Seq2Seq使用神经网络进行序列到序列学习
Posted Sonhhxg_柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Seq2Seq使用神经网络进行序列到序列学习相关的知识,希望对你有一定的参考价值。
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本系列中,我们将使用PyTorch和torch文本构建一个机器学习模型,从一个序列到另一个序列。这将在德语到英语的翻译中完成,但这些模型可以应用于涉及从一个序列到另一个序列的任何问题,例如摘要,即从一个序列到同一语言的较短序列。
介绍
最常见的序列到序列 (seq2seq) 模型是编码器-解码器模型,它们通常使用递归神经网络 (RNN) 将源(输入)句子编码为单个向量。在本笔记本中,我们将此单个向量称为上下文向量。我们可以将上下文向量视为整个输入句子的抽象表示。然后,该向量由第二个RNN解码,该RNN通过一次生成一个单词来学习输出目标(输出)句子。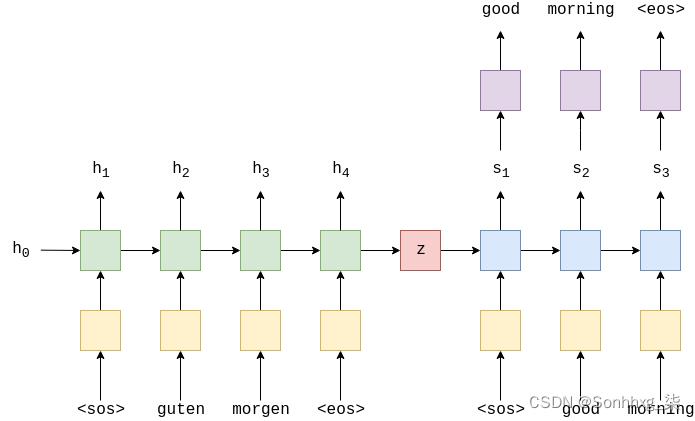
上图显示了一个示例翻译。输入/源句子“guten morgen”通过嵌入层(黄色),然后输入到编码器(绿色)。我们还将序列的开头 (<sos>) 和序列结尾 (<eos>) 标记分别附加到句子的开头和结尾。在每个时间步长处,编码器 RNN 的输入既是嵌入,e,当前单词,e(Xt),以及上一个时间步长的隐藏状态,ht-1,编码器 RNN 输出新的隐藏状态ht.到目前为止,我们可以将隐藏状态视为句子的向量表示。RNN 可以表示为e(Xt)和ht-1:
ht = EncoderRNN(e(xt),ht-1)
我们在这里通常使用术语RNN,它可以是任何循环架构,例如LSTM(长短期存储器)或GRU(门控循环单元)。这里我们有X = x1,x2,x3,....,xT,在x1 = <sos>,x2=guten,etc,隐含层状态为h0,
通常初始化为零或学习的参数。一旦最后一句话,xT,已通过嵌入层传递到 RNN 中,我们使用最终的隐藏状态hT,作为上下文向量,即hT = z这是整个源句子的向量表示。
现在我们有了上下文向量,我们可以开始解码它以获得输出/目标句子“good morning”。同样,我们将序列标记的开始和结束附加到目标句子。在每个时间步长处,解码器RNN(蓝色)的输入是嵌入,d,当前字数d(yt)以及上一个时间步长的隐藏状态,st-1,其中初始解码器隐藏状态,s0,是上下文向量,s0=z=hT,即解码器的初始隐藏状态是最终编码器的隐藏状态。因此,与编码器类似,我们可以将解码器表示为:
st = DecoderRNN(d(yt),st-1)
尽管输入/源嵌入层 e和输出/目标嵌入层 d在图中都以黄色显示,但它们是两个不同的嵌入层,具有自己的参数。
在解码器中,我们需要从隐藏状态转到实际单词,因此在每个时间步长中,我们使用st
预测(通过将其通过线性层,以紫色显示)我们认为序列中的下一个单词是什么,y^t.
y^t = f(st)
解码器中的单词总是一个接一个地生成,每个时间步长一个。我们总是使用<sos>解码器的第一个输入,y1,但对于后续输入,yt>1,我们有时会使用序列中的下一个单词,yt有时使用我们的解码器预测的单词,y^t-1.这被称为teacher forcing,在这里看到更多关于它的信息。
在训练/测试我们的模型时,我们总是知道目标句子中有多少单词,所以一旦我们达到那么多单词,我们就会停止生成单词。在推理过程中,通常会继续生成单词,直到模型输出<eos>token或生成一定数量的单词之后。
一旦我们有了预测的目标句子,Y^ = y^1,y^2,...,y^T,我们将其与实际目标句子进行比较,Y = y1,y2,...,yT,来计算我们的损失。然后,我们使用此损失来更新模型中的所有参数。
准备数据
我们将在PyTorch中对模型进行编码,并使用torch文本来帮助我们完成所需的所有预处理。我们还将使用 spaCy 来协助对数据进行标记化。
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time我们将为确定性结果设置随机种子。
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True接下来,我们将创建分词器。分词器用于将包含句子的字符串转换为构成该字符串的各个标记的列表,例如,“good morning!”变为["good", "morning", "!"]。从现在开始,我们将开始讨论句子是一系列标记,而不是说它们是一系列单词。有什么区别?好吧,“好”和“早晨”既是单词又是token,但是“!”是一个token,而不是一个单词。
spaCy具有每种语言的模型(德语的“de_core_news_sm”和英语的“en_core_web_sm”),需要加载,以便我们可以访问每个模型的分词器。
注意:必须首先在命令行上使用以下命令下载模型:
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm我们按如下方式加载模型:
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')接下来,我们创建分词器函数。这些可以传递给火炬文本,并将句子作为字符串接收,并将句子作为标记列表返回。
在我们正在实现的论文中,他们发现颠倒输入的顺序是有益的,他们认为输入的顺序“在数据中引入了许多短期依赖关系,使优化问题变得更加容易”。我们通过在德语句子转换为标记列表后反转它来复制它。
def tokenize_de(text):
"""
将字符串中的德语文本标记化为字符串(标记)列表并反转它
"""
return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):
"""
将字符串中的英语文本标记化为字符串(标记)列表
"""
return [tok.text for tok in spacy_en.tokenizer(text)]tensortext的字段处理应如何处理数据。这里详细介绍了所有可能的论点。
我们将每个标记化参数设置为正确的标记化函数,德语是 SRC(源)字段,英语是 TRG(目标)字段。该字段还通过init_token和eos_token参数追加“序列开始”和“序列结束”标记,并将所有单词转换为小写。
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)接下来,我们下载并加载训练、验证和测试数据。
我们将使用的数据集是 Multi30k 数据集。这是一个包含约 30,000 个并行英语、德语和法语句子的数据集,每个句子约 12 个单词。
exts 指定要用作源和目标的语言(源优先),字段指定要用于源和目标的字段。
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))我们可以仔细检查我们是否加载了正确数量的示例:
print(f"Number of training examples: len(train_data.examples)")
print(f"Number of validation examples: len(valid_data.examples)")
print(f"Number of testing examples: len(test_data.examples)")Number of training examples: 29000 Number of validation examples: 1014 Number of testing examples: 1000
我们还可以打印出一个示例,确保源句子反转:
print(vars(train_data.examples[0]))'src': ['.', 'büsche', 'vieler', 'nähe', 'der', 'in', 'freien', 'im', 'sind', 'männer', 'weiße', 'junge', 'zwei'], 'trg': ['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']
句点位于德语 (src) 句子的开头,因此看起来句子已被正确反转。
接下来,我们将为源语言和目标语言构建词汇表。词汇用于将每个唯一标记与索引(整数)相关联。源语言和目标语言的词汇表是不同的。
使用min_freq参数,我们只允许在词汇表中出现至少 2 次的标记。仅出现一次的token将转换为<unk>(未知)token。
重要的是要注意,我们的词汇表只能从训练集构建,而不是从验证/测试集构建。这可以防止“信息泄露”到我们的模型中,从而人为地夸大验证/测试分数。
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)print(f"Unique tokens in source (de) vocabulary: len(SRC.vocab)")
print(f"Unique tokens in target (en) vocabulary: len(TRG.vocab)")Unique tokens in source (de) vocabulary: 7853 Unique tokens in target (en) vocabulary: 5893
准备数据的最后一步是创建迭代器。可以对这些参数进行迭代,以返回一批数据,这些数据将具有 src 属性(包含一批数值化源句子的 PyTorch 张量)和 trg 属性(包含一批数值化目标句子的 PyTorch 张量)。数字化只是一种花哨的方式,说它们已经从一系列可读的标记转换为一系列相应的索引,使用词汇。
我们还需要定义一个火炬设备。这用于告诉火炬文本是否将张量放在GPU上。我们使用torch.cuda.is_available()函数,如果我们的计算机上检测到 GPU,该函数将返回 True。我们将此设备传递给迭代器。
当我们使用迭代器获得一批示例时,我们需要确保所有源句子都填充到相同的长度,与目标句子相同。幸运的是,火炬文本迭代器为我们处理这个问题!
我们使用 BucketIterator 而不是标准迭代器,因为它以这样一种方式创建批处理,从而最大限度地减少源句子和目标句子中的填充量。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)构建seq2seq模型
我们将分三部分构建模型。编码器、解码器和 seq2seq 模型封装编码器和解码器,并提供一种与每个编码器和解码器接口的方法。
编码器
首先是编码器,一个2层的LSTM。我们正在实现的论文使用4层LSTM,但为了训练时间,我们将其减少到2层。多层 RNN 的概念很容易从 2 层扩展到 4 层。
对于多层 RNN,X输入句子在嵌入到 RNN 的第一层(底部)和隐藏状态后,H = h1,h2,...,hT
,则此层的输出将用作上一层中 RNN 的输入。因此,用上标表示每个层,第一层中的隐藏状态由下式给出: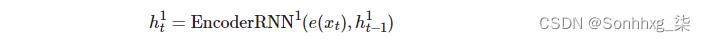
第二层中的隐藏状态由下式给出: 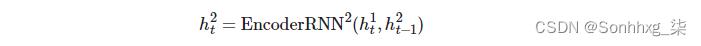
使用多层RNN还意味着我们还需要一个初始隐藏状态作为每层的输入,h0l,我们还将每层输出一个上下文向量,zl
在不详细介绍 LSTM 的情况下(请参阅此博客文章以了解有关它们的更多信息),我们需要知道的是,它们是一种 RNN,它不仅仅是在隐藏状态中并按时间步长返回新的隐藏状态,还接受并返回单元格状态,ct,每个时间步长。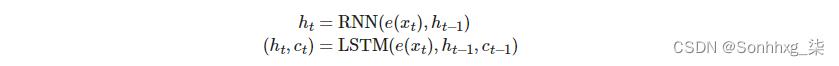
我们只能想到ct作为另一种类型的隐藏状态。似h0l,c0l
,
将初始化为所有零的张量。此外,我们的上下文向量现在既是最终的隐藏状态,也是最终的单元格状态,即zl = (hTl,cTl)
.将我们的多层方程扩展到 LSTM,我们得到:
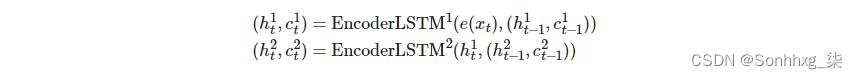
请注意,只有第一层的隐藏状态作为输入传递到第二层,而不是单元格状态。
因此,我们的编码器如下所示: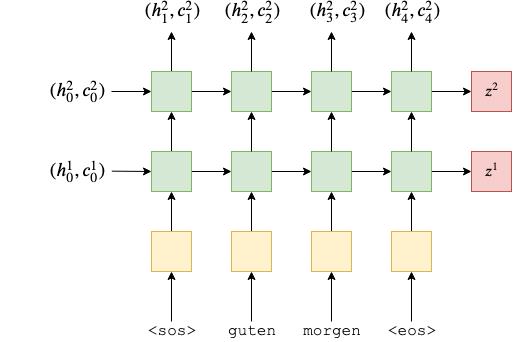
我们通过制作一个编码器模块在代码中创建它,这需要我们从torch.nn.Module继承并使用super().__init__()作为一些样板代码。编码器采用以下参数:
- input_dim是将输入到编码器的单热矢量的大小/维度。这等于输入(源)词汇大小。
- emb_dim是嵌入层的维度。此层将单热向量转换为具有emb_dim维度的密集向量。
- hid_dim是隐藏状态和细胞状态的维度。
- n_layers是 RNN 中的层数。
- dropout是要使用的dropout量。这是一个正则化参数,用于防止过度拟合。有关dropout的更多详细信息,请查看此内容。
在这些教程中,我们不会详细讨论嵌入层。我们需要知道的是,在将单词(从技术上讲,单词的索引)传递到RNN之前有一个步骤,其中单词被转换为向量。要阅读有关词嵌入的更多信息,请查看以下文章:1,2,3,4。
嵌入层是使用 nn 创建的。nn.Embedding,具有 nn 的 LSTM。 nn.Dropout和带有 nn 的压差层。dropout。有关这些内容的更多信息,请查看 PyTorch 文档。
需要注意的一点是,LSTM的压差参数是在多层RNN的层之间应用多少压差,即在层输出的隐藏状态l和用于层输入的相同隐藏状态之间。l+1
在 forward 方法中,我们传入源句子 ,X该句子使用嵌入层转换为密集向量,然后应用 embedding。然后,嵌入被传递到RNN中。当我们将整个序列传递给RNN时,它将自动为我们对整个序列进行隐藏状态的循环计算!请注意,我们不会将初始隐藏状态或单元格状态传递给 RNN。这是因为,如文档中所述,如果没有隐藏/单元格状态传递给RNN,它将自动创建一个初始隐藏/单元格状态作为所有零的张量。
RNN 返回:输出(每个时间步的顶层隐藏状态)、隐藏(每层的最终隐藏状态、hT,堆叠在彼此之上)和单元格(每层的最终单元格状态,cT,堆叠在彼此之上)。
由于我们只需要最终的隐藏和单元格状态(以使我们的上下文向量),因此转发仅返回隐藏和单元格。
每个张量的大小在代码中作为注释保留。在此实现n_directions将始终为 1,但请注意,双向 RNN(在教程 3 中介绍)的n_directions为 2。
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell解码器
接下来,我们将构建我们的解码器,它也将是一个2层(论文中有4层)LSTM。
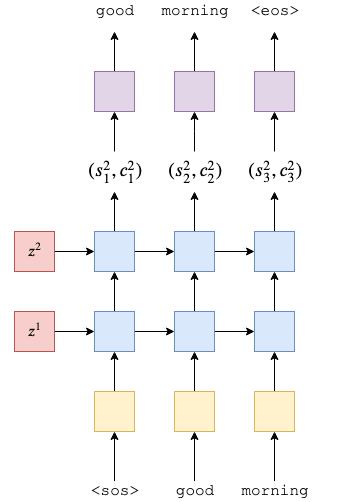
解码器类执行单个解码步骤,即它每个时间步长输出单个令牌。第一层将接收来自上一个时间步长的隐藏和单元格状态,(slt-1,clt-1),并使用当前嵌入的令牌通过 LSTM 向其馈送,yt,以产生新的隐藏和单元状态,(slt,clt).后续层将使用下面层中的隐藏状态,sl-1t.,以及其层中先前的隐藏状态和单元格状态,(slt-1,clt-1)这提供了与编码器中非常相似的方程式。
请记住,解码器的初始隐藏和单元格状态是我们的上下文向量,它们是来自同一层的编码器的最终隐藏和单元格状态,即
.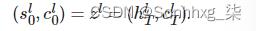
然后,我们从RNN的顶层传递隐藏状态,stT,通过线性层,f 来预测目标(输出)序列中的下一个token应该是什么,y^t+1
.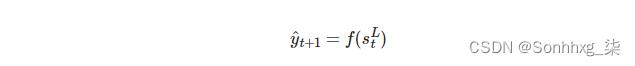
参数和初始化类似于 Encoder 类,只是我们现在有一个output_dim它是输出/目标的词汇表大小。还添加了线性层,用于从顶层隐藏状态进行预测。
在 forward 方法中,我们接受一批输入令牌、以前的隐藏状态和以前的单元格状态。由于我们一次只解码一个令牌,因此输入令牌的序列长度将始终为 1。我们取消挤压输入标记以添加句子长度维度 1。然后,与编码器类似,我们穿过嵌入层并应用丢弃。然后,这批嵌入的令牌被传递到具有先前隐藏状态和单元格状态的 RNN 中。这将生成输出(来自RNN顶层的隐藏状态),新的隐藏状态(每层一个,彼此堆叠)和一个新的单元状态(每层一个,堆叠在一起)。然后,我们将输出(在摆脱句子长度维度之后)通过线性层来接收我们的预测。然后,我们返回预测、新的隐藏状态和新的单元格状态。.
注意:由于我们的序列长度始终为1,因此可以使用 nn.LSTMCell, ,而不是 nn.LSTM,因为它旨在处理一批不一定在序列中的输入。嗯。低铁矿细胞只是一个单一的细胞和nn。LSTM是围绕潜在多个细胞的包装器。使用 nn.在这种情况下,LSTMCell意味着我们不必unsqueeze添加一个假序列长度维度,但我们需要一个 nn。LSTM细胞每层在解码器中并确保每一个nn。LSTMCell 从编码器接收正确的初始隐藏状态。所有这些都使代码不那么简洁 - 因此决定坚持使用常规nn。新浪网.
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#seq len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cellseq2seq
对于实现的最后一部分,我们将实现 seq2seq 模型。这将处理:
- 接收输入/源句子
- 使用编码器生成上下文向量
- 使用解码器生成预测的输出/目标句子
我们的完整模型将如下所示:

Seq2Seq 模型采用编码器、解码器和设备(如果存在,用于在 GPU 上放置张量)。
对于此实现,我们必须确保编码器和解码器中的层数和隐藏(和单元)尺寸相等。情况并非总是如此,在序列到序列模型中,我们不一定需要相同数量的层数或相同的隐藏维度大小。但是,如果我们做了类似的事情具有不同数量的层,那么我们需要决定如何处理它。例如,如果我们的编码器有2层,而我们的解码器只有1层,这是如何处理的?我们是否对解码器输出的两个上下文向量进行平均?我们是否通过线性层传递两者?我们是否只使用最高层的上下文向量?等。
我们的前向方法采用源句子,目标句子和教师强迫比率。在训练我们的模型时使用教师强迫比率。解码时,在每个时间步长,我们将从先前解码的令牌中预测目标序列中的下一个令牌,y^t+1 = f(stL).当概率等于示教强制比(teacher_forcing_ratio)时,我们将在下一个时间步长中使用序列中实际的下一个真实值作为解码器的输入。但是,在概率为 1 - teacher_forcing_ratio的情况下,我们将使用模型预测的令牌作为模型的下一个输入,即使它与序列中的实际下一个令牌不匹配。
我们在正向方法中做的第一件事是创建一个输出张量,它将存储我们所有的预测,Y^
.然后,我们将输入/源句子 src 馈送到编码器中,并接收最终的隐藏状态和单元格状态。
解码器的第一个输入是序列 (<sos>) 标记的开始。由于我们的 trg 张量已经<sos>附加了标记(一直追溯到我们在 TRG 字段中定义init_token),我们得到
通过切入它。我们知道目标句子应该有多长(max_len),所以我们循环了很多次。输入解码器的最后一个<eos>令牌是令牌之前的令牌 - <eos> 令牌永远不会输入到解码器中。
在循环的每次迭代中,我们:
- 传递输入、以前的隐藏和以前的单元格状态 (yt,st-1,ct-1) 进入解码器
- 接收预测、下一个隐藏状态和下一个单元格状态 (y^t+1,st,ct) 来自解码器
- 放置我们的预测,y^t+1/output 在我们的预测张量中,Y^/outputs
- 决定我们是否要“teacher force”
- 如果我们这样做,下一个input是序列中的下一个真实标记,yt+1/tg[t]
-
如果我们不这样做,则下一个input是序列中预测的下一个令牌,y^t+1/top1,我们通过在输出张量上做一个 argmax 得到
一旦我们做出了所有的预测,我们就会返回充满预测的张量,Y^/outputs。注意:我们的解码器循环从1开始,而不是0.这意味着我们的output张量的第0个元素保持全部为零。因此,我们的 trg 和outputs如下所示:
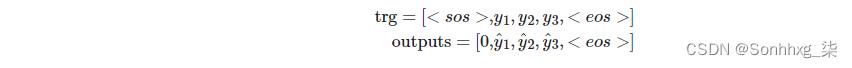
稍后,当我们计算损失时,我们切断每个张量的第一个元素得到:
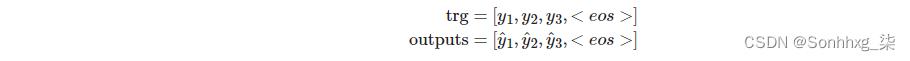
class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, device): super().__init__() self.encoder = encoder self.decoder = decoder self.device = device assert encoder.hid_dim == decoder.hid_dim, \\ "Hidden dimensions of encoder and decoder must be equal!" assert encoder.n_layers == decoder.n_layers, \\ "Encoder and decoder must have equal number of layers!" def forward(self, src, trg, teacher_forcing_ratio = 0.5): #src = [src len, batch size] #trg = [trg len, batch size] #teacher_forcing_ratio是使用eacher forcing的概率 #例如,如果teacher_forcing_ratio为 0.75,我们在 75% 的时间内使用地面实况输入 batch_size = trg.shape[1] trg_len = trg.shape[0] trg_vocab_size = self.decoder.output_dim #tensor 存储解码器输出 outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device) #编码器的最后隐藏状态用作解码器的初始隐藏状态 hidden, cell = self.encoder(src) #first input to the decoder is the <sos> tokens input = trg[0,:] for t in range(1, trg_len): #insert input token embedding, previous hidden and previous cell states #receive output tensor (predictions) and new hidden and cell states output, hidden, cell = self.decoder(input, hidden, cell) #place predictions in a tensor holding predictions for each token outputs[t] = output #decide if we are going to use teacher forcing or not teacher_force = random.random() < teacher_forcing_ratio #get the highest predicted token from our predictions top1 = output.argmax(1) #if teacher forcing, use actual next token as next input #if not, use predicted token input = trg[t] if teacher_force else top1 return outputs
Training the Seq2Seq Model
现在我们已经实现了我们的模型,我们可以开始训练它了。
首先,我们将初始化模型。如前所述,输入和输出维度由词汇表的大小定义。编码器和解码器的嵌入角和间隔可以不同,但层数和隐藏/单元格状态的大小必须相同。
然后,我们定义编码器,解码器,然后定义我们的Seq2Seq模型,并将其放置在设备上。
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)接下来是初始化模型的权重。在论文中,他们声明他们初始化所有权重从-0.08和+0.08之间的均匀分布,即。u(-0.08,0.08)
我们在PyTorch中通过创建一个应用于模型的函数来初始化权重。使用 apply 时,将在模型中的每个模块和子模块上调用init_weights函数。对于每个模块,我们遍历所有参数,并从具有nn.init.uniform_的均匀分布中对它们进行采样。
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(7853, 256)
(rnn): LSTM(256, 512, num_layers=2, dropout=0.5)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Decoder(
(embedding): Embedding(5893, 256)
(rnn): LSTM(256, 512, num_layers=2, dropout=0.5)
(fc_out): Linear(in_features=512, out_features=5893, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
)
我们还定义了一个函数,用于计算模型中可训练参数的数量。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has count_parameters(model):, trainable parameters')The model has 13,898,501 trainable parameters
我们定义优化器,用于更新训练循环中的参数。查看这篇文章,了解有关不同优化器的信息。在这里,我们将使用Adam。
optimizer = optim.Adam(model.parameters())接下来,我们定义损失函数。 CrossEntropyLoss计算对数软最大值以及预测的负对数可能性。
我们的损失函数计算每个令牌的平均损失,但是通过将令牌的索引<pad>作为ignore_index参数传递,只要目标令牌是填充令牌,我们就会忽略损失。
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)接下来,我们将定义训练循环。
首先,我们将模型设置为“训练模式”,使用 model.train()。这将打开丢弃(和批处理规范化,我们没有使用),然后循环访问我们的数据迭代器。
如前所述,我们的解码器循环从 1 开始,而不是 0。这意味着输出张量的第 0 个元素保持所有零。因此,我们的 trg 和输出如下所示: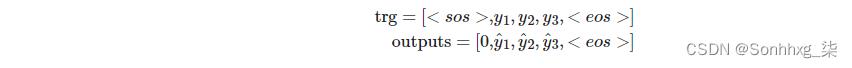
在这里,当我们计算损失时,我们切断每个张量的第一个元素得到: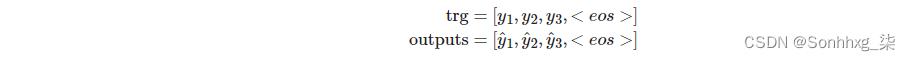
每次迭代时:
- 从批处理中获取源句子和目标句子,X以及Y
- 从最后一批计算的梯度归零
- 将源和目标馈送到模型中获取输出,Y^
由于损失函数仅适用于具有 1d 目标的 2d 输入,因此我们需要使用 .view 将其中的每一个扁平化
- 计算有损失的loss.backward()
- 裁剪渐变以防止它们爆炸(RNN 中的常见问题)
- 通过执行优化器步骤来更新模型的参数
- 将损失值与运行总计相加
最后,我们返回所有批次的平均损失。
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)我们的评估循环类似于我们的训练循环,但是由于我们不更新任何参数,因此不需要传递优化器或剪辑值。
我们必须记住使用 model.eval() 将模型设置为求值模式。这将关闭丢弃(以及批量规范化,如果使用)。
我们使用 with torch.no_grad() 块来确保块内不计算任何梯度。这减少了内存消耗并加快了速度。
迭代循环是相似的(没有参数更新),但是我们必须确保关闭教师强制进行评估。这将导致模型仅使用其自己的预测在句子中进行进一步的预测,这反映了它在部署中的使用方式。
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)接下来,我们将创建一个函数,用于告诉我们一个 epoch 需要多长时间。
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs我们终于可以开始训练我们的模型了!
在每个 epoch,我们将检查我们的模型是否实现了迄今为止的最佳验证损失。如果有,我们将更新最佳验证损失并保存模型的参数(在PyTorch中称为state_dict)。然后,当我们来测试我们的模型时,我们将使用保存的参数来实现最佳的验证损失。
我们将打印出每个时代的损失和困惑。看到困惑的变化比损失的变化更容易,因为数字要大得多。
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut1-model.pt')
print(f'Epoch: epoch+1:02 | Time: epoch_minsm epoch_secss')
print(f'\\tTrain Loss: train_loss:.3f | Train PPL: math.exp(train_loss):7.3f')
print(f'\\t Val. Loss: valid_loss:.3f | Val. PPL: math.exp(valid_loss):7.3f')Epoch: 01 | Time: 0m 26s Train Loss: 5.052 | Train PPL: 156.386 Val. Loss: 4.916 | Val. PPL: 136.446 Epoch: 02 | Time: 0m 26s Train Loss: 4.483 | Train PPL: 88.521 Val. Loss: 4.789 | Val. PPL: 120.154 Epoch: 03 | Time: 0m 25s Train Loss: 4.195 | Train PPL: 66.363 Val. Loss: 4.552 | Val. PPL: 94.854 Epoch: 04 | Time: 0m 25s Train Loss: 3.963 | Train PPL: 52.625 Val. Loss: 4.485 | Val. PPL: 88.672 Epoch: 05 | Time: 0m 25s Train Loss: 3.783 | Train PPL: 43.955 Val. Loss: 4.375 | Val. PPL: 79.466 Epoch: 06 | Time: 0m 25s Train Loss: 3.636 | Train PPL: 37.957 Val. Loss: 4.234 | Val. PPL: 69.011 Epoch: 07 | Time: 0m 26s Train Loss: 3.506 | Train PPL: 33.329 Val. Loss: 4.077 | Val. PPL: 58.948 Epoch: 08 | Time: 0m 27s Train Loss: 3.370 | Train PPL: 29.090 Val. Loss: 4.018 | Val. PPL: 55.581 Epoch: 09 | Time: 0m 26s Train Loss: 3.241 | Train PPL: 25.569 Val. Loss: 3.934 | Val. PPL: 51.113 Epoch: 10 | Time: 0m 26s Train Loss: 3.157 | Train PPL: 23.492 Val. Loss: 3.927 | Val. PPL: 50.743
我们将加载为模型提供最佳验证损失的参数(state_dict),并在测试集上运行模型。
model.load_state_dict(torch.load('tut1-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: test_loss:.3f | Test PPL: math.exp(test_loss):7.3f |')| Test Loss: 3.951 | Test PPL: 52.001 |
以上是关于Seq2Seq使用神经网络进行序列到序列学习的主要内容,如果未能解决你的问题,请参考以下文章