss007_01]> select * from student;
+----+-----------+-----+---------------------+
| id | name | age | create_time |
+----+-----------+-----+---------------------+
| 1 | 王二狗 | 35 | 2022-10-01 08:00:00 |
+----+-----------+-----+---------------------+
1 row in set (0.001 sec)
从库:
MariaDB [ss007_01]> select * from student;
+----+-----------+-----+---------------------+
| id | name | age | create_time |
+----+-----------+-----+---------------------+
| 1 | 王二狗 | 35 | 2022-10-01 08:00:00 |
+----+-----------+-----+---------------------+
1 row in set (0.001 sec)
可见数据已经插入了主库,并被同步到了从库。有的同学要问了:两个结果完全一样,你怎么证明插入到了master而不是slave。因为我们搭建的是主从复制,数据只能从主库复制到从库,不能从从库复制到主库…
- 查询数据(读)
为了证明查询走的是slave,我们需要手动修改一下slave库的数据。
MariaDB [ss007_01]> update student set age = 18 where id = 1;
Query OK, 1 row affected (0.003 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MariaDB [ss007_01]> select * from student;
+----+-----------+-----+---------------------+
| id | name | age | create_time |
+----+-----------+-----+---------------------+
| 1 | 王二狗 | 18 | 2022-10-02 08:13:08 |
+----+-----------+-----+---------------------+
1 row in set (0.002 sec)
我们已经将从库的王二狗年龄从35改到了风华正茂的18岁,而主库的王二狗还是即将被辞退的35岁,接下来我们查一下。
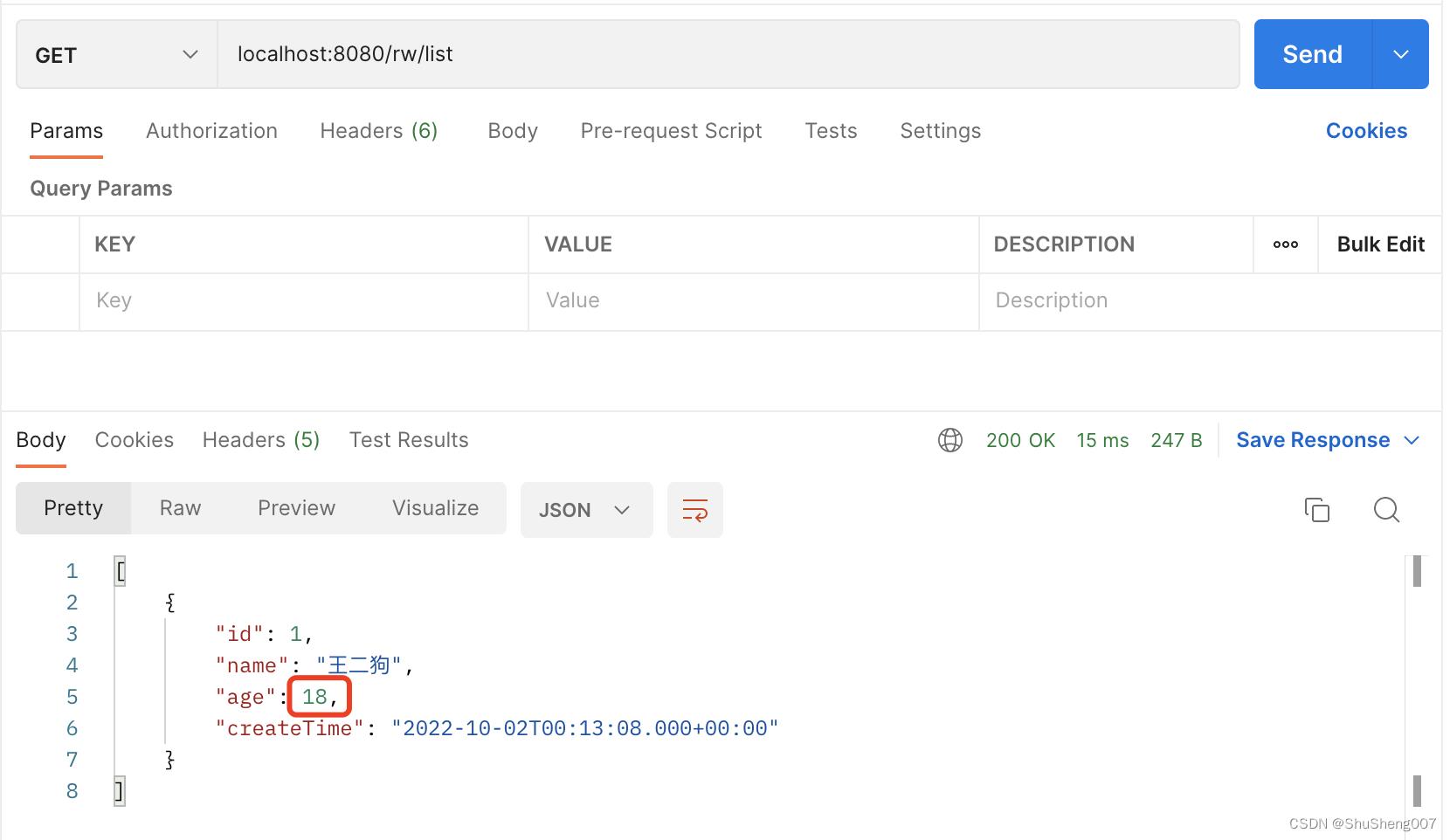
可见查到的是18岁的王二狗,这就证明了我们成功完成了读写分离。
下面是输出的日志:
切换数据源:MASTER
插入学生:"id":1,"name":"王二狗","age":35,"createTime":1664582400000
切换数据源:SLAVE
获取学生列表:["id":1,"name":"王二狗","age":18,"createTime":1664669588000]
总结
至此我们已经完成了一套使用mybatis进行读写分离的方案,如果你愿意也可以使用到生产环境中。但是如果是大型项目更推荐使用本文开头提到的现存成熟的方案,但本文作为学习资料是非常非常有价值的。
本文源码可以在GitHub上获取:read-write-split,小星星点帮忙起来哦。
以上是关于秒懂MyBatis之读写分离简单实现的主要内容,如果未能解决你的问题,请参考以下文章