Few-Shot Learning
Posted Harris-H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Few-Shot Learning相关的知识,希望对你有一定的参考价值。
Few-Shot Learning

与普通的分类学习方法不同,Few-Shot Learning通过小样本Support Set 来判断Query的类别。

Few-shot learning 是一种Meta Learning。
Meta Learning 就是自主学习。

1.Supervised Learning vs. Few-Shot Learning


与监督学习相比,Few-Shot Learning 的Query Sample 的类别也是未知的。

Support Set 通常是一个二维矩阵的形式。
k-way 表示类别的个数
n-shot 表示每个类样本的个数



变化关系如上图所示。
显然类别越多准确率越低,shots 越大,准确率越高。
2.Basic Idea

从大规模数据集中训练CNN网络,学习相似函数sim。
然后应用sim进行预测,将Query 与 Support Set 依次求sim,取最高得分的类。

2.1 常见的数据集datasets

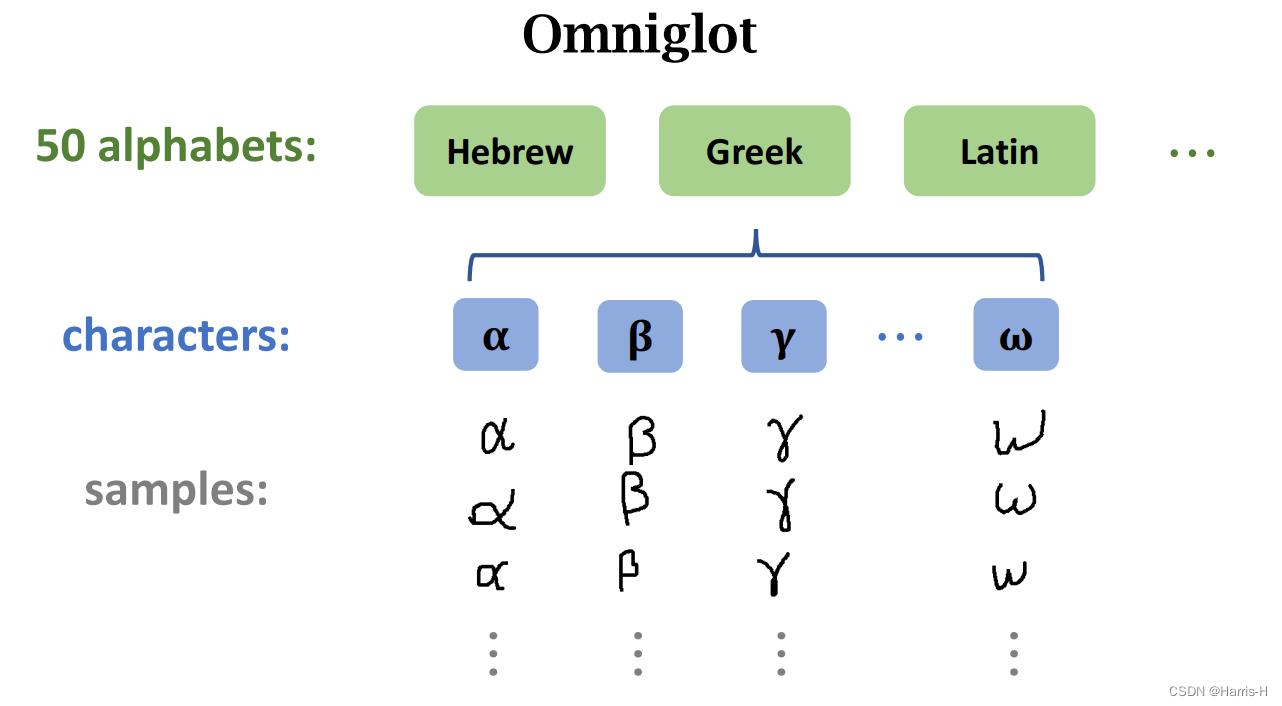

字符集Omniglot。

图像集Mini-ImageNet
3.Siamese Network
3.1 Learning Pairwise Similarity Scores

将data分为两类,Positive and Negative Samples。
每个数据都是一个三元组:第一个图片、第二个图片、标签。1表示是同一类,0表示不是同一类。

构建一个CNN提取图片的特征向量。
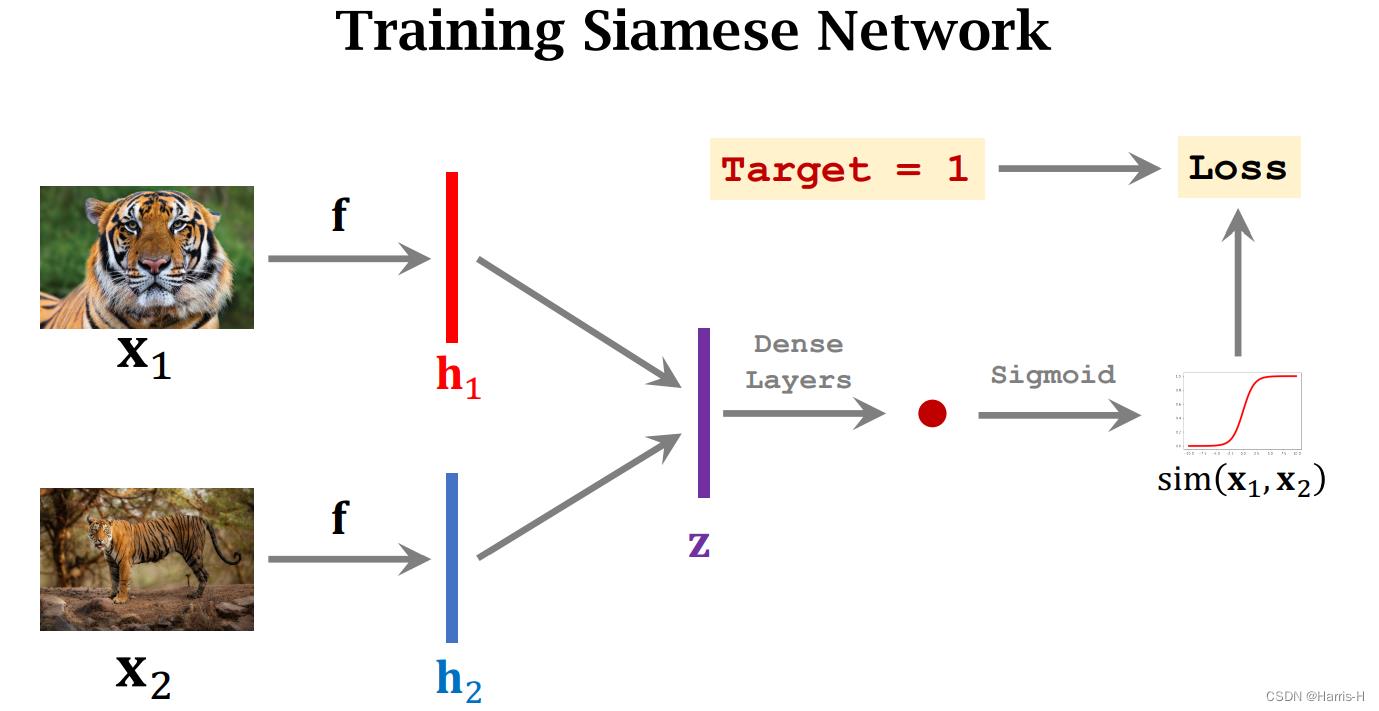
每次求输入两个图片,通过CNN得到两个特征向量 h 1 , h 2 h_1,h_2 h1,h2。然后相减取绝对值 z = ∣ h 1 − h 2 ∣ z=|h_1-h_2| z=∣h1−h2∣,再通过全连接层和激活函数Sigmoid得到值在 [ 0 , 1 ] [0,1] [0,1]之间。然后与标签target 计算Loss。使用Loss进行梯度更新全连接层和CNN的参数。
target为0时同理。

3.2 Triplet Loss

Triplet Loss 是每次选择一个anchor 作为锚点,然后选择同类的另一个作为postive、不同类的一个作为negative。

通过CNN 提取特征向量后,分别与 x a x^a xa 计算二范数的平方。


我们的目的是让 d + d^+ d+ 更小, d − d^- d− 更大。因此考虑设置超参数 α \\alpha α 。
当 d − ≥ d + + α d^-\\ge d^++\\alpha d−≥d++α 时就不用管,Loss为0.
否则 Loss = d + + α − d − \\textLoss=d^++\\alpha-d^- Loss=d++α−d−。然后梯度下降更新CNN。

在于预测的时候,我们计算两个图片的在特征向量空间的距离即可。
3.3 Summary

CNN用于提取特征向量,对于Query要么使用Sigmoid 近似相似度sim,要么使用distance 比较。
4.Pretraining and Fine Tuning

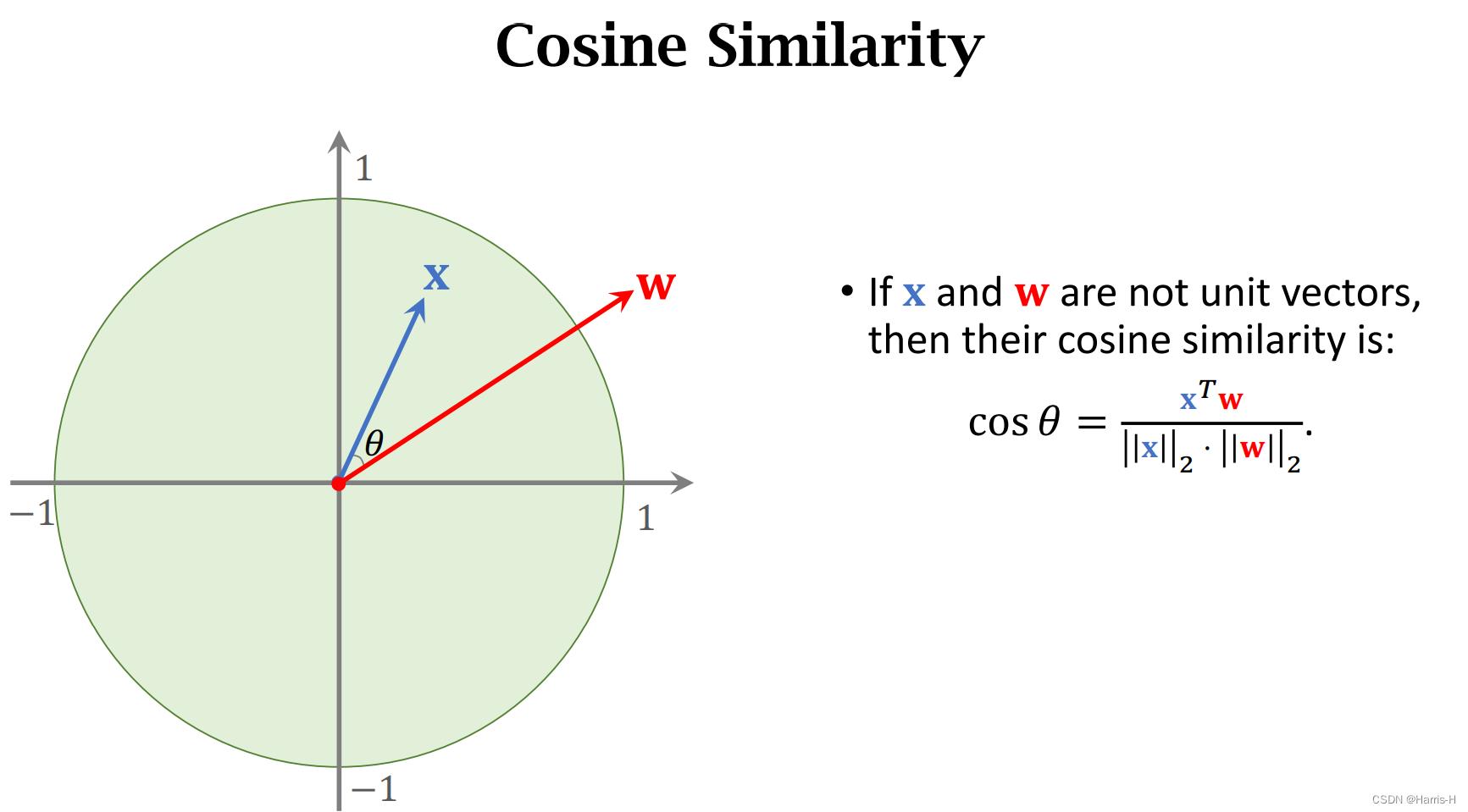
cosine similarity 是两个二范数为1的向量的内积。几何意义上看是一个向量在另一个向量上的映射范围是 [ − 1 , 1 ] [-1,1] [−1,1]。
若模长不为1,可以进行归一化。
4.1 Softmax Function

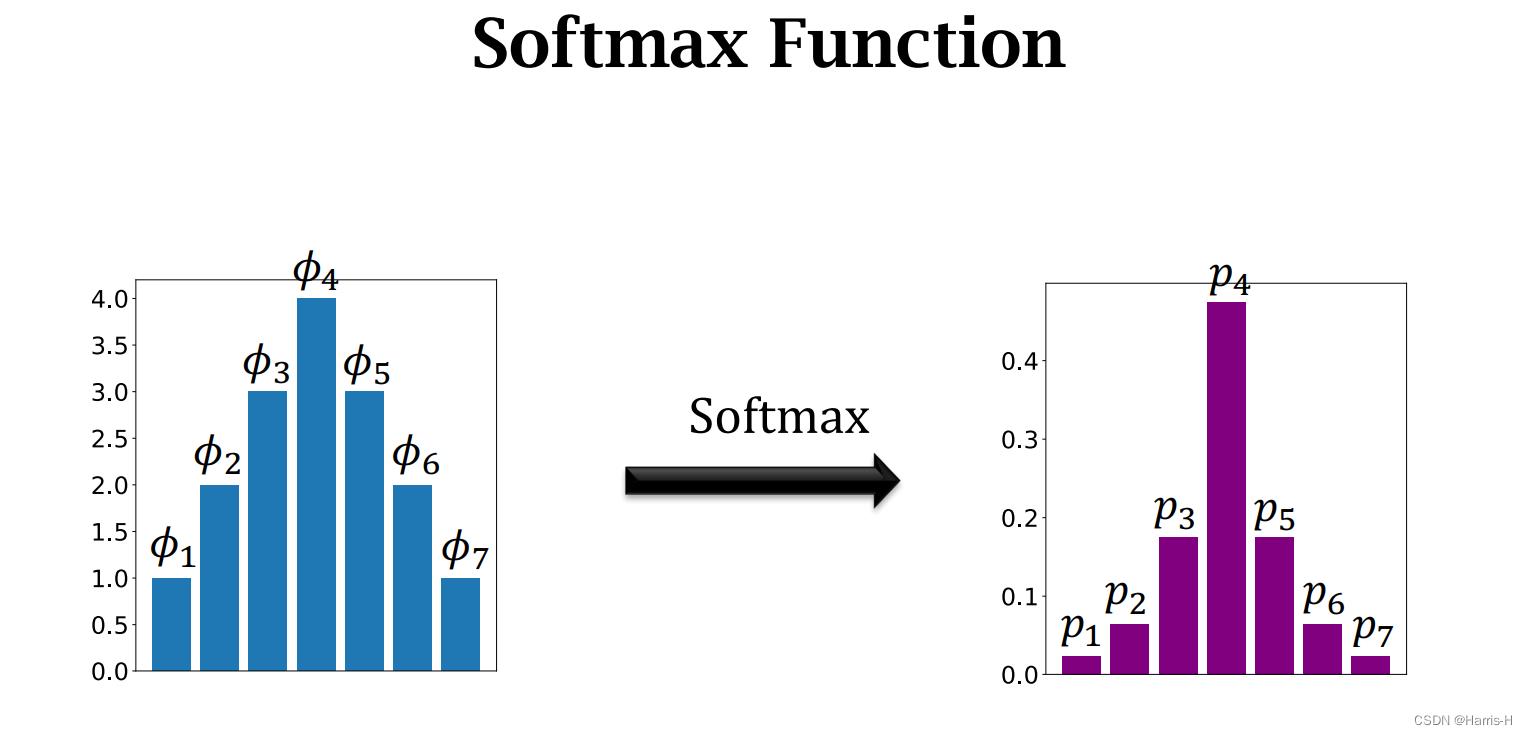
Softmax 函数常常用于输出概率密度分布,将输入的一组向量进行softmax后得到对应的概率分布。

Softmax Classifier 的组成由二维向量W和常量b组成。
4.2 Few-Shot Prediction Using Pretrained CNN


使用CNN提取特征向量,然后对于Support Set中的每类进行取均值,然后归一化。

归一化后堆叠为矩阵M。
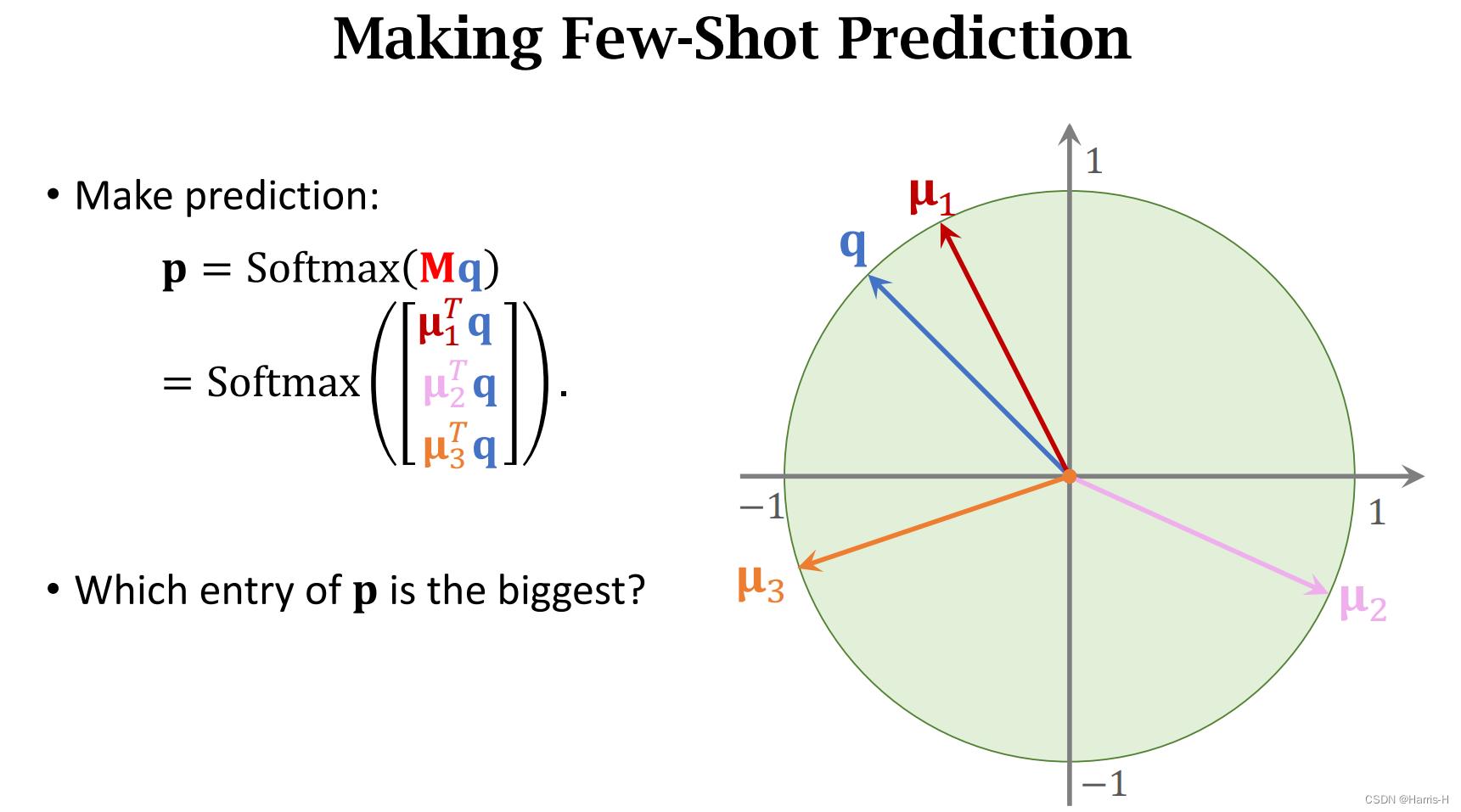
这样Mq 的结果就是cos 相似值,然后进行softmax即可得到概率密度分布。
4.3 Fine-Tuning(微调)
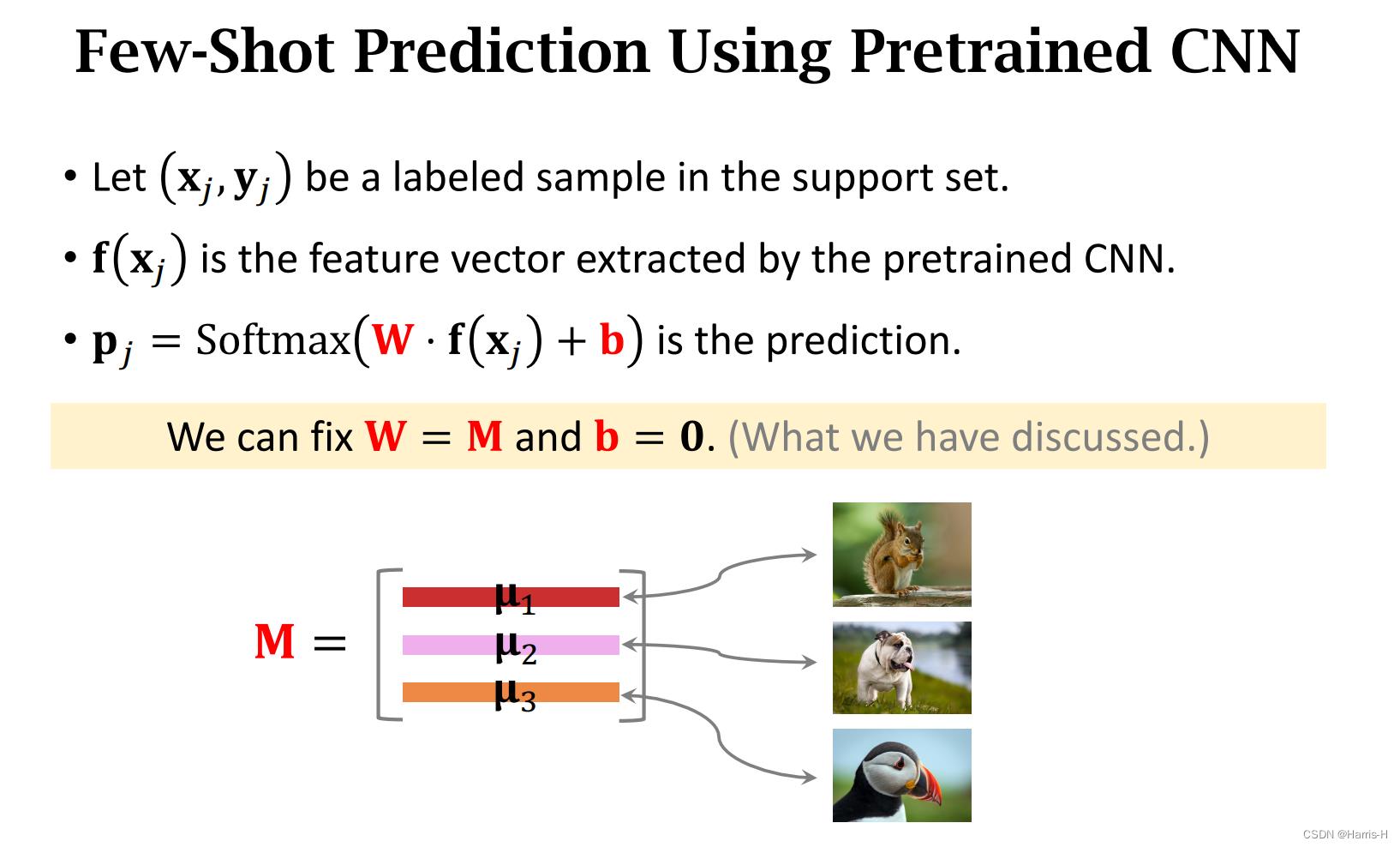
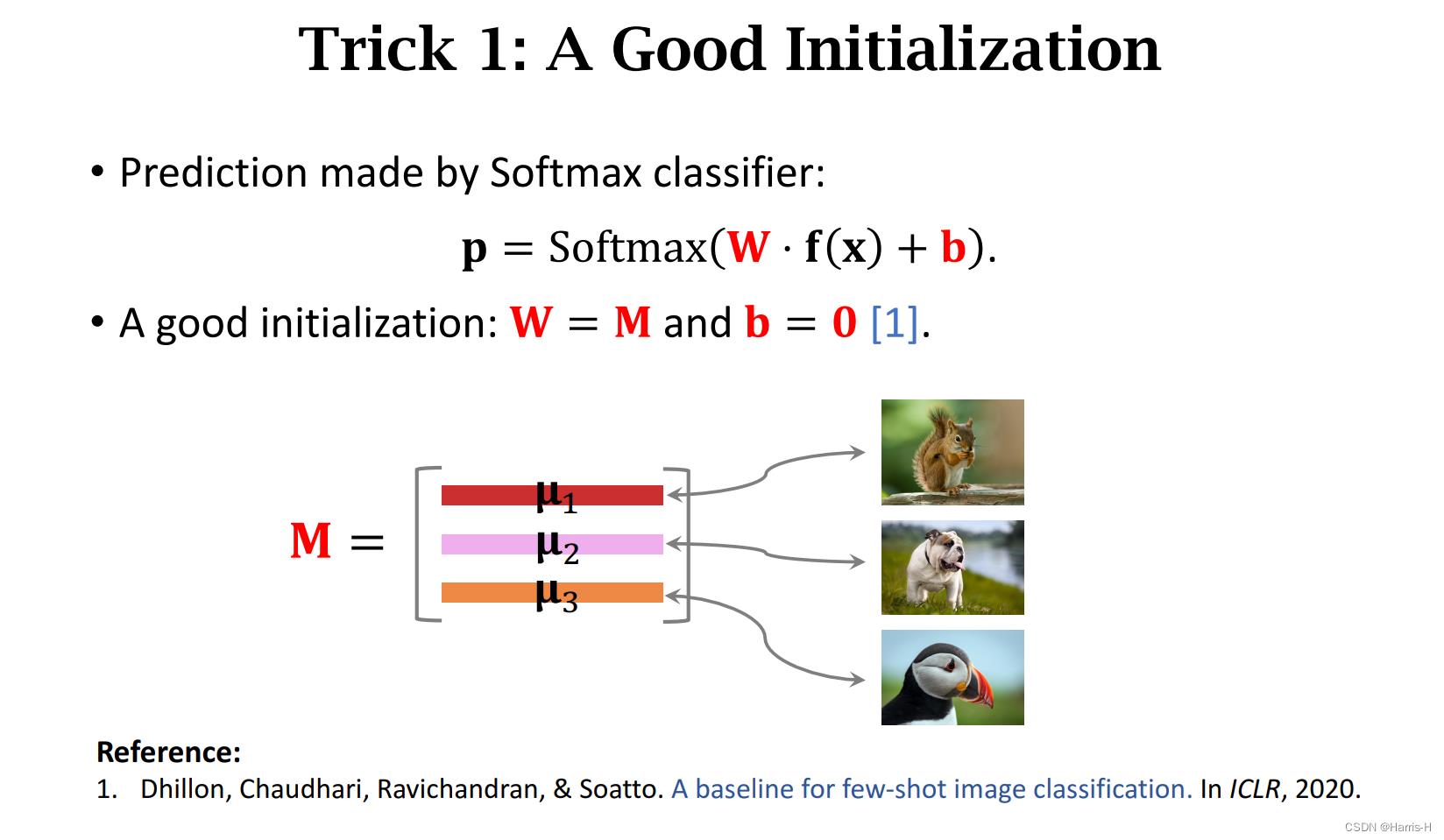
在使用CNN进行Few-Shot 预测时,softmax 的W和b时固定的。
W就是Support set 中计算堆叠后的M,b=0。

我们对softmax得到的 p j p_j pj 和真实标签 y j y_j yj 求CrossEntropy,然后最小化。

为了避免过拟合,一般还会加上Regularization。

实验证明Fine Tuning效果会更好。
4.4 优化Tricks

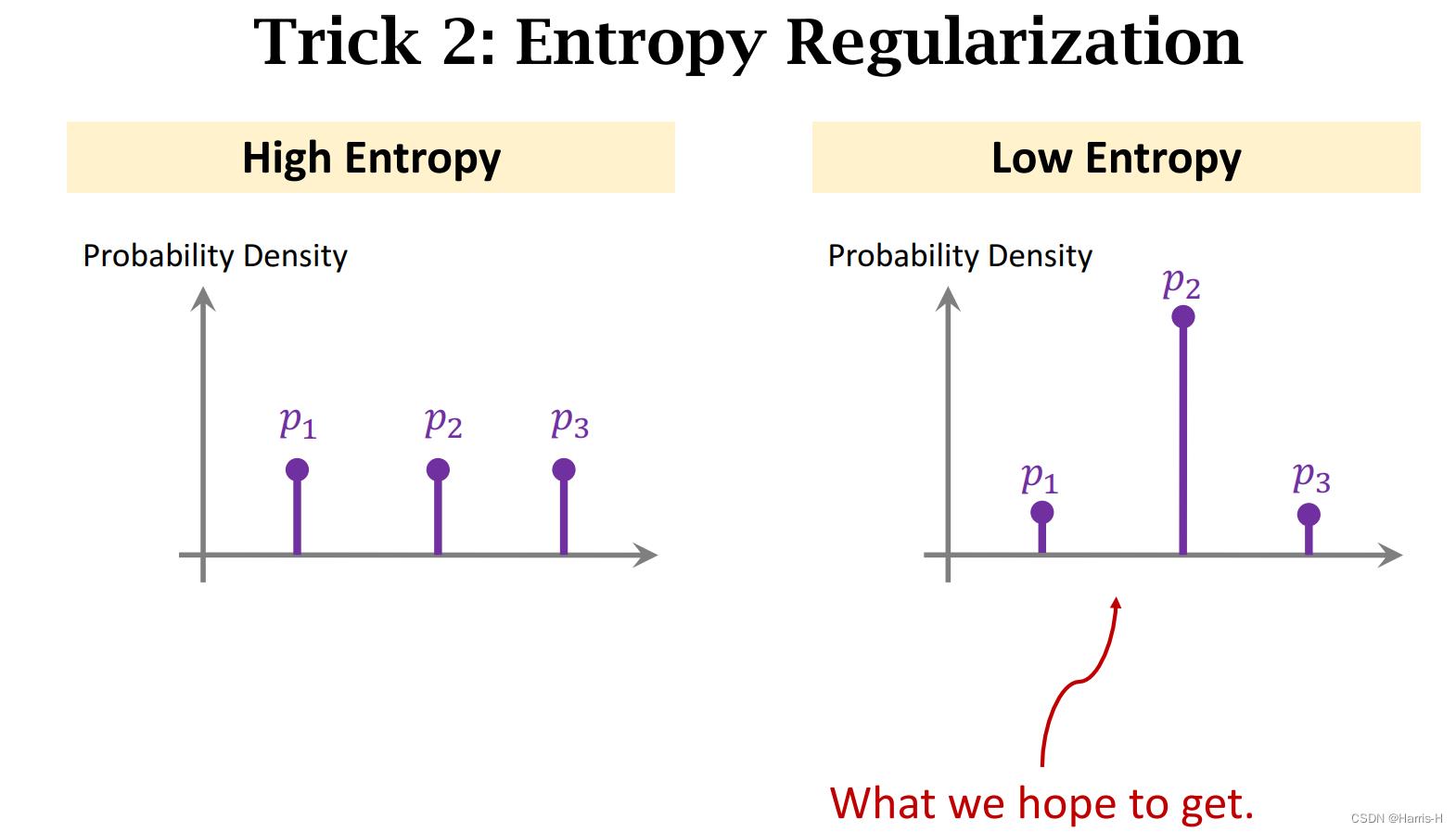
对所有样例得到的sotamax p p p 进行Entropy 然后正则化,该值越小说明更容易区分。

Trick3 使用Cosine Similarity 代替 w T q w^Tq wTq。本质就是将 w T q w^Tq wTq 进行归一化,映射到模长为1,实际证明效果更好。
4.5 Summary

大规模数据集预训练CNN,使用CNN提取特征向量。
计算Support Set 每个类别的特征向量均值。
然后比较两两的距离,选择分类。

在Pretraining后,还可以通过Fine Tuning优化Softmax 分类器。同时也可以在训练分类器的同时反向传播更新CNN参数。
以上是关于Few-Shot Learning的主要内容,如果未能解决你的问题,请参考以下文章