目标检测 YOLOv3 基本思想
Posted 氢键H-H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测 YOLOv3 基本思想相关的知识,希望对你有一定的参考价值。
目标检测 YOLOv3 基本思想
1. 简介
参考源于产业实践的开源深度学习平台 飞桨PaddlePaddle 的《零基础实践深度学习》 的 《目标检测YOLOv3》
根据以上资料,简化和重新梳理 YOLOv3 模型设计的基本思想
相关源码参考上述《目标检测YOLOv3》 或者 YOLOv3-PaddlePaddle
2. 基础概念
2.1. 边界框(bounding box)
目标检测通常使用 边界框(bounding box,bbox)来表示物体的位置
边界框是正好能包含物体的矩形框

通常有两种格式来表示边界框的位置:
- ( x 1 x_1 x1, y 1 y_1 y1, x 2 x_2 x2, y 2 y_2 y2) :表示矩形框左上角和右下角的坐标
- ( x x x, y y y, w w w, h h h):表示矩形框中心点的坐标,矩形框的宽度和高度
图片坐标的原点在左上角,x轴向右为正方向,y轴向下为正方向
在检测任务中,训练数据集的标签里会给出目标物体真实边界框所对应的(
x
1
x_1
x1,
y
1
y_1
y1,
x
2
x_2
x2,
y
2
y_2
y2)
这样的边界框也被称为真实框(ground truth box)
在预测过程中,模型会对目标物体可能出现的位置进行预测
由模型预测出的边界框则称为预测框(prediction box),如上图所示
2.2. 锚框(Anchor box)
锚框与物体边界框不同,是由人们假想出来的一种框
先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框
在下图中,以像素点[300, 500]为中心可以使用下面的程序生成3个框
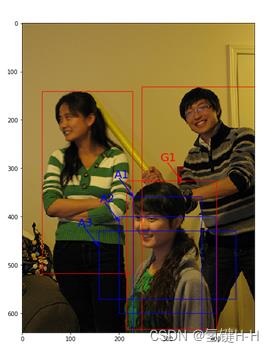
如图中蓝色框所示,其中锚框A1跟人像区域非常接近
在目标检测任务中,通常会以某种规则在图片上 生成一系列锚框,将这些锚框当成可能的候选区域
模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别
还有更为重要的一点是,由于锚框位置是固定的,它不大可能刚好跟物体边界框重合
所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框,模型需要预测出微调的幅度
在训练过程中,模型通过学习不断的调整参数
最终能学会如何判别出锚框所代表的候选区域 是否包含物体,如果包含物体的话,物体属于哪个类别,以及物体边界框相对于锚框位置需要调整的幅度
2.3. 交并比(loU)
如何衡量这三个锚框跟真实框之间的关系呢?
在检测任务中,使用交并比(Intersection of Union,IoU)作为衡量指标
这一概念来源于数学中的集合,用来描述两个集合A和B之间的关系
它等于两个集合的交集里面所包含的元素个数,除以它们的并集里面所包含的元素个数
具体计算公式:
I
o
U
=
A
∪
B
A
∩
B
IoU= \\fracA∪BA∩B
IoU=A∩BA∪B

交集的宽度inter_w为AB两个集合的右边的最小值减去左边的最大值:
m
a
x
max
max(
m
i
n
min
min(
A
x
m
a
x
A_x_max
Axmax,
B
x
m
a
x
B_x_max
Bxmax) -
m
a
x
max
max(
A
x
m
i
n
A_x_min
Axmin,
B
x
m
i
n
B_x_min
Bxmin), 0)
交集的高度inter_h为AB两个集合的下边的最小值减去上边的最大值:
m
a
x
max
max(
m
i
n
min
min(
A
y
m
a
x
A_y_max
Aymax,
B
y
m
a
x
B_y_max
Bymax) -
m
a
x
max
max(
A
y
m
i
n
A_y_min
Aymin,
B
y
m
i
n
B_y_min
Bymin), 0)
A
∪
B
A∪B
A∪B = inter_w x inter_h
A
∩
B
A∩B
A∩B = 面积
S
A
S_A
SA + 面积
S
B
S_B
SB -
A
∪
B
A∪B
A∪B
算法的实现具体可以参考代码和资料
为了直观的展示交并比的大小跟重合程度之间的关系
下图示意了不同交并比下两个框之间的相对位置关系,从 IoU = 0.95 到 IoU = 0

3. 训练思想

-
按一定规则在图片上产生一系列的候选区域
-
根据这些候选区域与真实框之间的位置关系对候选区域进行标注正负样本
跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标
偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别 -
使用卷积神经网络提取图片特征 C
-
使用卷积神经网络 关联图片特征C 对应候选区域的位置和类别进行预测 ,形成 特征图P
-
将网络预测值和标签值进行比较,就可以建立起损失函数
将每个预测框就看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值
3. 产生候选区域
3.1. 生成锚框
将原始图片划分成
m
×
n
m×n
m×n个区域,即 均分切块
如原始图片高度H=640, 宽度W=480,如果选择小块区域的尺寸为32×32
则m和n分别为:
m
=
H
/
32
=
20
,
n
=
W
/
32
=
15
m=H/32=20,n=W/32=15
m=H/32=20,n=W/32=15
将原始图像分成了20行15列小方块区域

这里为了跟程序中的编号对应,最上面的行号是第0行,最左边的列号是第0列

为了展示方便,左图中第十行第四列的小方块位置附近画出生成3个不同尺寸的锚框
右图每个区域附近都生成3个锚框
3.2. 生成预测框
锚框的位置都是固定好的,不可能刚好跟物体边界框重合
需要在锚框的基础上进行位置的微调以生成预测框
预测框相对于锚框会有不同的 中心位置和 大小
3.2.1. 预测框中心位置坐标
通过该方式生成预测框的中心坐标: b x = c x + σ ( t x ) , b y = c y + σ ( t y ) b_x=c_x+σ(t_x),b_y=c_y+σ(t_y) bx=cx+σ(tx),by=cy+σ(ty)
| 符号 | 含义 |
|---|---|
| b x , b y b_x,b_y bx,by | 预测框的中心坐标 |
| c x , c y c_x,c_y cx,cy | 小方块区域左上角的位置坐标 |
| σ σ σ | Sigmoid函数 |
| t x , t y t_x,t_y tx,ty | 预测框的中心坐标的微调系数 |
由于Sigmoid的函数值在0∼1之间: σ ( x ) = 1 1 + e x p ( − x ) σ(x)=\\frac11+exp(−x) σ(x)=1+exp(−x)1
因此由上面公式计算出来的预测框的中心点总是落在第十行第四列的小区域内部
3.2.2. 预测框大小
锚框的大小是预先设定好的,在模型中可以当作是超参数
通过该方式生成预测框的大小:
b
w
=
p
w
e
t
w
,
b
h
=
p
h
e
t
h
b_w=p_we^t_w,b_h=p_he^t_h
bw=pwetw,b