玩转Elastic Search 之 服务集群搭建实例
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转Elastic Search 之 服务集群搭建实例相关的知识,希望对你有一定的参考价值。
文章目录
前言
没什么就是来玩玩Elastic Search 来look。顺便记录一下,就非常nice,顺便放松一下,水一篇博客~。
环境
阿里云 centos8
2 核 8 G
连接工具 Final Shell

这个是非常干净的服务器,咱们刚刚创建的一个实例。
Java 安装
这个没啥先装一个Java:
sudo yum -y install java-11-openjdk-devel
或者这个,上面那个把Java的一些额外的东西都会给你搞好。
sudo yum -y install java-11-openjdk

安装docker
卸载可能存在的docker版本
yum remove docker \\
docker-client \\
docker-client-latest \\
docker-common \\
docker-latest \\
docker-latest-logrotate \\
docker-logrotate \\
docker-selinux \\
docker-engine-selinux \\
docker-engine \\
docker-ce
咱们这个是新的玩意,不需要这个,但是如果你有可能安装过了,那就可以跳过,或者重装一下。
输入下面的指令,这个是安装一些可能需要的依赖的:
yum install -y yum-utils \\
device-mapper-persistent-data \\
lvm2 --skip-broken
然后设置一下镜像:
yum-config-manager \\
--add-repo \\
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
yum makecache --refresh
然后安装一下:
yum install -y docker-ce
安装成功,我们可以看到这个:

之后,把防火墙关一下:
# 关闭
systemctl stop firewalld
# 禁止开机启动防火墙
systemctl disable firewalld
dockers compose 安装
考虑到后面还要部署集群的话,那么我们必然是需要来安装这个玩意的。
curl -L https://github.com/docker/compose/releases/download/1.23.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
之后可以在这里看到这个:

然后我们修改一下权限:
chmod +x /usr/local/bin/docker-compose
好了这个就装好了。
es部署
这个可以去docker 镜像那里去拉取,我这里也有一个7.12的
链接:https://pan.baidu.com/s/1tmBP7RHVX62FdAigpcV0Lg
提取码:6666
我在服务器这边创建了一个目录,然后上传了这个tar包

要的小伙伴自取。
之后我们加载一下镜像。
为了测试,我们先做单节点部署,看看行不行。
单节点部署测试
安装ES
我们先运行一下我们的docker
systemctl start docker
然后切换到 es.tar 的目录,我的目录是 /elastic
然后加载镜像
docker load -i es.tar
之后我们创建一个容器:
docker run -d \\
--name es \\
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \\
-e "discovery.type=single-node" \\
-v es-data:/usr/share/elasticsearch/data \\
-v es-plugins:/usr/share/elasticsearch/plugins \\
--privileged \\
--network es-net \\
-p 9200:9200 \\
-p 9300:9300 \\
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
之后你可以看到容器当中创建了一个叫做es的玩意

之后打开你的 IP:9200 端口
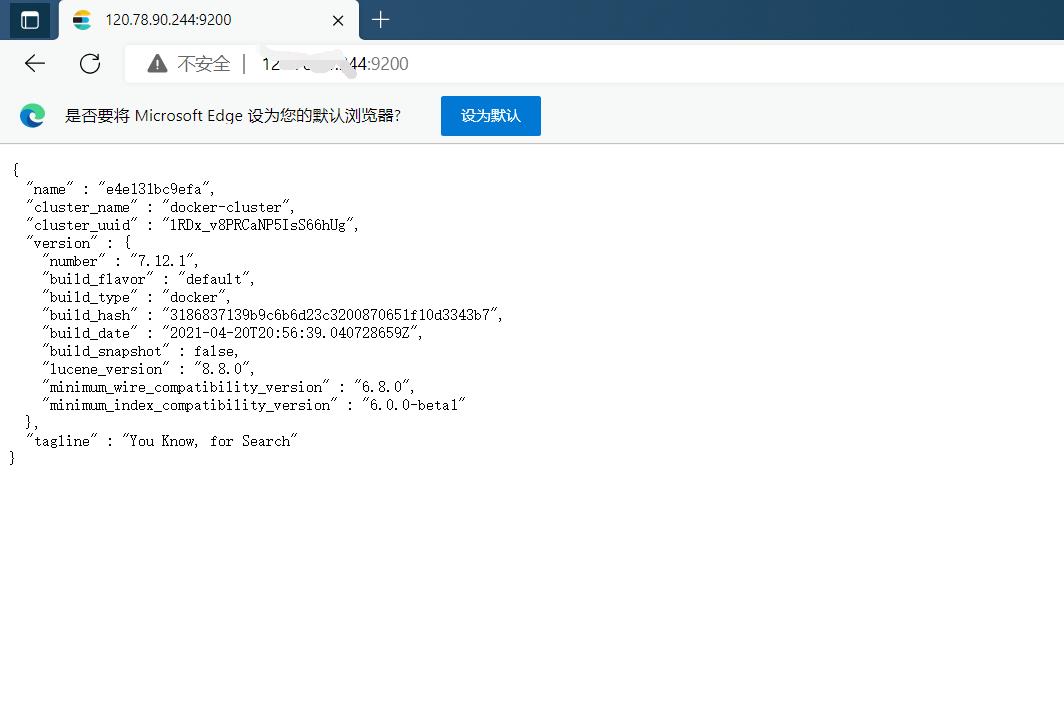
访问正常
安装kibana
这个是咱们联调elastic用的。
docker run -d \\
--name kibana \\
-e ELASTICSEARCH_HOSTS=http://es:9200 \\
--network=es-net \\
-p 5601:5601 \\
kibana:7.12.1
运行这个命令会自动帮助我们安装。
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
可以看到有两个了

之后在浏览器打开 5601端口
由于一个DevTool

安装ik分词器
这个分词器主要是针对中文,和jieba一样也支持自定义词库。
安装的话两种方案:
在线安装
这个比较慢。
执行如下指令就好了:
# 进入容器内部
docker exec -it containerName /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
离线安装
那么我们这边选择离线安装,所以先到ik官网,去搞到压缩包。
我们可以在docke看到有两个数据卷正在被使用。

并且可以看到具体信息

然后的话我们直接进入那个目录,然后上传ik分词器。
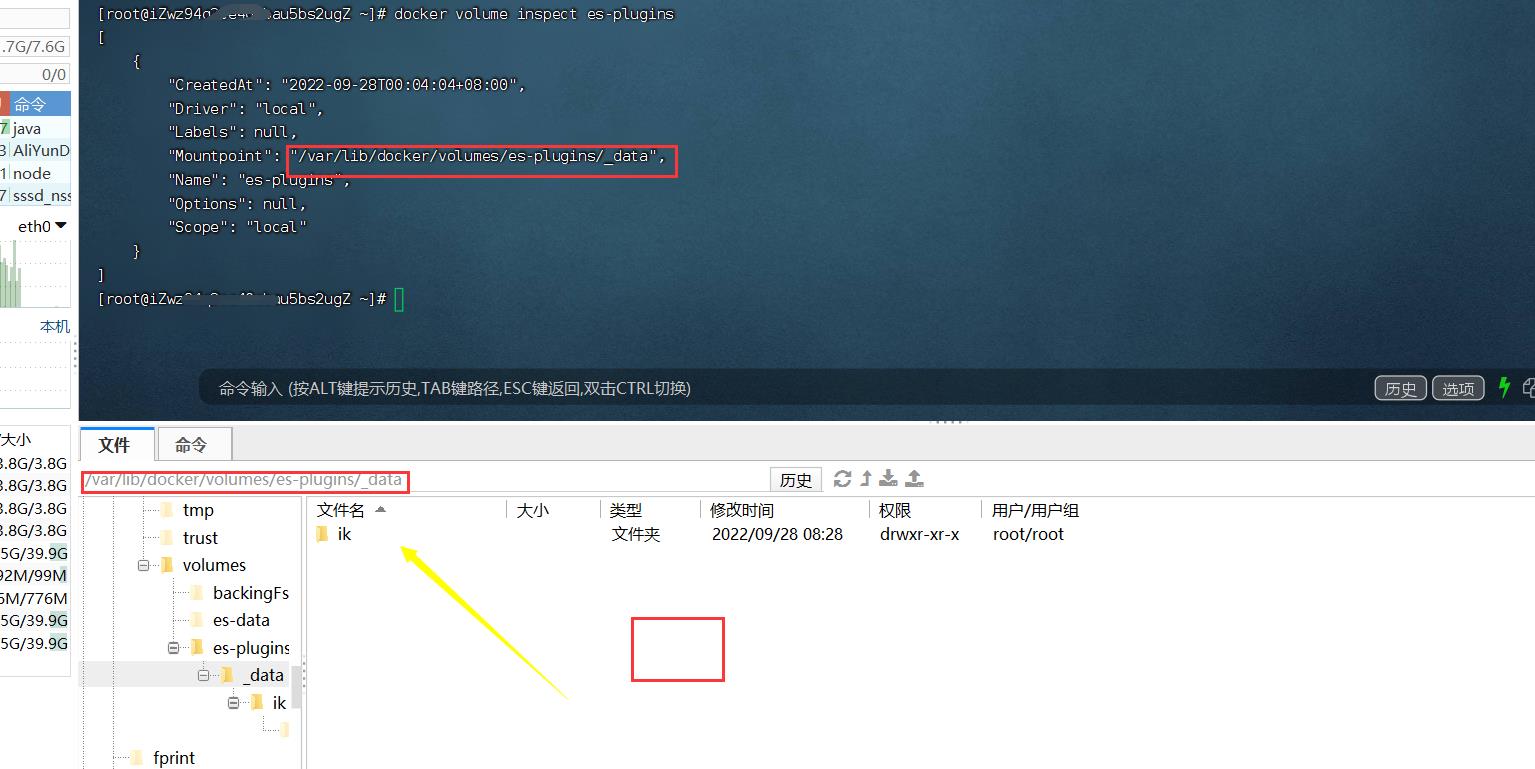
然后重启容器。
docker restart es
之后我们可以看到分词效果:
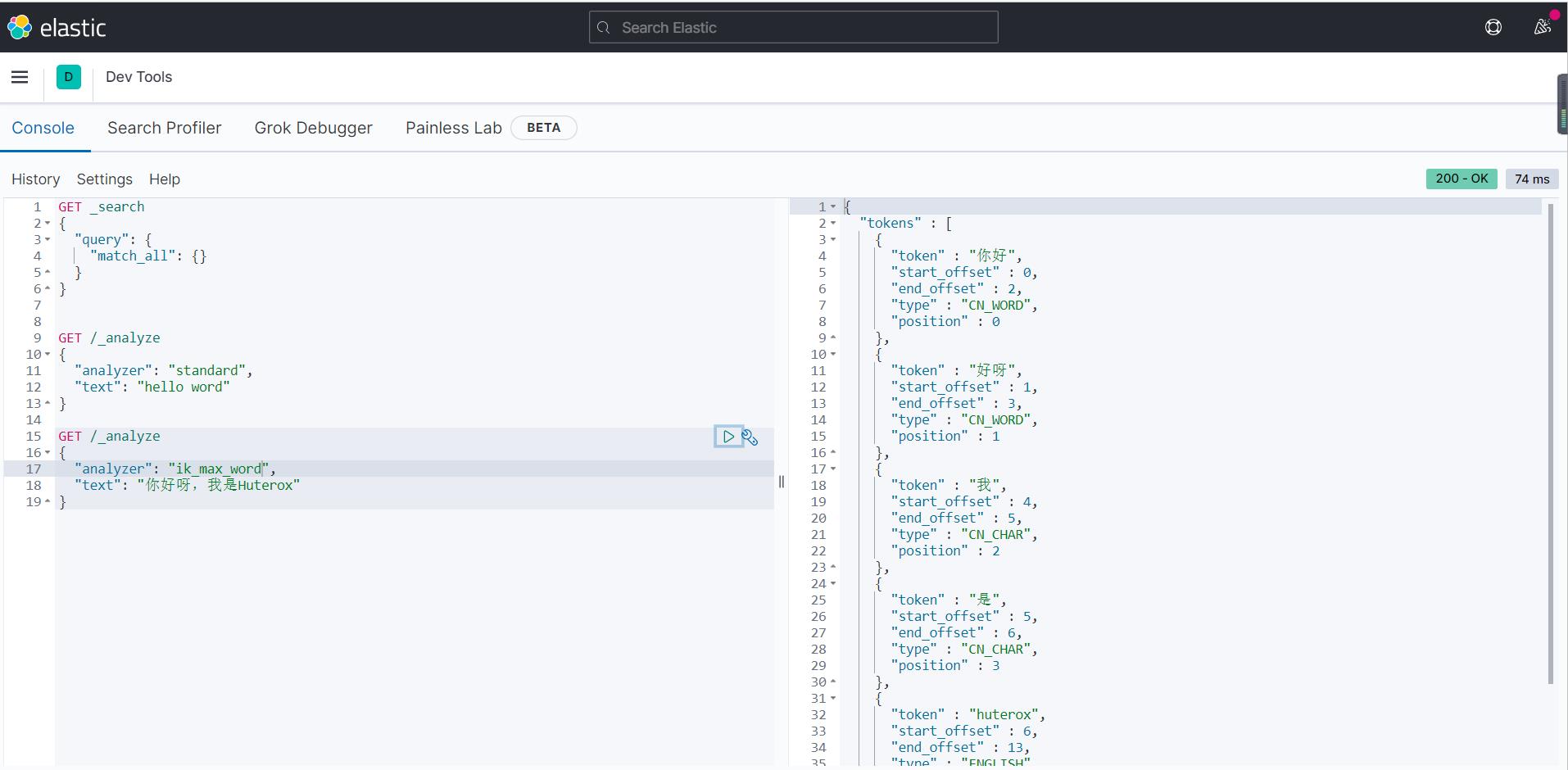
有两个模式
ik_smart
ik_max_word
现在演示的是ik_max_word 这个就和N-gram 有点像了。
此外也支持扩展词库。这个和jieba是一样的,格式也一样。
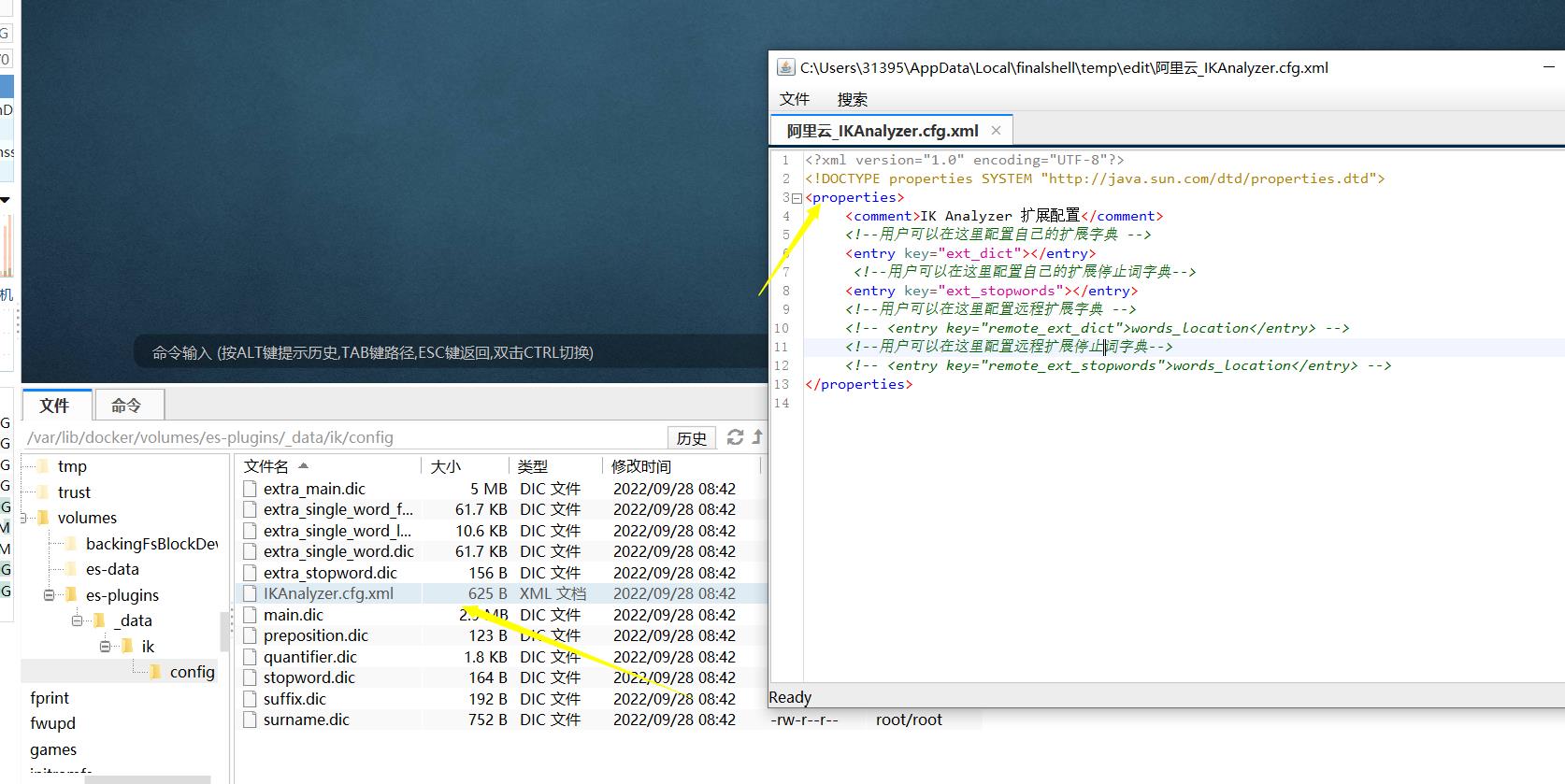
当然还有一些停用词,这个在做聊天机器人的时候用的不少。各大输入法平台都有提供。
集群部署
部署镜像
先说明一下es默认启动1GB内存,所以需要部署集群的话,至少保证你的服务器有4GB的运行内存。用都是一样的,只是看你的需求,如果是做快速缓存的话不如直接SpringCache+ redis ,像我只是玩玩的,最多用es做个简单查询,而且数据量也不多,所以还不如直接mysql怼,加上缓存缓解压力,毕竟qps 1K 都木有。
那么由于咱们这里是8GB的服务器,所以先浪一波,反正看自己,那么我这里先把容器stop一下。
创建一个docker-compose文件,然后上传服务器。
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
这个是我上传的文件

然后我们修改一下。这个文件:
vi /etc/sysctl.conf
添加这个:
vm.max_map_count=262144

然后
sysctl -p
让修改生效
之后启动集群
docker-compose up -d

安装cerebro
这个主要是用来监控集群的,刚刚那个也可以。
这个你可以上传你的服务器,也可以直接在本地使用。那么我们就上传服务器了。
我这里上传了一个:
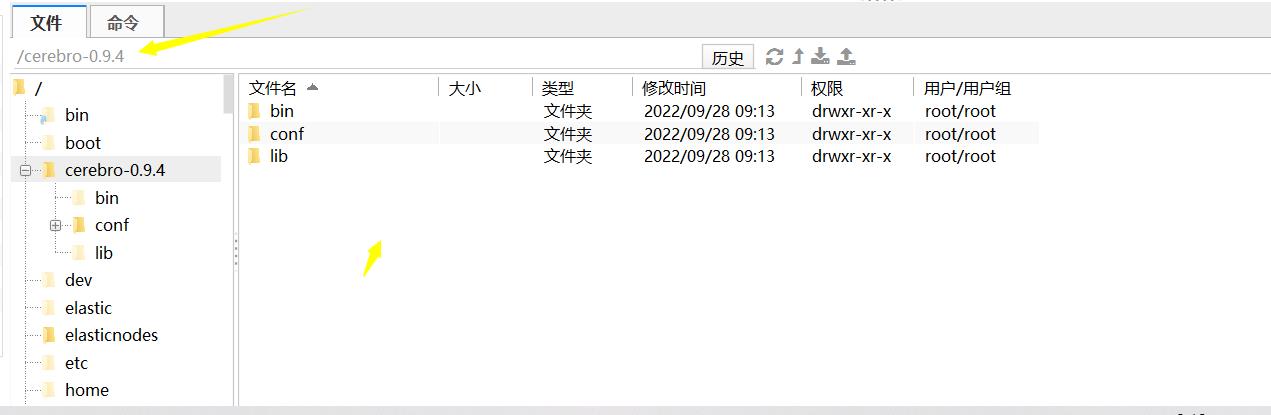
没办法,这些玩意不好下,只能用老一点的版。
进入到bin,然后的话,改一下权限
chomd 777 cerebro
然后
bash cerebro
之后启动成功。

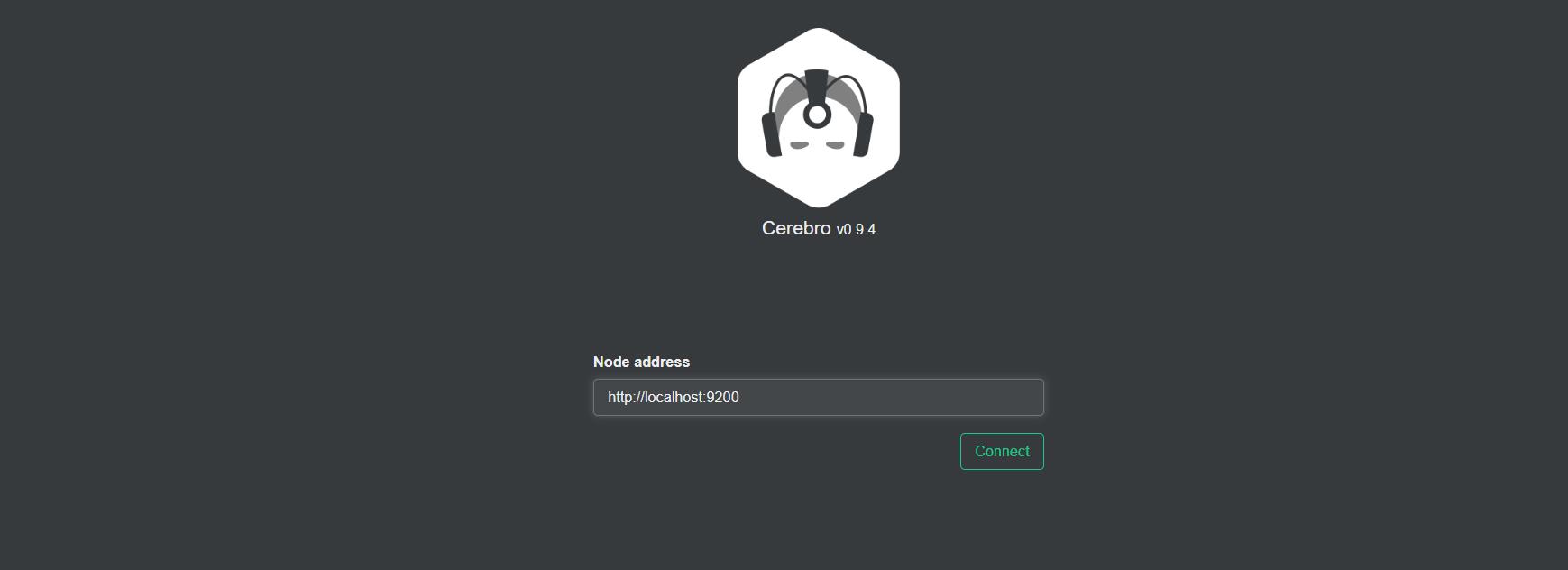
我这里是装在服务器的,所以填这个就好了
然后可以看到有3个
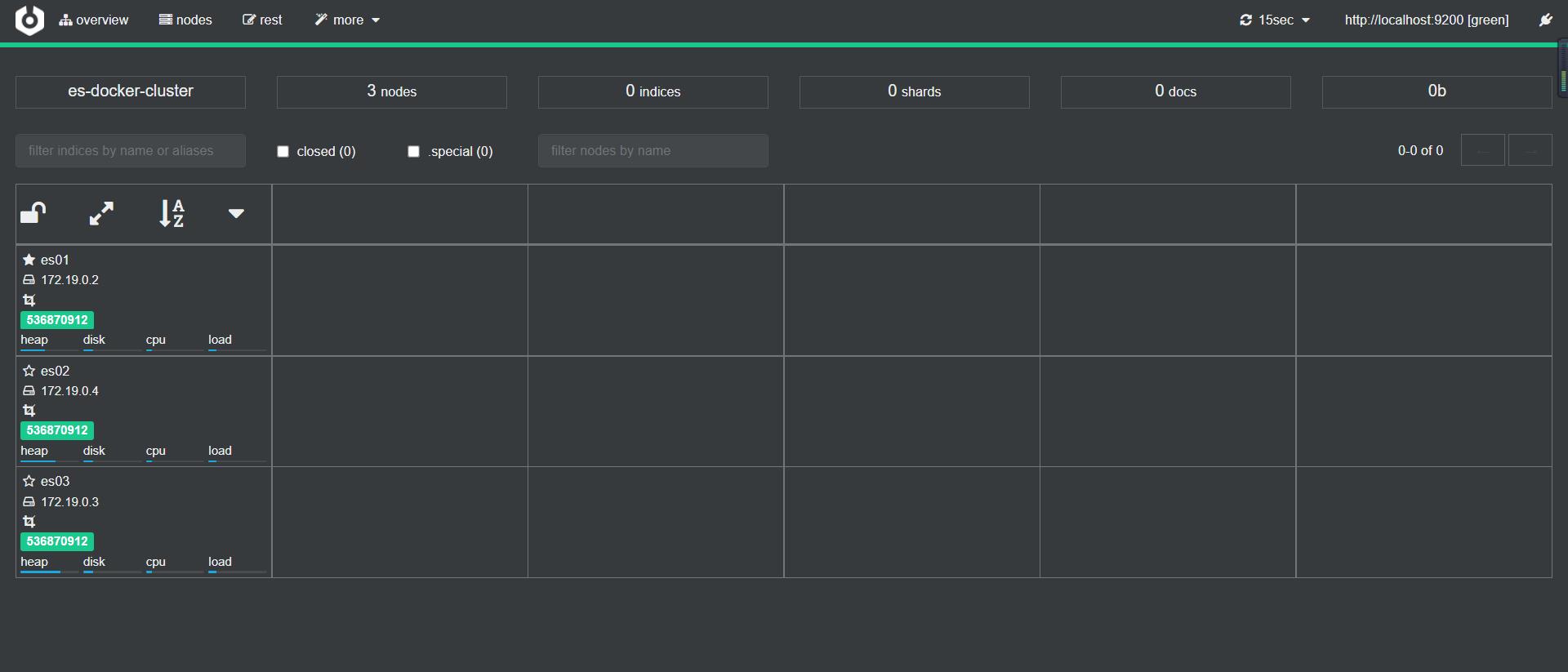
测试
这里的话我们可以直接使用Kibana测试,但是刚刚我们创建的集群和那个Kibana不在一个虚拟网络,所以我们需要重新创建,或者直接使用postman去搞一下。
这里我们再创建一个容器,玩玩。
docker run -d \\
--name kibananodes \\
-e ELASTICSEARCH_HOSTS=http://172.19.0.2:9200 \\
--network=elasticnodes_elastic \\
-p 5601:5601 \\
kibana:7.12.1
这个http://172.19.0.2:9200是我们es01 的内网地址,实际上你改成http:ip:9200也可以。
然后我们来创建一个mapping
PUT /huteroxdev
"settings":
"number_of_shards": 3,
"number_of_replicas": 1
,
"mappings":
"properties":
"name":
"type": "text"
,
"age":
"type": "integer"
此时可以看到有东西了

POST /huteroxdev/_doc/1
"name":"小明",
"age":18
POST /huteroxdev/_doc/2
"name":"小红",
"age":18
然后查一下:
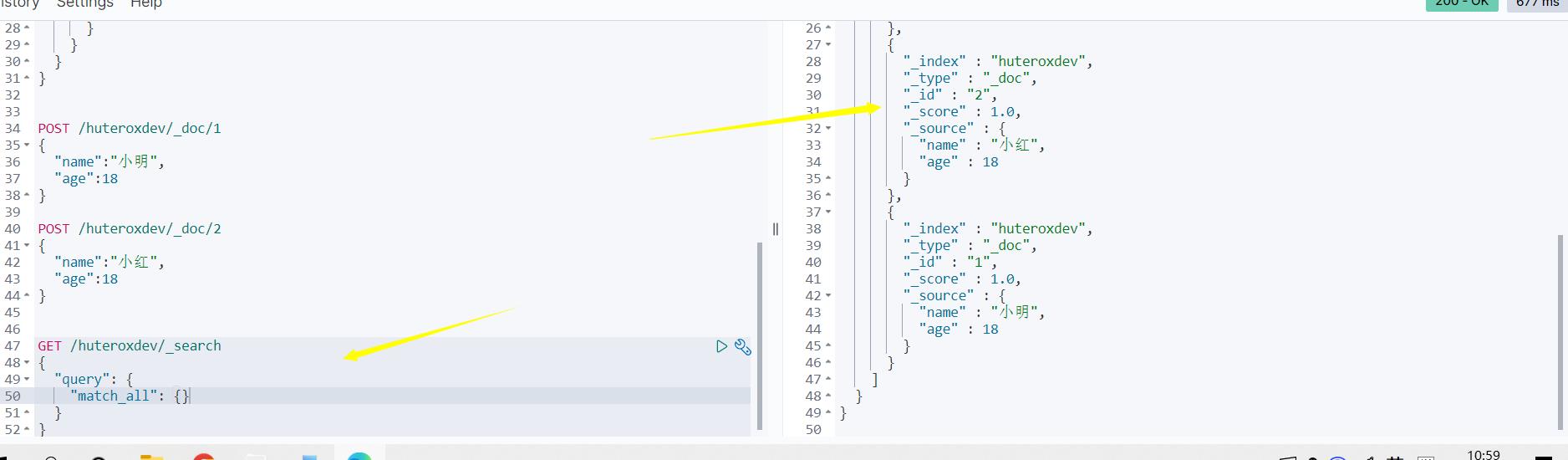
完美,接下来就用RestClient 玩一下就好了。
当然玩玩还是单节点就好了。
最后,停止所有容器,还是玩玩单节点吧,那玩意2GB 服务器就能玩。
docker stop $(docker ps -a -q)
以上是关于玩转Elastic Search 之 服务集群搭建实例的主要内容,如果未能解决你的问题,请参考以下文章