视觉SLAMSO-SLAM: Semantic Object SLAM With Scale Proportional and Symmetrical Texture Constraints
Posted 振华OPPO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视觉SLAMSO-SLAM: Semantic Object SLAM With Scale Proportional and Symmetrical Texture Constraints相关的知识,希望对你有一定的参考价值。
Citations: Z. Liao, Y. Hu, J. Zhang, et al. SO-SLAM: Semantic Object SLAM With Scale Proportional and Symmetrical Texture Constraints[J].in IEEE Robotics and Automation Letters.2022,7(2):4008-4015.
Keywords: Simultaneous localization and mapping,Semantics,Robots,Cameras,Ellipsoids,Solid modeling,Object detection
| letter提出了一个单目对象SLAM系统,系统使用二次曲线对物体进行建模,并构建一个物体级地图表示环境。介绍了三种空间结构约束,包括比例约束、对称纹理约束和支持平面约束。基于这些约束,本文又提出了两个新的模块——单帧初始化和定向精细优化,显著降低了对象SLAM系统对观测值数量和变化的依赖。 但是只讨论了水平放置在支持平面上的物体,纹理约束采用的是对称描述符,不能适用在不规则物体场景。 |
|---|
论文目录
摘要
对象SLAM将对象的概念引入同步定位和建图(SLAM),并帮助理解移动机器人和对象级交互式应用程序的室内场景。最先进的对象SLAM系统面临着诸如部分观测,遮挡,不可观察的问题等挑战,限制了建图的准确性和鲁棒性。 本文提出了一种新的单目语义对象SLAM(SO-SLAM)系统,该系统解决了对象空间约束的引入。我们探索了三种具有代表性的空间约束,包括比例约束、对称纹理约束和平面支撑约束。基于这些语义约束,我们提出了两种新方法——更健壮的对象初始化方法和定向精细优化方法。我们在公共数据集和作者记录的移动机器人数据集上验证了该算法的性能,并在地图效果上取得了显著的提升。我们将在此处发布代码。
一、介绍
几十年来,机器人研究人员一直在探索如何让机器人在开放世界中自主感知、学习和与环境交互。想象一下,一个长期服务机器人在室内人机共存的场景中工作——家庭、博物馆、办公室等。为了响应人类指令并执行任务,它需要强大的映射和定位能力,从语义上理解环境,并检测环境变化以进行终身地图维护。1
然而,传统的SLAM算法使用点、线和平面特征来构建地图,缺乏语义信息[1]。人工设计的特征描述符难以适应较大的视角变化,并且容易受到光线和传感器噪声的干扰[2]。传统的SLAM算法大多基于环境的静态假设。基于点、线和平面的地图很难根据环境的变化进行更新。因此,传统的SLAM算法远远不能满足室内服务机器人的需求。
我们认为,作为室内环境的重要组成部分,物体在代表室内环境方面具有以下潜在优势。首先,物体的空间信息可以通过更高级的抽象特征来表达,例如中心,方向和占用空间。它对起源观测数据的变化不敏感,对强扰动直观上更稳健。其次,可以将物体和结构(如墙)之间的空间关系作为辅助约束,以提高鲁棒性和准确性,这有助于机器人从几何层面到语义层面的场景理解。
最近,对象SLAM系统[3]–[7]引入了对象作为地标,并紧凑地对环境进行了建模。其中,基于二次曲面的对象SLAM系统[7],[9]-[15]使用二次曲线来紧凑地模拟对象的中心,方向和占用的空间。与RGB-D对象SLAM系统[3],[4]相比,单目相机更方便,成本更低,重量轻,这使得该算法可用于更广泛的应用,例如手机和无人机。
这封信的动机是解决单目物体SLAM系统的以下两个挑战和局限性。首先,单目相机包含较少的信息来约束物体并处理部分观察、遮挡等,使得单目物体SLAM在实际应用中脆弱[6],[7]。特别是在移动机器人的典型向前运动轨迹中,与理想的环顾轨迹不同,机器人运动轨迹难以产生角度变化较大的多帧观测,引发了不可观测性的问题[10]。其次,当前对象SLAM [7],[10]主要约束对象的占用空间,因此方向相对随机且没有意义。我们明确地用对称性约束对象的方向,以便我们的对象级地图使机器人能够进行语义室内导航,例如,移动到沙发的侧面或前面。
在这封信中,我们提出了一种新的单目语义对象SLAM(SO-SLAM)系统,如图1所示。我们继承了对象的语义信息,引入了<>种具有代表性的对象空间约束,包括比例约束、对称纹理约束和平面支撑约束。我们将在SLAM系统中推导出它们的数学表示和约束模型,以参与前端初始化和后端优化。总之,我们将做出以下贡献:
-
提出一种单目物体SLAM算法,该算法完全耦合了室内环境的三个空间结构约束。
-
提出两种基于空间约束的新方法:单帧对象初始化方法和对象定向优化方法。
-
在两个公共数据集和一个作者记录的真实移动机器人数据集上证明所提算法的有效性。
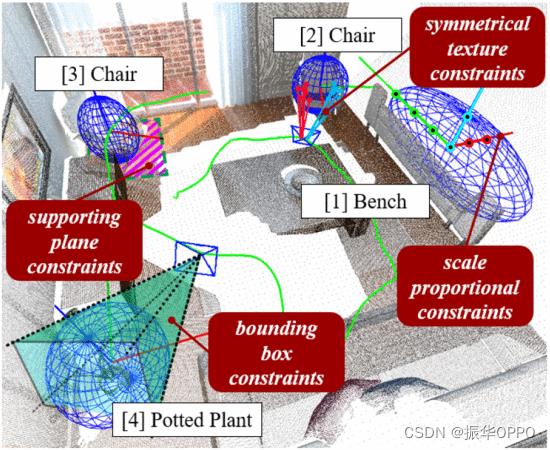
图1. 对象 SLAM。它可以构建包含中心、方向和占用空间等物体的地图,帮助机器人理解人类面向对象的指令。
二、相关工作
A. 对象SLAM
对象 SLAM 或对象级 SLAM 侧重于对象特征的构建,包括对象的位置、方向、占用空间以及与地图中空间结构的关系,如图 1 所示。对象 SLAM 的早期探索可以追溯到 SLAM++ [3]。离线建立对象CAD模型数据库,然后利用RGB-D相机的深度信息与实际操作中的对象数据库进行匹配。2019年,马丁等. [4] 提出了MaskFusion,它使用神经网络来检测物体,不需要数据库。它实时检测和跟踪动态对象。然而,受其密集对象模型的限制,上述系统需要大量的计算硬件来实现实时和高速操作。2019年,Yang等人提出了CubeSLAM [5],它使用长方体对环境中的物体进行建模。自2017年以来,研究人员[6],[25]已经探索了使用二次模型来表示运动结构领域中的物体。2019 年,Nicholson 等人提出了 QuadricSLAM [7],这是第一次用二次曲线构建对象 SLAM 系统。
与特征点相比,长方体和二次曲面不仅可以模拟位置,还可以模拟方向和占用空间,这对于机器人导航来说已经足够了。长方体是人类定义的模型,而二次曲线具有紧凑的二次数学表示和完整的射影几何[8]。最近,二次曲线模型越来越受到研究人员的关注[9]-[15],甚至超二次模型[17]也在探索中。
B. 对象 SLAM 中的语义先验
为了使系统更加健壮,研究人员进一步探索了定向的含义。在[12]中,引入了重力和支撑平面,定义了“顶部”侧。奥克等人。 [10]提出了纹理平面,它基本上定义了“正面”。此外,深度学习方法也被用来帮助估计椭球体[13]。作者探索了RGB-D相机在二次曲面中的引入[14],并尝试了RGB-D数据下基于对称性的物体方向估计[15]。这封信将进一步探讨基于单眼相机的算法。
综上所述,前面的信件表明,基于二次模型的对象SLAM系统被越来越多的研究人员所接受。然而,仍然有很大的研究空间,以使系统在现实世界中更加健壮和准确。
三、单目对象SLAM框架
系统的前端输入包括单目图像和测程数据。对象检测算法(例如,YOLO [16])从RGB图像中提取边界框。椭球体Q具有 9 个自由度,可以使用 SVD 方法估计,该方法至少需要 3 帧观测值,并具有足够的视图多样性 [7]。正如相关工作中提到的,这种方法不仅脆弱,而且缺乏定向的准确性。在后端,我们将对象SLAM问题建模为姿势图,包括由对象和相机姿势组成的节点,以及由约束组成的边缘。对象 SLAM 公式可以表示为非线性优化问题:
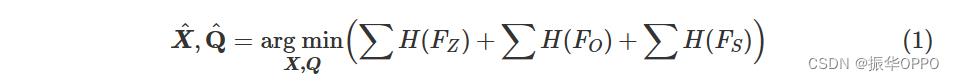
这里X是相机姿势,Q是地图中的对象。Fz是相机-物体观察约束,Fo是测程约束,两者在 [7] 中都有详细介绍。本文强调了新添加的Fs,由平面支撑约束组成f苏普、比例比例约束fS SC和对称纹理约束fsym,将在以下部分中介绍。H(⋅)是健壮的内核,使系统对异常值更加健壮,我们在实验中使用Huber内核。
四、使用语义先验进行单帧初始化
类似人类的感知对于服务机器人理解对象并与之交互是必要的。 我们遵循人类的认知习惯来建立对象坐标。我们认为人造物体的“顶部”通常与物体的支撑侧相反,而“正面”通常是对称的方向,例如汽车和椅子。前者定义Z轴的方向,后者定义X轴的方向,因此物体的三个轴是完全固定的。之后,我们可以利用更多的约束,例如每个对象的支持关系和比例。如图2所示,我们提出了一种只需要一帧的9自由度对象初始化方法,克服了传统SVD方法难以满足的要求。
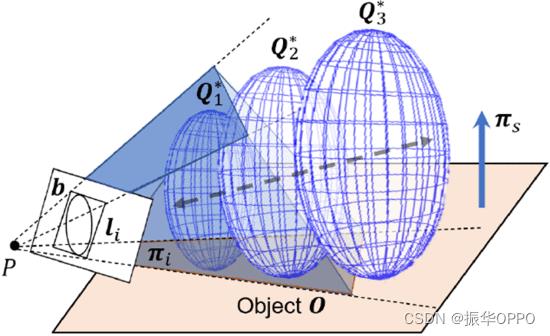
图2. 单帧二次曲线启动。来自目标检测边界框背投影的切平面和目标支撑平面将共同约束椭球体。沿观测方向的深度不确定性将进一步受到尺度约束的约束。
A. 对象检测约束
如图 2 所示,一个对象O放置在其支撑平面上πs在一帧中观察到。图像中由目标检测算法生成的对象的边界框为b,通常仅从一次观察中不知道物体的深度和规模。
B. 平面支撑约束
在正常的室内环境中,为了克服重力,物体必须与空间结构形成几何关系。例如,桌上的杯子,天花板下的灯和墙上的画。本文介绍了最常见的支撑关系,当结构平面位于物体下方时。悬架、精益和其他关系可以用类似的方式推导出来。
C. 语义尺度比例约束
同一类别中室内人造物体的规模具有一定的分布,这也是物体语义的几何反映。已经有一些研究讨论了如何将对象缩放先验约束应用于对象映射。例如,Ok等人。[10]假设汽车的尺寸是已知的。但是,它的灵活性有限,无法适应具有相同标签的特定实例(例如,真车和小型玩具车)的规模模糊性。本文提出了一种新的柔性对象尺度先验 - 尺度比例约束(SPC),它约束对象的比例尺度而不是其特定尺度。
对于具有不同语义标签的对象,可以定义一个常见对象的缩放比例表,在实际应用中可以通过查询表得到比例。在实际使用中,可以通过平均常见对象类型的比例来获得该表。
D. 解决单帧初始化问题
由于约束形式多样,很难直接获得解析解。我们基于Levenberg-Marquardt算法[18]构造了一个非线性优化器,并迭代求解最优值。目标函数定义为:
包括对象检测约束fb box、平面支撑约束f苏普和比例约束fSSC.
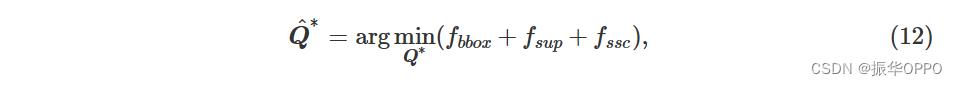
五、通过纹理对称进行方向优化
A. 物体对称性的数学描述
我们试图通过对称性进一步限制物体的方向,这在人造物体中很常见。本章的以下部分仅重点介绍对称对象。 在几何学上,人造物体的前部通常被认为是其对称平面的方向。我们认为它对应于物体坐标系的X轴方向,如图3(a)所示。
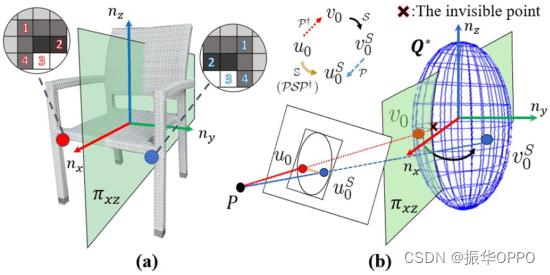
图3.(a) 围绕平面的两个对象点之间的对称关系。(b) 求解图像中对称像素的过程。
物体的对称性在数学上表现为以下事实:对于任何一点v0∈V在一个对象上,一个点vS0∈V总能发现它的对称平面是对称的πxz.由于假设对象是椭球体,对称平面可以用矩阵中的元素表示Q.关于平面的两点之间的对称关系具有明确的线性表示[26],表示为vS0=S(v0,Q).考虑到具有多个对称平面的物体,例如盒子和球,我们在对象初始化时发现的第一个对称面的方向上均匀建立正X轴方向。
B.对称描述符的构造
描述符β(u)需要反映某些特征u这就是对称投影不变性。我们做了不同的尝试,并在第六节中进行了比较。
最初步的选择是像素的灰度值βGRAY(u),它及其变体广泛用于直接方法 SLAM,但在实际情况中不够健壮。然后我们尝试了 BRIEF 描述符βBR我EF(u),可以反映附近的纹理信息。为了保证对称不变性,纹理的采样顺序接近u0及其对称点uS0应该彼此对称,如图3(a)所示。
然而,在优化过程(16)中使用βBR我EF(u),每个采样点u我固定,对称点uS我=S(u我,Q)将随着优化迭代而变化Q,因此uS我| i=1,2…n需要在每个迭代步骤中重新采样和重新编码,这严重减慢了算法的速度。然后,我们试图找到一个更轻量级的描述符来满足SLAM的实时要求,这促使我们考虑像素的距离变换值。
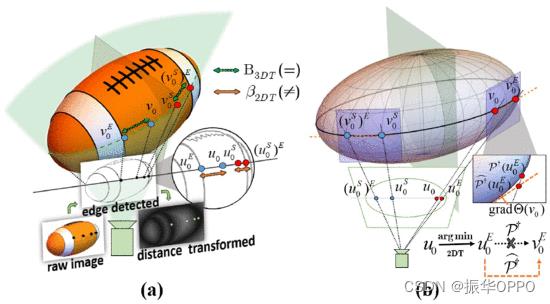
图4.(a) 投影变形后对称点的边缘距离不再相等。(b) 边缘点缩小映射的线性化。
但与图像不同的是,计算B3DT(v0)在 3D 空间中需要遍历每个边缘点v∈Ve在每次迭代中找到最接近的,这使得计算成本再次无法接受。我们的解决方案是结合两者的优势β2DT(⋅)和B3DT(⋅),并提出了一个改进的DT描述符。
C. 进一步加快优化进程
使用改进的 DT 描述符β3DT(⋅),在每次迭代中,采样点映射v=P†(u)计算准确,边缘点映射vE≈P†ˆ(uE)近似计算,这进一步加快了优化过程。
D. 采样点战略
我们已经详细描述了构建描述符的过程以及如何加速优化过程,只留下如何获得采样点uI.由于剩余o||vE0−v0||在(23)中,线性化近似仅在以下情况下有效||vE0−v0||≈0.因此,我们使用两种点采样策略:
一种是对角点进行采样,可以认为是更严格的边缘点,并且可以保证||vE0−v0||≈0.但也因为距离近,理论上会有β3DT(u我)≡0,这可能会导致接近最佳值的梯度消失问题,如图5(a)所示。另一种是统一采样边界框中的点。如图5(b)所示,梯度问题得到了显著改善,但是||vE0−v0||≈0不太满意。我们发现,将角点与几个均匀点一起使用可以在我们的实验中达到最佳效果。
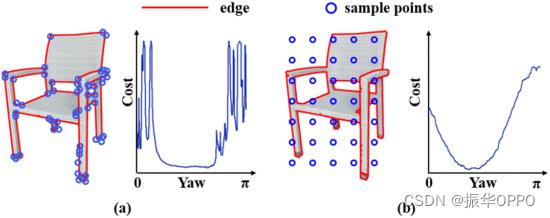
图5.(a) 抽样边缘点(左)及其成本函数(右)。(b) 统一抽样(左)及其损失函数(右)。
六、实验
A. 背景
为了充分验证本文提出的单帧初始化、纹理方向优化和完整的系统性能,我们在公共数据集和作者记录的真实机器人数据集上进行了实验。TUM RGB-D [19] 和 ICL-NUIM [20] 数据集广泛用于 SLAM,涵盖房间级和桌面级环境。为了更好地反映移动机器人的有效性,我们在Turtlebot3上进行了实验,该Turtlebot14带有Kinect相机,可在类似家庭的环境中运行,如[3]中所述。我们每拍摄五张图像,使用 YOLOv<> 执行对象检测,以获得边界框。
我们使用指标 IoU 和 Rot(deg) 来全面评估映射效果。IoU评估其估计对象和地面真实对象外接立方体之间的交集。对于具有对称性的物体,Rot(deg) 评估将估计物体的三个旋转轴与真实对象的任何轴对齐到直线所需的最小旋转角度。对于轨迹,上述指标是所有对象评估结果的平均值。尽管我们的方法只能用一个观察来初始化,但SVD和QuadricSLAM至少需要三个观测值。为了使实验具有可比性,我们考虑了至少具有三个观察值的对象,并过滤了那些部分边界框(靠近图像边缘小于30像素的边界框),以便所有对象都可以成功初始化。
由于平面提取不是我们的重点,在实验中,我们对世界坐标系中的支撑平面进行了注释,然后将其转换为每帧的局部坐标,得到了真实平面。通过这种方式,我们可以知道我们提出的方法的精度极限。在实际场景中,支持平面可以从SLAM [2]生成的点云中提取,也可以直接通过平面SLAM系统[21]提取。对于轮式移动机器人,在考虑地面上的物体时,可以在启动前校准相机与地面相关的外部参数后获得地平面参数。
B. 单帧对象初始化
我们将结果与最先进的算法 QuadricSLAM [7] 的初始化方法 SVD 和 CubeSLAM [5] 的初始化方法进行了比较。SVD 方法至少需要三帧观测值。我们将对象的所有观察结果放在一起,以便在实验中进行SVD初始化。像我们一样,CubeSLAM 引入了支撑平面来约束对象的方向。我们将CubeSLAM信函中给出的室内数据集的实验结果进行比较。我们以估计对象和真实对象之间的 IoU 作为基准,并对轨迹中的所有对象求平均值。
表I和图6显示了结果。SVD方法不仅需要更多的观测值,而且精度也较低。特别是在机器人轨迹中,移动机器人的向前运动很难在观测之间产生足够的角度差,导致IoU仅为0.5%。与SVD方法相比,CubeSLAM的初始化只需要一次观测,就能获得更好的结果。CubeSLAM 需要提取线特征来计算消失点,这要求对象表面具有明显的直线。我们不仅需要一次观察,而且对物体的线特征也没有要求。对纹理类型有更好的适应性。即使使用 1:1:1 比例比例约束(参见 Init1-1),我们的平均 IoU 也达到了 16.3%。使用语义对象语义先验(参见 InitP),它上升到 21.8%,比 SVD 显着增加了 13%。在ICL room15上,CubeSLAM公布的数据也增加了4.2%。Fr3_cabinet仅包含一个长方体对象,CubeSLAM 显示最佳结果。
表一 单帧对象初始化 IoU & 方向
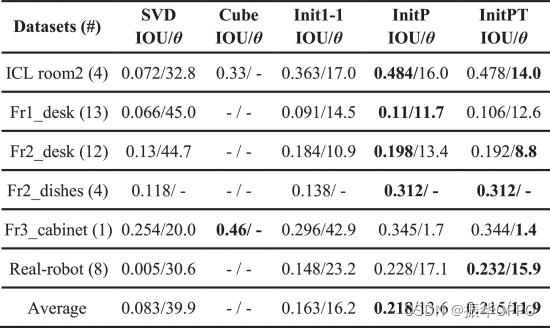
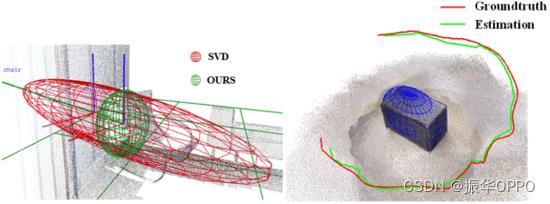
图6. 对象初始化和轨迹估计的示例。
C. 基于纹理对称性的取向估计
为了验证这封信中提出的改进DT描述符表示对象对称性的有效性,我们分析了与灰度,BRIEF和DT描述符相比的成本,如图7所示。垂直线标记真实值 (θ) 当前帧中对象的偏航角。改进型DT描述符在真实值附近具有明显的全局最优值,而其他描述符具有多个局部最优值。随着对象方向的变化,其误差变化更平滑、更显著。因此,在优化过程中有更好的局部梯度来约束。虽然我们演示了从−90到90度的所有结果,但在实际的SLAM系统中,我们只使用±30度范围以避免过多的角度失真。
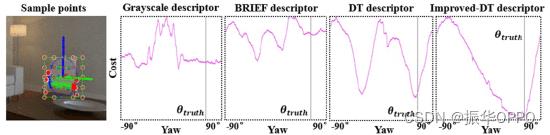
图7. 不同描述符的对称成本函数。
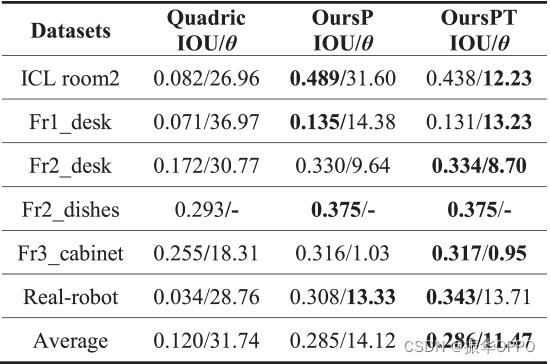
接下来,我们使用改进的DT描述符来估计对象的方向,如图8所示。表 I 和 II 分别显示了单帧初始化(参见 InitPT)和多帧优化(参见 OursPT)后的对象面向错误。我们只考虑每个对象第一次观察的纹理约束,以避免约束冲突。给出了SVD初始化和二次SLAM的定向结果作为参考。虽然SVD初始化和QuadricSLAM可以求解一个完整的椭球体,但它们并没有明确约束物体的方向,因此平均方向误差相对较大,分别达到39.9度和31.7度。在引入对象支持约束和默认比例(Init 1-1)、实比例先验(InitP)和纹理(InitPT)后,方向误差得到改善,最终达到11.9度,比SVD提高了64%。通过多帧优化,方向(OursPT)提高到11.5度,其IoU从0.215增加到0.286。对于涉及面向对象的语义导航应用程序,例如“移动到桌子前面”和“移动到工作台一侧”等命令,这种准确性已经足够了。
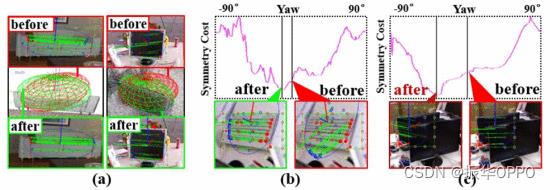
图8. 对称约束前后的结果(a)对象地标(b)成本函数值(典型情况)(c)成本函数值(失效情况)。
表二 多帧对象估计 IoU & Orientation
我们还发现了一些可以指导未来工作的失败案例。在ICL-NUIM数据集上,椅子和长凳等大型物体的方向误差达到大约几度。但是,在fr1_desk和fr2_desk中,书籍和键盘等小物体的方向达到 30-40 度。我们发现对小物体的中心和尺度的估计很差,这使得纹理约束中的三维对称点不准确。遮挡也会导致一些聚类环境的减少,如图8(c)所示,这揭示了多帧优化的必要性。
D. 多帧优化
为了与最先进的算法进行比较,我们重现了QuadricSLAM的性能,这是一个最先进的具有二次曲线的单目物体SLAM系统。QuadricSLAM使用SVD方法初始化对象,然后在后端进行优化。数据关联问题决定了观测值属于地图中的哪些对象。已经有工作[22]专注于这个问题。我们之前的工作[14]也讨论了将二次模型与非参数姿态图相结合来解决数据关联。二次曲线 SLAM 字母在实验中使用手动注释的数据关联。由于数据关联不是这封信的重点,我们还对 QuadricSLAM 和我们的使用手动注释的数据关联来证明实验中的最佳效果。
我们使用优化框架来利用来自多个帧的观察结果(1)。表二显示了欠条和方向误差。与SVD初始化相比,IoU和QuadricSLAM的方向都得到了改进。在平面支持约束和语义先验的情况下,我们没有纹理(参见 OursP)实现了更好的 IoU,方向为 0.285 和 14.12 度。在上述基础上进一步引入纹理对称约束(参见OursPT)后,取向改进至11.47度,在IoU上略有改善。总的来说,与QuadricSLAM相比,我们的IoU提高了138.3%,方向提高了63.9%。在fr2_dishe s和fr3_cabinet中,与QuadricSLAM相比,差距较小,因为在这些数据集中,相机轨迹围绕物体并产生足够的观测值,有利于QuadricSLAM的优化。
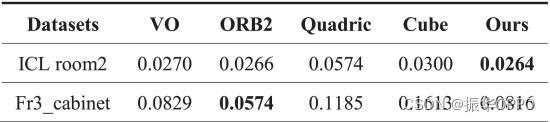
我们在表III中显示了轨迹误差。我们使用RGB-D版本ORB-SLAM2作为基线,并使用闭环禁用版本作为QuadricSLAM和我们的测程法(VO)。ORB-SLAM2无法完成完整的fr3_cabinet轨迹。为了公平比较,我们对截断的轨迹进行了评估,如 . 6 右。我们在两个数据集中都取得了比VO更好的结果,在ICL room2中甚至比ORB-SLAM2的结果略好,具有来自四个对象的新约束,但在fr3_cabinet上存在一定的差距,仅来自一个对象的有限约束。与对象SLAM基线相比,我们的基线优于QuadricSLAM,这证明了所提出的语义约束的有效性。CubeSLAM在信[2]中给出了ICL room3和fr5_cabinet的评估。我们为 ICL room2 选择数据,并使用开源代码获得截断的 CubeSLAM 结果fr3_cabinet,这比字母中的数据(0.17m)略好。尽管我们在两个数据集中都优于 CubeSLAM,但我们需要指出,为了获得比例,CubeSLAM 假设第一帧的姿势是已知的,而我们使用深度信息进行里程计,就像字母 [7] 中的 QuadricSLAM 一样。
表三 轨迹误差。有效值 (m)
E. 计算分析
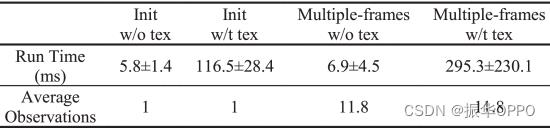
我们在C++中实现了该算法,并使用 g2o 库进行图优化。除了目标检测在GTX 1660 s上运行,频率为33 Hz外,所提出的算法在公共CPU上实时运行。我们在表 IV 中的fr5_desk数据集上展示了配备英特尔酷睿 i7200-2U 5.8GHz CPU、1GB RAM 的笔记本电脑的运行时间。
表四 运行时间性能
F. 讨论
我们没有发现引入物体后轨迹精度的显着提高。QuadricSLAM和我们之前的工作[14]都显示了相同的结论。我们认为这是因为ORB-SLAM2提供的测程数据已经相对准确。我们注意到,轨迹改善主要来自比例尺度和支撑平面约束。目前,地图中没有保持对称点,因此将它们与基于点的SLAM系统耦合将是未来进一步提高轨迹精度的工作。除了轨迹精度之外,我们相信对象特征在为SLAM系统带来高层次的理解和鲁棒性方面具有巨大的潜力,例如处理长期变化,社交导航和机器人操作。
纹理方向约束仍然与优化前二次曲面本身的精度密切相关。我们假设将方向估计与其他自由度解耦将进一步改善方向估计。我们已经探索了几种类型的对称描述符。我们将它留给探索其他更复杂的手动设计描述符的未来工作,例如FREAK [24]。我们讨论了水平放置在支撑平面上的物体,因此探索如何通过 3D 旋转估计物体的姿势是一项有价值的未来工作。
七、结论
本文提出了一个单目物体SLAM系统,该系统使用二次曲线对物体进行建模,并构建一个物体级地图来表示环境。本文还介绍了三种空间结构约束,包括比例约束、对称纹理约束和支持平面约束。基于这些约束,本文提出了两个新的模块——单帧初始化和定向精细优化,显著降低了对象SLAM系统对观测值数量和变化的依赖。这些方法有望使对象SLAM更好地适应实际复杂的环境。对象方向的对称约束为语义导航提供了信息,并有助于估计对象的比例和中心。考虑到未来的工作,进一步探索更多类型的对象空间约束和语义先验以帮助SLAM系统将是有希望的。
以上是关于视觉SLAMSO-SLAM: Semantic Object SLAM With Scale Proportional and Symmetrical Texture Constraints的主要内容,如果未能解决你的问题,请参考以下文章